Formal and Informal Model Selection with Incomplete Data
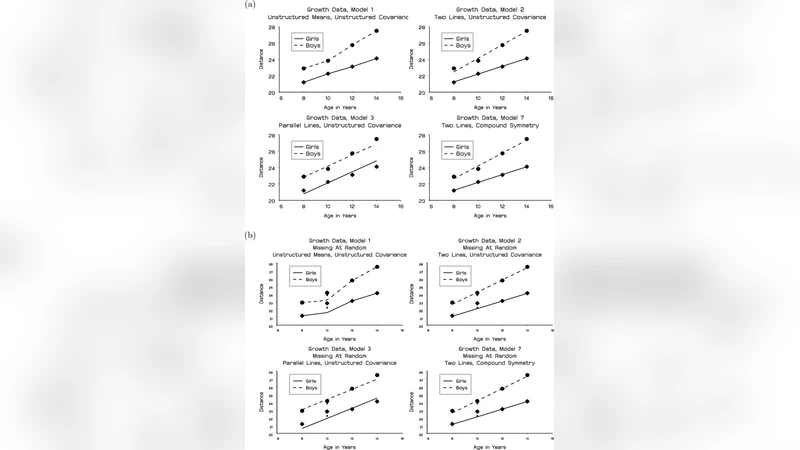
Model selection and assessment with incomplete data pose challenges in addition to the ones encountered with complete data. There are two main reasons for this. First, many models describe characteristics of the complete data, in spite of the fact that only an incomplete subset is observed. Direct comparison between model and data is then less than straightforward. Second, many commonly used models are more sensitive to assumptions than in the complete-data situation and some of their properties vanish when they are fitted to incomplete, unbalanced data. These and other issues are brought forward using two key examples, one of a continuous and one of a categorical nature. We argue that model assessment ought to consist of two parts: (i) assessment of a model’s fit to the observed data and (ii) assessment of the sensitivity of inferences to unverifiable assumptions, that is, to how a model described the unobserved data given the observed ones.
💡 Research Summary
The paper tackles the often‑overlooked problem of model selection and assessment when the data are incomplete. While the challenges of working with complete data are well known, the presence of missing values introduces two fundamental difficulties. First, most statistical and machine learning models are defined in terms of the full (unobserved) data generating process. When only a subset of the variables or cases is observed, the direct comparison between model predictions and the data becomes ambiguous. Second, models that are robust under complete‑data conditions can become highly sensitive to their underlying assumptions once the data are unbalanced or contain missing entries; properties such as consistency, efficiency, or identifiability may disappear.
To illustrate these points, the authors present two canonical examples. The first concerns a continuous‑variable setting, using a Gaussian mixture model. Under complete data the mixture weights, component means and variances are estimated reliably, and information criteria (AIC, BIC) provide a clear ranking of competing models. When missingness is introduced, especially under a Not‑Missing‑At‑Random (MNAR) mechanism that preferentially removes observations from certain components, the estimated mixture proportions become severely biased and the component parameters drift. Simulations that vary the missingness mechanism from MCAR (Missing Completely At Random) to MAR (Missing At Random) to MNAR demonstrate how the log‑likelihood, parameter estimates, and model‑selection scores change dramatically.
The second example deals with a categorical outcome, employing multinomial logistic regression. With full data the odds ratios for each class are stable and standard errors are modest. However, when a substantial fraction of the outcome is missing—particularly for a minority class—the regression coefficients become unstable, standard errors inflate, and the model’s predictive accuracy collapses. Moreover, if the missingness depends on covariates (a MAR situation), the apparent relationship between predictors and outcome is distorted, leading to misleading inference. The authors replicate this phenomenon using a real survey dataset, artificially imposing different missingness patterns and showing the resulting variation in coefficient estimates and classification performance.
From these case studies the authors derive a two‑stage framework for model assessment with incomplete data.
- Fit‑to‑Observed‑Data Assessment – Traditional goodness‑of‑fit measures (log‑likelihood, AIC, BIC, cross‑validation error) are computed only on the observed portion of the data. Parameter estimation can be carried out using Expectation‑Maximization (EM) or multiple imputation (MI) to handle the missing entries while preserving the likelihood structure.
- Assumption‑Sensitivity Analysis – A set of plausible missing‑data mechanisms (e.g., MCAR, MAR, various MNAR scenarios) is specified, and for each mechanism a complete‑data surrogate is generated (via MI, Bayesian data augmentation, or pattern‑mixture models). The variability of parameter estimates, predictive metrics, and selected models across these scenarios quantifies how dependent the conclusions are on unverifiable assumptions. Techniques such as Bayesian Model Averaging (BMA), sensitivity curves, or weighted averaging of imputed datasets are recommended to summarize this variability.
The paper emphasizes several practical recommendations. Researchers should first explore the missingness pattern, possibly collecting auxiliary information that can inform the missing‑data mechanism. Relying on a single imputation method is discouraged; instead, multiple imputations should be used to propagate uncertainty. Model selection should never be based solely on the observed‑data fit; the sensitivity analysis must be reported alongside to reveal hidden biases. In high‑stakes domains—policy evaluation, clinical decision‑making, social science—these sensitivity results should be explicitly incorporated into the decision process, ensuring that stakeholders understand the degree of confidence (or lack thereof) attached to the chosen model.
In conclusion, the authors argue that model selection with incomplete data must balance accuracy (how well a model fits the observed data) with robustness (how stable the inference is under alternative, plausible missing‑data assumptions). By separating the assessment into the two stages described above, analysts can obtain a clearer picture of both dimensions, leading to more reliable inference and more transparent, responsible decision‑making when faced with inevitably imperfect data.
Comments & Academic Discussion
Loading comments...
Leave a Comment