📝 Original Info
- Title: Enabling Loosely-Coupled Serial Job Execution on the IBM BlueGene/P Supercomputer and the SiCortex SC5832
- ArXiv ID: 0808.3536
- Date: 2008-08-27
- Authors: Researchers from original ArXiv paper
📝 Abstract
Our work addresses the enabling of the execution of highly parallel computations composed of loosely coupled serial jobs with no modifications to the respective applications, on large-scale systems. This approach allows new-and potentially far larger-classes of application to leverage systems such as the IBM Blue Gene/P supercomputer and similar emerging petascale architectures. We present here the challenges of I/O performance encountered in making this model practical, and show results using both micro-benchmarks and real applications on two large-scale systems, the BG/P and the SiCortex SC5832. Our preliminary benchmarks show that we can scale to 4096 processors on the Blue Gene/P and 5832 processors on the SiCortex with high efficiency, and can achieve thousands of tasks/sec sustained execution rates for parallel workloads of ordinary serial applications. We measured applications from two domains, economic energy modeling and molecular dynamics.
💡 Deep Analysis
Deep Dive into Enabling Loosely-Coupled Serial Job Execution on the IBM BlueGene/P Supercomputer and the SiCortex SC5832.
Our work addresses the enabling of the execution of highly parallel computations composed of loosely coupled serial jobs with no modifications to the respective applications, on large-scale systems. This approach allows new-and potentially far larger-classes of application to leverage systems such as the IBM Blue Gene/P supercomputer and similar emerging petascale architectures. We present here the challenges of I/O performance encountered in making this model practical, and show results using both micro-benchmarks and real applications on two large-scale systems, the BG/P and the SiCortex SC5832. Our preliminary benchmarks show that we can scale to 4096 processors on the Blue Gene/P and 5832 processors on the SiCortex with high efficiency, and can achieve thousands of tasks/sec sustained execution rates for parallel workloads of ordinary serial applications. We measured applications from two domains, economic energy modeling and molecular dynamics.
📄 Full Content
Enabling Loosely-Coupled Serial Job Execution on the
IBM BlueGene/P Supercomputer and the SiCortex SC5832
Ioan Raicu*, Zhao Zhang+, Mike Wilde#+, Ian Foster#*+
*Department of Computer Science, University of Chicago, IL, USA
+Computation Institute, University of Chicago & Argonne National Laboratory, USA
#Math and Computer Science Division, Argonne National Laboratory, Argonne IL, USA
iraicu@cs.uchicago.edu, zhaozhang@uchicago.edu, wilde@mcs.anl.gov, foster@mcs.anl.gov
Abstract
Our work addresses the enabling of the execution of highly
parallel computations composed of loosely coupled serial jobs
with no modifications to the respective applications, on large-
scale systems. This approach allows new-and potentially far
larger-classes of application to leverage systems such as the IBM
Blue Gene/P supercomputer and similar emerging petascale
architectures. We present here the challenges of I/O performance
encountered in making this model practical, and show results
using both micro-benchmarks and real applications on two large-
scale systems, the BG/P and the SiCortex SC5832. Our
preliminary benchmarks show that we can scale to 4096
processors on the Blue Gene/P and 5832 processors on the
SiCortex with high efficiency, and can achieve thousands of
tasks/sec sustained execution rates for parallel workloads of
ordinary serial applications. We measured applications from two
domains, economic energy modeling and molecular dynamics.
Keywords: high throughput computing, loosely coupled
applications, petascale systems, Blue Gene, SiCortex, Falkon,
Swift
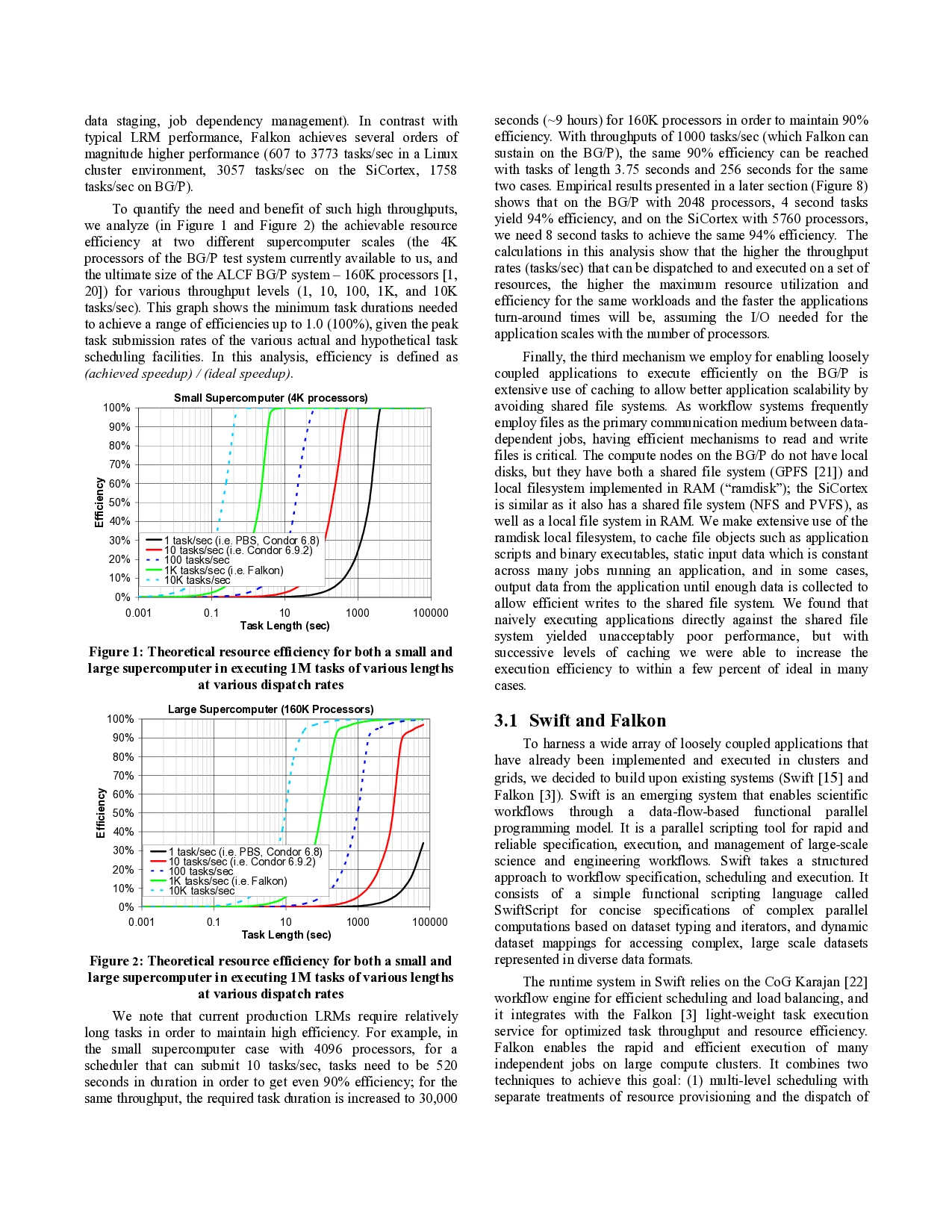
- Introduction
Emerging petascale computing systems are primarily
dedicated to tightly coupled, massively parallel applications
implemented using message passing paradigms. Such systems—
typified by IBM’s Blue Gene/P [1]—include fast integrated
custom interconnects, multi-core processors, and multi-level I/O
subsystems, technologies that are also found in smaller, lower-
cost, and energy-efficient systems such as the SiCortex SC5832
[2]. These architectures are well suited for a large class of
applications that require a tightly coupled programming approach.
However, there is a potentially larger class of “ordinary” serial
applications that are precluded from leveraging the increasing
power of modern parallel systems due to the lack of efficient
support in those systems for the “scripting” programming model
in which application and utility programs are linked into useful
workflows through the looser task-coupling model of passing data
via files.
With the advances in e-Sciences and the growing complexity
of scientific analyses, more and more scientists and researchers
are relying on various forms of application scripting systems to
automate the workflow of process coordination, derivation
automation, provenance tracking, and bookkeeping. Their
approaches are typically based on a model of loosely coupled
computation, exchanging data via files, databases or XML
documents, or a combination of these. Furthermore, with
technology advances in both scientific instrumentation and
simulation, the volume of scientific datasets is growing
exponentially. This vast increase in data volume combined with
the growing complexity of data analysis procedures and
algorithms have rendered traditional manual and even automated
serial processing and exploration unfavorable as compared with
modern high performance computing processes automated by
scientific workflow systems.
We focus in this paper on the ability to execute large scale
applications leveraging existing scripting systems on petascale
systems such as the IBM Blue Gene/P. Blue Gene-class systems
have been traditionally called high performance computing (HPC)
systems, as they almost exclusively execute tightly coupled
parallel jobs within a particular machine over low-latency
interconnects; the applications typically use a message passing
interface (e.g. MPI) to achieve the needed inter-process
communication. Conversely, high throughput computing (HTC)
systems (which scientific workflows can more readily utilize)
generally involve the execution of independent, sequential jobs
that can be individually scheduled on many different computing
resources across multiple administrative boundaries. HTC systems
achieve this using various grid computing techniques, and almost
exclusively use files, documents or databases rather than messages
for inter-process communication.
The hypothesis is that loosely coupled applications can be
executed efficiently on today’s supercomputers; this paper
provides empirical evidence to prove our hypothesis. The paper
also describes the set of problems that must be overcome to make
loosely-coupled programming practical on emerging petascale
architectures: local resource manager scalability and granularity,
efficient utilization of the raw hardware, shared file system
contention, and application scalability. It describes how
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.