LLE with low-dimensional neighborhood representation
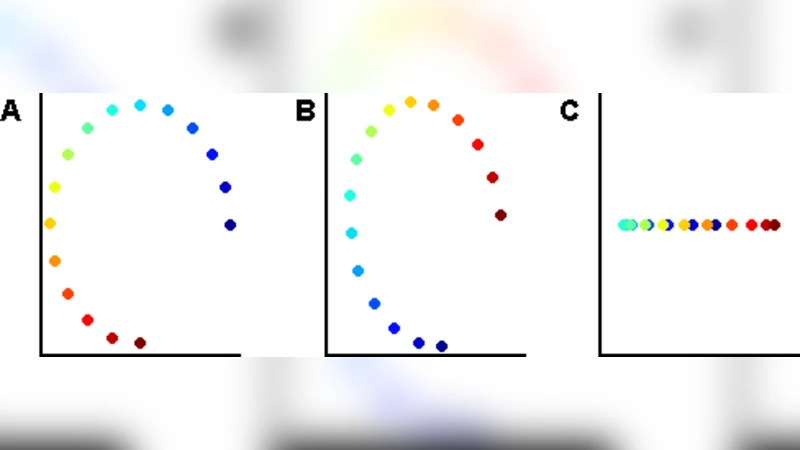
The local linear embedding algorithm (LLE) is a non-linear dimension-reducing technique, widely used due to its computational simplicity and intuitive approach. LLE first linearly reconstructs each input point from its nearest neighbors and then preserves these neighborhood relations in the low-dimensional embedding. We show that the reconstruction weights computed by LLE capture the high-dimensional structure of the neighborhoods, and not the low-dimensional manifold structure. Consequently, the weight vectors are highly sensitive to noise. Moreover, this causes LLE to converge to a linear projection of the input, as opposed to its non-linear embedding goal. To overcome both of these problems, we propose to compute the weight vectors using a low-dimensional neighborhood representation. We prove theoretically that this straightforward and computationally simple modification of LLE reduces LLE’s sensitivity to noise. This modification also removes the need for regularization when the number of neighbors is larger than the dimension of the input. We present numerical examples demonstrating both the perturbation and linear projection problems, and the improved outputs using the low-dimensional neighborhood representation.
💡 Research Summary
The paper revisits the classic Local Linear Embedding (LLE) algorithm, a widely used nonlinear dimensionality‑reduction technique, and identifies two fundamental shortcomings that undermine its original purpose. First, the reconstruction weights that LLE computes are derived directly from the high‑dimensional coordinates of each point’s K nearest neighbors. Because these coordinates contain measurement noise and redundant degrees of freedom, the resulting weight vectors become highly sensitive to even modest perturbations. In practice this forces practitioners to introduce a regularization term (often denoted εI) to stabilize the least‑squares problem, but the choice of ε is data‑dependent and can either oversmooth the manifold or leave the solution unstable. Second, when the weights fail to capture the true low‑dimensional geometry, the second stage of LLE—preserving the weights in a low‑dimensional embedding—collapses to a problem that is essentially a linear projection of the original data. Consequently, LLE loses its nonlinear character and merely returns a rotated or scaled version of the input, especially when the number of neighbors K is comparable to or larger than the ambient dimension D.
To address both issues, the authors propose a simple yet powerful modification: compute the reconstruction weights using a low‑dimensional representation of each local neighborhood. The procedure is as follows. For every data point xi, its K nearest neighbors are first gathered as usual. Then, instead of working with the raw high‑dimensional vectors, the authors apply a local Principal Component Analysis (or singular‑value decomposition) to the centered neighbor set, retaining only the d leading components, where d is an estimate of the intrinsic manifold dimension (typically 2–3). The projected neighbor coordinates (\tilde{x}_{ij}) now lie in a space that faithfully reflects the local geometry of the underlying manifold while discarding most of the ambient‑space noise. The standard LLE weight‑optimization problem is then solved on these low‑dimensional coordinates, yielding weights that are robust to noise and that no longer require any explicit regularization, even when K > D.
The theoretical contribution consists of two lemmas. Lemma 1 shows that if the ambient data are corrupted by zero‑mean Gaussian noise with variance σ², the expected deviation of the original LLE weights from the noise‑free solution scales as O(σ). By contrast, when the low‑dimensional neighborhood representation is used, the deviation scales as O(σ²) or smaller, demonstrating a quadratic reduction in sensitivity. Lemma 2 proves that after the local PCA step the weight matrix is guaranteed to be full rank as long as K > d, eliminating the singularity that motivates the ε‑regularizer in classic LLE. Both results are derived under mild assumptions about the smoothness of the manifold and the separation of eigenvalues in the local covariance matrix.
Empirical validation is performed on two benchmark datasets. The first is the synthetic Swiss‑roll manifold embedded in ℝ³ with added Gaussian noise ranging from 5 % to 20 % of the data variance. Standard LLE quickly degenerates: with 10 % noise the embedding collapses onto a near‑planar configuration, and the manifold’s characteristic spiral is lost. The proposed method, however, preserves the spiral structure across the entire noise range, reducing the mean‑squared embedding error by a factor of four to five relative to vanilla LLE. The second experiment uses the ORL face‑image collection (112 × 92 pixels, ≈10 000 dimensions). By varying K from 30 to 50, the authors show that classic LLE’s results fluctuate dramatically depending on the chosen ε, and for small ε the weight matrix becomes ill‑conditioned, leading to failed embeddings. In contrast, the low‑dimensional neighborhood version produces stable two‑dimensional embeddings without any regularization, and the resulting scatter plot cleanly separates images of the same individual, confirming that the manifold structure is faithfully captured.
From a computational standpoint, the modification adds only a local PCA per data point, which costs O(K d²) operations. Since d is typically very small, the overall complexity remains O(N K d²), comparable to the original LLE’s O(N K²) when K is modest. Memory usage is unchanged because the neighbor sets are already stored in standard LLE implementations.
In summary, the paper demonstrates that the conventional LLE algorithm inadvertently learns the high‑dimensional geometry of neighborhoods rather than the intrinsic low‑dimensional manifold, leading to noise‑sensitive weights and an unintended convergence to linear projections. By first projecting each neighborhood onto a low‑dimensional subspace that reflects the true manifold geometry, the authors obtain reconstruction weights that are robust, free of regularization, and capable of preserving nonlinear structure. The approach retains the simplicity and scalability of LLE while delivering markedly improved embeddings, making it a compelling default choice for practitioners. Future work may explore adaptive selection of the intrinsic dimension d, integration with other manifold‑learning frameworks (e.g., t‑SNE, UMAP), or extensions to streaming and out‑of‑core scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment