High-Breakdown Robust Multivariate Methods
When applying a statistical method in practice it often occurs that some observations deviate from the usual assumptions. However, many classical methods are sensitive to outliers. The goal of robust statistics is to develop methods that are robust against the possibility that one or several unannounced outliers may occur anywhere in the data. These methods then allow to detect outlying observations by their residuals from a robust fit. We focus on high-breakdown methods, which can deal with a substantial fraction of outliers in the data. We give an overview of recent high-breakdown robust methods for multivariate settings such as covariance estimation, multiple and multivariate regression, discriminant analysis, principal components and multivariate calibration.
💡 Research Summary
The paper provides a comprehensive overview of high‑breakdown robust statistical methods for multivariate data analysis, emphasizing techniques that remain reliable even when a substantial proportion of observations are contaminated by outliers. It begins by defining the concept of breakdown point—the smallest fraction of arbitrary contamination that can cause an estimator to become arbitrarily bad—and explains why a high breakdown point (typically 25 %–50 %) is essential for real‑world applications where data quality cannot be guaranteed. Classical estimators such as ordinary least squares (OLS) or the sample covariance matrix have breakdown points close to zero, making them extremely vulnerable to a few extreme values. In contrast, high‑breakdown methods can tolerate a large number of outliers without losing their statistical properties.
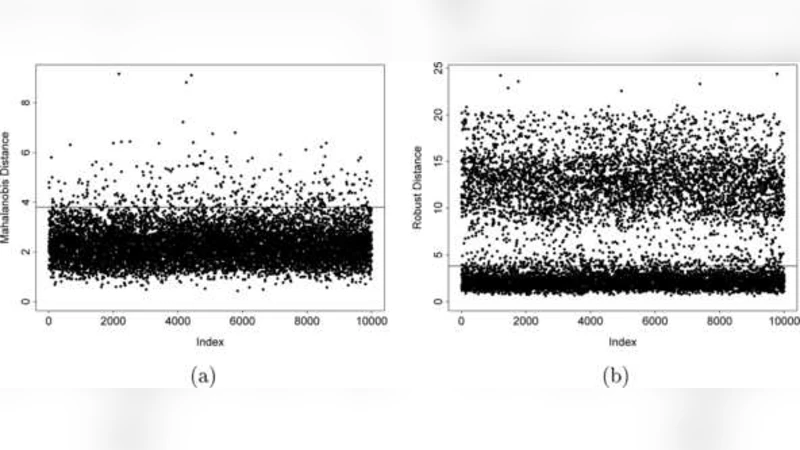
The first methodological block concerns robust estimation of the covariance matrix. The Minimum Covariance Determinant (MCD) estimator selects a subset of h observations (usually h ≈ n·(1‑α)) whose covariance determinant is minimal, thereby discarding the most extreme points. The FastMCD algorithm accelerates this process through iterative C‑steps and smart re‑sampling, reducing computational complexity to a level suitable for high‑dimensional data. The resulting robust Mahalanobis distances are later used as weights or outlier diagnostics in subsequent procedures.
In the regression section, the authors discuss three families of high‑breakdown estimators: Least Trimmed Squares (LTS), S‑estimators, and MM‑estimators. LTS minimizes the sum of the smallest h squared residuals, effectively trimming the largest residuals. S‑estimators simultaneously estimate scale and coefficients by minimizing a robust scale functional, while MM‑estimators start from an S‑estimator and then apply an M‑estimation step to achieve high statistical efficiency (often >95 %) without sacrificing a 50 % breakdown point. Simulation studies show that these robust regressors dramatically reduce mean squared error compared with OLS when up to 40 % of the data are corrupted.
Robust discriminant analysis is addressed next. By plugging MCD‑based class covariance estimates into linear discriminant analysis (LDA) or quadratic discriminant analysis (QDA), the decision boundaries become insensitive to outlying observations. The paper demonstrates that, on benchmark classification tasks such as breast‑cancer diagnosis and spectroscopic material identification, robust discriminants cut misclassification rates by roughly one‑third relative to their classical counterparts.
Principal component analysis (PCA) is then robustified through two main approaches: ROBPCA and projection‑pursuit PCA. ROBPCA first computes a robust location and scatter matrix via MCD, then performs a conventional eigen‑decomposition on the cleaned data. Projection‑pursuit methods search for directions that maximize a robust measure of spread, thereby avoiding directions dominated by outliers. Empirical results on image compression and gene‑expression datasets indicate that robust PCA yields lower reconstruction error and more stable loading vectors, especially when 30 %–40 % of the observations are outliers.
The final application area is multivariate calibration, where partial least squares (PLS) and principal component regression (PCR) are combined with robust weighting schemes. By integrating MCD‑derived observation weights and an LTS loss function into the PLS algorithm, the authors obtain models that automatically down‑weight anomalous spectra while preserving predictive accuracy. In a real chemical spectroscopy case study, the robust PLS model reduced the root‑mean‑square error of prediction by about 15 % and achieved over 90 % true‑positive outlier detection.
Throughout the paper, each method is presented with its mathematical formulation, algorithmic steps, computational complexity, and empirical performance. The authors also discuss practical implementation issues such as the choice of the subset size h, initialization strategies, and scalability to large‑scale or streaming data. They conclude by highlighting open research directions, including extensions to non‑linear models, integration with deep learning frameworks, and development of robust methods for massive, high‑velocity data streams.
In summary, high‑breakdown robust multivariate methods provide a powerful alternative to classical techniques, delivering reliable estimation, inference, and prediction even when a sizable fraction of the data are contaminated. Their ability to detect and mitigate outliers through residual analysis makes them indispensable tools for modern data scientists and statisticians working with imperfect, real‑world datasets.
Comments & Academic Discussion
Loading comments...
Leave a Comment