Verbal Autopsy Methods with Multiple Causes of Death
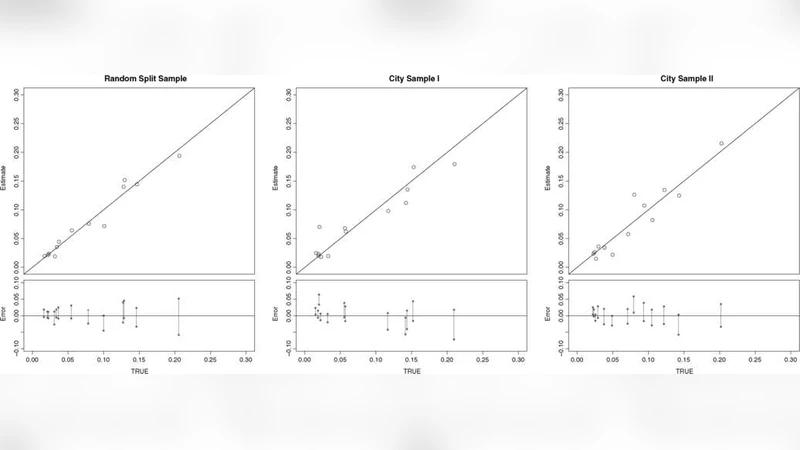
Verbal autopsy procedures are widely used for estimating cause-specific mortality in areas without medical death certification. Data on symptoms reported by caregivers along with the cause of death are collected from a medical facility, and the cause-of-death distribution is estimated in the population where only symptom data are available. Current approaches analyze only one cause at a time, involve assumptions judged difficult or impossible to satisfy, and require expensive, time-consuming, or unreliable physician reviews, expert algorithms, or parametric statistical models. By generalizing current approaches to analyze multiple causes, we show how most of the difficult assumptions underlying existing methods can be dropped. These generalizations also make physician review, expert algorithms and parametric statistical assumptions unnecessary. With theoretical results, and empirical analyses in data from China and Tanzania, we illustrate the accuracy of this approach. While no method of analyzing verbal autopsy data, including the more computationally intensive approach offered here, can give accurate estimates in all circumstances, the procedure offered is conceptually simpler, less expensive, more general, as or more replicable, and easier to use in practice than existing approaches. We also show how our focus on estimating aggregate proportions, which are the quantities of primary interest in verbal autopsy studies, may also greatly reduce the assumptions necessary for, and thus improve the performance of, many individual classifiers in this and other areas. As a companion to this paper, we also offer easy-to-use software that implements the methods discussed herein.
💡 Research Summary
Verbal autopsy (VA) is a widely used tool for estimating cause‑specific mortality in settings where medical certification of death is unavailable. Traditional VA analyses treat each cause of death separately, rely on physician review, expert‑crafted algorithms, or parametric statistical models, and rest on a series of strong assumptions (e.g., symptom independence, cause‑specific conditional independence, and known symptom‑cause probability matrices). These requirements make the methods costly, time‑consuming, and often fragile when the assumptions are violated.
The authors propose a fundamentally different framework that estimates the entire cause‑of‑death distribution simultaneously. They model the observed symptom frequencies in the population as a linear mixture of cause‑specific symptom probability vectors. Formally, let (C) be the number of possible causes and (S) the number of recorded symptoms. For each cause (c), a vector (p_c = P(\text{symptom}=s \mid c)) describes the probability of each symptom given that cause. The population‑level cause‑specific mortality fractions are denoted by (\pi = (\pi_1,\dots,\pi_C)). The observed symptom distribution (f) then satisfies
\
Comments & Academic Discussion
Loading comments...
Leave a Comment