Accuracy in Spreadsheet Modelling Systems
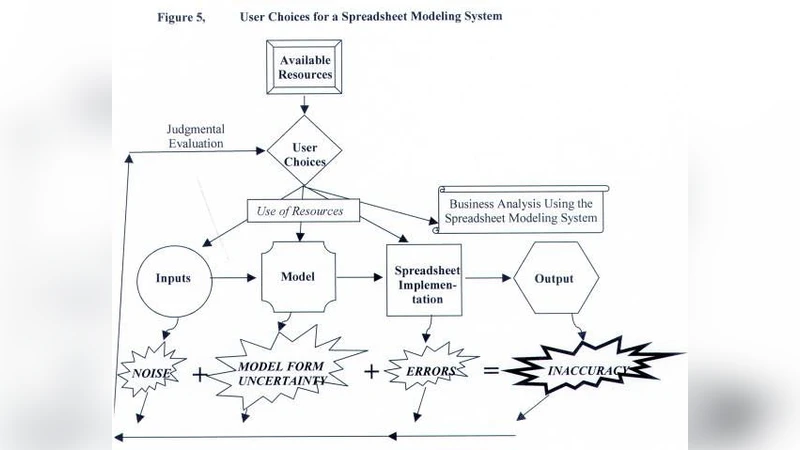
Accuracy in spreadsheet modelling systems can be reduced due to difficulties with the inputs, the model itself, or the spreadsheet implementation of the model. When the “true” outputs from the system are unknowable, accuracy is evaluated subjectively. Less than perfect accuracy can be acceptable depending on the purpose of the model, problems with inputs, or resource constraints. Users build modelling systems iteratively, and choose to allocate limited resources to the inputs, the model, the spreadsheet implementation, and to employing the system for business analysis. When making these choices, users can suffer from expectation bias and diagnosis bias. Existing research results tend to focus on errors in the spreadsheet implementation. Because industry has tolerance for system inaccuracy, errors in spreadsheet implementations may not be a serious concern. Spreadsheet productivity may be of more interest.
💡 Research Summary
The paper “Accuracy in Spreadsheet Modelling Systems” offers a nuanced view of why spreadsheet‑based decision models often deviate from an ideal of perfect numerical correctness. It argues that inaccuracy can arise at three distinct stages: (1) the input stage, where raw data may be incomplete, outdated, or contaminated; (2) the modelling stage, where the underlying mathematical or logical representation may be based on inappropriate assumptions, oversimplifications, or insufficient domain knowledge; and (3) the implementation stage, where the translation of the model into spreadsheet formulas, macros, and cell references can introduce classic spreadsheet errors such as broken links, mis‑typed formulas, or hidden circular references.
A central contribution of the article is the recognition that, in many real‑world contexts, the “true” output of a model is unknowable. Consequently, accuracy cannot be measured solely by objective error metrics; instead, practitioners must rely on subjective judgments about whether the model’s results are “good enough” for the intended purpose. The authors introduce the concept of “subjective accuracy assessment,” emphasizing that acceptable error thresholds are driven by the model’s purpose (e.g., strategic scenario analysis versus detailed financial forecasting), the quality of the available inputs, and the organization’s resource constraints (time, staff, budget).
The paper further describes how users allocate limited resources across four competing activities: (a) cleaning and enriching input data, (b) refining the conceptual model, (c) perfecting the spreadsheet implementation, and (d) applying the model’s outputs to business analysis. Because resources are finite, users inevitably make trade‑offs, and the allocation decisions are vulnerable to two well‑documented cognitive biases. Expectation bias leads users to interpret data and model behaviour in ways that confirm pre‑existing beliefs, often resulting in selective data cleaning or model tweaking that masks underlying problems. Diagnosis bias causes users to mis‑attribute the source of an error—e.g., blaming bad inputs when the real cause lies in a flawed model assumption—thereby prompting inefficient corrective actions.
In reviewing the existing literature, the authors note that most academic work on spreadsheet risk focuses almost exclusively on implementation errors. While such errors are certainly detectable with audit tools and training, the paper argues that industry practice tolerates a certain level of inaccuracy because the primary value of spreadsheets lies in speed, flexibility, and the ability to support rapid “what‑if” exploration. In many organizations, a model that is 95 % accurate but can be built and updated within hours is preferred to a perfectly accurate model that takes weeks to develop and maintain. Consequently, the authors suggest that research should shift its emphasis from exhaustive error elimination toward enhancing spreadsheet productivity.
The paper proposes two forward‑looking research agendas. First, it calls for the development of productivity‑oriented tools—version‑control systems, collaborative editing platforms, reusable template libraries, and automated documentation generators—that help teams iterate faster while keeping a clear audit trail. Second, it recommends the design of decision‑support frameworks that explicitly surface the trade‑offs between input quality, model fidelity, implementation effort, and analysis depth, thereby helping users recognize and mitigate expectation and diagnosis biases.
In summary, the authors contend that spreadsheet modelling accuracy is a multi‑dimensional construct shaped by data quality, model design, and implementation practices, all filtered through subjective judgments about acceptable error. In practice, organizations often prioritize “good enough” accuracy and rapid insight generation over absolute numerical precision. Effective management of spreadsheet modelling therefore requires a balanced allocation of resources, awareness of cognitive biases, and tools that boost productivity rather than merely hunting for the last remaining formula error.
Comments & Academic Discussion
Loading comments...
Leave a Comment