In-depth analysis of the Naming Game dynamics: the homogeneous mixing case
Language emergence and evolution has recently gained growing attention through multi-agent models and mathematical frameworks to study their behavior. Here we investigate further the Naming Game, a model able to account for the emergence of a shared vocabulary of form-meaning associations through social/cultural learning. Due to the simplicity of both the structure of the agents and their interaction rules, the dynamics of this model can be analyzed in great detail using numerical simulations and analytical arguments. This paper first reviews some existing results and then presents a new overall understanding.
💡 Research Summary
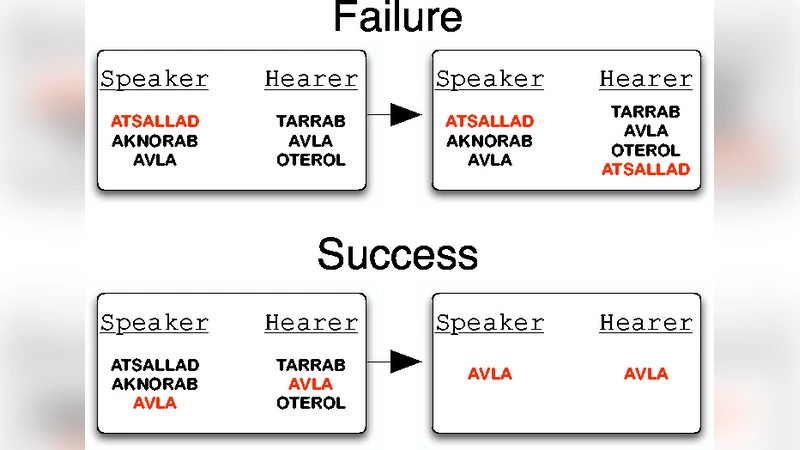
The paper presents a thorough investigation of the Naming Game—a minimalist multi‑agent model of cultural language emergence—under the assumption of homogeneous mixing, i.e., every pair of agents can interact with equal probability. Each agent possesses an inventory of form‑meaning pairs (initially empty). At each discrete time step two agents are randomly chosen: the speaker either invents a new word (if its inventory is empty) or selects one of its known words uniformly at random; the hearer either already knows the transmitted word (success) or does not (failure). In a successful interaction both agents delete all words except the winning one; in a failure the hearer adds the new word to its inventory.
The authors first define three macroscopic observables: the total number of words present in the system N_w(t), the number of distinct words N_d(t), and the instantaneous success rate S(t). Numerical simulations for populations up to N=10^3 reveal a characteristic trajectory: an early transient of rapid word invention, a long plateau where N_w grows while N_d stays roughly constant around N/2, and a sharp rise of S(t) that coincides with the peak of N_w. After the peak, N_w and N_d both decrease, and the system finally reaches the absorbing consensus state (N_w=N, N_d=1, S=1) where every agent uses the same unique word. The early linear growth of the success rate, S(t)≈t/N², is explained by the fact that successful interactions can only occur between pairs that have already met; the number of such pairs grows proportionally to t, while the total number of possible pairs is N(N‑1)/2.
A central contribution of the work is the scaling analysis with respect to the population size N. The authors measure four quantities: the time t_max at which N_w reaches its maximum, the height N_max = N_w(t_max), the convergence time t_conv (when consensus is reached), and the difference Δt = t_conv – t_max. All four follow power‑law dependences N^α, N^γ, N^β, and N^δ respectively, with exponents α≈β≈γ≈δ≈1.5. To rationalise these exponents, they assume that at the peak each agent’s inventory contains on average c N^a words. By writing a mean‑field rate equation for dN_w/dt that balances the increase due to failed interactions (∝1) and the decrease due to successful ones (∝2c N^a/N), they obtain a condition that forces a=½, which yields α=3/2. The same reasoning applied to the success rate’s linear regime reproduces γ=3/2 for the peak height. Thus the observed scaling is a direct consequence of the simple stochastic rules and the homogeneous mixing hypothesis.
Beyond the main scaling laws, the paper uncovers a “hidden timescale” Δt that governs the final burst of consensus. After the peak, a small subset of words survives; stochastic fluctuations break the symmetry among them, leading to a rapid cascade where one word dominates. This symmetry‑breaking process is analogous to phase transitions in opinion dynamics and explains why the success rate exhibits an S‑shaped curve.
The authors also examine properties of the consensus word (frequency distribution, robustness) and discuss how the model’s behavior changes when the underlying interaction network is altered (e.g., lattices, complex networks). They find that the homogeneous mixing case provides a baseline: deviations from the N^1.5 scaling appear only when the network introduces strong locality or heterogeneity.
In the concluding section the paper connects the Naming Game to broader fields. It highlights parallels with models of opinion formation, where agents adopt states through pairwise persuasion, and with artificial intelligence research on decentralized coordination among robots or software agents. The simplicity of the rules makes the model readily implementable in real‑world multi‑robot experiments, while the analytical tractability offers a valuable test‑bed for studying how local cultural learning can give rise to global linguistic order.
Overall, the study delivers a comprehensive quantitative picture of the Naming Game under homogeneous mixing, elucidating the mechanisms that drive vocabulary invention, competition, and eventual consensus, and providing scaling laws and hidden‑timescale insights that are likely to inform future work in sociolinguistics, statistical physics of social systems, and distributed AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment