Text Data Mining: Theory and Methods
This paper provides the reader with a very brief introduction to some of the theory and methods of text data mining. The intent of this article is to introduce the reader to some of the current methodologies that are employed within this discipline area while at the same time making the reader aware of some of the interesting challenges that remain to be solved within the area. Finally, the articles serves as a very rudimentary tutorial on some of techniques while also providing the reader with a list of references for additional study.
💡 Research Summary
The paper “Text Data Mining: Theory and Methods” serves as a concise yet comprehensive introduction to the field of text data mining, targeting readers who are new to the discipline while also highlighting ongoing challenges that remain unsolved. It begins by outlining the distinctive characteristics of textual data—its unstructured nature, high dimensionality, linguistic variability, and semantic richness—and explains why traditional data‑mining techniques cannot be directly applied without adaptation. The authors then detail the essential preprocessing pipeline, covering tokenization, morphological analysis, normalization, stop‑word removal, stemming, and lemmatization. Special attention is given to language‑specific considerations, contrasting the processing of English with that of morphologically rich languages such as Korean, and recommending tools and best‑practice heuristics for each step.
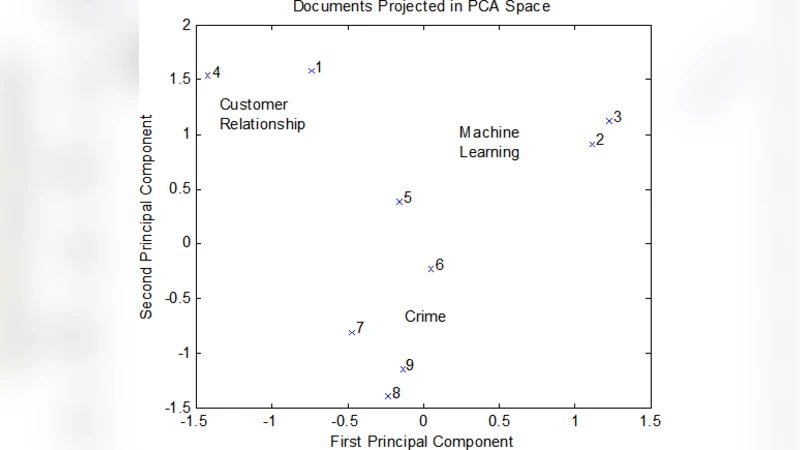
Following preprocessing, the paper surveys feature extraction methods. The classic Bag‑of‑Words (BoW) model and its TF‑IDF weighting scheme are presented as baseline approaches, with a discussion of their sparsity and the consequent need for dimensionality reduction. The authors describe latent semantic analysis (LSA) based on singular value decomposition and latent Dirichlet allocation (LDA) as probabilistic topic‑modeling alternatives. For LDA, both variational inference and Gibbs sampling are compared, and the authors discuss scalability strategies—including online variational Bayes and distributed sampling—that enable application to massive corpora. Word‑embedding techniques such as Word2Vec and GloVe are introduced as modern alternatives that capture semantic similarity in dense vector spaces, and the paper briefly touches on contextual embeddings (e.g., BERT) that have reshaped downstream tasks.
The third section focuses on application domains. In sentiment analysis, the paper contrasts traditional classifiers (Naïve Bayes, support vector machines) with deep learning architectures (CNNs, RNNs, and especially Transformer‑based models). It emphasizes the transfer‑learning paradigm where large‑scale pretrained language models are fine‑tuned on relatively small labeled datasets, achieving state‑of‑the‑art performance with reduced annotation effort. For document classification, the authors discuss supervised learning pipelines, feature selection techniques, and evaluation metrics such as accuracy, F1‑score, and macro‑averaged measures. Unsupervised clustering methods—including K‑means, hierarchical clustering, and topic‑model‑driven clustering—are examined, with guidance on interpreting cluster quality using silhouette scores and perplexity. Information retrieval and question‑answering are mentioned as advanced use‑cases that benefit from vector‑space indexing and neural re‑ranking.
The final part of the paper identifies four major research challenges that continue to shape the field. First, multilingual and code‑switching text processing demands models that can handle mixed‑language inputs without sacrificing accuracy. Second, bias and shallow semantics remain problematic; models often inherit societal biases present in training data and may fail to capture nuanced contextual meaning. Third, real‑time streaming text analytics requires efficient, low‑latency architectures capable of processing high‑velocity data streams while maintaining model freshness. Fourth, privacy and ethical considerations call for techniques such as differential privacy, federated learning, and robust de‑identification to protect sensitive information. For each challenge, the authors cite recent advances—multilingual BERT, debiasing regularizers, streaming‑compatible transformer variants, and privacy‑preserving training frameworks—and propose future research directions, including multimodal integration, continual learning, and explainable text mining.
In summary, the paper delivers a balanced blend of theoretical foundations, practical implementation guidance, and forward‑looking research insights. It equips newcomers with the essential concepts and toolkits needed to embark on text mining projects, while also providing seasoned researchers with a concise roadmap of unresolved issues and emerging opportunities in the rapidly evolving landscape of textual data analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment