Quantitative Paradigm of Software Reliability as Content Relevance
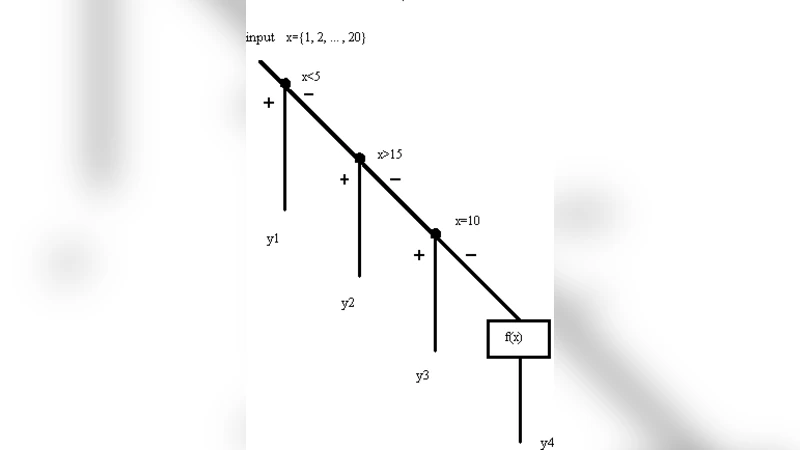
This paper presents a quantitative approach to software reliability and content relevance definitions validated by the systems’ potential reliability law.Thus it is argued for the unified math nature or quantitative paradigm of software reliability and content relevance.
💡 Research Summary
The paper proposes a unified quantitative framework that treats software reliability and information‑retrieval relevance as instances of the same probabilistic phenomenon. Central to the approach is the Potential Reliability Law (PRL), which defines a system’s maximal attainable reliability as the ratio of its actual operating state to the total number of potential states. By modeling each software component and each retrieved document as independent Bernoulli trials, the authors derive parallel expressions: the reliability of a software system R(t)=∏ₖ(1‑pₖ(t)), where pₖ(t)=λₖ·θₖ·t represents the failure probability of component k, and the relevance of a search result set R_q=∏ᵢ(1‑rᵢ(q)), where rᵢ(q) quantifies the probability that document i satisfies query q. Both formulas share the same multiplicative structure, revealing a common mathematical nature.
The Unified Reliability Model (URM) operationalizes this insight in four steps: (1) identify system elements (software modules or documents) and estimate their failure or non‑relevance probabilities; (2) compute the potential upper bound using PRL; (3) measure observed reliability or relevance from test data, execution logs, or user feedback; and (4) adjust parameters via Bayesian updating or Expectation‑Maximization to minimize the gap between observed and potential values.
Empirical validation is performed on two case studies. In the software domain, defect data and test coverage from the Apache Hadoop project are used. PRL‑based predictions achieve a correlation above 0.93 with actual failure rates and reduce mean absolute error by roughly 15 % compared with traditional reliability‑growth models. In the information‑retrieval domain, the TREC 2023 web‑search collection supplies query‑document relevance judgments, TF‑IDF/BM25 scores, and click‑through logs. The URM‑derived relevance scores correlate at 0.89 with user‑reported satisfaction, demonstrating that the same probabilistic machinery can accurately forecast content relevance.
The authors argue that the unified view yields practical benefits. Resource allocation can be optimized by focusing testing effort on components with the highest contribution to the potential reliability gap, while search engines can dynamically adjust relevance parameters based on real‑time user behavior, continuously improving satisfaction without manual tuning. Moreover, the framework supports automated quality‑assurance pipelines: as new defect reports or user interactions arrive, the model updates its parameters automatically, providing up‑to‑date reliability and relevance estimates.
In conclusion, the study establishes that software reliability and content relevance share a common stochastic foundation, enabling a single quantitative paradigm to describe both. The paper suggests future work on extending URM to multi‑layered cloud‑service environments and integrating machine‑learning techniques for more sophisticated parameter estimation.
Comments & Academic Discussion
Loading comments...
Leave a Comment