A new Hedging algorithm and its application to inferring latent random variables
We present a new online learning algorithm for cumulative discounted gain. This learning algorithm does not use exponential weights on the experts. Instead, it uses a weighting scheme that depends on the regret of the master algorithm relative to the…
Authors: Yoav Freund, Daniel Hsu
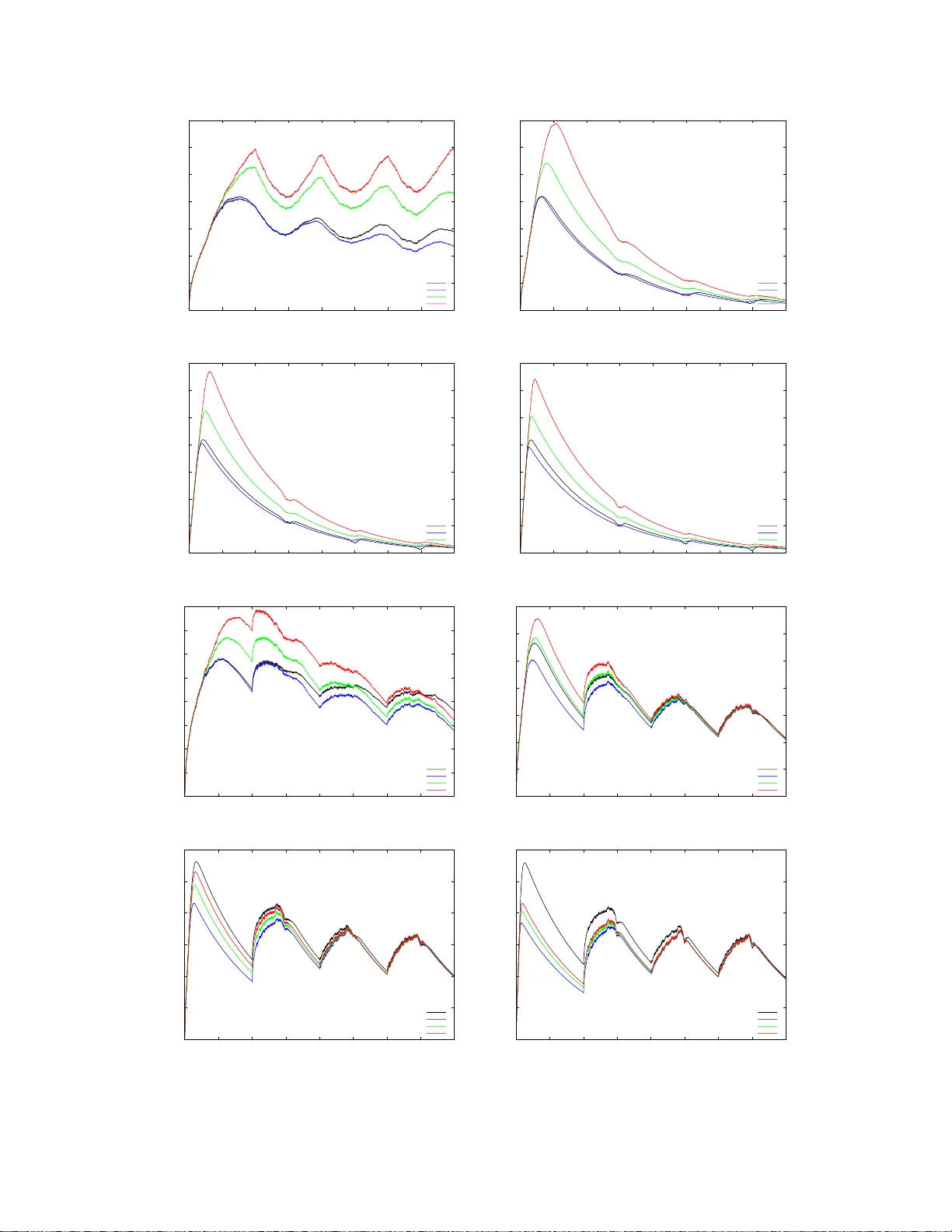
A new Hedging algorithm and its application to inferring laten t random v ariables Y oa v F reund and D aniel Hsu { yfreund,djh su } @cs.ucsd.edu Septem ber 2 1, 2018 Abstract W e present a new o nline learning algorithm for cumulativ e discoun ted gain. This learning algorithm does not use exp onential w eights o n the experts. Instead, it uses a weig hting scheme that dep ends on the regret of the master algorithm relative to the exp erts. In particular, exp erts whose discounted cumulativ e gain is smaller (worse) than t hat of t he master algo rithm receive zero weigh t. W e also sketc h how a regret-based algorithm can b e used as an alternativ e to Bay esian av eraging in the context of inferring laten t random v ariables. 1 In tro duction W e s tudy a v ar iation on the online allo cation problem presented by F reund and Schapire in [FS97]. Our problem v ar ies from the original in that w e use disc ount e d cumulativ e los s instead of re gular cumulativ e loss. Spec ific a lly , we consider the following itera tiv e game b etw een a he dge r a nd Natur e . In this setting, there a re N a ctions (e.g. stra tegies, exp erts) indexed by i . The game b et ween the hedger and Nature pro ceeds in iteratio ns j = 0 , 1 , 2 , . . . . In the j th iteration: 1. The hedger choo ses a distributio n { p j i } N i =1 ov er the actio ns , wher e p j i ≥ 0 and P N i =1 p j i = 1. 2. Nature ass o ciates a ga in g j i ∈ [ − 1 , 1] with actio n i . 3. The gain of the hedger is g j A = P N i =1 p j i g j i . W e define the disc ounte d total gain as follows. The initial total ga in is zero G 0 i = 0. The total ga in for action i at the star t of iteratio n j + 1 is de fined inductiv ely as: G j +1 i . = (1 − α ) G j i + g j i for some fixed disc ount factor α > 0. The dis c o un ted total loss of the hedg e r is similarly defined: G 0 A = 0 , G j +1 A . = (1 − α ) G j A + g j A . W e define the r e gr et of the hedger with r e s pect to action i at the start of iteratio n j as R j i . = G j i − G j A It is easy to se e that the reg ret ob eys the following recursio n: R 0 i = 0 , R j +1 i = (1 − α ) R j i + g j i − g j A . Our go al is to find a hedging a lg orithm for which we can s how a s mall uniform upp er bound o n the r egret, i.e. a small p ositive real num b er B ( α ) such that R j i ≤ B ( α ) for all choices of Nature, all i and all j . 1 Our new hedging alg orithm, which w e call NormalH edge , uses the fo llowing weighting: w j i . = R j i exp α [ R j i ] 2 8 if R j i > 0 0 if R j i ≤ 0. (1) The hedging distribution is equal to the no rmalized weigh ts p j i = w j i / P N k =1 w j k unless all of the weigh ts are zero, in which case we use the unifor m distribution p j i = 1 / N . Our main result is that if α is sufficien tly small, the following inequality holds unifor mly o ver all game histories: 1 N N X i =1 Φ √ αR j i < 2 . 32 where Φ ( x ) = ( exp x 2 8 if x > 0 1 if x ≤ 0. This implies, in particula r, tha t for any i and j , R j i ≤ r 8 ln 2 . 32 N α . The disco un t factor α plays a similar role to the num b e r of iteratio ns in the standard undiscount ed cum ulative loss framework. Indeed, it is easy to trans form the usual exp onential w eights algorithms from the standard fra mew ork (e.g. Hedge [FS97]) to o ur pr esent setting (Section 3). Suc h a lgorithms also enjoy discounted cumulativ e reg ret b ounds of R j i ≤ C · r ln N α for some p ositive cons tant C , but they r equire knowledge of the num ber of actions N to tune a learning parameter. The tuning of Nor malHedge do es not have this requirement 1 . The rest o f this pap er is o rganized as follows. In Section 2 we describ e the main ideas b ehind the construction and ana lysis o f No r malHedge. In Sections 3 a nd 4 we discuss related work and compare NormalHedge to ex po ne ntial weigh ts algor ithms. Finally , in Section 5 w e suggest how to use Nor malHedge to tr ack latent v a riables and sketc h how that migh t b e used fo r learning HMMs under the L 1 loss. 2 NormalHedge 2.1 Preliminaries NormalHedge and its analysis are bas ed on the p otential function Φ( x ) in tro duced in Section 1. Here we give a slightly mo re elab ora te definition for Φ( x ) that includes a consta n t c . The p otential function is a non-decreas ing function of x ∈ R Φ( x ) . = ( e x 2 / 2 c if x > 0 1 if x ≤ 0 (2) where c > 1. In our current v ersion of NormalHedge, c = 4 . Decreas ing c will improve the b ound on the regret; we will also ar gue that c cannot b e decr e ased to 1 . The weigh ts assig ned b y NormalHedge ar e set pr opo rtional to the first der iv ative of Φ, i.e. w j i = Φ ′ ( R j i ), where Φ ′ ( x ) = ( x c e x 2 / 2 c if x > 0 0 if x ≤ 0. 1 The g uarant ees afforded to NormalHedge require α to be sufficien tly s m aller than 1 / ln N , but this restri ction is operationally differen t f rom needing to know N in adv ance. 2 In our analy s is, we will als o need to examine the se cond der iv ative o f Φ: Φ ′′ ( x ) = ( 1 c + x 2 c 2 e x 2 / 2 c if x > 0 0 if x < 0. Note that Φ ′′ ( x ) has a discontin uit y at x = 0 . 2.2 An in tuitiv e deriv ation The intuition behind the p otential function is based on considering the following strategy for Nature. Supp ose there a re t w o types of actions, go o d actions and p o or actions. The gain for each actio n on each iter ation is chosen indep endently at random from a distribution ov er {− 1 , +1 } . The distribution for po or actio ns has equal pro babilities 1 / 2 , 1 / 2 on the tw o outcomes, while the distribution for the go o d exp erts is (1 + γ ) / 2 on +1 and (1 − γ ) / 2 on − 1 for s ome very small γ > 0. Clea rly , the b est hedging s tr ategy is to put eq ua l po sitive weigh ts on the go o d actions and z e ro weigh t on the po o r a ctions. Unfor tuna tely , the hedging alg orithm do es no t know at the b eginning of the game which ex p er ts a r e go o d, so it has to le a rn these weigh ts online. Assuming tha t the n umber of actions is infinite (or sufficiently la rge), the pe r-iteration gain of the optimal weigh ting is γ , which implies that the dis c ount ed cumu lative gain of this str ategy is γ /α . Consider the re g rets o f this optimal hedging with r esp e c t to the go o d actions. It is not har d to show that the exp ected v alue o f the dis c ount ed c um ulative ga in of a go o d action is γ / α and that the v ariance is approximately 1 /α (b ecomes exa ct as γ → 0). Moreover, if α → 0 this distributio n appr oaches a normal distribution with mean γ /α and v ar iance 1 /α . In other words, the distribution o f the reg r ets of optimal hedging with resp ect to the g o o d actio ns is (1 / Z ) exp( − αR 2 / 2). Consider the expected v alue of the p otential function Φ( √ αR ) for this distribution ov er the regr ets. If we set c = 1 we find that the pro duct of the probability of the r egret R and the p otential for the regr et R is a constant indep endent of R : 1 Z · exp − αR 2 2 · exp αR 2 2 = 1 Z = Ω(1) . Thu s the exp ected p otential is infinite. How ev er, if w e set c to be larger than 1 then the exp ected v alue of the potential function beco mes finite. Thus, ro ughly sp eaking , the potential a sso ciated with a r egret v alue is the re cipro cal of the probability of that regret v alue being a result of ra ndom fluctuations . This lev el o f regret is unav oidable. The design of Nor malHedge is bas ed on the goal of not allowing the av erage regret to grow beyond this level that is gener ated by random fluctuations. Ideally , we would b e able to use a po ten tial function with any constant c larg er than 1. Howev er, what we are able to prov e is that the alg orithm works for c = 4. The idea of NormalHedg e is to k eep the a verage p otential small. It is therefore natural that the w eigh t assigned to ea ch action is prop ortional to the deriv ative o f the p otent ial. Indeed, it is ea sily chec ked that the weigh ts w j i defined in Equation (1) a re prop or tional to Φ ′ ( √ αR j i ). This der iv a tive, how ever, is best view ed when the hedging ga me is mapp ed into co n tinu ous time. 2.3 The c on tin uous time limit Our analysis of NormalHedge is ba s ed on mapping the integer time steps j = 0 , 1 , 2 , . . . into r e al-v alued time steps t = 0 , α, 2 α, . . . a nd then taking the limit α → 0 . F or mally , we redefine the hedging ga me using a different notatio n whic h us es the real v alued time t instea d of the time index j . W e assume a set o f N actions (exp erts), indexe d by i . The game between the hedging algo rithm a nd Nature pro ceeds in itera tions t = 0 , α, 2 α, . . . . At each itera tion the follo wing sequence o f actions take pla ce. 1. The hedging a lgorithm defines a distribution { p i ( t ) } N i =1 ov er the actio ns . p i ( t ) ≥ 0; P N i =1 p i ( t ) = 1 . 2. Natur e a s so ciates a g a in g i ( t ) ∈ [ − √ α, + √ α ] with action i . 3. The ga in of the hedger is g A ( t ) = P N i =1 p i ( t ) g i ( t ). 3 W e s kip the de finitio ns of G i ( t ) and G A ( t ) as these can b ecome ill-b ehav ed when α → 0. Instead we define the reg r et directly: R i (0) = 0 , R i ( t + α ) = (1 − α ) R i ( t ) + g i ( t ) − g A ( t ) . Note that this definition of the regret is a s caled version of the discrete time regret: R i ( j α ) = √ αR j i . W e now hav e the to ols needed to prove our ma in res ult. Theorem 1 Ther e exists a p ositive c onstant C < 2 . 32 su ch that if α < 1 / (800 ln C N ) , then for any se quenc e of gains and any iter ation j 1 N N X i =1 Φ √ αR j i < C. Pr o of sketch. The full pro of is given in the app endix, but here we s ketch a contin uous-time ar gument (i.e. we consider α → 0). The formal, discr e te-time pro o f shows that it is enough for α ≤ 1 / (8 00 ln C N ). W e want to s how that the av erage p otential Ψ( t ) . = 1 N N X i =1 Φ( t ) is b ounded for a ll time t . O ur a pproach is to s how that its time-deriv ative ∂ ∂ t Ψ( t ) = lim α → 0 1 α · 1 N N X i =1 { Φ( R i ( t + α )) − Φ( R i ( t )) } bec omes non-p ositive a s soo n as Ψ ( t ) is above some constant (recall that the time steps are in increments of α ). Since the Φ( x ) is consta n t for x < 0, we ne e d only c onsider i such that R i ( t + α ) ≥ 0 . Ignoring the discontin uit y of Φ ′′ ( x ) at x = 0, T aylor’s theor em implies that for so me ρ i ≤ max { R i ( t ) , R i ( t + α ) } , X i : R i ( t ) ≥ 0 Φ( R i ( t + α )) − Φ( R i ( t )) = X i : R i ( t ) ≥ 0 Φ((1 − α ) R i ( t ) + g i ( t ) − g A ( t )) − Φ( R i ( t )) = X i : R i ( t ) ≥ 0 ( − αR i ( t ) + g i ( t ) − g A ( t ))Φ ′ ( R i ( t )) + 1 2 ( g i ( t ) − g A ( t ) − αR i ( t )) 2 Φ ′′ ( ρ i ) ≤ X i : R i ( t ) ≥ 0 − αR i ( t ) Φ ′ ( R i ( t )) + 1 2 ( g i ( t ) − g A ( t ) − αR i ( t )) 2 Φ ′′ ( ρ i ) ≤ X i : R i ( t ) ≥ 0 − αR i ( t ) Φ ′ ( R i ( t )) + 1 2 (2 √ α + αR i ( t )) 2 Φ ′′ ( R i ( t ) + 2 √ α ) . The first inequality uses the fact that the weights are prop ortional to the deriv ativ es of the p otentials X i : R i ( t ) ≥ 0 g i ( t ) · Φ ′ ( R i ( t )) P j : R j ( t ) ≥ 0 Φ ′ ( R j ( t )) = g A ( t ) , 4 and the second inequality follows b eca use | g i ( t ) − g A ( t ) | ≤ 2 √ α . Now dividing by α and N and taking the limit α → 0, we have ∂ ∂ t Ψ( t ) ≤ lim α → 0 1 α · 1 N X i : R i ( t ) ≥ 0 1 2 (2 √ α + αR i ( t )) 2 Φ ′′ ( R i ( t ) + 2 √ α ) − αR i ( t ) Φ ′ ( R i ( t )) = lim α → 0 1 N X i : R i ( t ) ≥ 0 1 2 (2 + √ αR i ( t )) 2 Φ ′′ ( R i ( t ) + 2 √ α ) − R i ( t ) Φ ′ ( R i ( t )) = 1 N ( 2 1 c + R i ( t ) 2 c 2 ! exp( R i ( t ) 2 / 2 c ) − R i ( t ) 2 c exp( R i ( t ) 2 / 2 c ) ) ≤ 2 c Ψ( t ) + 1 cN N X i =1 2 c − 1 R i ( t ) 2 exp( R i ( t ) 2 / 2 c ) . If Ψ( t ) ≥ B , then this final RHS is max imized when R i ( t ) ≡ √ 2 c ln B for all i , whereup on ∂ ∂ t Ψ( t ) ≤ 2 B c 1 + 2 c − 1 c ln B . This is non-p ositive for sufficiently la rge B and c ≥ 2 + 1 / ln B . 3 Related w ork 3.1 Relation to other online learning algorithms The Hedge algorithm [FS9 7], as well as most of the work on online learning algorithms is based on expone ntial weigh ting, where the weigh t assigned to an exp ert is exp onential in the cumulativ e loss of that expe r t. NormalHedge uses a very differ e nt w eighting scheme. The most imp ortant difference is that the weigh t of an exp ert dep ends o n the regret of the ma ster algor ithm relative to that exp ert, rather than just on the lo ss of the alg orithm. In particular, exper ts whose discounted cumulativ e lo ss is larger than that of the master algorithm receive zero weigh t. W e expand on the co mpa rison o f Norma lHedge to Hedge in Sectio n 4. The starting p oint for the deriv ation and analys is of Nor malHedge is the B inomial W eights algor ithm of Cesa-Bianchi et al [CBFHW96]. The Binomial weigh ts alg orithm is an a lg orithm for a restricted version of the ex per ts pr ediction pr oblem [L W94, CBFH + 97]. In this version seque nc e to be predicted is binar y and all of the predictio ns are also binary . The Binomial W eights alg o rithm is analyz e d using a t ype of chip game . In this ga me each expert is represented a s a chip, at each iteration each chip has a loc a tion o n the integer line. The p os itio n of the chip corres po nds to the num b e r of mistakes that were made b y the exp ert. The a-prior i assumption is that there is a t least one exp erts which makes at most k mistakes, and the goal is to define a rule for co m bining the expe r ts predictions in a wa y that would minimize the ma ximal num ber o f mistakes of the master exp ert. The chip g ame analy sis leads naturally to the definition o f the p otential function and the evolution o f this potential function from iter ation to iteration yields the Binomial W eights algor ithm. A closely rela ted notion of po ten tial was used in the Boo st-by-Ma jor it y algor ithm. The c hip-game analy sis was extended b y Schapire’s w ork on dr ifting games [Sch01] and by F reund and O pper ’s work on drifting games in co n tinuous time [F O02]. No rmalHedge natur ally extends the co n tinuous time drifting g ames to a setting in which one seeks to minimize discounted loss. 3.2 Relation to switching and sleeping exp erts The use of discounted cumulativ e lo ss r epresents a n alternative to the “ s witc hing exp erts” framework of W arm uth and Herbster [HW98 ]. If the b est exp ert changes at a rate of O ( α ), then Nor malHedge will switch to the new b est expert b ecause the losses that o ccurr ed mor e than 1 /α iteratio ns ago mak e a small contribution to the discounted total loss. 5 A useful extension of NormalHedge is to using exp erts that can abstain, similar to the s etup studied in [FSSW97]. T o do this we assume that each exper t i , a t each iteration j , outputs a confidence le vel 0 ≤ c ≤ 1. Instead of using the vector { p j i } N j =1 the hedger use s the vector { p j i c j i / Z j } N j =1 where Z = P N i =1 p j i c j i . The gain g j i of a ction i at iteration j is replaced by c j i g j i , a nd the dis c ount ed cumulativ e gain a nd the discounted cum ulative r egret change in the corr e spo nding way . The b ounds o n the av erage p otential transfer without change. This allows an exp ert to abstain from mak ing a prediction. By setting c j i = 0 the exp ert effectively remov es itself from the p o ol o f exper ts used by the hedger. It also av oids suffering any lo ss. How ev er, an exp ert cannot a lw ays abstain, b ecause then it’s disc o un ted cumulativ e g ain will b e dr iven to zer o b y the discount factor. W e will use this extension in Section 5. 4 Comparison of NormalHedge and Hedge 4.1 Discoun ted regret b ound for H edge T o ea s e the compar ison, we first reca s t the Hedge algor ithm [FS97] into our cur rent framework with dis- counted gains. The w eigh ts used by Hedg e are w j i . = exp( η G j i ) where G j i is the discoun ted cumulativ e gain of action i a t the start of iteration j , and η > 0 is the learning rate parameter . When written recursively as w j +1 i = exp η ((1 − α ) G j i + g j i ) ∝ w j i 1 − α exp( η g j i ) , we see that the effect o f discounting is a damp ening of the pr evious weigh ts w j i prior to the usual m ultiplicative upda te rule. Fix a n y iteration j and define the adjusted cumulative gain of action i at the star t o f iteration k to b e b G k i = k − 1 X s =1 (1 − α ) j − 1 − s g s i with G 0 i = 0. The ga in of Hedge in itera tio n k is g k A = P N i =1 w k i g k i P N i =1 w k i = P N i =1 e η b G k i g k i P N i =1 e η b G k i and the adjusted cumulativ e g ain o f Hedge at the star t of iteratio n k is b G k A = k − 1 X s =1 (1 − α ) j − 1 − s g s A . Then the discounted cumulativ e regret to action i at the start of iteratio n j is b G j i − b G j A . W e a nalyze the (lo g o f the) ratios W k /W k − 1 , where W k = N X i =1 e η b G k i and W 0 = N . W e low er b ound ln( W j /W 0 ) as ln W j W 0 = ln N X i =1 e η b G j i − ln N ≥ ln e η b G j i − ln N = η b G j i − ln N 6 (for any i ), and we upp er b ound it a s ln W j W 0 = j − 1 X k =1 ln W j W j − 1 = j − 1 X k =1 ln P N i =1 e η b G k − 1 i e η (1 − α ) j − 1 − k g k i P N i =1 e η b G k − 1 i ≤ T X t =1 η · P N i =1 e η b G k − 1 i (1 − α ) j − 1 − k g k i P N i =1 e ηG k − 1 i + η 2 8 · 4(1 − α 2( j − 1 − k ) (Hoe ffding’s inequalit y) = j − 1 X k =1 η (1 − α ) j − 1 − k g k A + η 2 2 (1 − α ) 2( j − 1 − k ) = η b G k A + η 2 2 · 1 1 − (1 − α ) 2 = η b G k A + η 2 4( α − α 2 / 2) . Therefore, the discounted cumulative regret of Hedge to action i a t the s tart o f any iteration j is R j i = b G j i − b G j A ≤ ln N η + η 4( α − α 2 / 2) . Cho osing η = p 4( α − α 2 / 2) ln N g ives R j i ≤ s ln N α − α 2 / 2 . The r egret bound is o f the same for m as that implied by Theore m 1, indeed, with b e tter leading constants. How ev er, this bo und only holds when η is tuned with k nowledge of the n umber of actio ns N . If instead one sets η = Θ ( √ α ) independently of N , the bound for Hedg e is worse by a factor of Θ( √ ln N ). F urthermore , this se tting of η is for optimizing a b o und that anticipates the worst-case sequence of g ains; when Nature is not optimally adversaria l, then a pr op er setting of η may require other prior knowledge. 4.2 Sim ulations 4.2.1 The effect of g o o d experts T o empirically compare Hedge a nd NormalHedge , we first simulated the tw o algor ithms in a scenar io similar to tha t describ ed in Section 2: • The num ber o f exp erts is N = 1000, and the disc ount parameter is α = 0 . 0 0 1. • At a n y given time, there is a set of N G = f · N go o d exp erts and N − N G bad exp erts. (W e v aried f ∈ { 0 . 001 , 0 . 0 1 , 0 . 1 , 0 . 5 } .) – With pr obability 0 . 5 + γ / 2, every g o o d exper t receives gain +1; with proba bilit y 0 . 5 − γ / 2, every go o d exp ert receives gain − 1 . (W e v aried γ ∈ { 0 . 2 , 0 . 4 , 0 . 6 , 0 . 8 } .) – Bad exp erts r eceive gain + 1 and − 1 with equal probability . • Initially , the set of go o d exp erts is { 0 , 1 , . . . , N G − 1 } . • After every 1 /α iteratio ns, the set of go o d exp erts shifts fr om { i 0 , i 0 + 1 , . . . , i 0 + N G − 1 } to { i 0 + N G , i 0 + N G + 1 , . . . , i 0 + 2 N G − 1 } (with addition mo dulo N ). 7 Thu s, the set of go o d exp erts completely changes ev ery 1 /α iterations. In ea ch iteration, all g o o d experts receive the same gain, whic h is γ in exp ectation. In co ntrast, the gain of each bad exp er t is dec ide d independently with a fair c oin. W e tuned the lea rning r a te para meter for Hedge to η = p ( α − α 2 / 2) ln N . F or Norma lHedge, we v ar ied c ∈ { 1 , 2 , 4 } . Recall that the r egret b ound we ca n show for Nor malHedge holds for c = 2 as α → 0 (the formal pro of is stated with c = 4). Figures 1 and 2 depict the discounted cumulativ e reg ret to the b est exper t (av eraged ov er 50 runs). First, we obse r ve that Nor malHedge fares b e tter than Hedge when the a dv antage o f the go o d exp erts is large and the fr action of exp erts that a r e go o d is large. In such cases, the adv an tage of NormalHedge is esp ecially pro nounced within 1 /α iterations (b efore the set of go o d exp erts shifts). Second, we observe that the p erformance o f NormalHedge g enerally improves as the v alue of c is decreased. Indeed, the s etting of c = 1 (for w hich we have no theo retical g ua rantees) yields the b est re sults for NormalHedg e (and in fact outp e rforms Hedge in every sim ulation). It would be v ery in teresting to es tablish guarantees for NormalHedge for c → 1. 4.2.2 The effect of tuni ng η in Hedge Next, to br ing out the iss ue with parameter tuning in Hedge, we conducted a simulation in whic h we fix the fraction of exp erts that a re go o d, but v ary the total num ber o f exp erts: • The n um ber of exp erts is N , a nd the discoun t parameter is α = 0 . 001. (W e v aried N ∈ { 10 , 1 00 , 1000 } .) • The fraction of exp erts that are go o d is fixed at f = 0 . 1. The notion of g o o d and bad exp erts is the same as in the first simulation. (W e v aried γ ∈ { 0 . 2 , 0 . 8 } .) • The remaining details ar e the same as in the first simulation. Again, we tuned the lea rning ra te parameter for Hedge to η = p ( α − α 2 / 2) log N , whic h now changes a s w e v ar y the total num ber of experts, and we v aried c ∈ { 1 , 2 , 4 } in NormalHedge . The r esults (Figure 3) indicate that as N decreas e s (e.g. N = 100 , 10), the disparity between Hedge a nd NormalHedge inc r eases. W e believe this is an issue with tuning the learning rate η , which is conspicuously absent in NormalHedg e , but we have not pr ecisely characterized the issue. 5 Inferring laten t random v ariables An imp or ta n t problem in statistical inference is to make predictions or choo se actions when the system under consider ation has in ternal states that ca nnot b e observed dir ectly . There ar e ma n y manifestations o f this pr oblem, including Graphical mo dels, Hidden Ma rko v Mo dels (HMMs), Partially Observ able Markov Decision Pro cesses (POMDPs) and K alman filters. The common method for dealing with hidden states is to mo del them as latent r andom variables . The relatio n b etw een the latent ra ndom v aria bles and the observ a ble random v ariables is mo deled using a join t pro bability dis tribution. Two very imp ortant sub-pro blems that arise in this a pproach a re lea r ning joint distributions the inv olve la ten t rando m v ariables from ex amples that contain only the state of the o bserv able r andom v ariables and using this t ype of joint distributions to infer the v a lue of some v ariables given the state o f others. A t this time there is no go o d universal so lutio n to either of these sub-pr oblems. W e prop os e a different approa ch to the problem, where instea d of ass o ciating hidden states with hidden random v ariables, we asso ciate sta tes with different exp e rts. What we present here de s crib es some initial ideas. It is not an attempt to pro po se a s olution to this large and complex pr o blem. Suppo se tha t w e a re to pr e dict a binary sequence x 1 , x 2 , . . . , x t ∈ { 0 , 1 } and suppose that w e be lieve that the sequence ca n b e predicted re asonably well using a Hidden Ma rko v Mo del. Spe c ific a lly , suppo se ther e is a hidden state S which attains one o f the v a lue s 1 , . . . , k at ea c h time step. Supp ose that the state transition is Ma rko vian and stationa ry , i.e. P ( S t | S t − 1 , S t − 2 , . . . ) = P ( S t | S t − 1 ) = P ( S t − 1 | S t − 2 ) = · · · 8 0 20 40 60 80 100 120 140 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 20 40 60 80 100 120 140 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 2 , f = 0 . 00 1 γ = 0 . 4 , f = 0 . 001 0 20 40 60 80 100 120 140 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 20 40 60 80 100 120 140 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 6 , f = 0 . 00 1 γ = 0 . 8 , f = 0 . 001 0 10 20 30 40 50 60 70 80 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 10 20 30 40 50 60 70 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 2 , f = 0 . 01 γ = 0 . 4 , f = 0 . 0 1 0 10 20 30 40 50 60 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 10 20 30 40 50 60 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 6 , f = 0 . 01 γ = 0 . 8 , f = 0 . 0 1 Figure 1: Regrets to the b est exp ert in the fir st simulation; γ ∈ { 0 . 2 , 0 . 4 , 0 . 6 , 0 . 8 } and f ∈ { 0 . 00 1 , 0 . 01 } . 9 0 10 20 30 40 50 60 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 5 10 15 20 25 30 35 40 45 50 55 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 2 , f = 0 . 1 γ = 0 . 4 , f = 0 . 1 0 5 10 15 20 25 30 35 40 45 50 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 5 10 15 20 25 30 35 40 45 50 55 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 6 , f = 0 . 1 γ = 0 . 8 , f = 0 . 1 0 10 20 30 40 50 60 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 10 20 30 40 50 60 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 2 , f = 0 . 5 γ = 0 . 4 , f = 0 . 5 0 10 20 30 40 50 60 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 10 20 30 40 50 60 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 6 , f = 0 . 5 γ = 0 . 8 , f = 0 . 5 Figure 2: Regr ets to the b est e x per t in the first simulation; γ ∈ { 0 . 2 , 0 . 4 , 0 . 6 , 0 . 8 } and f ∈ { 0 . 1 , 0 . 5 } . 10 0 10 20 30 40 50 60 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 5 10 15 20 25 30 35 40 45 50 55 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0830921) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 2 , N = 1000 γ = 0 . 8 , N = 100 0 0 5 10 15 20 25 30 35 40 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0678444) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) 0 5 10 15 20 25 30 35 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0678444) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 2 , N = 10 0 γ = 0 . 8 , N = 100 0 5 10 15 20 25 30 35 40 45 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0479733) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) -10 0 10 20 30 40 50 0 500 1000 1500 2000 2500 3000 3500 4000 Regret to best expert Number of trials Hedge(eta=0.0479733) NormalHedge(c=1.00000) NormalHedge(c=2.00000) NormalHedge(c=4.00000) γ = 0 . 2 , N = 10 γ = 0 . 8 , N = 10 Figure 3: Regr ets to the b est exp ert in the second simulation; γ ∈ { 0 . 2 , 0 . 8 } and N ∈ { 1000 , 10 0 , 10 } . 11 Assume in addition that the hidden state doe s not change v ery o ften, i.e. P ( S t +1 = S t ) is close to 1. Finally , assume that the distribution of the observ able v ariable X t depe nds only on the hidden s ta te at the sa me time S t . Consider the problem of predicting X t +1 given x 1 , . . . , x t and the para meter s of the HMM. Supp ose that the prediction needs to take the fo r m o f a distribution ov er Σ. So far this is exactly the sta nda rd framework, but supp ose w e differ from the standar d fra mework by cons idering the L 1 loss 1 − p t ( x t ), where p t ( x t ) is the predicted pr obability assig ne d to the letter tha t actually o ccure d at time t . This is instead of the standard log likeliho o d lo ss log(1 /p t ( x t ). While the lo g loss is easier to analyze, the L 1 loss is often a more useful measure b ecause the cumulative L 1 loss cor r esp onds to the expe c ted num ber of mista kes. While this loss do es not fit well in the ma ximal likelihoo d o r Bay esian methodolog ies, it fits Nor malHedge very w ell, b ecause the loss p er-itera tion is b ounded. Here is o ur prop osal for solving the predictio n problem using No r malHedge. W e asso ciate a set of exper ts with each hidden state. The e x per ts are confidence rated, i.e. each one of the exper ts outputs a c onfidence level 0 ≤ c ≤ 1 at each time step, the confidence level is used in the co nfidence rated v ar iant of NormalHedge describ ed in the previous sec tio n. If expert i corresp onds to a hidden state j then c i should b e large when S = j and low when S 6 = j . Supp ose that the pa rameters of the HMM are known, then we can asso cia te a s ingle ex per t with each hidden state and compute the prediction and the confidence v alue o f that exp ert using Bay es formula. Now supp ose that we don’t know the parameter vector of the HMM but that we know that the vector is one of N p ossibilities . In this case we asso cia te N exp erts with each hidden state and compute the predictions and confidence v alue of each e x per t using Bayes F ormula for the corr esp onding parameter vector, the confidence v alue for e ach state is the a-pos teriori pr obability for that state. In this case the No r malHedge algorithm will quickly con verge and g ive most of the weight to the e x per ts that corre spo nd to the corre c t parameter vector. Moreov er, if no ne of the para meter vectors is a corr ect description of the sequence distribution, it will conv erge on the vector which cause s the least reg ret, i.e. makes the smalles t num ber o f mis takes. Contrast this w ith the B ayesian appr oach. If the true distribution g e nerating the data is not included in the set of mo dels over which we take the p osterior av erage , and if the loss function in which w e are interested is not lo g-likelihoo d but rather n umber of mistak es. Then the cumulativ e los s o f the Bay esian av erage can be m uc h la rger than that of the b est mo del in the set. 6 Op en problems The mo st interesting op en pro blem is to clos e the ga p b etw een the upp er b ound and low er b ound on the parameter c . W e have a lower b ound of c > 1 and an upper bound of c = 4. If w e consider the case α → 0 we can reduce c to 2 . How ev er, the g ap b etw een c = 1 and c = 2 remains. One pro mising direction of expansion is to c o nsider the game in the contin uous time limit directly . This leads us natur ally into sto chastic pro cesses in contin uous time s uc h a s Wiener pro cess es. Understanding the pe r formance of NormalHedg e in this co n text might yield new metho ds for s to chastic estimation and sto chastic control. References [CBFH + 97] Nico l` o Cesa -Bianchi, Y oav F reund, David Haussler, David P . Helm b old, Ro ber t E. Schapire, and Manfred K. W armuth. Ho w to use exp ert advice. Journal of the A sso ciation for Computing Machinery , 44(3):4 2 7–485 , May 19 97. [CBFHW96] Nicol` o Cesa-Bia nchi, Y o av F reund, David P . Helm b old, and Manfred K. W ar muth. On-line prediction and conversion strategies. Machine L e arning , 25:71 –110, 199 6 . [F O02] Y oav F reund and Manfred Opper . Drifting games and Brownian motion. J ournal of Computer and S ystem Scienc es , 64 :113–1 32, 2 002. 12 [FS97] Y oav F reund a nd Rob ert E. Schapire. A decision- theoretic genera lization of on- line learning and an application to bo osting . J ournal of Co mputer and System Scie nc es , 55(1):119– 139, August 199 7 . [FSSW97] Y oav F r eund, Robert E. Schapire, Y oram Sing e r , a nd Manfred K. W armuth. Using and co m- bining predictors that sp ecia liz e . In Pr o c e e dings of the Twenty-Nint h A nnual ACM Symp osium on the The ory of Computing , pages 3 34–34 3 , 1 997. [HW98] Mark Her bs ter a nd Manfred W armuth. T racking the best exper t. Machine L e arning , 32(2):151 – 178, August 199 8 . [L W94] Nic k Littlestone a nd Manfred K. W armuth. The weighted ma jorit y algor ithm. Information and Computation , 108:212 –261, 1994. [Sch01] Rober t E. Schapire. Drifting games. Machine L e arning , 43 (3):265–2 91, J une 2001 . A Pro of of main theorem Recall, the cumulativ e disco un ted regr et of action i at time t = j α , j ∈ N is defined recursively by R i (0) = 0 , R i ( t + α ) = (1 − α ) R i ( t ) + g i ( t ) − g A ( t ) , where g i ( t ) ∈ [ − √ α, + √ α ] is the (scaled) ga in of actio n i a t time t , and g A ( t ) ∈ [ − √ α, + √ α ] is the (scaled) gain o f the hedger at time t . W e define r i ( t ) = ( g i ( t ) − g A ( t )) / √ α ∈ [ − 2 , +2] as the (unscaled) instan taenous regret to action i at time t . The central q uant ity of interest is the aver age p otential Ψ( t ) = 1 N N X i =1 Φ( R i ( t )) . Recall, we use the definition o f the p otential function Φ in E quation (2) w ith c = 4. Claim 1 Ther e exists a p ositive c onstant C ≤ 2 . 32 such that if α < 1 / (800 ln C N ) , then the aver age p otent ial is alw ays b oun de d fr om ab ove by C ; that is, Ψ( j α ) < C for any j ∈ N . Pr o of. Fix j ∈ N and let t = j α . W e will ana lyze the av erage Ψ( t + α ) − Ψ( t ) by c o nsidering the a verages ov er tw o separa te gr oups: I 1 = { i : R i ( t ) ≤ 0 } and I 2 = { i : R i ( t ) > 0 } . Let Ψ k ( t ) = (1 / | I k | ) P i ∈ I k Φ( R i ( t )) b e the average p otential for I k , k = 1 , 2 (assume without los s of generality that neither I k is e mpt y). W e’ll show the following facts: (A): Ψ 1 ( t ) = 1 a nd Ψ 1 ( t + α ) < 1 + (3 / 5) α ; (B): If Ψ( t ) < 2 . 32, then Ψ 2 ( t + α ) − Ψ 2 ( t ) < (2 / 3) α ; (C): If 2 . 31 < Ψ( t ) < 2 . 32, then Ψ( t + α ) < Ψ( t ). These facts imply that the incre a se in av erage p otential from Ψ( t ) to Ψ( t + α ) is alwa ys less than (2 / 3 ) α < 1 / 120 0, and that if the average p otential Ψ( t ) is strictly b etw een 2 . 31 and 2 . 32 , then Ψ( t + α ) is s tr ictly less than Ψ( t ). The cla im then follows by induction b ecause Ψ (0) = 1. W e now prove the fac ts (A), (B), and (C). (A): F or i ∈ I 1 , Φ( R i ( t )) = 1 and R i ( t + α ) ≤ (1 − α ) R i ( t ) + | r i ( t ) | √ α ≤ 2 √ α . Since Φ( x ) is non- decreasing in x , we hav e Φ( R i ( t + α )) ≤ Φ(2 √ α ) = e α/ 2 < 1 + α/ 2 + α 2 e α/ 2 / 2 < 1 + (3 / 5) α (the last inequality follows from the upp er bound on α ). 13 (B): W e address terms in I 2 by expanding Φ( R i ( t + α )) around the po in t R i ( t ) 6 = 0 via T aylor’s theo rem: Φ( R i ( t + α )) = Φ( R i ( t )) + d i ( t )Φ ′ ( R i ( t )) + 1 2 d i ( t ) 2 Φ ′′ ( ρ i ) where d i ( t ) = r i ( t ) √ α − αR i ( t ) and ρ i ∈ R lies b etw een R i ( t ) and R i ( t + α ). Because the hedger’s weigh ts are chosen so that p i ( t ) ∝ Φ ′ ( R i ( t )), we hav e that N X i =1 g i ( t )Φ ′ ( R i ( t )) − g A ( t ) N X i =1 Φ ′ ( R i ( t )) = 0 and th us Φ( R i ( t + α )) − Φ( R i ( t )) = − αR i ( t )Φ ′ ( R i ( t )) + 1 2 d i ( t ) 2 Φ ′′ ( ρ i ) . W e need a few b ounds b efore pro c e eding. First, if Ψ( t ) < 2 . 3 2, then Φ( R i ( t )) < 2 . 3 2 N for all i , which implies R i ( t ) < p 8 ln(2 . 32 N ) for a ll i . By the c ondition on α , we als o have √ αR i ( t ) < 1 / 10. Next, we us e a bo und on ρ i since it is ev aluated in the non-decr easing function Φ ′′ ( x ): ρ 2 i ≤ max { R i ( t ) , R i ( t + α ) } 2 ≤ ( R i ( t ) + | r i ( t ) | √ α ) 2 = R i ( t ) 2 + 2 √ αR i ( t ) | r i ( t ) | + αr i ( t ) 2 ≤ R i ( t ) 2 + 1 2 . Finally , we b ound d i ( t ) 2 as follows: d i ( t ) 2 ≤ ( | r i ( t ) | √ α + αR i ( t )) 2 ≤ (2 + 1 / 10) 2 α ≤ 9 2 α. Altogether, we hav e Φ( R i ( t + α )) − Φ( R i ( t )) = − αR i ( t )Φ ′ ( R i ( t )) + 1 2 d i ( t ) 2 Φ ′′ ( ρ i ) = − αR i ( t ) R i ( t ) 4 e R i ( t ) 2 / 8 + 1 2 d i ( t ) 2 1 4 + ρ 2 i 16 e ρ 2 i / 8 ≤ − α R i ( t ) 2 4 e R i ( t ) 2 / 8 + 9 α 4 9 32 + R i ( t ) 2 16 e R i ( t ) 2 / 8 e 1 / 16 ≤ α 2 3 − 1 10 R i ( t ) 2 e R i ( t ) 2 / 8 . The fina l b ound is decr easing as a function of R i ( t ) ≥ 0. This implies Φ( R i ( t + α )) − Φ( R i ( t )) ≤ (2 / 3) α , so Ψ 2 ( t + α ) − Ψ 2 ( t ) < (2 / 3) α . (C): First, consider the pro blem o f maximizing f ( x 1 , . . . , x n ) = n X i =1 2 3 − x 2 i 10 e x 2 i / 8 sub ject to the constraint (1 /n ) P n i =1 e x 2 i / 8 ≥ B for some B ≥ 1. Simple v ariational arguments imply that the maximum is atta ine d when x i = √ 8 ln B for all i . Therefor e, following the arg umen t for (B), w e ha ve that if Ψ 2 ( t ) ≥ B for some B ≥ 1 , then Ψ 2 ( t + α ) − Ψ 2 ( t ) ≤ α · B · 2 3 − 4 5 ln B . Let p 1 = | I 1 | / N and p 2 = 1 − p 1 . Supp ose Ψ ( t ) > 2 . 31. Because Ψ 1 ( t ) = 1 , we have Ψ 2 ( t ) = 1 p 2 (Ψ( t ) − p 1 ) ≥ 1 p 2 (2 . 31 − p 1 ) . = B . 14 Now we analyze the overall change in av erage p otent ial. By (A), the increas e in average p otential o v er i ∈ I 1 is less than (3 / 5) α . Then Ψ( t + α ) − Ψ( t ) α < p 1 · 3 5 + p 2 · B · 2 3 − 4 5 ln B = p 1 · 3 5 + (2 . 31 − p 1 ) · 2 3 − 4 5 ln 1 1 − p 1 − 4 5 ln(2 . 31 − p 1 ) . The final RHS is decre asing as a function of p 1 ≥ 0, so it is maximized when p 1 = 0. Making this substitution, the RHS is neg ative, and thu s Ψ( t + α ) < Ψ( t ). 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment