An Evolutionary-Based Approach to Learning Multiple Decision Models from Underrepresented Data
The use of multiple Decision Models (DMs) enables to enhance the accuracy in decisions and at the same time allows users to evaluate the confidence in decision making. In this paper we explore the ability of multiple DMs to learn from a small amount …
Authors: ** Vitaly Schetinin, Dayou Li, Carsten Maple **
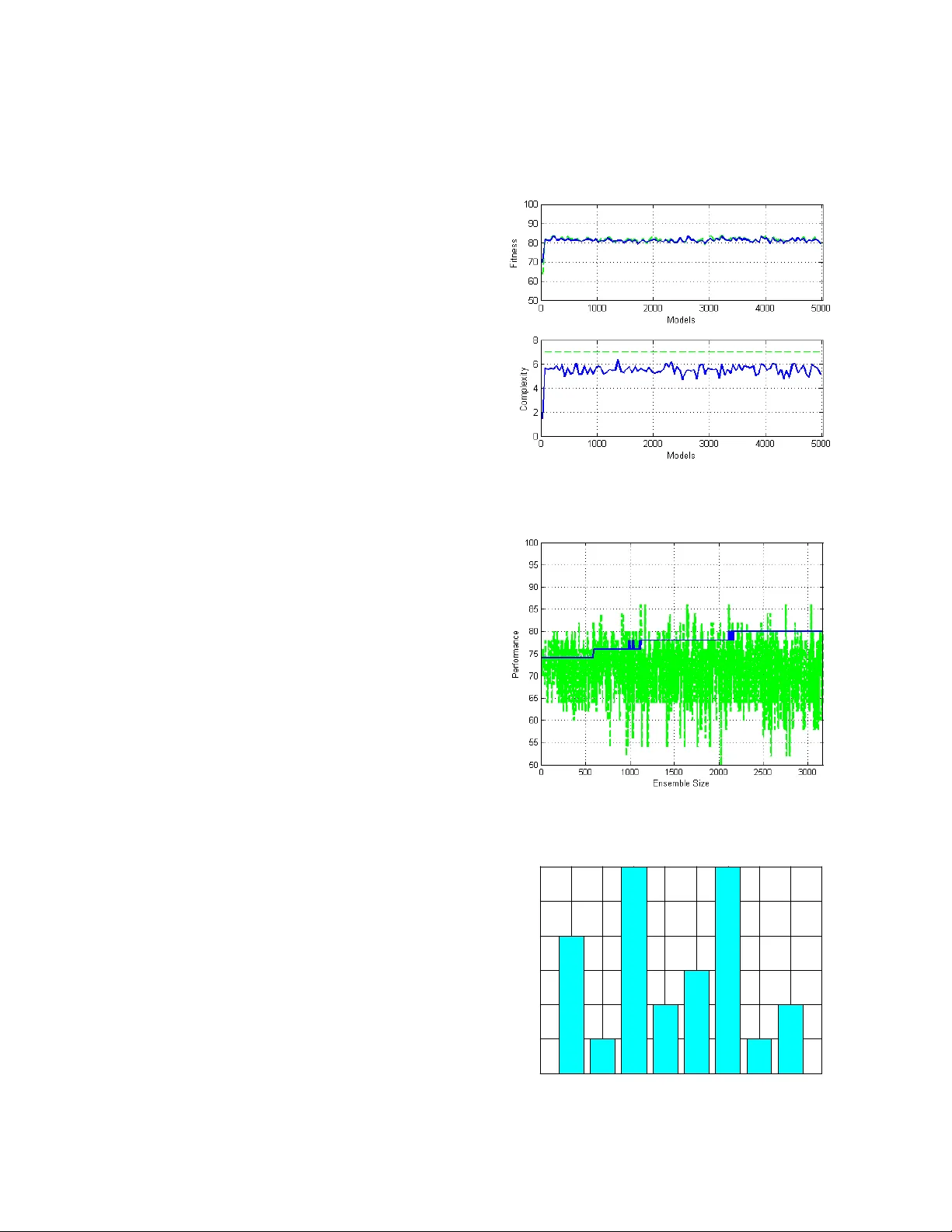
An Evolution ary-Based Appr oach to Lear n ing Mu ltiple D ecis ion Mode ls from Underrepresented Data Vitaly Schetinin, Da you Li, Carsten Maple Computing and Information Systems Department, Un iversity of Bedfordshire, Luton, UK, LU1 3JU {vitaly.schetinin, dayou.li, carsten.maple}@beds.ac.uk Abstract Abstract – The u se of multiple Decision Mod els (DMs) enables to enh ance the accuracy in deci sions and at the same time allows u sers to evaluate the confidence in decision makin g. In this p aper we explo re the ability of multiple DMs to learn from a small amount of verified data. This becomes im portant when dat a samples are difficult to collect and verify. We propose an evolutionary-b ased ap proach to solvi ng this pr oblem. The proposed techni que is examined on a few clinical problems presente d by a small amount of data . 1. Introduction The use of multiple Decisio n Models (DMs) enables to enhance the generalization ab ility of the models. At the same time the use o f multiple DMs allo ws users to evaluate the confidence in decision making. These properties are im port ant for such appli cations as medi cal diagnostics when data collected for learning diagn ostic models are repres ented by a small amount of patients’ cases which have been reliably v erified. Ideally, the DMs should satis fy the follo wing require ments: they s hould provide th e maxim al perform ance; th ey should prov ide the estimates of confidence in decisions, and finally the decision models should be in terpretabl e for domain experts [1, 2]. Such m odels can be learn t from a set of ve rified data which sh ould be larg e enough to represen t a problem. However, in practice domain data collected by users are often underrepresented t o be used for learn ing decision models with an acceptable predictive accuracy. For example, in clinical practice the domain data can be collected from a small number of patients because of the difficulty of their dia gnostic ve rification. In such cases the resultant models become unacceptably dependent on the variations in the collected data. Moreover, the use of cross-validation tech niques aiming to mitigate the overfitting proble m becomes inefficient o n a small amount of data, affecting the ability of models to generalize. However, the generalization abilit y can be still evaluated within leave- one-out technique [2 - 4]. Fortunately, the lo ss of generalization ability can be compensated by averaging over multiple models’ outcomes without the common cross-validation technique [3 - 5]. The use of multiple models also allows t he confidence in decisi ons to be evaluated in terms of the consiste ncy of th e models’ ou tcom es [3]. In this paper w e anticipate that the generalization ability of DMs ca n be further enhanced b y using the leave-one-out technique while the DMs learn fro m training data. We hope that th is technique will allo w us to mitigate the negative effect of overcomplicating DMs, which usually affects their ability to generalize [6]. The use of ev olutionary-based algorithms for learning DMs of the growing co mplexity was sho wn efficient on a small amount of data [4 - 6]. To allow DMs to be gradual ly grown , these algorit hms em ploy tw o basic operations: generating can didate-models and s electing the best of t hem as des cribed in [4 - 10]. Within our approach DMs can be considered as multiple semantic networ ks which are logically interpretable [1, 2]. The models consist of processing units linked with attributes or outputs of t he previous units. Each model learns fro m the domain data independen tly from each others in order to en hance the models ’ divers ity. Makin g an ens emble of models diverse we can therefore improve its generalization ability by averaging over the multiple m odels. The use of multiple models allows us also to naturally esti mate the confidence in decis ions. In many practi cal cases, domain data can be represented by many attrib utes while onl y a small amount of these data is available to collect. Learning DMs from such data cannot be efficient, and therefore the DMs loose the ability to generalize. Ho wever, the efficiency of the learning from a small amount of data can be improv ed by decomposing models with many attributes into several reference m odels with a few attributes [11 - 14]. The evolu tionary-bas ed method propos ed in [15 ] has proved the eff iciency of su ch approach on seve ral problems . Thus, th e novelty of our approach to im prove DMs learnt from a small amount of data is that we use the leave-on e-out techni que for select ion of the reference models com posing a DM. To make DMs interpret able, the reference models are repres ented in a logical form. Within our approach ev olution ary compos ition of the refe rence models allows us to combine them into DM en semble providin g a better perf orman ce. The remain der of this paper is organized as follows. Section 2 des cribes ou r evoluti onary-based approach to learning DMs from domain data. Sect ion 3 presen ts the cases of applications of our method to the clinical problem s, and final ly section 4 concludes t he paper. 2. An Evolutionar y Te chnique for Learning DMs fro m Underrepres ented Data In general, when models learn from a small amount o f data, thei r perform ance becomes poor due to th e loss of generalization ability [1 - 4]. The perform ance becomes especially poor when m odels are dependent on many arguments. Howev er, in such cases th e performance of models can be improved by decomposing t heir funct ions into several functions depend ent on a smaller n umber of argument s, particul arly, on two argum ents [14 - 15]. In this paper our attention is focused on lo gical functions because of their interpretability. Let g k ( u 1 , u 2 ), k = 1, …, 10, denote all 10 log ical funct ions of two argum ents u 1 and u 2 . Then according to the theorem about decomposition, a ny function of m argu ment s x 1 , …, x m , f ( x 1 , …, x m ) can be written a s follows: (...)) )), , ( , (... ( ) ,..., ( 1 g x x g g g x x f j i m = , (1) where x i , x j , i ≠ j , j = 1, …, m , are arg um ents of log ical funct io n f. The logical functions of tw o arguments are listed in Table 1, where operators +, *, and ~ repres ent logical OR, AND, and NOT, respectively. Table 1. Log ical fun ctions of tw o arguments. # Functions 1 g = u 1 + u 2 2 g = ~ u 1 + u 2 3 g = ~( u 1 + u 2 ) 4 g = u 1 + ~ u 2 5 g = u 1 * u 2 6 g = ~ u 1 * u 2 7 g = ~( u 1 * u 2 ) 8 g = u 1 * ~ u 2 9 g = ~ u 1 * u 2 + u 1 * ~ u 2 10 g = ~ u 1 *~ u 2 + u 1 * u 2 Attributes or arguments x 1 , …, x m can b e no minal o r numeric. The nominal variables can be eas ily convertible into logical, while t he numeric attributes need to b e converted with minimal losses of infor mation. The simplest way of converti ng numeric attributes into logical is the use of a threshold technique [3]. However such convers ion can loose im portant information. The losses can be redu ced if an attribute can be tak en in combination with other attributes which deter mine a so-call ed context of th e problem [1 - 5]. How ever, th e determination of such context even for a few attributes is not a trivial task because of the combinatorial problem . 2.1. Training Mode ls Within our approach model units are trained one-b y- one and then added t o the model whil e the model perform ance increases. Therefore th e number of processing units can be associated with the complexity of a model w hich in creases gradually. For training we need to fi nd such threshold Q and model M, being represented as decompos ition (1), wh ich provide the best perform ance for a give n co mple xit y of mod el M. To c onver t nume ric attr ibute s we can attempt to search for a desired t hresh old Q in the contex t of the current DM by exploiting more than one attributes. T he search procedure aims to minim ise entropy of a model unit as follows. For attribute A and set of t raining data , S , the value of entropy H is: ∑ = − = r i i i P P S H 1 2 ) ( log ) (, ( 2 ) where r is a given number of clas ses, and P i is the probability of occurrence of class C i . The search procedure creates a candidate m odel Μ each input of which is linked to either attribute o r the previous model. In this case the pro bability P is calculated as a ratio | S i |/| S |, where S i is the portion of training sam ples assig ned by model Μ to class C i , and | S | is t he tota l numb er o f trai ning sa mples. For t he gi ven t hres hold Q and m odel (log ical fun ction of two argum ents) Μ k , the set S is div ided in to two su bsets S 1 and S 2 for whi c h we can calculate conditional entropy H ( A , S | Q, M k ): ) ( | | | | ) ( | | | | ) , | , ( 2 2 1 1 S H S S S H S S Q S A H k + = Μ . (3) For a reasonably large number of th e random samples from a set of attribute’s values, this technique can find a thresh old Q * and a logical function M* for w hich conditional entropy (3) is near minimal: )) , | , ( ( min arg *) *, ( 10 1 , k j k S Q Q S A H Q j Μ = Μ ≤ ≤ ∈ . (4) During the search , the candidate values of Q j are drawn from a un iform distri bution U for a gi ven n umber o f samples, l , as follows: l j S U Q j ..., , 1 ), ( ~ = . (5) Thus, for a reas onably large num ber l , the above search procedure can fi nd the solution ( Q *, M *) . 2.2. Selection of Models The DMs train ed on a sm all am ount of data can be selected by the number of errors on th e training data. However, such selection favours overfitted DMs with a poor ability to generalise. To enhance the generalisation ability, we can atte mpt to se lect the DM s by usi ng the leave-one-out cross validatio n technique allowing us to evaluate the generalisat ion abilit y in terms of a verage number of errors. For a small amount of data, this technique run s for a reasonable com putational time. Selecting the DMs, we need also ex clude those DMs, which have differen t model’s structures but provide the same outcomes; such DMs are redundant and useless repetitions, so-called ta utologies. Within o ur approach both selection goals are ach ieved as follows. Let μ , μ 1 , and μ 2 be the average n umbers of errors admitted by a candidate mo del, Μ , and the previous models Μ 1 and Μ 2 , respectively. The inputs of model M are link ed with the ou tputs of model s Μ 1 and Μ 2 . Then the candidate model is selected if the following conditio n is m et: μ < min( μ 1 , μ 2 ). (6) Indeed, if a can didate model Μ admits few er errors than models Μ 1 and Μ 2 , then the generalisation abilit y of model Μ beco mes better. Applying this heuristic rule iteratively to each candidate model, we therefore can achieve a near-optimal generalisation ability of a DM. In theory, the maximum of this abilit y cannot be guaranteed by usi ng he urist ics se arc h. The above rule can als o effectively prevent the acceptance of th e tautological DMs. Indeed, if m odel Μ is tautolog ical, then it repeats on e of m odels Μ 1 or Μ 2 , and the above ru le will reject such model. 2.3. Stopping Crite ria The learning proces s continues wh ile the performance of DMs is improved. When the performance stabilises, we can assume that the trained DMs provide the best generalisation ability. Further perfor mance improvement becomes unlikely and al most all candidate -models will be rejected by the s election criterion (6). In general, the evolution process terminates due to one of th e following reas ons: 1) If an acceptable lev el of errors w as achieved. 2) I f the gi ven nu mbe r of unsucc ess ful a tte mpts o f improvin g the perform ance was exceeded. 3) If the g iven complexity of DMs was exceeded. According to these criteria, one or m ore DMs in the last gener atio n ca n p rovi de a mi nimal nu mber o f e rro rs. When there are sev eral DMs, it seems reasonable to select from them those which h ave a minimal complexity, i.e., the DMs which comprise a minimal number of processing units . Such selection allows us to discard ov ercomplicated DMs and u se the rem aining m odels Μ 1 , …, Μ m of a minimal complexity, where m is th e number of models. Each DM was learnt from the training data independentl y from each oth er, and therefore w e can arran ge these DMs in an ensemble in order to enhance the reliabilit y of decisions ; e.g., the final decis ion can be m ade by the majority voting. Ense mble of DMs allo ws us also to evaluate the conf idence in decisions. 2.4. Confidence in De cisions When the resultant ense mble consists of several DMs, their outcomes calculated for a given input x can be inconsi stent. F or real-worl d problems, such inconsiste ncy may be caus ed by noise or corruption in data. Therefore, we can determine the confiden ce in decisions in terms of the consistency χ calculated as a ratio m i / m , where m i is the num ber of models v oted for class i . C lea rly , th e estimates of confiden ce range between 0.5 an d 1 (0.5 is the least confident, and 1.0 is the most confident). 3. Application to Clinic al P roblems In this section f irst we describe our ex perim ents with learning the DMs to differentiate Infectious E ndocarditis (IE) from Sys tem Red Lupus (SRL) on th e data collected in the Penza Hospital Rheumatology Department, see [15] for details . Second, w e descri be our experim ent s with the UK Trauma D ata [16] and two data s ets from the UCI ML Reposi tory [17], th e SPECT Heart an d Wiscon sin Prognostic Breast Can cer (WPBC). To differentiate the IE an d SRL, an expert collected 18 verified cases represen ted by the results of 24 clinical and laboratory tes ts which are commonly used for distingu ishing thes e diseases. Among these 24 tests, 7 are represente d by num eric v alues and th e remaining 17 by nominal values. In total, the data set consists of 36 cases. The Traum a data are represe nt ed by 16 v ariables : 11 categorical and 5 num erical. The SPECT data comprise 22 variables, all categorical. The WPBC data are represented by 33 variables , all numerical. To deal w ith underrepresen ted data in our ex periments we use a sm all amoun t of data for train ing, nam ely, 50 data sam ples with an equal ratio of negative and positive outcomes. We compare the proposed Ev olving D ecision Model (EDM) techn ique with a common Artificial Neu ral Network (ANN) ensemble technique. Each ANN is trained by back- propagation. The com parisons are ma de in term s of the perf ormances prov ided by bes t single models (BS) and en sem bles (E) w ithin two-f old cross validati on. The ensembles com prise 5000 AN Ns, each including 10 hidden neurons , traine d within leave-on e-out validation technique to reduce the negative effect of overfitting to underrepresented d ata. To make the ANN ensemble effective, each ANN is randomly initialised and exploits a random set of variables. For com parison w e enable the propos ed EDM techniqu e to collect u p to 5000 m odels as well . The complexity of models is made restricted to achieve the best perform ance; th e complexity is simply count ed by the num ber of m odel’s uni ts. In ou r experim ents the compl exity was restricted to 7, 10, and 20 un its for the mentioned data sets. Fi g. 1 sh ow s th e fi tne ss fun cti on va lue s ( th e s ol id l in e in the upper plot) an d complexi ty of models (the s olid line in the lower plot) over the number of units accepted during t he evolu tionary learnin g. The dash ed line in th e upper plot depi cts th e performan ce of units with in leave one-out techn ique, and the das hed line in the low er plot depicts the maximal co mplexity of models. From this figure we can see that the fitness fun ction reaches a maximum very fast and then becom es to be slight ly oscillated around 80%. The complexity of models is also grown fas t and reaches a m aximum aroun d 6 units. Fig. 2 depi cts the perf ormances of single models (in grey) an d the performan ce of the ensem ble (in black) over the number of models accepted during the learning. It is importan t that f rom this figure we can observe that the perform ance of an ensem ble tends to increase. The results of ou r experiments are listed in Table 2 presenting the mean and standard deviation values of the perform ances calculated ov er 5 runs within 2-fold cross validation . From this table we can see th at the proposed EDM technique is s uperior to the ANN e nsemble technique in terms of the predictive accuracy. The additional advan tage of the proposed EDM technique is that we can derive the bes t models from an ensemble to create a diagnostic table which clinicians can conveniently use to mak e decisions and evaluate their consistency. As an exam ple, for the above IE and SRL diff erentiat ion problem we found the ni ne DMs, on e of which is represented belo w in a for m of if-th en rules: if leuko cytes ( x 2 ) are less than 6.2 and circulatin g immu ne comp lex ( x 5 ) is less than 130 and articular syndr ome ( x 8 ) is absent and anhelati on ( x 11 ) is absen t and erythema ( x 13 ) is absent and noises in heart ( x 14 ) are absent and hepat omega ly ( x 15 ) is absent and myocarditis ( x 16 ) is abse nt, then the di agnose is t he IE. Figure 3 shows the ranks of the eigh t attributes selected to be used in the DMs. The mos t important contribu tion is made by attribut es x 8 and x 14, whi ls t attributes x 5 and x 15 make the w eakest contribution. Therefore we can attempt to exclude the remaining attributes from the DMs keeping their perf ormance high. For a giv en inpu t, the out comes of the DMs may be inconsistent, and the final decision is made by the majority voting. The resultan t diagnostic table has bee n applied to ov er 200 patie nts , and the misdia gnosed rate was less t han 2%. Our experimen ts were run in Matlab 7 w ith Intel Core 2 Duo CPU E675 2.66 G Hz. The creati on of a ty pical ensembl e of DMs us ually took about 10 m in of the comp utatio ns. Fig. 1. F itness function v alue (upper plot) an d compl exity (lower plot ) over t he num ber of units. Fig. 2. Pe rfor mances o f si ngle mod els (i n gra y) and a n ensemble (i n black ) over the num ber of m odels. x2 x5 x8 x11 x1 3 x1 4 x15 x1 6 0 1 2 3 4 5 6 rank Fig. 3. R anks of t he attributes . Table 2. Perform ances of the ANN and EDM techniques. Data Fold ANN EDM BS E BS E Trauma 1 70.8±1. 1 78.8±1. 1 77.6±3. 8 81.6±2. 2 2 77.2±1. 8 80.8±1. 1 75.6±3. 8 83.2±3. 0 SPECT 1 64.0±3. 7 64.4±2. 0 73.2±4. 2 77.6±5. 9 2 62.0±3, 2 64.0±1. 4 69.6±2. 2 72.8±1. 8 WPBC 1 72.5±1. 1 66.8±1. 8 63.7±7. 2 70.4±7. 0 2 64.2± 2.3 66.3± 0.9 64.2±4. 0 67.1±9. 6 4. Conclusions and Disc ussion We have pres ented a new evolution ary-based approach to learning DMs from underrepresent ed data w hich frequently appear in practice. We aim ed to fin d the DMs proving the best perform ance while keeping a form interpretable for users. Based on an evolu tionary approach, the pr oposed technique st arts to learn the DMs cons isting of one pro cessing uni t a nd t hen ste p-b y-ste p e volve s t he DM s while their performance increases. Each proces sing unit ha s a pai r of in pu ts tha t al low s th e un ce rt ain ty o f m odel paramet ers learnt from the dat a to be redu ced. In theory, the propos ed technique can prov ide a near- optim al complexity of models. However i n practice, wh en dealing with un derrepresented data, w e cannot use a substantial po rtion of data for va lidation and, as a consequence, we needed to res trict the maximum of models’ com plexity. This restriction can be viewed as an additional technique for mitigatin g the overfitting problem . Within our approach w e com bined the leave-one-out validation technique with the complexity restriction to achieve a near-optim al performance of ensem ble. Our experim ents on clin ical datasets show th at the proposed technique ou tperforms a common ANN ensemble technique in term of predictive acc uracy. Additionally, the proposed t echni que is shown capable of excluding redundant clinical tests from decision models while their perform ance is kept high. 5. References [1] J. Sowa, Knowledge Repr esentatio n: Logical, Phi loso phica l, and C omputa tiona l Fo undat ions . Brook s & Cole Publis hing, Pacif ic G rove , CA, 2000. [2] J. Doyle, “A Tru th Maint enance Syste m”, Artificial Intelligenc e , 12, 1 979. [3] W. Kloe sge n, and J. Zy tkow (eds.) , Hand book of D ata Mining a nd Knowle dge D iscov ery , Oxford Univers ity Press, New York, NY, USA, 2002 . [4] H. Mada la, and A . G. I vakhne nko, Ind uctive Learni ng Algorithm s for Comple x Sys tems M odeling , CRC Press Inc.: Boca Raton, 1994 . [5] J. A. Müller, and F. L emke, Self-Organizi ng Dat a Minin g. Extracting K nowled ge from D ata , Tra fford Publis hing, Canada , 200 3. [6] V. Schetinin, “ Pattern Recogniti on with Neura l Netw ork”, Optoelec tronics , Inst rument ation an d Data Pr oces sing , Alle rton Press, 2, 75- 80, 2000. [7] T. Back, D. Fo gel, and Z. Mi chalewicz (ed s), Handbook of Evolution ary Comp utatio n , IOP Publ ishi ng, Ox for d Universit y Press, 1997 . [8] A. Freitas, Data M ining and K nowle dge Di scove ry with Evolution ary Algorit hms , S pringe r-Verlag , 2002 . [9] W. Kwedlo , and M. Kret owski, “Discover y of Deci sion Rules f rom Da tabases : an Ev olutionar y Approa ch”, Principles of Data Minin g and Kn owledge D iscov ery , Second E uro pean Sym posium (PK DD'9 8) , Nantes, F rance, Septem ber 23- 26, 199 8. Spri nge r Lect ure Note s in Compute r Scienc e 1510 , 199 8. [10] N. Nikolaev an d H. Iba, “Automated Disco very of Polynom ials by Inductiv e Genetic Progra mm ing”, J. Zutkow , and J . Ranc h (eds .) Pr inciple s of Data M ining and Knowledg e Discovery (PKDD’99 ) , Springer, Be rlin, 199 9. [11] G. Cybenk o, “A pproxim ation by Super positi ons of a Sing le Function” , Mathemati cs of Control , Signal s and Syst ems, 2 , 1989. [12] R. Hecht-Nie lsen, “ Kolm ogorov Mapping Neur al Ne twork Existence theorem”, Proc . IEEE First International Confere nce o n Neural Netw orks , San Die go, 198 7. [13] J. Schmidhuber , “Dis cove ring N eural N ets with Low Kolmog orov Com plexity a nd High Ge neration Capa bility ”, Neural Ne tworks , 10, 1997. [14] L. Kurkova, “K olmogorov' s Theorem and Multila yer Neural Networks”, Neural Ne twork s , 5, 199 2. [15] V. Sc hetinin , an d A. Braz hnikov , “Ex trac ting De cisi on Rules Using Neur al Networks ”, Biomedical E ngine ering , Kluwer Acade mic, 1, 2000. [16] Trau ma Audit and Research Net work. Avail able on line: http://www .tarn.ac.uk [17] The M achine Le arning Rep ository of the Un iversit y of Calif ornia, Irv in. A vailable online: http://arc hive.ics .uci.edu/m l/datas ets.htm l
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment