Bit-Interleaved Coded Modulation Revisited: A Mismatched Decoding Perspective
We revisit the information-theoretic analysis of bit-interleaved coded modulation (BICM) by modeling the BICM decoder as a mismatched decoder. The mismatched decoding model is well-defined for finite, yet arbitrary, block lengths, and naturally captu…
Authors: Alfonso Martinez, Albert Guillen i Fabregas, Giuseppe Caire
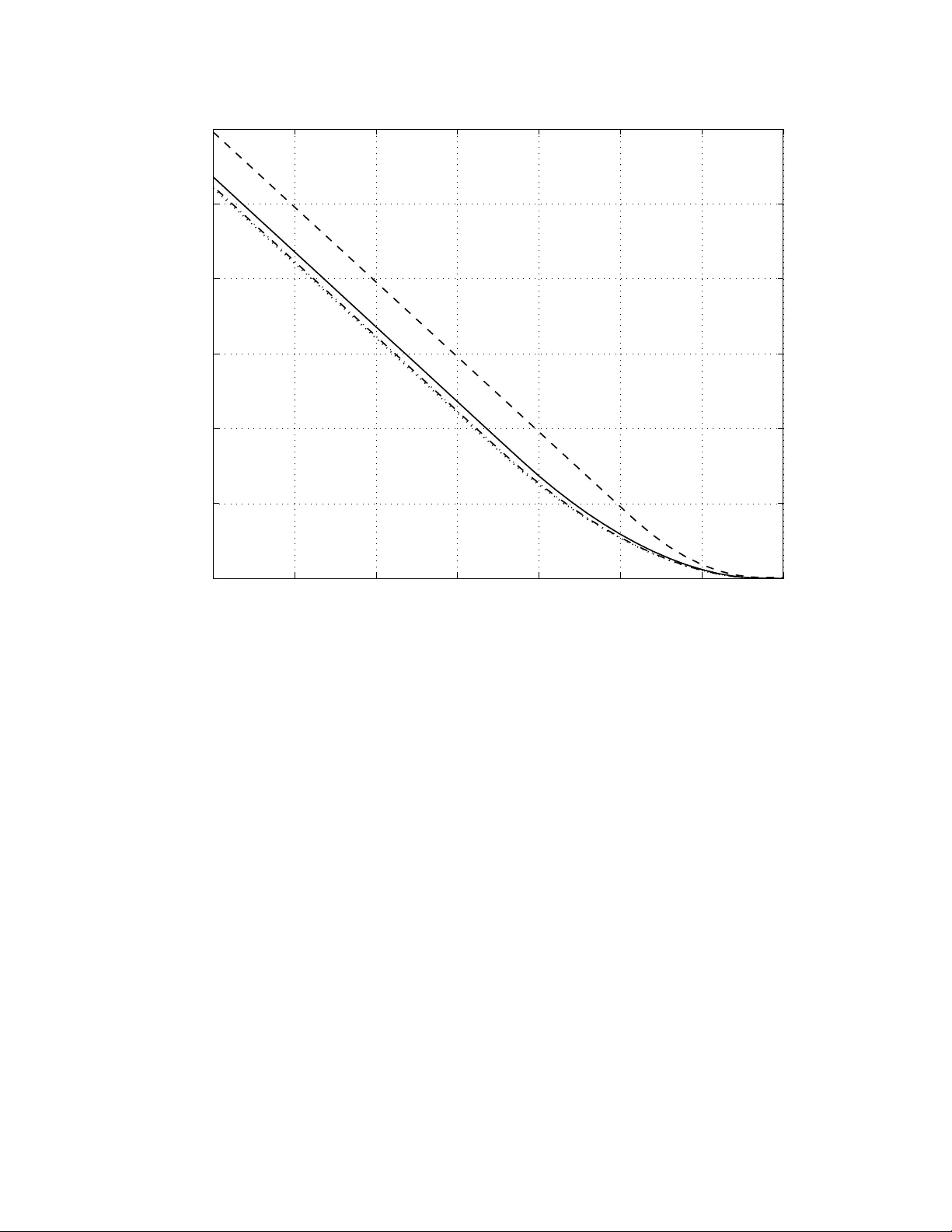
1 Bit-Interlea v ed Coded Modulation Re visited: A Mismatched Decoding Perspecti ve Alfonso Martinez, Albert Guill ´ en i F ` abreg as, Giuseppe Caire and Frans W illems Abstract W e revisit the information-theoretic analysis of bit-interleaved coded modulation (BICM) by mod- eling the BICM decoder as a mismatched decoder . The mismatched decoding model is well-defined for finite, yet arbitrary , block lengths, and naturally captures the channel memory among the bits belonging to the same symbol. W e giv e two independent proofs of the achiev ability of the BICM capacity calculated by Caire et al. where BICM was modeled as a set of independent parallel binary- input channels whose output is the bitwise log-likelihood ratio. Our first achiev ability proof uses typical sequences, and shows that due to the random coding construction, the interleaver is not required. The second proof is based on the random coding error e xponents with mismatched decoding, where the largest achiev able rate is the generalized mutual information. W e show that the generalized mutual information of the mismatched decoder coincides with the infinite-interleaver BICM capacity . W e also show that the error exponent –and hence the cutoff rate– of the BICM mismatched decoder is upper bounded by that of coded modulation and may thus be lo wer than in the infinite-interleav ed model. For binary reflected Gray mapping in Gaussian channels the loss in error exponent is small. W e also consider the mutual information appearing in the analysis of iterati ve decoding of BICM with EXIT charts. W e show that the corresponding symbol metric has knowledge of the transmitted symbol and the EXIT mutual information admits a representation as a pseudo-generalized mutual information, which is in general not achiev able. A different symbol decoding metric, for which the extrinsic side information refers to the hypothesized symbol, induces a generalized mutual information lower than the coded modulation capacity . W e also show how perfect extrinsic side information turns the error exponent of this mismatched decoder into that of coded modulation. A. Martinez is with the Centrum voor W iskunde en Informatica (CWI), Kruislaan 413, P .O. Box 94079, 1090 GB Amsterdam, The Netherlands, e-mail: alfonso.martinez@ieee.org . A. Guill ´ en i F ` abregas is with the Department of Engineering, Univ ersity of Cambridge, Cambridge, CB2 1PZ, UK, e-mail: guillen@ieee.org . G. Caire is with the Electrical Engineering Department, Univ ersity of Southern California, 3740 McClintock A ve., Los Angeles, CA 90080, USA, e-mail: caire@usc.edu . F . W illems is with the Department of Electrical Engineering, T echnische Univ ersiteit Eindhov en, Postbus 513, 5600 MB Eindhoven, The Netherlands, e-mail: f.m.j.willems@tue.nl . This work has been supported by the International Incoming Short V isits Scheme 2007/R2 of the Royal Society . This work has been presented in part at the 27th Symposium Information Theory in the Benelux, wic 2006, June 2006, Noordwijk, The Netherlands, and at the IEEE International Symposium on Information Theory , T oronto, Canada, July 2008. May 28, 2018 DRAFT 2 I . I N T RO D U C T I O N In the classical bit-interleaved coded modulation (BICM) scheme proposed by Zeha vi in [1], the channel observ ation is used to generate decoding metrics for each of the bits of a symbol, rather than the symbol metrics used in Ungerb ¨ ock’ s coded modulation (CM) [2]. This decoder is sub-optimal and non-iterativ e, but offers very good performance and is interesting from a practical perspectiv e due to its low implementation complexity . In parallel, iterativ e decoders hav e also recei ved much attention [3], [4], [5], [6], [7] thanks to their impro ved performance. Caire et al. [8] further elaborated on Zehavi’ s decoder and, under the assumption of an infinite- length interleav er , presented and analyzed a BICM channel model as a set of parallel independent binary-input output symmetric channels. Based on the data processing theorem [9], Caire et al. sho wed that the BICM mutual information cannot be lar ger than that of CM. Howe ver , and rather surprisingly a priori, they found that the cutoff rate of BICM might exceed that of CM [10]. The error exponents for the parallel-channel model were studied by W achsmann et al. [11]. In this paper we take a closer look to the classical BICM decoder proposed by Zehavi and cast it as a mismatched decoder [12], [13], [14]. The observation that the classical BICM decoder treats the dif ferent bits in a giv en symbol as independent, ev en if they are clearly not, naturally leads to a simple model of the symbol mismatched decoding metric as the product of bit decoding metrics, which are in turn related to the log-likelihood ratios. W e also examine the BICM mutual information in the analysis of iterativ e decoding by means of EXIT charts [5], [6], [7], where the sum of the mutual informations across the parallel subchannels is used as a figure of merit of the progress in the iterati ve decoding process. This paper is organized as follo ws. Section II introduces the system model and notation. Section III giv es a proof of achiev ability of the BICM capacity , deriv ed in [8] for the independent parallel channel model, by using typical sequences. Section IV sho ws general results on the error exponents, including the generalized mutual information and cutoff rate as particular instances. The BICM error exponent (and in particular the cutof f rate) is alw ays upper-bounded by that of CM, as opposed to the corresponding exponent for the independent parallel channel model [8], [11], which can sometimes be larger . In particular , Section IV -D studies the achie v able rates of BICM under mismatched decoding and shows that the generalized mutual information [12], [13], [14] of the BICM mismatched decoder yields the BICM capacity . The section concludes with May 28, 2018 DRAFT 3 some numerical results, including a comparison with the parallel-channel models. In general, the loss in error e xponent is negligible for binary reflected Gray mapping in Gaussian channels. In Section V we turn our attention to the iterativ e decoding of BICM. First, we re vie w ho w the mutual information appearing in the analysis of iterativ e decoding of BICM with EXIT charts, where the symbol decoding metric has some side knowledge of the transmitted symbol, admits a representation as a pseudo-generalized mutual information. A different symbol decoding metric, for which the extrinsic side information refers to the hypothesized symbol, induces a generalized mutual information lower in general than the coded modulation capacity . Moreover , perfect extrinsic side information turns the error e xponent of this mismatched decoder into that of coded modulation. Finally , Section VI draws some concluding remarks. I I . C H A N N E L M O D E L A N D C O D E E N S E M B L E S A. Channel Model W e consider the transmission of information by means of a block code M of length N . At the transmitter, a message m is mapped onto a codew ord x = ( x 1 , . . . , x N ) , according to one of the design options described later , in Section II-B. W e denote this encoding function by φ . Each of the symbols x are drawn from a discrete modulation alphabet X = { x 1 , . . . , x M } , with M ∆ = |X | and m = log 2 M being the number of bits required to index a symbol. W e denote the output alphabet by Y and the channel output by y ∆ = ( y 1 , . . . , y N ) , with y k ∈ Y . W ith no loss of generality , we assume the output is continuous 1 , so that the channel output y related to the codeword x through a conditional probability density function p ( y | x ) . Further , we consider memoryless channels, for which p ( y | x ) = N Y k =1 p ( y k | x k ) , (1) where p ( y | x ) is the channel symbol transition probability . Henceforth, we drop the words density function in our references of p ( y | x ) . W e denote by X, Y the underlying random v ariables. Similarly , the corresponding random vectors are X ∆ = ( X , . . . , X | {z } N times ) and Y ∆ = ( X , . . . , X | {z } N times ) , respecti vely drawn from the sets X ∆ = X N , Y ∆ = Y N . 1 All our results are directly applicable to discrete output alphabets, by appropriately replacing integrals by sums. May 28, 2018 DRAFT 4 A particularly interesting, yet simple, case is that of complex-plane signal sets in A WGN with fully-interleav ed fading where Y = C and y k = h k √ snr x k + z k , k = 1 , . . . , N (2) where h k are fading coef ficients with a verage unit energy , z k are the complex zero-mean unit- v ariance A WGN samples and snr is the signal-to-noise ratio (SNR). The decoder outputs an estimate of the message b m according to a gi ven code word decoding metric , which we denote by q ( x , y ) as b m = arg max m q ( x m , y ) . (3) The codeword metrics we consider are the product of symbol decoding metrics q ( x, y ) , for x ∈ X and y ∈ Y , namely q ( x , y ) = N Y k =1 q ( x k , y k ) . (4) Assuming that the code words ha ve equal probability , this decoder finds the most likely code- word as long as q ( x, y ) = f p ( y | x ) , where f ( . ) is a one-to-one increasing function, i.e., as long as the decoding metric is a one-to-one increasing mapping of the transition probability of the memoryless channel. If the decoding metric q ( x, y ) is not an increasing one-to-one function of the channel transition probability , the decoder defined by (3) is a mismatc hed decoder [12], [13], [14]. B. Code Ensembles 1) Coded Modulation: In a coded modulation (CM) scheme M , the encoder φ selects a code word of N modulation symbols, x m = ( x 1 , . . . , x N ) according to the information message m . The code is in general non-binary , as symbols are chosen according to a probability la w p ( x ) . Representing the information message set { 1 , . . . , |M|} , we have that the rate R of this scheme in bits per channel use is given by R = K N , where K ∆ = log 2 |M| denotes the number of bits needed to represent every information message. At the recei ver , a maximum metric decoder φ (as in Eq. (3)) acts on the recei ved sequence y to generate an estimate of the transmitted message, ϕ ( y ) = b m . In coded modulation constructions, such as Ungerboeck’ s [2], the symbol decoding metric is proportional to the channel transition probability , that is q ( x, y ) ∝ p ( y | x ) ; the v alue of proportionality constant is irrele vant, as long as it is not zero. Reliable communication May 28, 2018 DRAFT 5 is possible at rates lo wer than coded modulation capacity or CM capacity , denoted by C cm X and gi ven by C cm X ∆ = E " log p ( Y | X ) P x 0 ∈X p ( x 0 ) p ( Y | x 0 ) # . (5) The expectation is done according to p ( x ) p ( y | x ) . W e consider often a uniform input distribution p ( x ) = 2 − m . 2) Bit-Interleaved Coded Modulation: In a bit-interleaved coded modulation scheme M , the encoder is restricted to be the serial concatenation of a binary code C of length n ∆ = mN and rate r = R m , a bit interleav er , and a binary labeling function µ : { 0 , 1 } m → X which maps blocks of m bits to signal constellation symbols. The codew ords of C are denoted by b = ( b 1 , . . . , b mN ) . The portions of codew ord allocated to the j -th bit of the label are denoted by b j ∆ = ( b j , b m + j , . . . , b m ( N − 1)+ j ) . W e denote the in verse mapping function for labeling position j as b j : X → { 0 , 1 } , that is, b j ( x ) is the j -th bit of symbol x . Accordingly , we now define the sets X j b ∆ = { x ∈ X : b j ( x ) = b } as the set of signal constellation points x whose binary label has v alue b ∈ { 0 , 1 } in its j -th position. W ith some abuse of notation, we will denote B 1 , . . . , B m and b 1 , . . . , b m the random v ariables and their corresponding realizations of the bits in a gi ven label position j = 1 , . . . , m . The classical BICM decoder [1] treats each of the m bits in a symbol as independent and uses a symbol decoding metric proportional to the product of the a posteriori marginals p ( b j = b | y ) . More specifically , we hav e that q ( x, y ) = m Y j =1 q j b j ( x ) , y , (6) where the j -th bit decoding metric q j ( b, y ) is gi ven by q j b j ( x ) = b, y = X x 0 ∈X j b p ( y | x 0 ) . (7) This metric is proportional to the transition probability of the output y giv en the bit b at position j , which we denote for later use by p j ( y | b ) , p j ( y | b ) ∆ = 1 X j b X x 0 ∈X j b p ( y | x 0 ) . (8) The set of m probabilities p j ( y | b ) can be used as departure point to define an equiv alent BICM channel model. Accordingly , Caire et al. defined a BICM channel [8] as the set of m May 28, 2018 DRAFT 6 parallel channels having bit b j ( x k ) as input and the bit log-metric (log-likelihood) ratio for the k -th symbol Ξ m ( k − 1)+ j = log q j b j ( x k ) = 1 , y q j b j ( x k ) = 0 , y (9) as output, for j = 1 , . . . , m and k = 1 , . . . , N . This channel model is schematically depicted in Figure 1. W ith infinite-length interleaving, the m parallel channels were assumed to be independent in [8], [11], or in other words, the correlations among the dif ferent subchannels are neglected. For this model, Caire et al. defined a BICM capacity C bicm X , giv en by C bicm X ∆ = m X j =1 I ( B j ; Y ) = m X j =1 E " log P x 0 ∈X j B p ( Y | x 0 ) 1 2 P x 0 ∈X p ( Y | x 0 ) # , (10) where the e xpectation is taken according to p j ( y | b ) p ( b ) , for b ∈ { 0 , 1 } and p ( b ) = 1 2 . In practice, due to complexity limitations, one might be interested in the following lo wer- complexity version of (7), q j ( b, y ) = max x ∈X j b p ( y | x ) . (11) In the log-domain this is kno wn as the max-log approximation. Summarizing, the decoder of C uses a mismatched metric of the form giv en in Eq. (4) where the decoder of C outputs a binary codew ord ˆ b according to ˆ b = arg max b ∈C N Y k =1 m Y j =1 q j b j ( x k ) , y n . (12) I I I . A C H I E V A B I L I T Y O F T H E B I C M C A PAC I T Y : T Y P I C A L S E Q U E N C E S In this section, we provide an achiev ability proof for the BICM capacity based on typical sequences. The proof is based on the usual random coding arguments [9] with typical sequences, with a slight modification to account for the mismatched decoding metric. This result is obtained without recurring to an infinite interleaver to remov e the correlation among the parallel subchan- nels of the classical BICM model. W e first introduce some notation needed for the proof. W e say that a rate R is achie vable if, for ev ery > 0 and for N suf ficiently large, there exists an encoder , a demapper and a decoder such that 1 N log |M| ≥ R − and Pr( b m 6 = m ) ≤ . W e define the joint probability of the channel output y and the corresponding input bits ( b 1 , . . . , b m ) as p ( b 1 , . . . , b m , y ) ∆ = Pr B 1 = b 1 , . . . , B m = b m , y ≤ Y < y + dy , (13) May 28, 2018 DRAFT 7 for all b j ∈ { 0 , 1 } , y and infinitely small dy . W e denote the deri ved marginals by p j ( b j ) , for j = 1 , . . . , m , and p ( y ) . The marginal distributions with respect to bit B j and Y are special, and are denoted by p j ( b j , y ) . W e ha ve then the follo wing theorem. Theor em 1: The BICM capacity C bicm X is achiev able. Pr oof: Fix an > 0 . For each m ∈ M we generate a binary codew ord b 1 ( m ) . . . , b m ( m ) with probabilities p j ( b j ) . The codebook is the set of all code words generated with this method. W e consider a threshold decoder , which outputs b m only if b m is the unique integer satisfying b 1 ( b m ) , . . . , b m ( b m ) , y ∈ B , (14) where B is a set defined as B ∆ = ( b 1 , . . . , b m , y : 1 N m X j =1 log p j b j ( b m ) , y p j ( b j ) p ( y ) ≥ ∆ ) (15) for ∆ ∆ = P m j =1 I ( B j ; Y ) − 3 m . Otherwise, the decoder outputs an error flag. The usual random coding argument [9] shows that the error probability , a veraged over the ensemble of randomly generated codes, ¯ P e , is upper bounded by ¯ P e ≤ P 1 + ( |M| − 1) P 2 , (16) where P 1 is the probability that the recei ved y does not belong to the set B , P 1 ∆ = X ( b 1 ,..., b m , y ) / ∈B p ( b 1 , . . . , b m , y ) , (17) and P 2 is the probability that another randomly chosen codeword would be (wrongly) decoded, that is, P 2 ∆ = X ( b 1 ,..., b m , y ) ∈B p ( y ) m Y j =1 p j ( b j ) . (18) First, we prov e that B ⊇ A ( B 1 , . . . , B m , Y ) , where A is the corresponding jointly typical set [9]. By definition, the sequences b 1 , . . . , b m , y in the typical set satisfy (among other constraints) the follo wing − log p ( y ) > N ( H ( Y ) − ) , (19) − log p j ( b j ) > N ( H ( B j ) − ) , j = 1 , . . . , m, (20) − log p b j , y < N ( H ( B j , Y ) + ) , j = 1 , . . . , m. (21) May 28, 2018 DRAFT 8 Here H ( · ) are the entropies of the corresponding random variables. Multiplying the last equation by ( − 1) , and summing them, we hav e log p j b j ( b m ) , y p j ( b j ) p ( y ) ≥ N H ( B j ) + H ( Y ) − H ( B j , Y ) − 3 (22) = N I ( B j ; Y ) − 3 , (23) where I ( B j ; Y ) is the corresponding mutual information. Now , summing o ver j = 1 , . . . , m we obtain m X j =1 log p j b j ( b m ) , y p j ( b j ) p ( y ) ≥ N m X j =1 I ( B j ; Y ) − 3 = N ∆ . (24) Hence, all typical sequences belong to the set B , that is, A ⊆ B . This implies that B c ⊆ A c and, therefore, the probability P 1 in Eq. (17) can be upper bounded as P 1 ≤ X ( b 1 ,..., b m , y ) / ∈A p ( b 1 , . . . , b m , y ) ≤ , (25) for N sufficiently large. The last inequality follo ws from the definition of the typical set. W e now move on to P 2 . For ( b 1 , . . . , b m , y ) ∈ B , and from the definition of B , we hav e that 2 N ∆ ≤ m Y j =1 p j b j , y p j ( b j ) p ( y ) = m Y j =1 p j ( b j | y ) p j ( b j ) . (26) Rearranging terms we hav e m Y j =1 p j ( b j ) ≤ 1 2 N ∆ m Y j =1 p j ( b j | y ) . (27) Therefore the probability P 2 in Eq. (18) can be upper bounded P 2 ≤ 1 2 N ∆ X ( b 1 ,..., b m , y ) ∈B p ( y ) m Y j =1 p j ( b j | y ) (28) ≤ 1 2 N ∆ X ( b 1 ,..., b m , y ) p ( y ) m Y j =1 p j ( b j | y ) (29) = 1 2 N ∆ X ( b 1 ,..., b m , y ) p ( b 1 , . . . , b m , y ) (30) = 1 2 N ∆ . (31) May 28, 2018 DRAFT 9 No w we can write for ¯ P e , ¯ P e ≤ P 1 + ( |M| − 1) P 2 ≤ + |M| 2 − N ∆ ≤ 2 , (32) for |M| = 2 N (∆ − ) and large enough N . W e conclude that for large enough N there exist codes such that 1 N log 2 |M| ≥ ∆ − = m X j =1 I ( B j ; Y ) − (3 m + 1) , (33) and Pr b m 6 = m ≤ . The rate P m j =1 I ( B j ; Y ) is thus achiev able. T o conclude, we verify that the BICM decoder is able to determine the probabilities required for the decoding rule defining B in Eq. (15). Since the BICM decoder uses the metric q j ( b j , y ) ∝ p j ( y | b j ) , the log-metric-ratio , or equiv alently the a posteriori bit probabilities p j ( b j | y ) , it can also compute p j ( b j , y ) p j ( b j ) p ( y ) = p j ( b j | y ) p j ( b j ) , (34) where the bit probabilities are kno wn, p j (1) = p j (0) = 1 2 . I V . A C H I E V A B I L I T Y O F T H E B I C M C A PAC I T Y : E R RO R E X P O N E N T S , G E N E R A L I Z E D M U T UA L I N F O R M A T I O N A N D C U T - O FF R A T E A. Random coding e xponent The behaviour of the average error probability of a family of randomly generates, decoded with a maximum-likelihood decoder , i. e. for a decoding metric satisfying q ( x, y ) = p ( y | x ) , was studied by Gallager in [15]. In particular, Gallager showed the error probability decreases exponentially with the block length N according to a parameter called the err or exponent , provided that the code rate R is below the channel capacity C . For memoryless channels Gallager found [15] that the a verage error probability over the random coding ensemble can be bounded as ¯ P e ≤ exp − N E 0 ( ρ ) − ρR (35) May 28, 2018 DRAFT 10 where E 0 ( ρ ) is the Gallager function, gi ven by E 0 ( ρ ) ∆ = − log Z y X x p ( x ) p ( y | x ) 1 1+ ρ ! 1+ ρ dy , (36) and 0 ≤ ρ ≤ 1 is a free parameter . For a particular input distribution p ( x ) , the tightest bound is obtained by optimizing ov er ρ , which determines the random coding exponent E r ( R ) = max 0 ≤ ρ ≤ 1 E 0 ( ρ ) − ρR . (37) For uniform input distribution, we define the coded modulation e xponent E cm 0 ( ρ ) as the exponent of a decoder which uses metrics q ( x, y ) = p ( y | x ) , namely E cm 0 ( ρ ) = − log E " 1 2 m X x 0 p ( Y | x 0 ) p ( Y | X ) 1 1+ ρ ! ρ # . (38) Gallager’ s deriv ation can easily be extended to memoryless channels with generic code word metrics decomposable as product of symbols metrics, that is q ( x , y ) = Q N n =1 q ( x n , y n ) , Details can be found in [13]. The error probability is upper bounded by the expression ¯ P e ≤ exp − N E q 0 ( ρ, s ) − ρR , (39) where the generalized Gallager function E q 0 ( ρ, s ) is gi ven by E q 0 ( ρ, s ) = − log E " X x 0 p ( x 0 ) q ( x 0 , Y ) s q ( X , Y ) s ! ρ # . (40) The e xpectation is carried out according to the joint probability p ( y | x ) p ( x ) . F or a particular input distribution p ( X ) , the random coding error exponent E q r ( R ) is then giv en by [13] E q r ( R ) = max 0 ≤ ρ ≤ 1 max s> 0 E q 0 ( ρ, s ) − ρR . (41) For the specific case of BICM, assuming uniformly distributed inputs and a generic bit metric q j ( b, y ) , we hav e that Gallager’ s generalized function E bicm 0 ( ρ, s ) is gi ven by E bicm 0 ( ρ, s ) = − log E " 1 2 m X x 0 m Y j =1 q j ( b j ( x 0 ) , Y ) s q j ( b j ( X ) , Y ) s ! ρ # . (42) For completeness, we note that the cutof f rate is gi ven by R 0 = E 0 (1) and, analogously , we define the generalized cutof f rate as R q 0 ∆ = E q r ( R = 0) = max s> 0 E q 0 (1 , s ) . (43) May 28, 2018 DRAFT 11 B. Data pr ocessing inequality for err or exponents In [13], it was prov ed that the data-processing inequality holds for error exponents, in the sense that for a giv en input distribution we hav e that E q 0 ( ρ, s ) ≤ E 0 ( ρ ) for an y s > 0 . Next, we rederi ve this result by extending Gallager’ s reasoning in [15] to mismatched decoding. The generalized Gallager function E q 0 ( ρ, s ) in Eq. (40) can be expressed as E q 0 ( ρ, s ) = − log Z y X x p ( x ) p ( y | x ) X x 0 p ( x 0 ) q ( x 0 , y ) q ( x, y ) s ! ρ ! dy . (44) As long as the metric does not depend on the transmitted symbol x , the function inside the logarithm can be re written as Z y X x p ( x ) p ( y | x ) q ( x, y ) − sρ ! X x 0 p ( x 0 ) q ( x 0 , y ) s ! ρ dy . (45) For a fixed channel observation y , the integrand is reminiscent of the right-hand side of H ¨ older’ s inequality (see Exercise 4.15 of [15]), which can be expressed as X i a i b i 1+ ρ ≤ X i a 1+ ρ i X i b 1+ ρ ρ i ρ . (46) Hence, with the identifications a i = p ( x ) 1 1+ ρ p ( y | x ) 1 1+ ρ q ( x, y ) − sρ 1+ ρ (47) b i = p ( x ) ρ 1+ ρ q ( x, y ) sρ 1+ ρ , (48) we can lo wer bound Eq. (45) by the quantity Z y X x p ( x ) p ( y | x ) 1 1+ ρ dy ! 1+ ρ . (49) Recov ering the logarithm in Eq. (44), for a general mismatched decoder , arbitrary s > 0 and any input distribution, we obtain that E 0 ( ρ ) ≥ E q 0 ( ρ, s ) . (50) Note that the expression in Eq. (49) is independent of s and of the specific decoding metric q ( x, y ) . Nev ertheless, ev aluation of Gallager’ s generalized function for the specific choices s = 1 1+ ρ and q ( x, y ) ∝ p ( y | x ) attains the lo wer bound, which is also Eq. (38). May 28, 2018 DRAFT 12 Equality holds in H ¨ older’ s inequality if and only if for all i and some positiv e constant c , a ρ 1+ ρ i = c b 1 1+ ρ i (see Ex ercise 4.15 of [15]). In our context, simple algebraic manipulations sho w that the necessary condition for equality to hold is that p ( y | x ) = c 0 q ( x, y ) s 0 for all x ∈ X (51) for some constants c 0 and s 0 . In other words, the metric q ( x, y ) must be proportional to a power of the channel transition probability p ( y | x ) , for the bound (50) to be tight, and therefore, to achie ve the coded modulation error e xponent. C. Err or exponent for BICM with the parallel-channel model In their analysis of multilev el coding and successiv e decoding, W achsmann et al. provided the error exponents of BICM modelled as a set of parallel channels [11]. The corresponding Gallager’ s function, which we denote by E ind 0 ( ρ ) , is gi ven by E ind 0 ( ρ ) = − m X j =1 log Z y 1 X b j =0 p j ( b j ) p j ( y | b j ) 1 X b 0 j =0 p j ( b 0 j ) q j ( b 0 j , y ) 1 1+ ρ q j ( b j , y ) 1 1+ ρ ρ dy , (52) which corresponds to a binary-input channel with input b j , output y and bit metric matched to the transition probability p j ( y | b j ) . This equation can be rearranged into a form similar to the one giv en in previous sections. First, we insert the summation in the logarithm, E ind 0 ( ρ ) = − log m Y j =1 Z y 1 X b j =0 p j ( b j ) p j ( y | b j ) 1 X b 0 j =0 p j ( b 0 j ) q j ( b 0 j , y ) 1 1+ ρ q j ( b j , y ) 1 1+ ρ ρ dy . (53) Then, we notice that the output variables y are dummy v ariables which possibly v ary for each v alue of j . Let us denote the dummy variable in the j -th subchannel by y 0 j . W e have then E ind 0 ( ρ ) = − log m Y j =1 Z y 0 j 1 X b j =0 p j ( b j ) p ( y 0 j | b j ) 1 X b 0 j =0 p j ( b 0 j ) q j ( b 0 j , y 0 j ) 1 1+ ρ q j ( b j , y 0 j ) 1 1+ ρ ρ dy 0 j (54) = − log Z y 0 X x p ( x ) p ( y 0 | x ) X x 0 p ( x 0 ) q ( x 0 , y 0 ) 1 1+ ρ q ( x, y 0 ) 1 1+ ρ ! ρ d y 0 ! . (55) Here we carried out the multiplications, defined the vector y 0 to be the collection of the m channel outputs, and denoted by x = µ ( b 1 , . . . , b m ) and x 0 = µ ( b 0 1 , . . . , b 0 m ) the symbols selected by the bit sequences. This equation is the Gallager function of a mismatched decoder for a May 28, 2018 DRAFT 13 channel output y 0 , such that for each of the m subchannels sees a statistically independent channel realization from the others. In general, since the original channel cannot be decomposed into parallel, conditionally independent subchannels, this parallel-channel model fails to capture the statistics of the channel. The cut-off rate with the parallel-channel model is gi ven by R ind 0 = − m X j =1 log Z y 1 X b j =0 p j ( b j ) p j ( y | b j ) 1 2 2 dy . (56) The cutoff rate was giv en in [8] as m times the cutof f rate of an a veraged channel, R av 0 ∆ = m log 2 − log 1 + 1 m m X j =1 E v u u t P x 0 ∈X j ¯ B p ( Y | x 0 ) P x 0 ∈X j B p ( Y | x 0 ) . (57) From Jensen’ s inequality one easily obtains that R av 0 ≤ R ind 0 . D. Generalized mutual information for BICM The largest achie vable rate with mismatched decoding is not known in general. Perhaps the easiest candidate to deal with is the generalized mutual information (GMI) [12], [13], [14], gi ven by I gmi ∆ = sup s> 0 I gmi ( s ) , (58) where I gmi ( s ) ∆ = E log q ( X , Y ) s P x 0 ∈X p ( x 0 ) q ( x 0 , Y ) s . (59) As in the case of matched decoding, this definition can be recov ered from the error exponent, I gmi ( s ) = dE q 0 ( ρ, s ) dρ ρ =0 = lim ρ → 0 E q 0 ( ρ, s ) ρ . (60) W e next see that the generalized mutual information is equal to the BICM capacity of [8] when the metric (7) is used. Similarly to Section III, the result does not require the presence of an interleav er of infinite length. Further , the interleav er is actually not necessary for the random coding arguments. First, we ha ve the follo wing, May 28, 2018 DRAFT 14 Theor em 2: The generalized mutual information of the BICM mismatched decoder is equal to the sum of the generalized mutual informations of the independent binary-input parallel channel model of BICM, I gmi = sup s> 0 m X j =1 E " log q j ( b j , Y ) s 1 2 P 1 b 0 =0 q j ( b 0 j , Y ) s # . (61) The expectation is carried out according to the joint distribution p j ( b j ) p j ( y | b j ) , with p j ( b j ) = 1 2 . Pr oof: For a gi ven s , and uniform inputs, i.e., p ( x ) = 1 2 m , Eq. (59) gi ves I gmi ( s ) = E " log Q m j =1 q j b j ( X ) , Y s P x 0 1 2 m Q m j =1 q j b j ( x 0 ) , Y s # . (62) W e no w hav e a closer look at the denominator in the logarithm of (62). The key observ ation here is that the sum ov er the constellation points of the product o ver the binary label positions can be expressed as the product over the label position is the sum of the probabilities of the bits being zero and one, i.e., X x 0 1 2 m m Y j =1 q j b j ( x 0 ) , Y s = 1 2 m m Y j =1 q j ( b 0 j = 0 , Y ) s + q j ( b 0 j = 1 , Y ) s (63) = m Y j =1 1 2 q j ( b 0 j = 0 , Y ) s + q j ( b 0 j = 1 , Y ) s ! . (64) Rearranging terms in (62) we obtain, I gmi ( s ) = E " m X j =1 log q j b j ( x ) , Y s 1 2 q j ( b 0 j = 0 , Y ) s + q j ( b 0 j = 1 , Y ) s # (65) = m X j =1 1 2 1 X b =0 1 2 m − 1 X x ∈X j b E " log q j b j ( x ) , Y s 1 2 P 1 b 0 =0 q j ( b 0 j , Y ) s # , (66) the expectation expectation being done according to the joint distribution p j ( b j ) p j ( y | b j ) , with p j ( b j ) = 1 2 . There are a number of interesting particular cases of the above theorem. Cor ollary 1: For the classical BICM decoder with metric in Eq. (7), I gmi = C bicm X . (67) Pr oof: Since the metric q j ( b j , y ) is proportional to p j ( y | b j ) , we can identify the quantity E log q j B j , Y s 1 2 P 1 b 0 j =0 q j ( b 0 j , Y ) s (68) May 28, 2018 DRAFT 15 as the generalized mutual information of a matched binary-input channel with transitions p j ( y | b j ) . Then, the supremum ov er s is achiev ed at s = 1 and we get the desired result. Cor ollary 2: For the max-log metric in Eq. (11), I gmi = sup s> 0 m X j =1 E " log max x ∈X B j p ( y | x ) s 1 2 P 1 b =0 max x 0 ∈X j b p ( y | x 0 ) s # . (69) Szczecinski et al. studied the mutual information with this decoder [16], using this formula for s = 1 . Clearly , the optimization ov er s may induce a larger achiev able rate, as we see in the next section. More generally , as we shall see later , letting s = 1 / (1 + ρ ) in the mismatched error exponent can yield some degradation. E. BICM with mismatc hed decoding: numerical results The data-processing inequality for error exponents yields E bicm 0 ( ρ, s ) ≤ E cm 0 ( ρ ) , where the quantity in the right-hand side is the coded modulation exponent. On the other hand, no gen- eral relationship holds between E ind 0 ( ρ ) and E cm 0 ( ρ ) . As it will be illustrated in the following examples, there are cases for which E cm 0 ( ρ ) can be larger than E ind 0 ( ρ ) , and vice versa. Figures 2, 3 and 4 show the error exponents for coded modulation (solid), BICM with independent parallel channels (dashed), BICM using mismatched metric (7) (dash-dotted), and BICM using mismatched metric (11) (dotted) for 16 -QAM with Gray mapping, Rayleigh fading and snr = 5 , 15 , − 25 dB, respectiv ely . Dotted lines labeled with s = 1 1+ ρ correspond to the error exponent of BICM using mismatched metric (11) letting s = 1 1+ ρ . The parallel-channel model gi ves a lar ger exponent than the coded modulation, in agreement with the cutoff rate results of [8]. In contrast, the mismatched-decoding analysis yields a lower exponent than coded modulation. As mentioned in the pre vious section, both BICM models yield the same capacity . In most cases, BICM with a max-log metric (11) incurs in a marginal loss in the exponent for mid-to-large SNR. In this SNR range, the optimized exponent and that with s = 1 1+ ρ are almost equal. F or lo w SNR, the parallel-channel model and the mismatched-metric model with (7) hav e the same exponent, while we observ e a larger penalty when metrics (11) are used. As we observe, some penalty is incurred at low SNR for not optimizing over s . W e denote with crosses the corresponding achie vable information rates. An interesting question is whether the error exponent of the parallel-channel model is always larger than that of the mismatched decoding model. The answer is negati ve, as illustrated in May 28, 2018 DRAFT 16 Figure 5, which shows the error exponents for coded modulation (solid), BICM with independent parallel channels (dashed), BICM using mismatched metric (7) (dash-dotted), and BICM using mismatched metric (11) (dotted) for 8 -PSK with Gray mapping in the unfaded A WGN channel. V . E X T R I N S I C S I D E I N F O R M A T I O N Next to the classical decoder described in Section II, iterative decoders hav e also receiv ed much attention [3], [4], [5], [6], [7] due to their improved performance. Iterativ e decoders can also be modelled as mismatched decoders, where the bit decoding metric is now of the form q j ( b, y ) = X x 0 ∈X j b p ( y | x 0 ) Y j 0 6 = j ext j 0 b j 0 ( x 0 ) , (70) where we denote by ext j ( b ) the extrinsic information, i.e., the “a priori” probability that the j -th bit takes the value b . Extrinsic information is commonly generated by the decoder of the binary code C . Clearly , we hav e that ext j (0) + ext j (1) = 1 , and 0 ≤ ext j (0) , ext j (1) ≤ 1 . W ithout extrinsic information, we tak e ext j (0) = ext j (1) = 1 2 , and the metric is gi ven by Eq. (7). In the analysis of iterativ e decoding, extrinsic information is often modeled as a set of random v ariables EXT j (0) , where we have defined without loss of generality the variables with respect to the all-zero symbol. W e denote the joint density function by p (ext 1 (0) , . . . , ext m (0)) = Q m j =1 p (ext j (0)) . W e discuss later ho w to map the actual extrinsic information generated in the decoding process onto this density . The mismatched decoding error exponent E q 0 ( ρ, s ) for metric (70) is giv en by Eq. (42), where the e xpectation is no w carried out according to the joint density p ( x ) p ( y | x ) p (ext 1 (0)) · · · p (ext m (0)) . Similarly , the generalized mutual information is again obtained as I gmi = max s lim ρ → 0 E q 0 ( ρ,s ) ρ . It is often assumed [5] that the decoding metric acquires kno wledge on the symbol x effecti vely transmitted, in the sense that for any symbol x 0 ∈ X , the j -th bit decoding metric is giv en by q j b j ( x 0 ) = b, y = X x 00 ∈X j b p ( y | x 00 ) Y j 0 6 = j ext j 0 b j 0 ( x 00 ) ⊕ b j 0 ( x ) , (71) where ⊕ denotes the binary addition. Observe that extrinsic information is defined relativ e to the transmitted symbol x , rather than relativ e to the all-zero symbol. If the j -th bit of the symbols x 00 and x coincide, the extrinsic information for bit zero ext j (0) is selected, otherwise the extrinsic information ext j (1) is used. May 28, 2018 DRAFT 17 For the metric in Eq. (71), the proof presented in Section IV -B of the data processing inequality fails because the integrand in Eq. (45) cannot be decomposed into a product of separate terms respecti vely depending on x and x 0 , the reason being that the metric q ( x 0 , y ) v aries with x . On the other hand, since the symbol metric q ( x 0 , y ) is the same for all symbols x 0 , the decomposition of the generalized mutual information as a sum of generalized mutual informations across the m bit labels in Theorem 2 remains valid, and we have therefore I gmi = m X j =1 E " log q j ( B j , Y ) 1 2 P 1 b 0 =0 q j ( b j = b 0 , Y ) # . (72) This expectation is carried out according to p ( b j ) p j ( y | b j ) p (ext 1 (0)) · · · p (ext m (0)) , with p ( b j ) = 1 2 . Each of the summands can be interpreted as the mutual information achiev ed by non-uniform signalling in the constellation set X , where the probabilities according to which the symbols are drawn are a function of the extrinsic informations ext j ( · ) . The value of I gmi may exceed the channel capacity [5], so this quantity is a pseudo-generalized mutual information, with the same functional form b ut lacking operational meaning as an achiev able rate by the decoder . Alternati vely , the metric in Eq. (70) may depend on the hypothesized symbol x 0 , that is q j b j ( x 0 ) = b, y = X x 00 ∈X j b p ( y | x 00 ) Y j 0 6 = j ext j 0 b j 0 ( x 00 ) ⊕ b j 0 ( x 0 ) . (73) Dif ferently from Eq. (71), the bit metric v aries with the hypothesized symbol x 0 and not with the transmitted symbol x . Therefore, Theorem 2 cannot be applied and the generalized mutual information cannot be expressed as a sum of mutual informations across the bit labels. On the other hand, the data processing inequality holds and, in particular , the error exponent and the generalized mutual information are upper bounded by that of coded modulation. Moreov er , we hav e the follo wing result. Theor em 3: In the presence of perfect extrinsic side information, the error exponent with metric (73) coincides with that of coded modulation. Pr oof: W ith perfect extrinsic side information, all the bits j 0 6 = j are kno wn, and then Y j 0 6 = j ext j 0 b j 0 ( x 00 ) ⊕ b j 0 ( x 0 ) = 1 when x 00 = x 0 , 0 otherwise, (74) which guarantees that only the symbol x 00 = x 0 is selected. Then, q j b j ( x 0 ) = b, y = p ( y | x 0 ) and the symbol metric becomes q ( x 0 , y ) = p ( y | x 0 ) m for all x 0 ∈ X . As we showed in Eq. (51), this May 28, 2018 DRAFT 18 is precisely the condition under which the error exponent (and the capacity) with mismatched decoding coincides that of coded modulation. The above result suggests that with perfect extrinsic side information, the gap between the error exponent (and mutual information) of BICM and that of coded modulation can be closed if one could provide perfect side information to the decoder . A direct consequence of this result is that the generalized mutual information with BICM metric (70) and perfect extrinsic side information is equal to the mutual information of coded modulation. An indirect consequence of this result is that the multi-stage decoding [17], [11] does not attain the exponent of coded modulation, e ven though its corresponding achiev able rate is the same. The reason is that the decoding metric is not of the form c p ( y | x ) s , for some constant c and s , except for the last bit in the decoding sequence. W e hasten to remark that the abov e rate in presence of perfect extrinsic side information need not be achiev able, in the sense that there may not exist a mechanism for accurately feeding the quantities ext j ( b ) to the demapper . Moreov er , the actual link to the iterati ve decoding process is open for future research. V I . C O N C L U S I O N S W e hav e presented a mismatched-decoding analysis of BICM, which is v alid for arbitrary finite-length interleav ers. W e ha ve proved that the corresponding generalized mutual information coincides with the BICM capacity originally gi ven by Caire et al. modeling BICM as a set of independent parallel channels. More generally , we ha ve seen that the error e xponent cannot be larger than that of coded modulation, contrary to the analysis of BICM as a set of parallel channels. For Gaussian channels with binary reflected Gray mapping, the gap between the BICM and CM error exponents is small, as found by Caire et al. for the capacity . W e hav e also seen that the mutual information appearing in the analysis of iterativ e decoding of BICM via EXIT charts admits a representation as a form of generalized mutual information. Howe ver , since this quantity may e xceed the capacity , its operational meaning as an achiev able rate is unclear . W e hav e modified the extrinsic side information av ailable to the decoder , to make it dependent on the hypothesized symbol rather than on the transmitted one, and shown that the corresponding error exponent is always lower bounded by that of coded modulation. In presence of perfect extrisinc side information, both error exponents coincide. The actual link to the iterativ e decoding process is open for future research. May 28, 2018 DRAFT 19 R E F E R E N C E S [1] E. Zehavi, “8-PSK trellis codes for a Rayleigh channel, ” IEEE T rans. Commun. , vol. 40, no. 5, pp. 873–884, 1992. [2] G. Ungerb ¨ ock, “Channel Coding W ith Multilev el/Phase Signals., ” IEEE T ransactions on Information Theory , vol. 28, no. 1, pp. 55–66, 1982. [3] X. Li and J. A. Ritcey , “Bit-interleav ed coded modulation with iterative decoding using soft feedback, ” Electronics Letters , vol. 34, no. 10, pp. 942–943, 1998. [4] X. Li and J. A. Ritcey , “Trellis-coded modulation with bit interleaving and iterativ e decoding, ” IEEE Journal on Selected Ar eas in Communications , vol. 17, no. 4, pp. 715–724, 1999. [5] S. ten Brink, “Designing iterativ e decoding schemes with the extrinsic information transfer chart, ” AEU Int. J. Electr on. Commun , vol. 54, no. 6, pp. 389–398, 2000. [6] S. ten Brink, J. Speidel, and R.H. Han, “Iterativ e demapping for QPSK modulation, ” Electr onics Letters , vol. 34, no. 15, pp. 1459–1460, 1998. [7] S. ten Brink, “Conv ergence of iterative decoding, ” Electr onics Letters , vol. 35, pp. 806, 1999. [8] G. Caire, G. T aricco, and E. Biglieri, “Bit-interleaved coded modulation, ” IEEE T rans. Inf. Theory , vol. 44, no. 3, pp. 927–946, 1998. [9] T . M. Cov er and J. A. Thomas, Elements of information theory , Wile y New Y ork, 1991. [10] J.M. W ozencraft and I.M. Jacobs, Principles of communication engineering , W iley , 1965. [11] U. W achsmann, R. F . H. Fischer , and J. B. Huber, “Multile vel codes: theoretical concepts and practical design rules, ” IEEE T rans. Inf. Theory , vol. 45, no. 5, pp. 1361–1391, Jul. 1999. [12] N. Merhav , G. Kaplan, A. Lapidoth, and S. Shamai Shitz, “On information rates for mismatched decoders, ” IEEE T rans. Inf. Theory , vol. 40, no. 6, pp. 1953–1967, 1994. [13] G. Kaplan and S. Shamai, “Information rates and error exponents of compound channels with application to antipodal signaling in a fading environment, ” AEU . Ar chiv f ¨ ur Elektr onik und ¨ Ubertragungstec hnik , vol. 47, no. 4, pp. 228–239, 1993. [14] A. Ganti, A. Lapidoth, and I. E. T elatar , “Mismatched decoding revisited: general alphabets, channels with memory , and the wideband limit, ” IEEE T rans. Inf. Theory , vol. 46, no. 7, pp. 2315–2328, 2000. [15] R. G. Gallager, Information Theory and Reliable Communication , John Wile y & Sons, Inc. New Y ork, NY , USA, 1968. [16] L. Szczecinski, A. Alv arado, R. Feick, and L. Ahumada, “On the distribution of L-values in gray-mapped M 2 -QAM signals: Exact expressions and simple approximations, ” in IEEE Global Commun. Conf, 26-30 November , W ashington, DC, USA , 2007. [17] H. Imai and S. Hirakawa, “A new multilevel coding method using error-correcting codes, ” IEEE T rans. Inf. Theory , vol. 23, no. 3, pp. 371–377, May 1977. May 28, 2018 DRAFT 20 Binary Encoder C m b Channel m . . . Channel j Channel 1 . . . Ξ 1 Ξ j Ξ m Fig. 1. Parallel channel model of BICM. May 28, 2018 DRAFT 21 0 0.5 1 1.5 2 0 0.2 0.4 0.6 0.8 1 R E r ( R ) Fig. 2. Error exponents for coded modulation (solid), BICM with independent parallel channels (dashed), BICM using mismatched metric (7) (dash-dotted), and BICM using mismatched metric (11) (dotted) for 16 -QAM with Gray mapping, Rayleigh fading and snr = 5 dB. May 28, 2018 DRAFT 22 0 0.5 1 1.5 2 2.5 3 3.5 0 0.5 1 1.5 2 2.5 3 R E r ( R ) Fig. 3. Error exponents for coded modulation (solid), BICM with independent parallel channels (dashed), BICM using mismatched metric (7) (dash-dotted), and BICM using mismatched metric (11) (dotted) for 16 -QAM with Gray mapping, Rayleigh fading and snr = 15 dB. May 28, 2018 DRAFT 23 0 1 2 3 4 5 x 10 −3 0 0.5 1 1.5 2 2.5 x 10 −3 R E r ( R ) s = 1 1 + ρ Fig. 4. Error exponents for coded modulation (solid), BICM with independent parallel channels (dashed), BICM using mismatched metric (7) (dash-dotted), and BICM using mismatched metric (11) (dotted) for 16 -QAM with Gray mapping, Rayleigh fading and snr = − 25 dB. Crosses correspond to (from right to left) coded modulation, BICM with metric (7), BICM with metric (11) and BICM with metric (11) with s = 1 . May 28, 2018 DRAFT 24 0 0.5 1 1.5 2 0 0.5 1 1.5 R E r ( R ) Fig. 5. Error exponents for coded modulation (solid), BICM with independent parallel channels (dashed), BICM using mismatched metric (7) (dash-dotted), and BICM using mismatched metric (11) (dotted) for 8 -PSK with Gray mapping, A WGN and snr = 5 dB. May 28, 2018 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment