Assessment of effective parameters on dilution using approximate reasoning methods in longwall mining method, Iran coal mines
Approximately more than 90% of all coal production in Iranian underground mines is derived directly longwall mining method. Out of seam dilution is one of the essential problems in these mines. Therefore the dilution can impose the additional cost of…
Authors: - H. Owladeghaffari - K. Shahriar - G. H. R. Saeedi
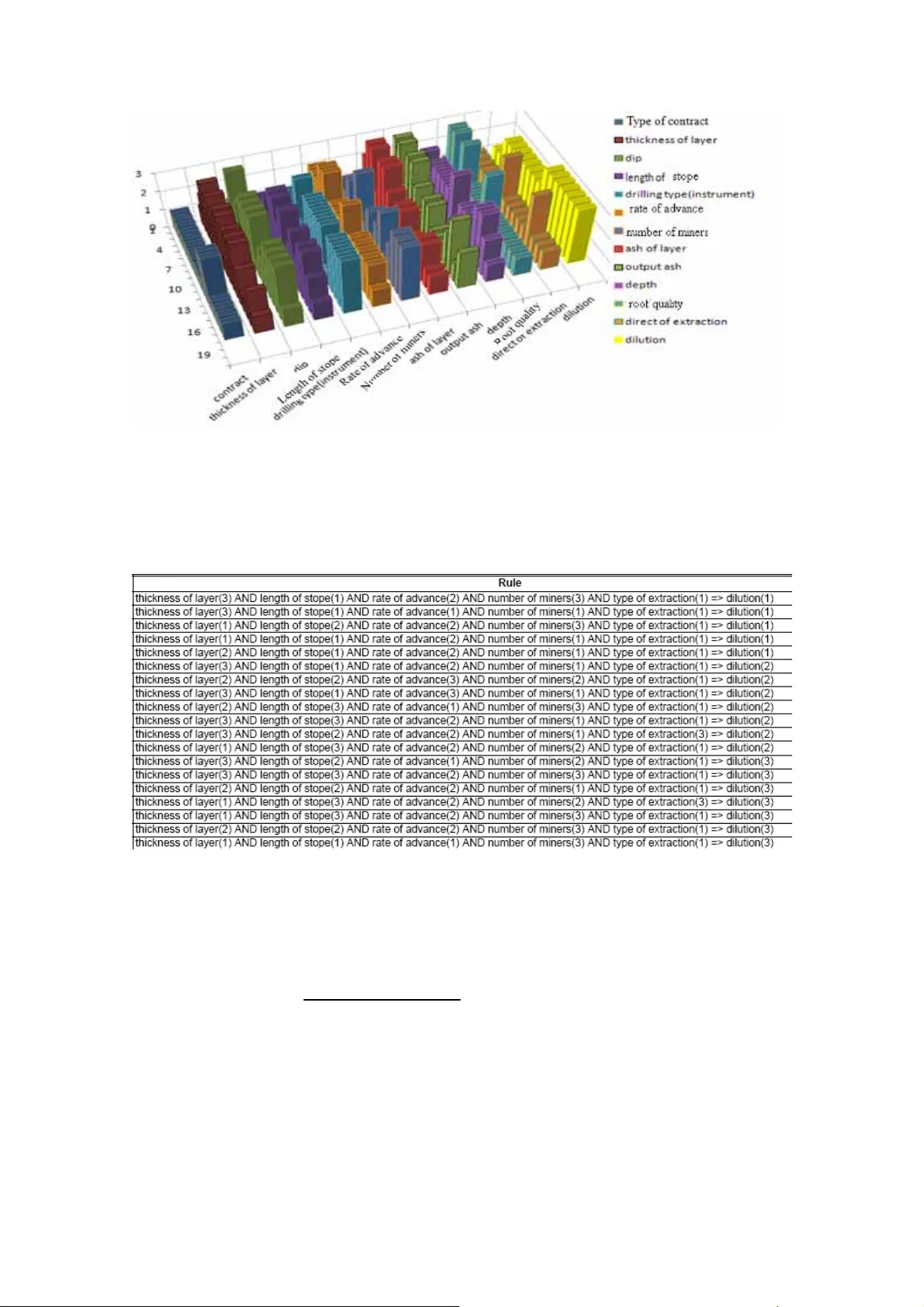
1 INTRODUCTION The dilution, as employed in mining, is on the reduction of the content of applicable constituents in the extracted ore as compared to their proportion in the mass of ore in the place (Popov, 1971). The main route of dilu tion can be ensued in extraction step where imminent extra costs in several levels of mining, mineral processing and envi- ronmental will be inevitable. As well as other applied m ethods in different streams of mining engineering to analysis of rock based system, in investigation of dilution, so, two known strategies cab be highlighted: direct methods and indirect m ethods. In first situation one can consider the real and simp lified param eters on the dilution in order to the real mining procedure system are transferred in to the accessible mathematical model. The distinguished approaches, in this field, are analytical and numerical mod- eling (Henning&Mitri, 2000) while former op tion is based on the direct calculations and latter case come from “computational” processes. In facing of theses m ethodolo- gies, indirect emulation of an event is based upon the humanity performance as well as historical aggregation of experts’ expe riences or the mimicked intelligent systems upon the individuality or society behaviors of glory creatures. Due to being of many agents in the recognizing of most m ain parameters on the dilution, representing of several definitions and relations ,along successive years, has been unavoidable for ex- ample see (Pakalnis et al, 1995). Considering of the thumb relation using simp le and available param eters can be pre- sumed as an overall measure that covers direct and indirect operators on the decision part. In fact, such a relation is an escape road from the complexity of problem while other unapparent factors take marginal guise. To bate of this fact, we refer to the reac- tions of real natural complex systems with their intricate circumstances. The emer- gence of such systems can be appeared in natural computing m ethods (not 1-1 map- ping models) involved me thods inspired in our nature as well as in microscopic or macroscopic view, i.e., neural comput ations, approximate reasoning(AR) me- thods(handling of vagueness and uncertainty ,…), evolutionary algorithms, artificial life, and artificial immune systems, quantum computing and so forth. In this study we employ approximate reasoning m ethods to analysis of dilution and based upon two main subsets of AR, Rough Set Theory and Fuzzy inference system, the position of ef- fective parameters are recognizes and evaluated. Assessment of effective paramet ers on dilution using approximate reasoning methods in longwall mining method, Iran coal mines H.Owladeghaffari, K.Shahriar & GH.R.Saeedi Department of Mi ning &Metallurgical Engineering, Amirka bir university of Technol ogy, Tehran, Iran ABSTRACT: Approximately more than 90% of all coal production in Iranian undergroun d mines is derived directly longwall mining me thod. Out – of – seam dilution ( namely 20-30 %) is one of the essential problems in these mines. Therefore the dilution can impose the additional cost of mining and milling. As a result, recogniti on of the effective parameters on the dilution has a remarkable role in industry. In this way, this paper has analyzed the influence of 13 para- meters (attributed variables) versus the decision attribute (dilution value), so that using two ap - proximate reasoning methods, name ly Rough Set Theory (RST) and Self Organizing Neuro- Fuzzy Inference System (SONFIS) the best rules on our collected data sets has been extracted. The other benefit of later methods is to pr edict new unknown cases. So , the reduced sets (re- ducts) by RST have been obtained. Therefore the emerged results by utilizing mentioned me- thods shows that the high sensitive variables are “t hickness of layer, length of stope, rate of ad- vance, number of miners, type of advanc ing”. 2 PERSPECTIVE OF METHODS To dissection of different attributes effects on th e dilution, we’ll use some of the main ap- proaches in the data engineering field, as well as sociated with intelligent computational and ap- proximate reasoning methods which based on them a new algorithm SONFIS will be proposed. 2.1 Rough set theory (RST) The rough set theory introduced by Pawlak (Paw lak1981, 1982) has often pro ved to be an excel- lent mathematical tool for the analysis of a va gue description of object. The adjective vague re- ferring to the quality of information means inconsistency, or ambiguity which follows from in- formation granulation. An information system is a pair S=< U, A > , where U is a nonempty finite set called the universe and A is a nonempty finite set of attributes. An attribute a can be regarded as a function from the domain U to some value set a V . An information system can be represented as an attribute-value table, in which rows are labeled by objects of the universe and columns by attributes. With every subset of attributes B ⊆ A , one can easily associate an equi- valence relation B I on U : {( , ) : , ( ) ( )} B Ix y U f o r e v e r y a B a x a y =∈ ∈ = (1) Then, B aB a II ∈ = I . If XU ⊆ ,the sets [ ] {: } x Ux X B ∈ ⊆ and [ ] {: } B xU x X ϕ ∈≠ I , where [ ] B x denotes the equi- valence class of the object x U ∈ relative to B I , are called the B-lower and the B-upper ap- proximation of X in S and denoted by B X and B X , respectively. Consider 12 n {x , x , ...,x } U = and 12 n {a , a , ...,a } A = in the information system S= U, A pf . By the discernibility matrix M(S) of S is meant an n*n m atrix such that { } :( ) ( ) ij i j ca A a x a x =∈ ≠ (2) A discernibilty function s f is a function of m Boolean variables 1 ... m aa corresponding of attribute 1 ... m aa , respectively, and defined as follows: where () ij c ∨ is the disjunction of all variables with ij ac ∈ .Using such discriminant matrix the appropriate rules are elicited (Pal et al, 2004) .Indiscernibility relation (similarity) reduces the data by defining of equivalence classes, under the present attributes. Reduction of attributes (conditions) can be utilized by keeping of the attri butes that maintain the similarity relation. The underway of idea behind finding out of reducts is the preserving of general information state with minimum attributes, and so superf luous attributes are eliminated. In equation (3), it can be proved that { } 1 ,. . . , r ii aa is a reduct in S iff 1 ... r ii aa ∧ ∧ is a prime implicant of s f .In our work, rule induction procedure was implemented within t he ROSETA software system, a rough set tool-kit for knowledge discovery and da ta mining ( φ hm et al,1998). 2.2 Neuro-Fuzzy Inference System (NFIS) There are different alternatives of fuzzy inference systems. Two well-known fuzzy modeling methods are the Tsukamoto fuzzy model and Takagi– Sugeno–Kang (TSK) model. In the present study, we focus on the TSK. The TSK fu zzy inference systems can be impl anted in the form of a Neuro-fuzzy network structure .In this study, we have employed an adaptive neuro- fuzzy inference system (Jang et al, 1997), within the general structure of SONFIS. 1 ( , ..., ) { ( ) : , , , } sm i j i j f aa c i j n j i c ϕ =∧ ∨ ≤ ≠ p (3) One of the most important stages of the Neur o-fuzzy TSK network generation is the establish- ment of the inference rules. Often employed me thod is used t he so-called grid method, in which the rules are defined as the combinations of th e membership functions for each input variable. If we split the input variable range into a limited number (say i n for i=1, 2... n ) of mem bership functions, the combinations of them lead to many different inference rules. The problem is that these combinations correspond in many cases to the regions of no data, and hence a lot of them may be deleted. This pr oblem can be solved by using the fuzzy self- organization algorithm. This algorithm splits the data space into a specified number of overlap- ping clusters. Each cluster may be associated with the specific rule of the center corresponding to the center of the appropriate cluster. In th is way all rules correspond to the regions of the space-containing majority of data and the problem of the empty rules can be avoided. The ulti- mate goal of data clustering is to partition the da ta into similar subgroups. This is accomplished by employing some sim ilar measures -e.g ., the Euclidean distance-(Nauk et al, 1997). In this paper data clustering is used to derive m embership functions from measured data, which, in turn, determine the number of If-Then rules in the model (i.e., rules indication). The method employed in this paper is the subtractive clustering method, proposed by Chiu as one of the simplest clustering m ethods (Chiu, 1994). 2.3 Self-Organizing feature Map (SOM) Kohonen’s SOM algorithm has been well renowned as an ideal candidate for classifying input data in an unsupervised learning way. Kohonen self-organizing networks (Kohonen feature maps or topology-preserving maps) are competiti on-based network paradi gm for data cluster- ing. The learning procedure of Kohonen feature ma ps is similar to the competitive learning net- works. The main idea behind competitive learning is simple; the winner takes all. The competitive transfer function returns neural outputs of 0 for all neurons except for the win- ner which receives the highest net input with out put 1. SOM changes all weight vectors of neu- rons in the near vicinity of the winner neuron towards the inp ut vector. Due to this property SOM, are used to reduce the dimensionality of complex data (data clustering). Competitive lay- ers will automatically learn to classify input vectors, the classes that the competitive layer finds are depend only on the distances between input vectors (Kohonen, 1986). 2.4 A combining of SOM&NFIS: SONFIS In this part, we reproduce the proposed a hybrid intelligent algorithm in (Owladeghaffari et al, 2008): Step (1): dividing the m onitored data in to groups of training and testing data Step (2): first granulation (clustering) by SOM or other crisp granulation methods Step (2-1): selecting the level of granularity randomly or depend on the obtained error from the NFIS or RST (regular neuron growth) Step (2-2): construction of the granules (no-fuzzy clusters). Step (3): second granulation by NFIS or RST Step (3-1): crisp granules as a new data. Step (3-2): selecting the level of granularity ; (Error level, number of rules, strength thre- shold...) Step (3-3): checking the suitability. (Close-open iteration: referring to the real data and reins- pect closed world) Step (3-4): construction of fuzzy/rough granules. Step (4): extraction of knowledge rules Balancing assumption is satisfied by the close-ope n iterations: this process is a guideline to ba- lancing of crisp and sub fuzzy/r ough granules by some random/re gular selection of initial gra- nules or other optimal structures and increment of supporting rule s (fuzzy partitions or increas- ing of lower /upper approximations ), graduall y. In this study, we use only two known intelligent systems: SOM&NFIS. The overall sche matic of Self Organizing Neuro-Fuzzy Infe- rence System -Random -: SONFIS-R has been shown in figure1. Figure 1. Self Organi zing Neuro-Fuzzy I nference System: SONFIS-R (Owladegha ffari et al, 2008) 3 RESULTS Figure 2 shows an overall view of the collected data set in a few coal mines, Iran. To employing of the mentioned m ethods, we must ascribe some appropriate codes to some qua- litative attributes (table 1). In first situation, to obtain most main conditional parameters on the dilution, we use RST. After this step, by applyi ng SONFIS-R the simplest rules companion with their memberships functions are displaced. So, on those rules graphical relations of reduct’s members are highlighted. In the whole of this paper, we select 21 objects among 30 patterns as training data set and the remained objects get testing data facet. With considering this point that the creation of discernible matrix-in RST- is depend on the transferring of data in to the arbitrary-or best - ranges (bins)-symbolic va lues-, we employ one dimensional topology grid SOM, in which attr ibutes are transferred within 3 categories: low ( 1), medium (2) and high (3) (fig3).Then, the categorized attributes as an information table are as- sessed by the RST. Figure 2.3D Column view of the accumulated da ta set and the appropriate decision table Table1.attribut ed codes to som e parameters Attributes Ascribed codes Contract Type Contract wor k =1 ;Service(state)=2 Drillin g Instrument Pic=1 ;Drillin g &blastin g =2 Direct of Extra ction Forward= 1 ;Backward=2 Type of Floor Roc k Argillite=1 ;Sandy rock=2 Figure 3. Result of transferring attrib utes in three categories over the tr aini ng data set (ve rtical axis) by 1- D SOM The obtained reduct set, by Johnson’s reduct algorith m is: {thickness of layer, length of stope, rate of advance, number of mi ners, type of extraction}. Under this set, 19 rules are produced and on the test data are evaluated (figs4, 5). The qua lity and accuracy of rules can be identified us- ing different criteria ( φ hm, 1998). Figure 4. The elicited rules -by RST (notice: here type of ascribed extraction type code transfer to 1&3) Analysis of second situation is started off by setting num ber of close-open iteration and maximum number of rules equal to 15 and 4 in SONFIS-R, respectively. The error measure criterion in SONFIS is mean square error (MSE): 2 1 () m r ea l cla ssified ii i dd MSE m = − = ∑ ( 4) where m is the number of test data . Figure 6(a&b) indicate the results of the aforesaid system (so, performance of selected SONFIS-R on the test data). In this case, we set the range of first granules (crisp clusters) between 5 and 20, as well as lower and upper floor. So, the number of leanings in second layer of SONFIS is supposed as a constant value, i.e., 20, for all inserted crisp granules. Add to this, we use Gaussian membership functions in fuzz y clustering. After 45 time steps (15 for each rule), the minimum MSE is come out in 17 neurons in SOM and 2 rules in NFIS (figures 7, 8 and table 2). Figure 5. Answer of RST (based on th e extracted rules) on the test data Figure 6. a) SONFIS-R resul ts with ma ximum number o f rules 4 an d close-open ite rations 10; b) Answer of selected (winner) SONFIS-R on the test data Figure 7. The results of clust ered training dat a set by selected best SOM (17*1 ne urons) by SONFI S-R The results of first granulation by 17*1 neurons in competitive layer of SOM has been portrayed in figure 7, as matrix plot form. It must be notice here; we reduced all of objects in to the 17 patterns, which are in balance with the simplest rules of NFIS, while we had employed error measure criteria to balancing. SONFIS-R which has been employed in other comprehensive da- ta set, show ability of this system in detecti on of the dominant structures on the attributes and representation of the simplest rules, as well as one wishes to catch up (Owladeghaffari et al,2008). Figure 8. Fi nal mem bership functions of i nputs in S ONFIS-R Table2.Extrated rul es by NFIS in SONFIS -R ( in i (i=1:12 ) is agree with the decision table attributes and mf j(j=1,2) is proper wit h blue and green curves, respect ively. 1. If (in1 is in 1mf1) and (in2 is in2mf1) and (in3 is in3mf1) a nd (in4 is in4m f1) and (in5 is in5m f1) and (in6 is in6mf1) an d (in7 is in7mf1) and (in8 is in8m f1) and (in9 is in9mf1) and (i n10 is in10mf1) and (in11 is i n11mf1) a nd (in12 is i n12mf1) then ( f 1) 2. If (in1 is in 1mf2) and (in2 is in2mf2) and (in3 is in3mf2) a nd (in4 is in4m f2) and (in5 is in5m f2) and (in6 is in6mf2) an d (in7 is in7mf2) and (in8 is in8m f2) and (in9 is in9mf2) and (i n10 is in10mf2) and (in11 is in 11mf2) and (in12 is i n12mf2) then ( f2 ) It is noteworthy that the density of mem bership functions (fig8) and the histogram of variables appeared by SOM (fig7) have been coincided. Add to this in seco nd granulation level -Fuzzy rules- decision part of rules are in the linear (one order) form of premises ( f1&f2 in ta- ble2). In a supplementary way to take visual re lates on the most effective parameters based on the reduct members, we use the fuzzy rules on thos e attributes and decision part (fig 9). Figure 9 shows how dilution changes under the main effec tive parameters, produced by RST as a reduct set, for instance increasing of length of stope and thickness of layer raises the dilution values as well as rate of advance and dip pa rameters. In other sense, transf erring of advance face to back- ward will display a remarkable reduces in dilution rate. Figure 9.The 3D relatio ns on the redu ct set memb ers and dilution by extracted rules of SONFIS-R 4 CONCLUSION To better controlling of dilution ra te in coal mines, considering of the high scope of variables will be undeniable. Under this view and “Information bears on uncertainty”, we employed two main algorithms: Self Organizing Neuro-Fuzzy Inference System (Random) SONFIS-R and Rough Set Theory, to analysis of dilution in a few Iranian coal m ines. So, the reduced set by RST, among 13 effective pa rameters on decision part, has been obtained. These attributes upon the best fuzzy rules-in bala nce with reduced objects- exhibit more details of dependency variations, as if nearly concurre d with the crisp granules (SOM weights).The emerged results by utilizing mentioned methods shows that the high sensitive variables are “thickness of layer, length of stope, rate of advance, num ber of miners, type of extraction”. REFERENCES 1. Chiu, S, L., 1994, “Fuzzy m odel identification base d on cluster estimation, Journal of intelligent and fuzzy systems , 2 (3). 2. Jang, J. S. R., Sun, C. T., and Mizutani, E. 1997. Neuro- Fuzzy and Soft Compu ting . Newjer- sy:Pretice Hall. 3. Henning,J.G., and Mitri,H.S. 2007 . Numerical Modeling of Ore Di lution in Blast hole Stopni g , Int J Rock Mc h Min Sci ,44, pp:692-70 3 4. Kohonen, T.1987. Self-Organizatio n and Associat e Memory . 2nd Ed, Springer – Verlag: Berlin . 5. Nauk,D., Klawoo n,F., and Kruse, R .1997. Foundat ions of Neuro-F uzzy Systems , John Wiley and Sons 6. Owladeghaffari, H., Shahrair, K. & Pedrycz, W. 2008. Graphical Estimation of Permeability Us- ing RST&NF IS, NAFIPS 20 08 New York, May 19-22, avail able at: http:/ 7. Owladeghaffa ri,H, Sharifza deh,M., Shahrai r,K.&Bakhtavar ,E..2008. Mode ling in rock en gineer- ing based on informati on granulation t heory”, Accept ed in “ 42nd U.S. Rock Mechanics Sympo- sium & 2nd U.S.-Canada Rock Mechan ics Symposium , San Francisco, CD-ROM. 8. Pakalnis, R., Poulin, R.andHad jieorgiou, J.1995. Quantifying the Cost of Dilution in Un derground Mines, SME Annual Meta llurgy and Explora tion, Denver. 9. Pal, S.K. & Mitra, P. 2004. Pattern Recognition Algorithms for Data Mining .Ch man&Hall/CRC:Boca Raton. 10. Pawlak, Z.1982. Rough sets. Int J Comput Inform Sc i 11: 341-35 6. 11. Pawlak, Z.1991. Rough Sets: Theoretical Aspects Reasoning a bout Data . Kluwer acade mic, Bos- ton. 12. Popov, G.1971. The Workin g of Mineral De posits , Mir P ublisher, Moscow. 13. φ hm , A., Komorowski, J., S kowron, A., and Sy nak, P.1998. The ROSSETA soft ware system, L.Polkowski and A.Skow ron (Eds), Ro ugh Sets in Kn owledge Discover y 2: Applicati ons, Case Studies and So ftware Systems , Physi ca-Verlag Heidelbe rg, pp: 572-576.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment