Crowding at the Front of the Marathon Packs
We study the crowding of near-extreme events in the time gaps between successive finishers in major international marathons. Naively, one might expect these gaps to become progressively larger for better-placing finishers. While such an increase does indeed occur from the middle of the finishing pack down to approximately 20th place, the gaps saturate for the first 10-20 finishers. We give a probabilistic account of this feature. However, the data suggests that the gaps have a weak maximum around the 10th place, a feature that seems to have a sociological origin.
💡 Research Summary
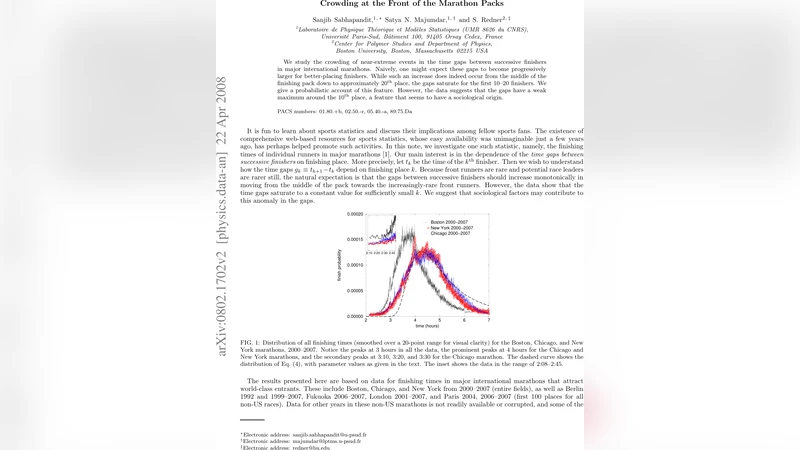
The paper investigates the statistical properties of the time gaps between successive finishers in major international marathons, focusing on the behavior of the gaps for the leading pack of runners. Using publicly available finish‑time data from the Boston, Chicago, and New York City marathons for the years 2000–2007 (as well as selected data from Berlin, London, and Paris), the authors compute the gap gₖ = tₖ₊₁ − tₖ for each finishing place k. The overall distribution of finish times shows pronounced peaks at 3 h (all three U.S. races) and at 4 h (Chicago and New York), with secondary peaks at 3:10, 3:20, and 3:30 in Chicago, suggesting psychological “time barriers” rather than pure physiological limits.
When the average gap ⟨gₖ⟩ is plotted versus rank, a clear pattern emerges: for ranks beyond roughly 20 the gaps decrease roughly as 1/k, reflecting the increasing density of finishers as the bulk of the field arrives. However, for the first 10–20 finishers the gaps do not follow this monotonic decline; instead they plateau at a roughly constant value (20–60 s) and even show a modest maximum around the 10th place, especially in the U.S. races where the largest gap appears between 5th and 6th place. This “saturation” contradicts the naive expectation that elite runners, being rarer, should be more widely spaced.
To explain these observations, the authors model finish times as independent, identically distributed (i.i.d.) random variables drawn from a parent distribution P(t). Using extreme‑value statistics, they derive the typical k‑th order statistic tₖ from the condition
∫₀^{tₖ} P(t) dt ≈ k/N,
where N is the total number of participants. They then compute the mean gap ⟨gₖ⟩ analytically for three illustrative parent distributions: (i) a uniform distribution, (ii) an increasing linear distribution, and (iii) a decreasing exponential distribution. The uniform case yields a constant gap independent of k, the increasing case gives ⟨gₖ⟩ ∝ 1/√k, and the decreasing case produces ⟨gₖ⟩ ∝ 1/(N − k).
For a more realistic marathon model they propose a distribution with a hard lower cutoff at the fastest possible time t_min and a rapid exponential tail:
P(t) = m T^{m} (t − t_min)^{-(m+1)} exp
Comments & Academic Discussion
Loading comments...
Leave a Comment