Bayesian Inference on Mixtures of Distributions
This survey covers state-of-the-art Bayesian techniques for the estimation of mixtures. It complements the earlier Marin, Mengersen and Robert (2005) by studying new types of distributions, the multinomial, latent class and t distributions. It also e…
Authors: Kate Lee, Jean-Michel Marin, Kerrie Mengersen
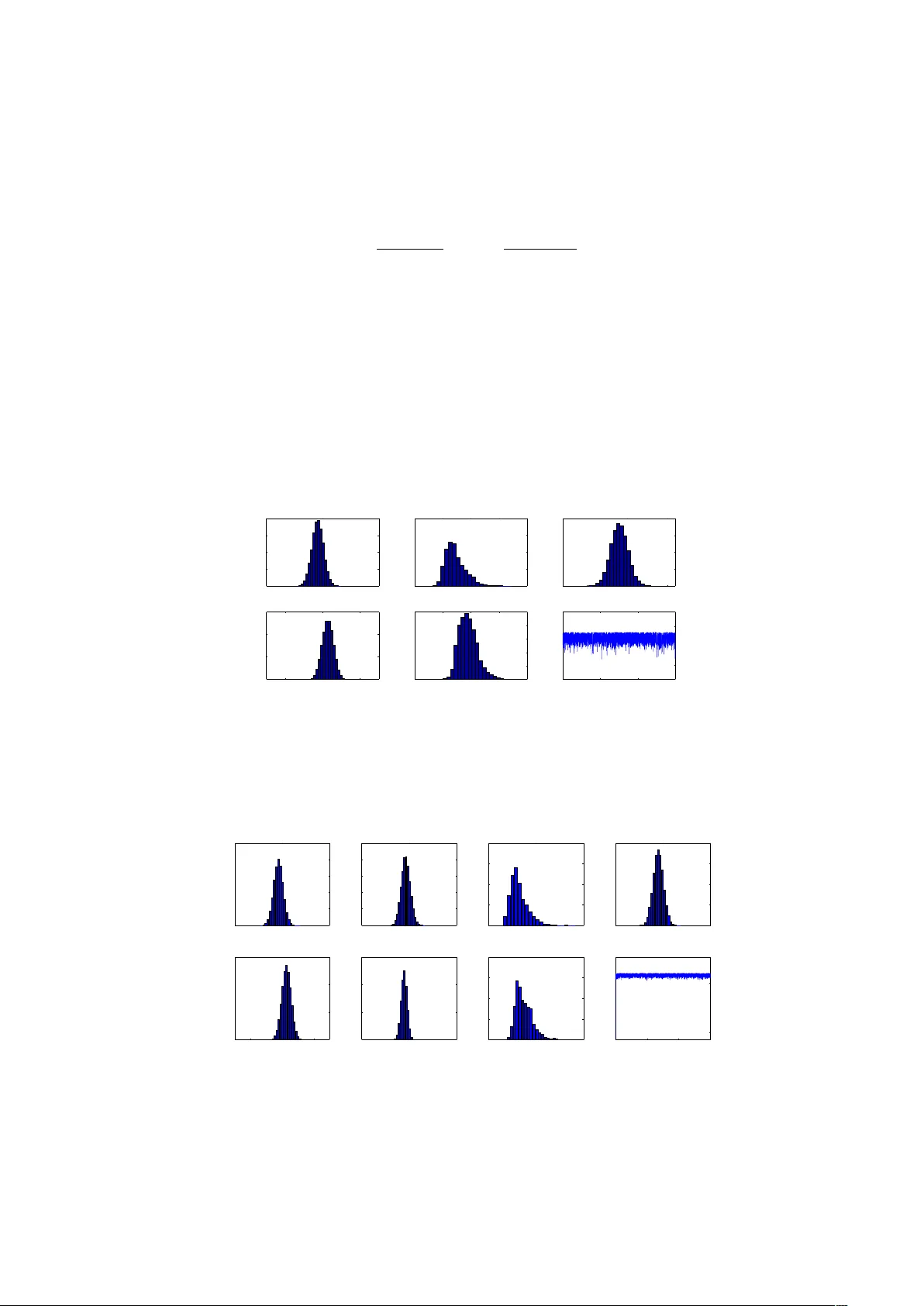
Ba y esian Inference on Mixtures of Distributions ∗ Kate Lee Queensland Univ ersity of T ec hnology Jean-Mic hel Marin INRIA Sacla y , Pro jet select , Univ ersit´ e P aris-Sud and CREST, INSEE Kerrie Mengersen Queensland Univ ersity of T ec hnology Christian Rob ert Univ ersit´ e P aris Dauphine and CREST, INSEE August 24, 2018 Abstract This surv ey cov ers state-of-the-art Bay esian tec hniques for the estimation of mixtures. It comple- men ts the earlier Marin et al. (2005) b y studying new t yp es of distributions, the m ultinomial, laten t class and t distributions. It also exhibits closed form solutions for Ba yesian inference in some discrete setups. Lastly , it sheds a new ligh t on the computation of Ba yes factors via the appro ximation of Chib (1995). 1 In tro duction Mixture mo dels are fascinating ob jects in that, while based on elemen tary distributions, they offer a m uch wider range of mo deling p ossibilities than their comp onents. They also face b oth highly complex computational challenges and delicate inferential deriv ations. Many statistical adv ances ha ve stemmed from their study , the most sp ectacular example being the EM algorithm. In this short review, we c ho ose to fo cus solely on the Ba yesian approac h to those models (Rob ert and Casella 2004). F r ¨ uh wirth-Schnatter (2006) pro vides a b o ok-long and in-depth co verage of the Bay esian pro cessing of mixtures, to which we refer the reader whose in terest is wok en by this short review, while MacLac hlan and Peel (2000) giv e a broader persp ective. Without op ening a new debate ab out the relev ance of the Ba yesian approac h in general, we note that the Ba yesian paradigm (see, e.g., Rob ert 2001) allo ws for probability statements to b e made directly ab out the unkno wn parameters of a mixture mo del, and for prior or exp ert opinion to be included in the analysis. In addition, the latent structure that facilitates the description of a mixture model can b e naturally aggregated with the unknown parameters (even though laten t v ariables are not parameters) and a global p osterior distribution can b e used to draw inference ab out both asp ects at once. This surv ey th us aims to in tro duce the reader to the construction, prior mo delling, estimation and ev aluation of mixture distributions within a Ba yesian paradigm. F o cus is on b oth Ba yesian inference and computational techniques, with light shed on the implementation of the most common samplers. W e also show that exact inference (with no Monte Carlo approximation) is achiev able in some particular settings and this leads to an interesting b enchmark for testing computational metho ds. ∗ Kate Lee is a PhD candidate at the Queensland Universit y of T ec hnology , Jean-Michel Marin is a researcher at INRIA, Universit ´ e Paris Sud, and adjunct professor at ´ Ecole Polytec hnique, Kerrie Mengersen is professor at the Queensland Universit y of T ec hnology , and Christian P . Robert is professor in Univ ersit´ e Paris Dauphine and head of the Statistics Laboratory of CREST. 1 In Section 2, we introduce mixture mo dels, including the missing data structure that originally app eared as an essential comp onent of a Ba yesian analysis, along with the precise deriv ation of the exact p osterior distribution in the case of a mixture of Multinomial distributions. Section 3 points out the fundamen tal difficult y in conducting Bay esian inference with such ob jects, along with a discussion ab out prior mo delling. Section 4 describ es the appropriate MCMC algorithms that can b e used for the approximation to the p osterior distribution on mixture parameters, follo wed b y an extension of this analysis in Section 5 to the case in whic h the n umber of comp onents is unkno wn and ma y b e derived from approximations to Ba yes factors, including the tec hnique of Chib (1995) and the robustification of Berkhof et al. (2003). 2 Finite mixtures 2.1 Definition A mixture of distributions is defined as a con vex combination J X j =1 p j f j ( x ) , J X j =1 p j = 1 , p j > 0 , J > 1 , of standard distributions f j . The p j ’s are called weights and are most often unknown. In most cases, the in terest is in ha ving the f j ’s parameterised, each with an unkno wn parameter θ j , leading to the generic parametric mixture mo del J X j =1 p j f ( x | θ j ) . (1) The dominating measure for (1) is arbitrary and therefore the nature of the mixture observ ations widely v aries. F or instance, if the dominating measure is the coun ting measure on the simplex of R m S m,` = ( ( x 1 , . . . , x m ); m X i =1 x i = ` ) , the f j ’s may b e the product of ` indep endent Multinomial distributions, denoted “ M m ( ` ; q j 1 , ..., q j m ) = ⊗ ` i =1 M m (1; q j 1 , ..., q j m )”, with m mo dalities, and the resulting mixture J X j =1 p j M m ( ` ; q j 1 , . . . , q j m ) (2) is then a p ossible model for rep eated observ ations taking place in S m,` . Practical o ccurrences of suc h mo dels are rep eated observ ations of c ontingency tables . In situations when contingency tables tend to v ary more than exp ected, a mixture of Multinomial distributions should b e more appropriate than a single Multinomial distribution and it may also con tribute to separation of the observ ed tables in homogeneous classes In the follo wing, we note q j · = ( q j 1 , . . . , q j m ). Example 1. F or J = 2, m = 4, p 1 = p 2 = . 5, q 1 · = ( . 2 , . 5 , . 2 , . 1), q 2 · = ( . 3 , . 3 , . 1 , . 3) and ` = 20, we sim ulate n = 50 independent realisations from mo del (2). That corresp onds to simiulate some 2 × 2 con tingency tables whose total sum is equal to 20. Figure 1 gives the histograms for the four entries of the con tingency tables. J Another case where mixtures of Multinomial distributions o ccur is the latent class mo del where d discrete v ariables are observed on eac h of n individuals (Magidson and V ermun t 2000). The observ ations (1 ≤ i ≤ n ) are x i = ( x i 1 , . . . , x id ), with x iv taking v alues within the m v mo dalities of the v -th v ariable. The distribution of x i is then J X j =1 p j d Y i =1 M m i 1; q ij 1 , . . . , q ij m i , 2 2 4 6 8 10 0.0 0.1 0.2 0.3 0.4 6 8 10 12 14 0.0 0.1 0.2 0.3 0.4 0 1 2 3 4 5 6 7 0.0 0.1 0.2 0.3 0.4 0.5 0 2 4 6 8 10 0.0 0.1 0.2 0.3 0.4 Figure 1: F or J = 2, p 1 = p 2 = . 5, q 1 · = ( . 2 , . 5 , . 2 , . 1), q 2 · = ( . 3 , . 3 , . 1 , . 3), ` = 20 and n = 50 indep endent sim ulations: histograms of the m = 4 entries. so, strictly sp eaking, this is a mixture of pr o ducts of Multinomials. The applications of this peculiar mo delling are numerous: in medical studies, it can b e used to asso ciate several symptoms or pathologies; in genetics, it may indicate that the genes corresp onding to the v ariables are not sufficien t to explain the outcome under study and that an additional (unobserved) gene may b e influen tial. Lastly , in marketing, v ariables ma y correspond to categories of products, mo dalities to brands, and components of the mixture to differen t consumer b ehaviours: iden tifying to which group a customer b elongs may help in suggesting sales, as on W eb-sale sites. Similarly , if the dominating measure is the coun ting measure on the set of the in tegers N , the f j ’s ma y b e Poisson distributions P ( λ j ) ( λ j > 0). W e aim then to mak e inference ab out the parameters ( p j , λ j ) from a sequence ( x i ) i =1 ,...,n of in tegers. The dominating measure ma y as well b e the Leb esgue measure on R , in which case the f ( x | θ )’s ma y all be normal distributions or Student’s t distributions (or even a mix of b oth), with θ representing the unkno wn mean and v ariance, or the unkno wn mean and v ariance and degrees of freedom, respectively . Suc h a mo del is appropriate for datasets presenting m ultimo dal or asymmetric features, like the aerosol dataset from Nilsson and Kulmala (2006) presented b elow. Example 2. The estimation of particle size distribution is imp ortan t in understanding the aerosol dynamics that go vern aerosol formation, whic h is of interest in en vironmental and health mo delling. One of the most imp ortan t ph ysical properties of aerosol particles is their size; the concen tration of aerosol particles in terms of their size is referred to as the p article size distribution. The data studied by Nilsson and Kulmala (2006) and represented in Figure 2 is from Hyyti¨ al¨ a, a measuremen t station in Southern Finland. It corresp onds to a full day of measurement, taken at ten min ute interv als. J While the definition (1) of a mixture mo del is elementary , its simplicity does not extend to the deriv ation of either the maximum lik eliho o d estimator (when it exists) or of Ba y es estimators. In fact, if w e tak e n iid observ ations x = ( x 1 , . . . , x n ) from (1), with parameters p = ( p 1 . . . , p J ) and θ = ( θ 1 , . . . , θ J ) , the full computation of the p osterior distribution and in particular the explicit represen tation of the corresp onding p osterior exp ectation in volv es the expansion of the likelihoo d L( θ , p | x ) = n Y i =1 J X j =1 p j f ( x i | θ j ) (3) 3 0 1 2 3 4 5 6 7 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Diameter (nm) Density Figure 2: Histogram of the aerosol diameter dataset, along with a normal (r e d) and a t (blue) modelling. in to a sum of J n terms. with some exceptions (see, for example Section 3). This is thus computationally to o exp ensive to be used for more than a few observ ations. This fundamen tal computational difficulty in dealing with the mo dels (1) explains why those mo dels hav e often b een at the forefront for applying new tec hnologies (suc h as MCMC algorithms, see Section 4). 2.2 Missing data Mixtures of distributions are typical examples of latent variable (or missing data ) mo dels in that a sample x 1 , . . . , x n from (1) can b e seen as a collection of subsamples originating from eac h of the f ( x i | θ j )’s, when b oth the size and the origin of each subsample may be unknown. Thus, each of the x i ’s in the sample is a priori distributed from an y of the f j ’s with probabilities p j . Dep ending on the setting, the inferential goal b ehind this modeling may b e to reconstitute the original homogeneous subsamples, sometimes called clusters , or to provide estimates of the parameters of the different comp onents, or even to estimate the num ber of comp onen ts. The missing data representation of a mixture distribution can be exploited as a technical device to facilitate (n umerical) estimation. By a demarginalisation argumen t, it is alwa ys possible to asso ciate to a random v ariable x i from a mixture (1) a second (finite) random v ariable z i suc h that x i | z i = z ∼ f ( x | θ z ) , P ( z i = j ) = p j . (4) This auxiliary v ariable z i iden tifies to which comp onent the observ ation x i b elongs. Dep ending on the fo cus of inference, the z i ’s may [or may not] b e part of the quantities to b e estimated. In any case, k eeping in mind the av ailability of such v ariables helps into drawing inference ab out the “true” parameters. This is the technique b ehind the EM algorithm of Dempster et al. (1977) as well as the “data augmen tation” algorithm of T anner and W ong (1987) that started MCMC algorithms. 2.3 The necessary but costly expansion of the lik eliho o d As noted ab ov e, the lik eliho o d function (3) inv olves J n terms when the n inner sums are expanded, that is, when all the p ossible v alues of the missing v ariables z i are taken in to accoun t. While the lik eliho od at a giv en v alue ( θ , p ) can b e computed in O( nJ ) operations, the computational difficulty in using the expanded version of (3) precludes analytic solutions via maximum lik eliho o d or Bay esian inference. Considering n iid observ ations from model (1), if π ( θ , p ) denotes the prior distribution on ( θ , p ), the p osterior distribution is naturally giv en b y π ( θ , p | x ) ∝ n Y i =1 J X j =1 p j f ( x i | θ j ) π ( θ , p ) . 4 It can therefore be computed in O( nJ ) operations up to the normalising [marginal] constant, but, similar to the likelihoo d, it does not pro vide an in tuitive distribution unless expanded. Relying on the auxiliary v ariables z = ( z 1 , . . . , z n ) defined in (4), we take Z to b e the set of all J n allo cation v ectors z . F or a given vector ( n 1 , . . . , n J ) of the simplex { n 1 + . . . + n J = n } , w e define a subset of Z , Z j = ( z : n X i =1 I z i =1 = n 1 , . . . , n X i =1 I z i = J = n J ) , that consists of all allo cations z with the giv en allo cation sizes ( n 1 , . . . , n J ), relab elled b y j ∈ N when using for instance the lexicographical ordering on ( n 1 , . . . , n J ). The n umber of nonnegative integer solutions to the decomp osition of n into k parts such that n 1 + . . . + n J = n is equal to (F eller 1970) r = n + J − 1 n . Th us, w e hav e the partition Z = ∪ r j =1 Z j . Although the total n umber of elemen ts of Z is the t ypically unmanageable J n , the num b er of partition sets is muc h more manageable since it is of order n J − 1 / ( J − 1)!. It is th us p ossible to en visage an exhaustive exploration of the Z j ’s. (Casella et al. 2004 did tak e adv an tage of this decomposition to prop ose a more efficien t imp ortant sampling approximation to the p osterior distribution.) The posterior distribution can then b e written as π ( θ , p | x ) = r X i =1 X z ∈Z i ω ( z ) π ( θ , p | x , z ) , (5) where ω ( z ) represents the posterior probabilit y of the given al lo cation z . (See Section 2.4 for a deriv ation of ω ( z ).) Note that with this representation, a Ba yes estimator of ( θ , p ) can b e written as r X i =1 X z ∈Z i ω ( z ) E π [ θ , p | x , z ] . (6) This decomp osition makes a lot of sense from an inferential p oin t of view: the Ba yes p osterior distribution simply considers each p ossible allo cation z of the dataset, allocates a p osterior probability ω ( z ) to this allo cation, and then constructs a p osterior distribution π ( θ , p | x , z ) for the parameters conditional on this allocation. Unfortunately , the computational burden is of order O( J n ). This is ev en more frustrating when considering that the o verwhelming ma jority of the p osterior probabilities ω ( z ) will b e close to zero for an y sample. 2.4 Exact p osterior computation In a somewhat paradoxical twist, we no w proceed to show that, in some v ery sp ecial cases, there exist exact deriv ations for the posterior distribution! This surprising phenomenon only takes place for discrete distributions under a particular choice of the comp onent densities f ( x | θ i ). In essence, the f ( x | θ i )’s must b elong to the natural exponential families, i.e. f ( x | θ i ) = h ( x ) exp { θ i · R ( x ) − Ψ( θ i ) } , to allow for sufficien t statistics to b e used. In this case, there exists a c onjugate prior (Rob ert 2001) asso ciated with each θ in f ( x | θ ) as well as for the w eights of the mixture. Le t us consider the complete lik eliho o d L c ( θ , p | x , z ) = n Y i =1 p z i exp { θ z i · R ( x i ) − Ψ( θ z i ) } = J Y j =1 p n j j exp θ j · X z i = j R ( x i ) − n j Ψ( θ j ) = J Y j =1 p n j j exp { θ j · S j − n j Ψ( θ j ) } , 5 where S j = P z i = j R ( x i ). It is easily seen that we remain in an exp onen tial family since there exist sufficien t statistics with fixed dimension, ( n 1 , . . . , n J , S 1 , . . . , S J ). Using a Diric hlet prior π ( p 1 , . . . , p J ) = Γ( α 1 + . . . + α J ) Γ( α 1 ) · · · Γ( α J ) p α 1 − 1 1 · · · p α J − 1 J on the v ector of the w eights ( p 1 , . . . , p J ) defined on the simplex of R J and (independent) conjugate priors on the θ j ’s, π ( θ j ) ∝ exp { θ j · τ j − δ j Ψ( θ j ) } , the p osterior associated w ith the complete lik eliho o d L c ( θ , p | x , z ) is then of the same family as the prior: π ( θ , p | x , z ) ∝ π ( θ , p ) × L c ( θ , p | x , z ) ∝ J Y j =1 p α j − 1 j exp { θ j · τ j − δ j Ψ( θ j ) } × p n j j exp { θ j · S j − n j Ψ( θ j ) } = J Y j =1 p α j + n j − 1 j exp { θ j · ( τ j + S j ) − ( δ j + n j )Ψ( θ j ) } ; the parameters of the prior get transformed from α j to α j + n j , from τ j to τ j + S j and from δ j to δ j + n j . If we no w consider the observed likelihoo d (instead of the complete lik elihoo d), it is the sum of the complete likelihoo ds ov er all p ossible configurations of the partition space of allo cations, that is, a sum o ver J n terms, X z J Y j =1 p n j j exp { θ j · S j − n j Ψ( θ j ) } . The associated p osterior is then, up to a constant, X z J Y j =1 p n j + α j − 1 j exp { θ j · ( τ j + S j ) − ( n j + δ j )Ψ( θ j ) } = X z ω ( z ) π ( θ , p | x , z ) , where ω ( z ) is the normalising constan t that is missing in J Y j =1 p n j + α j − 1 j exp { θ j · ( τ j + S j ) − ( n j + δ j )Ψ( θ j ) } . The w eight ω ( z ) is therefore ω ( z ) ∝ Q J j =1 Γ( n j + α j ) Γ( P J j =1 { n j + α j } ) × J Y j =1 K ( τ j + S j , n j + δ j ) , if K ( τ , δ ) is the normalising constan t of exp { θ j · τ − δ Ψ( θ j ) } , i.e. K ( τ , δ ) = Z exp { θ j · τ − δ Ψ( θ j ) } d θ j . Unfortunately , except for very few cases, lik e P oisson and Multinomial mixtures, this sum do es not simplify into a smaller n umber of terms b ecause there exist no summary statistics. F rom a Ba yesian p oin t of view, the complexity of the model is therefore truly of magnitude O( J n ). W e pro cess here the cases of b oth the P oisson and Multinomial mixtures, noting that the former case w as previously exhibited by F earnhead (2005). 6 Example 3. Consider the case of a tw o component Poisson mixture, x 1 , . . . , x n iid ∼ p P ( λ 1 ) + (1 − p ) P ( λ 2 ) , with a uniform prior on p and exp onen tial priors E xp ( τ 1 ) and E xp ( τ 2 ) on λ 1 and λ 2 , respectively . F or suc h a mo del, S j = P z i = j x i and the normalising constant is then equal to K ( τ , δ ) = Z ∞ −∞ exp { λ j τ − δ log ( λ j ) } d λ j = Z ∞ 0 λ τ − 1 j exp {− δ λ j } d λ j = δ − τ Γ( τ ) . The corresponding p osterior is (up to the o verall normalisation of the weigh ts) X z 2 Y j =1 Γ( n j + 1)Γ(1 + S j ) ( τ j + n j ) S j +1 Γ(2 + P 2 j =1 n j ) π ( θ , p | x , z ) = X z 2 Y j =1 n j ! S j ! ( τ j + n j ) S j +1 ( n + 1)! π ( θ , p | x , z ) ∝ X z 2 Y j =1 n j ! S j ! ( τ j + n j ) S j +1 π ( θ , p | x , z ) . π ( θ , p | x , z ) corresponds to a B (1 + n j , 1 + n − n j ) (Beta distribution) on p j and to a G ( S j + 1 , τ j + n j ) (Gamma distribution) on δ j , ( j = 1 , 2). An imp ortant feature of this example is that the abov e sum do es not in volv e all of the 2 n terms, simply b ecause the individual terms factorise in ( n 1 , n 2 , S 1 , S 2 ) that act lik e lo cal sufficien t statistics. Since n 2 = n − n 1 and S 2 = P x i − S 1 , the p osterior only requires as many distinct terms as there are distinct v alues of the pair ( n 1 , S 1 ) in the completed sample. F or instance, if the sample is (0 , 0 , 0 , 1 , 2 , 2 , 4), the distinct v alues of the pair ( n 1 , S 1 ) are (0 , 0) , (1 , 0) , (1 , 1) , (1 , 2) , (1 , 4) , (2 , 0) , (2 , 1) , (2 , 2) , (2 , 3) , (2 , 4) , (2 , 5) , (2 , 6) , . . . , (6 , 5) , (6 , 7) , (6 , 8) , (7 , 9). Hence there are 41 distinct terms in the p osterior, rather than 2 8 = 256. J Let n = ( n 1 , . . . , n J ) and S = ( S 1 , . . . , S J ). The problem of computing the n umber (or cardinal) µ n ( n , S ) of terms in the sum with an identical statistic ( n , S ) has been tackled b y F earnhead (2005), who prop oses a recurrent form ula to compute µ n ( n , S ) in an efficient bo ok-k eeping technique, as expressed b elo w for a k component mixture: If e j denotes the ve ctor of length J made of zer os everywher e exc ept at c omp onent j wher e it is e qual to one, if n = ( n 1 , . . . , n J ) , and n − e j = ( n 1 , . . . , n j − 1 , . . . , n J ) , then µ 1 ( e j , R ( x 1 ) e j ) = 1 , ∀ j ∈ { 1 , . . . , J } , and µ n ( n , S ) = J X j =1 µ n − 1 ( n − e j , S − R ( x n ) e j ) . Example 4. Once the µ n ( n , S )’s are all recursively computed, the p osterior can b e written as X ( n , S ) µ n ( n , S ) 2 Y j =1 n j ! S j ! ( τ j + n j ) S j +1 π ( θ , p | x , n , S ) , up to a constant, and the sum only dep ends on the p ossible v alues of the “sufficien t” statistic ( n , S ). This closed form expression allo ws for a straigh tforward representation of the marginals. F or instance, 7 ( n, λ ) J = 2 J = 3 J = 4 (10 , . 1) 11 66 286 (10 , 1) 52 885 8160 (10 , 10) 166 7077 120,908 (20 , . 1) 57 231 1771 (20 , 1) 260 20,607 566,512 (20 , 10) 565 100,713 — (30 , . 1) 87 4060 81,000 (30 , 1) 520 82,758 — (30 , 10) 1413 637,020 — T able 1: Number of pairs ( n , S ) for simulated datasets from a Poisson P ( λ ) and differen t n umbers of comp onen ts. (Missing terms ar e due to exc essive c omputational or stor age r e quir ements.) up to a constant, the marginal in λ 1 is giv en b y X z 2 Y j =1 n j ! S j ! ( τ j + n j ) S j +1 ( n 1 + 1) S 1 +1 λ S 1 exp {− ( n 1 + 1) λ 1 } /n 1 ! = X ( n , S ) µ n ( n , S ) 2 Y j =1 n j ! S j ! ( τ j + n j ) S j +1 × ( n 1 + τ 1 ) S 1 +1 λ S 1 1 exp {− ( n 1 + τ 1 ) λ 1 } /n 1 ! . The marginal in λ 2 is X ( n , S ) µ n ( n , S ) 2 Y j =1 n j ! S j ! ( τ j + n j ) S j +1 ( n 2 + τ 2 ) S 2 +1 λ S 2 2 exp {− ( n 2 + τ 2 ) λ 2 } /n 2 ! , again up to a constan t. Another interesting outcome of this closed form representation is that marginal densities can also b e computed in closed form. The marginal distribution of x is directly related to the unnormalised weigh ts in that m ( x ) = X z ω ( z ) = X ( n , S ) µ n ( n , S ) Q 2 j =1 n j ! S j ! ( τ j + n j ) S j +1 ( n + 1)! up to the pro duct of factorials 1 /x 1 ! · · · x n ! (but this pro duct is irrelev ant in the computation of the Ba yes factor). J No w, even with this considerable reduction in the complexit y of the posterior distribution, the n um b er of terms in the p osterior still explo des fast b oth with n and with the n umber of comp onen ts J , as shown through a few sim ulated examples in T able 1. The computational pressure also increas es with the range of the data, that is, for a giv en v alue of ( J, n ), the num ber of v alues of the sufficien t statistics is muc h larger when the observ ations are larger, as sho wn for instance in the first three ro ws of T able 1: a sim ulated P oisson P ( λ ) sample of size 10 is mostly made of 0’s when λ = . 1 but mostly tak es differen t v alues when λ = 10. The impact on the num b er of sufficient statistics can be easily assessed when J = 4. (Note that the simulated dataset corresp onding to ( n, λ ) = (10 , . 1) in T able 1 happ ens to corresp ond to a sim ulated sample made only of 0’s, which explains the n + 1 = 11 v alues of the sufficien t statistic ( n 1 , S 1 ) = ( n 1 , 0) when J = 2.) Example 5. If we hav e n observ ations n i = ( n i 1 , . . . , n im ) from the Multinomial mixture n i ∼ p M m ( d i ; q 11 , . . . , q 1 m ) + (1 − p ) M m ( d i ; q 21 , . . . , q 2 m ) 8 where n i 1 + · · · + n im = d i and q 11 + · · · + q 1 m = q 21 + · · · + q 2 m = 1, the conjugate priors on the q j v ’s are Diric hlet distributions, ( j = 1 , 2) ( q j 1 , . . . , q j m ) ∼ D ( α j 1 , . . . , α j m ) , and w e use once again the uniform prior on p . (A default c hoice for the α j v ’s is α j v = 1 / 2.) Note that the d j ’s may differ from observ ation to observ ation, since they are irrelev an t for the posterior distribution: giv en a partition z of the sample, the complete p osterior is indeed p n 1 (1 − p ) n 2 2 Y j =1 Y z i = j q n i 1 j 1 · · · q n im j m × 2 Y j =1 m Y v =1 q − 1 / 2 j v , (where n j is the n umber of observ ations allo cated to component j ) up to a normalising constant that do es not dep end on z . J More generally , considering a Multinomial mixture with m components, n i ∼ J X j =1 p j M m ( d i ; q j 1 , . . . , q j m ) , the complete p osterior is also directly av ailable, as J Y j =1 p n j j × J Y j =1 Y z i = j q n i 1 j 1 · · · q n im j m × J Y j =1 m Y v =1 q − 1 / 2 j v , once more up to a normalising constant. Since the corresp onding normalising constan t of the Dirichlet distribution is Q m v =1 Γ( α j v ) Γ( α j 1 + · · · + α j m ) , the o verall weigh t of a given partition z is n 1 ! n 2 ! Q m v =1 Γ( α 1 v + S 1 v ) Γ( α 11 + · · · + α 1 m + S 1 · ) × Q m v =1 Γ( α 2 v + S 2 v ) Γ( α 21 + · · · + α 2 m + S 2 · ) (7) where S j i is the sum of the n j i ’s for the observ ations i allo cated to component j and S j i = X z i = j n j i and S j · = X i S j i . Giv en that the p osterior distribution only depends on those “sufficien t” statistics S ij and n i , the same factorisation as in the Poisson case applies, namely we simply need to count the num ber of o ccurrences of a particular lo cal sufficient statistic ( n 1 , S 11 , . . . , S J m ) and then sum ov er all v alues of this sufficient statistic. The b o ok-k eeping algorithm of F earnhead (2005) applies. Note ho wev er that the n umber of differen t terms in the closed form expression is growing extremely fast with the n umber of observ ations, with the num b er of comp onents and with the num b er k of mo dalities. Example 6. In the case of the latent class mo del, consider the simplest case of t wo v ariables with t wo mo dalities each, so observ ations are pro ducts of Bernoulli’s, x ∼ p B ( q 11 ) B ( q 12 ) + (1 − p ) B ( q 21 ) B ( q 22 ) . W e note that the corresp onding statistical mo del is not iden tifiable beyond the usual lab el switc hing issue detailled in Section 3.1. Indeed, there are only tw o dic hotomous v ariables, four p ossible realizations for the x ’s, and five unknown parameters. W e ho wev er take adv an tage of this artificial mo del to highligh t the implemen tation of the ab ov e exact algorithm, which can then easily uncov er the unidentifiabilit y features of the p osterior distribution. 9 The complete p osterior distribution is the sum o ver all partitions of the terms p n 1 (1 − p ) n 2 2 Y j =1 2 Y v =1 q s j v j v (1 − q j v ) n j − s j v × 2 Y j =1 2 Y v =1 q − 1 / 2 j v where s j v = P z i = j x iv , the sufficien t statistic is thus ( n 1 , s 11 , s 12 , s 21 , s 22 ), of order O( n 5 ). Using the b enc hmark data of Stouffer and T oby (1951), made of 216 sample p oints inv olving four binary v ariables related with a so ciological questionnaire, w e restricted ourselv es to b oth first v ariables and 50 observ ations pic ked at random. A recursiv e algorithm that eliminated replicates giv es the results that (a) there are 5 , 928 differen t v alues for the sufficient statistic and (b) the most common o ccurrence is the middle partition (26 , 6 , 11 , 5 , 10), with 7 . 16 × 10 12 replicas (out of 1 . 12 × 10 15 total partitions). The p osterior w eight of a giv en partition is Γ( n 1 + 1)Γ( n − n 1 + 1) Γ( n + 2) 2 Y j =1 2 Y v =1 Γ( s j v + 1 / 2)Γ( n j − s j v + 1 / 2) Γ( n j + 1) = 2 Y j =1 2 Y v =1 Γ( s j v + 1 / 2)Γ( n j − s j v + 1 / 2) n 1 ! ( n − n 1 )! ( n + 1)! , m ultiplied b y the n umber of o ccurrences. In this case, it is therefore p ossible to find exactly the most lik ely partitions, namely the one with n 1 = 11 and n 2 = 39, s 11 = 11, s 12 = 8, s 21 = 0, s 22 = 17, and the symmetric one, whic h b oth only o ccur once and which hav e a joint p osterior probability of 0 . 018. It is also p ossible to eliminate all the partitions with very low probabilities in this example. J 3 Mixture inference Once again, the apparen t simplicit y of the mixture density should not b e tak en at face v alue for inferen tial purp oses; since, for a sample of arbitrary size n from a mixture distribution (1), there alw ays is a non-zero probabilit y (1 − p j ) n that the j th subsample is empt y , the likelihoo d includes terms that do not bring an y information about the parameters of the i -th comp onen t. 3.1 Noniden tifiabilit y , hence label switc hing A mixture mo del (1) is senso stricto nev er iden tifiable since it is inv ariant under p ermutations of the indices of the comp onents. Indeed, unless we in tro duce some restriction on the range of the θ i ’s, we cannot distinguish comp onen t num b er 1 (i.e., θ 1 ) from comp onen t num b er 2 (i.e., θ 2 ) in the likelihoo d, b ecause they are exc hangeable. This apparen tly b enign feature has consequences on b oth Bay esian inference and computational implementation. First, exchangeabilit y implies that in a J component mixture, the n umber of modes is of order O( J !). The highly m ultimo dal p osterior surface is therefore difficult to explore via standard Marko v chain Monte Carlo tec hniques. Second, if an exchangeable prior is used on θ = ( θ 1 , . . . , θ J ), all the marginals of the θ j ’s are identical. Other and more sev ere sources of uniden tifiability could o ccur as in Example 6. Example 7. (Example 6 c on tin ued) If we contin ue our assessment of the laten t class model, with tw o v ariables with t wo modalities each, based on subset of data extracted from Stouffer and T ob y (1951), under a Beta, B ( a, b ), prior distribution on p the p osterior distribution is the w eighted sum of Beta B ( n 1 + a, n − n 1 + b ) distributions, with w eights µ n ( n , s ) 2 Y j =1 2 Y v =1 Γ( s j v + 1 / 2)Γ( n j − s j v + 1 / 2) n 1 ! ( n − n 1 )! ( n + 1)! , where µ n ( n , s ) denotes the num b er of o ccurrences of the sufficient statistic. Figure 3 provides the p osterior distribution for a subsample of the dataset of Stouffer and T oby (1951) and a = b = 1. Since p is not iden tifiable, the impact of the prior distribution is stronger than in an identifying setting: using a Beta B ( a, b ) prior on p thus pro duces a p osterior [distribution] that reflects as m uch the influence of 10 0.0 0.2 0.4 0.6 0.8 1.0 0.4 0.6 0.8 1.0 1.2 1.4 Figure 3: Exact p osterior distribution of p for a sample of 50 observ ations from the dataset of Stouffer and T oby (1951) and a = b = 1. ( a, b ) as the information contained in the data. While a B (1 , 1) prior, as in Figure 3, leads to a p erfectly symmetric p osterior with three mo des, using an assymetric prior with a b strongly mo difies the range of the p osterior, as illustrated by Figure 4. J Iden tifiability problems resulting from the exc hangeability issue are called “lab el switching” in that the output of a prop erly con verging MCMC algorithm should pro duce no information ab out the component lab els (a feature whic h, inciden tally , provides a fast assessment of the p erformance of MCMC solutions, as prop osed in Celeux et al. 2000). A na ¨ ıve answer to the problem prop osed in the early literature is to impose an identifiability c onstr aint on the parameters, for instance b y ordering the means (or the v ariances or the w eigh ts) in a normal mixture. F rom a Ba y esian point of view, this amoun ts to truncating the original prior distribution, going from π ( θ , p ) to π ( θ , p ) I µ 1 ≤ ... ≤ µ J . While this device may seem inno cuous (b ecause indeed the sampling distribution is the same with or without this constrain t on the parameter space), it is not without consequences on the resulting inference. This can be seen directly on the p osterior surface: if the parameter space is reduced to its constrained part, there is no agreement b etw een the ab ov e notation and the top ology of this surface. Therefore, rather than selecting a single posterior mo de and its neighbourho o d, the constrained parameter space will most lik ely include parts of sev eral mo dal regions. Thus, the resulting p osterior mean ma y w ell end up in a very low probability region and b e unrepresentativ e of the estimated distribution. Note that, once an MCMC sample has been sim ulated from an unconstrained posterior distribution, an y ordering constraint can be imp osed on this sample, that is, after the simulations hav e b een completed, for estimation purp oses as stressed by Stephens (1997). Therefore, the simulation (if not the estimation) hindrance created by the constraint can be completely bypassed. Once an MCMC sample has b een simulated from an unconstrained p osterior distribution, a natural solution is to iden tify one of the J ! mo dal regions of the p osterior distribution and to op erate the relab elling in terms of proximit y to this region, as in Marin et al. (2005). Similar approaches based on clustering algorithms for the parameter sample are prop osed in Stephens (1997) and Celeux et al. (2000), and they achiev e some measure of success on the examples for whic h they ha ve b een tested. 3.2 Restrictions on priors F rom a Bay esian point of view, the fact that few or no observ ation in the sample is (ma y b e) generated from a given comp onen t has a direct and important drawbac k: this prohibits the use of indep endent 11 Figure 4: Exact p osterior distributions of p for a sample of 50 observ ations from the dataset of Stouffer and T oby (1951) under Beta B ( a, b ) priors when a = . 01 , . 05 , . 1 , . 05 , 1 and b = 100 , 50 , 20 , 10 , 5 , 1. improp er priors, π ( θ ) = J Y j =1 π ( θ j ) , since, if Z π ( θ j )d θ j = ∞ then for any sample size n and any sample x , Z π ( θ , p | x )d θ d p = ∞ . The ban on using improp er priors can b e considered b y some as b eing of little imp ortance, since prop er priors with large v ariances could be used instead. How ever, since mixtures are ill-posed problems, this difficult y with improp er priors is more of an issue, given that the influence of a particular prop er prior, no matter how large its v ariance, cannot be truly assessed. There exists, nonetheless, a possibility of using improper priors in this setting, as demonstrated for instance b y Mengersen and Rob ert (1996), b y adding some degree of dependence b etw een the component parameters. In fact, a Ba y esian p ersp ectiv e makes it quite easy to argue against independence in mixture mo dels, since the comp onen ts are only properly defined in terms of one another. F or the v ery reason that exchangeable priors lead to iden tical marginal p osteriors on all comp onen ts, the relev an t priors m ust contain some degree of information that comp onen ts are differ ent and those priors must b e explicit ab out this difference. The proposal of Mengersen and Rob ert (1996), also described in Marin et al. (2005), is to introduce first a common reference, namely a scale, lo cation, or lo cation-scale parameter ( µ, τ ), and then to define the original parameters in terms of dep artur e from those references. Under some conditions on the reparameterisation, expressed in Rob ert and Titterington (1998), this represen tation allows for the use of an improp er prior on the reference parameter ( µ, τ ). See W asserman (2000), P´ erez and Berger (2002), Moreno and Liseo (2003) for different approac hes to the use of default or non-informativ e priors in the setting of mixtures. 4 Inference for mixtures with a known num b er of comp onen ts In this section, w e describ e different Mon te Carlo algorithms that are customarily used for the appro x- imation of p osterior distributions in mixture settings when the num b er of comp onents J is known. W e 12 start in Section 4.1 with a proposed solution to the lab el-switching problem and then discuss in the follo wing sections Gibbs sampling and Metrop olis-Hastings algorithms, ackno wledging that a div ersity of other algorithms exist (temp ering, p opulation Monte Carlo...), see Rob ert and Casella (2004). 4.1 Reordering Section 3.1 discussed the dra wbacks of imp osing identifiabilit y ordering constraints on the parameter space for estimation p erformances and there are similar dra wbac ks on the computational side, since those constrain ts decrease the explorativ e abilities of a sampler and, in the most extreme cases, ma y ev en prev ent the sampler from conv erging (see Celeux et al. 2000). W e thus consider samplers that ev olve in an unconstrained parameter space, with the sp ecific feature that the p osterior surface has a n umber of mo des that is a m ultiple of J !. Assuming that this surface is prop erly visited b y the sampler (and this is not a trivial assumption), the deriv ation of p oint estimates of the parameters of (1) follows from an ex-p ost reordering prop osed b y Marin et al. (2005) whic h w e describ e below. Giv en a sim ulated sample of size M , a starting v alue for a p oin t estimate is the na ¨ ıv e approximation to the Maximum a P osteriori (MAP) estimator, that is the v alue in the sequence ( θ , p ) ( l ) that maximises the posterior, l ∗ = arg max l =1 ,...,M π (( θ , p ) ( l ) | x ) Once an approximated MAP is computed, it is then p ossible to reorder all terms in the sequence ( θ , p ) ( l ) b y selecting the reordering that is the closest to the appro ximate MAP estimator for a specific distance in the parameter space. This solution bypasses the iden tifiability problem without requiring a preliminary and most likely unnatural ordering with resp ect to one of the parameters (mean, weigh t, v ariance) of the model. Then, after the reordering step, an estimation of θ j is giv en b y M X l =1 ( θ j ) ( l ) M . 4.2 Data augmentation and Gibbs sampling appro ximations The Gibbs sampler is the most commonly used approac h in Bay esian mixture estimation (Dieb olt and Rob ert 1990, 1994, Lavine and W est 1992, V erdinelli and W asserman 1992, Escobar and W est 1995) b ecause it takes adv an tage of the missing data structure of the z i ’s unco vered in Section 2.2. The Gibbs sampler for mixture mo dels (1) (Dieb olt and Rob ert 1994) is based on the successive sim- ulation of z , p and θ conditional on one another and on the data, using the full conditional distributions deriv ed from the conjugate structure of the complete mo del. (Note that p only dep ends on the missing data z .) Gibbs sampling for mixture mo dels 0. Initialization: cho ose p (0) and θ (0) a rbitrarily 1. Step t. F or t = 1 , . . . 1.1 Generate z ( t ) i ( i = 1 , . . . , n ) from ( j = 1 , . . . , J ) P z ( t ) i = j | p ( t − 1) j , θ ( t − 1) j , x i ∝ p ( t − 1) j f x i | θ ( t − 1) j 1.2 Generate p ( t ) from π ( p | z ( t ) ) 1.3 Generate θ ( t ) from π ( θ | z ( t ) , x ) . As alwa ys with mixtures, the conv ergence of this MCMC algorithm is not as easy to assess as it seems at first sight. In fact, while the chain is uniformly geometrically ergodic from a theoretical p oint of view, the severe augmen tation in the dimension of the c hain brough t by the completion stage may induce strong conv ergence problems. The very nature of Gibbs sampling may lead to “trapping states”, that is, concen trated local modes that require an enormous n um b er of iterations to escape from. F or example, 13 comp onen ts with a small num b er of allo cated observ ations and very small v ariance b ecome so tightly concen trated that there is v ery little probability of mo ving observ ations in or out of those comp onents, as shown in Marin et al. (2005). As discussed in Section 2.3, Celeux et al. (2000) sho w that most MCMC samplers for mixtures, including the Gibbs sampler, fail to repro duce the permutation inv ariance of the p osterior distribution, that is, that they do not visit the J ! replications of a giv en mo de. Example 8. Consider a mixture of normal distributions with common v ariance σ 2 and unknown means and w eights J X j =1 p j N ( µ j , σ 2 ) . This mo del is a particular case of mo del (1) and is not identifiable. Using conjugate exc hangeable priors p ∼ D (1 , . . . , 1) , µ j ∼ N (0 , 10 σ 2 ) , σ − 2 ∼ E xp (1 / 2) , it is straightforw ard to implement the ab ov e Gibbs sampler: • the w eight vector p is sim ulated as the Dirichlet v ariable D (1 + n 1 , . . . , 1 + n J ) ; • the in verse v ariance as the Gamma v ariable G ( n + 2) / 2 , (1 / 2) 1 + J X j =1 0 . 1 n j ¯ x 2 j n j + 0 . 1 + s 2 j ! ; • and, conditionally on σ , the means µ j are sim ulated as the Gaussian v ariable N ( n j ¯ x j / ( n j + 0 . 1) , σ 2 / ( n j + 0 . 1)) ; where n j = P z i = j , ¯ x j = P z i = j x i and s 2 j = P z i = j ( x i − ¯ x j ) 2 /n j . Note that this choice of implemen tation allo ws for the block simulation of the means-v ariance group, rather than the more standard simulation of the means conditional on the v ariance and of the v ariance conditional on the means (as in Dieb olt and Robert 1994). J Consider the b enchmark dataset of the galaxy radial sp eeds described for instance in Roeder and W asserman (1997). The output of the Gibbs sampler is summarised on Figure 5 in the case of J = 3 comp onen ts. As is ob vious from the comparison of the three first histograms (and of the three follo wing ones), lab el switching do es not o ccur with this sampler: the three comp onen ts remain isolated during the sim ulation pro cess. J Note that Gew eke (2007) (among others) dispute the relev ance of asking for proper mixing ov er the k ! mo des, arguing that on the con trary the fact that the Gibbs sampler stic ks to a single mo de allows for an easier inference. W e obviously disagree with this p ersp ective: first, from an algorithmic p oint of view, giv en the unconstrained p osterior distribution as the target, a sampler that fails to explore all modes clearly fails to con verge. Second, the idea that b eing restricted to a single mo de provides a prop er repre- sen tation of the p osterior is na ¨ ıvely based on an intuition derived from mixtures with few components. As the num b er of comp onents increases, mo des on the posterior surface get inextricably mixed and a standard MCMC c hain cannot b e garanteed to remain within a single modal region. F urthermore, it is imp ossible to chec k in practice whether not this is the case. In his defence of “simple” MCMC strategies supplemented with p ostpro cessing steps, Gewek e (2007) states that [Celeux et al.’s (2000)] ar gument is p ersuasive only to the extent that ther e ar e mix- ing pr oblems b eyond those arising fr om p ermutation invarianc e of the p osterior distribution. Celeux et al. (2000) do es not make this ar gument, inde e d stating “The main defe ct of the Gibbs sampler fr om our p ersp e ctive is the ultimate attr action of the lo c al mo des” (p. 959). That article pr o duc es no evidenc e of additional mixing pr oblems in its examples, and we ar e not awar e of such examples in the r elate d liter atur e. Inde e d, the simplicity of the p osterior distributions c onditional on state assignments in most mixtur e mo dels le ads one to exp e ct no irr e gularities of this kind. 14 0.5 0.7 0.9 0 2 4 6 8 10 0.05 0.15 0.25 0 2 4 6 8 12 0.0 0.1 0.2 0.3 0 5 10 15 −0.4 −0.2 0.0 0.2 0 1 2 3 4 5 6 7 −3 −2 −1 0 1 0.0 0.5 1.0 1.5 2.0 0 1 2 3 0.0 0.4 0.8 1.2 0.4 0.6 0.8 1.0 0 2 4 6 8 10 0 200 600 1000 0.4 0.6 0.8 1.0 σ σ 0 200 600 1000 −115 −105 −95 log−likelihood Figure 5: F rom the left to the righ t, histograms of the parameters ( p 1 , p 2 , p 3 , µ 1 , µ 2 , µ 3 , σ ) of a normal mixture with k = 3 comp onents based on 10 4 iterations of the Gibbs sampler and the galaxy dataset, ev olution of the σ and of the log-likelihoo d. There are ho wev er clear irregularities in the con vergence behaviour of Gibbs and Metropolis–Hastings algorithms as exhibited in Marin et al. (2005) and Marin and Rob ert (2007) (Figure 6.4) for an identifiable t wo-component normal mixture with b oth means unknown. In examples as such as those, there exist secondary mo des that may hav e muc h lo wer p osterior v alues than the mo des of interest but that are nonetheless to o attractive for the Gibbs sampler to visit other mo des. In such cases, the p osterior inference derived from the MCMC output is plainly incoheren t. (See also Iacobucci et al. (2008) for another illustration of a m ultimo dal p osterior distribution in an iden tifiable mixture setting.) Ho wev er, as shown by the example b elow, for identifiable mixture mo dels, there is no lab el switching to exp ect and the Gibbs sampler ma y w ork quite well. While there is no fo olproof approach to c heck MCMC con vergence (Robert and Casella 2004), we recommend using the visited likelihoo ds to detect lac k of mixing in the algorithms. This does not detect the lab el switching difficulties (but individual histograms do) but rather the p ossible trapping of a secondary mo de or simply the slow exploration of the posterior surface. This is particularly helpful when implementing multiple runs in parallel. Example 9. (Example 2 con tin ued) Consider the case of a mixture of Student’s t distributions with kno wn and differen t num b ers of degrees of freedom J X j =1 p j t ν j ( µ j , σ 2 j ) . This mixture mo del is not a particular case of mo del (1) and is identifiable. Moreov er, since the noncentral t distribution t ν ( µ, σ 2 ) can be in terpreted as a contin uous mixture of normal distributions with a common mean and with v ariances distributed as scaled inv erse χ 2 random v ariable, a Gibbs sampler can b e easily implemen ted in this setting by taking adv an tage of the corresp onding laten t v ariables: x i ∼ t ν ( µ, σ 2 ) is the marginal of x i | V i , σ 2 ∼ N ( µ, V i σ 2 ) , V − 1 i ∼ χ 2 ν . Once these laten t v ariables are included in the simulation, the conditional posterior distributions of all parameters are av ailable when using conjugate priors like p ∼ D (1 , . . . , 1) , µ j ∼ N ( µ 0 , 2 σ 2 0 ) , σ 2 j ∼ I G ( α σ , β σ ) . 15 The full conditionals for the Gibbs sampler are a Dirichlet D (1 + n 1 , . . . , 1 + n J ) distribution on the w eight vector, inv erse Gamma I G α σ + n j 2 , β σ + X z i = j ( x i − µ j ) 2 2 V i distributions on the v ariances σ 2 j , normal N µ 0 σ 2 j + 2 σ 2 0 P z i = j x i V − 1 i σ 2 j + 2 σ 2 0 P z i = j V − 1 i , 2 σ 2 0 σ 2 j σ 2 j + 2 σ 2 0 P z i = j V − 1 i ! distributions on the means µ j , and inv erse Gamma I G 1 2 + ν j 2 , ( x i − µ j ) 2 2 σ 2 j + ν j 2 ! distributions on the V i . In order to illustrate the p erformance of the algorithm, we sim ulated 2 , 000 observ ations from the t wo-component t mixture with µ 1 = 0, µ 2 = 5, σ 2 1 = σ 2 2 = 1, ν 1 = 5, ν 2 = 11 and p 1 = 0 . 3. The output of the Gibbs sampler is summarized in Figure 6. The mixing b ehaviour of the Gibbs chains seems to be excellen t, as they explore neighbourho o ds of the true v alues. J ! 0.4 ! 0.2 0 0.2 0.4 0 2 4 6 8 10 0.5 1 1.5 0 2 4 6 8 10 0.25 0.3 0.35 0 10 20 30 40 4.6 4.8 5 5.2 5.4 0 5 10 15 0.8 1 1.2 0 5 10 15 20 0 1 2 3 x 10 4 ! 10 3.62 ! 10 3.63 Figure 6: Histograms of the parameters, µ 1 , σ 1 , p 1 , µ 2 , σ 2 , and evolution of the (observ ed) log-lik eliho o d along 30 , 000 iterations of the Gibbs sampler and a sample of 2 , 000 observ ations. The example b elow sho ws that, for specific mo dels and a small n umber of comp onen ts, the Gibbs sampler ma y reco ver the symmetry of the target distribution. Example 10. (Example 6 con tinued) F or the latent class mo del, if we use all four v ariables with t wo modalities each in Stouffer and T ob y (1951), the Gibbs sampler inv olves tw o steps: the completion of the data with the component lab els, and the sim ulation of the probabilities p and q tj from Beta ( B )( s tj + . 5 , n j − s tj + . 5) conditional distributions. F or the 216 observ ations, the Gibbs sampler seems to con verge satisfactorily since the output in Figure 7 exhibits the p erfect symmetry predicted b y the theory . W e can note that, in this sp ecial case, the mo des are well separated, and hence v alues can be crudely estimated for q 1 j b y a simple graphical identification of the modes. J 4.3 Metrop olis–Hastings appro ximations The Gibbs sampler may fail to escap e the attraction of a local mo de, ev en in a well-behav ed case as in Example 1 where the lik eliho o d and the p osterior distributions are b ounded and where the parameters are identifiable. P art of the difficult y is due to the completion scheme that increases the dimension of the simulation space and that reduces considerably the mobilit y of the parameter c hain. A standard alternativ e that do es not require completion and an increase in the dimension is the Metrop olis–Hastings algorithm. In fact, the lik eliho o d of mixture mo dels is av ailable in closed form, being computable in O( J n ) time, and the p osterior distribution is thus av ailable up to a multiplicativ e constan t. 16 0.2 0.4 0.6 0.8 0 1 2 3 0.0 0.1 0.2 0.3 0.4 0.5 0 5 10 15 20 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0 5 10 15 20 0.0 0.2 0.4 0.6 0.8 0 1 2 3 4 5 6 0.0 0.2 0.4 0.6 0.8 0 1 2 3 4 5 6 0.0 0.2 0.4 0.6 0.8 0 1 2 3 4 5 0.0 0.2 0.4 0.6 0.8 0 1 2 3 4 5 0.0 0.2 0.4 0.6 0.8 1.0 0 1 2 3 4 5 0.0 0.2 0.4 0.6 0.8 1.0 0 1 2 3 4 5 Figure 7: Laten t class mo del: histograms of p and of the q tj ’s for 10 4 iterations of the Gibbs sampler and the four v ariables of Stouffer and T oby (1951). The first histogram corresp onds to p , the next on the righ t to q 11 , follo wed by q 21 (iden tical), then q 21 , q 22 , and so on. General Metropolis–Hastings algorithm for mixture models 0. Initialization. Cho ose p (0) and θ (0) 1. Step t. F or t = 1 , . . . 1.1 Generate ( e θ , e p ) from q θ , p | θ ( t − 1) , p ( t − 1) , 1.2 Compute r = f ( x | e θ , e p ) π ( e θ , e p ) q ( θ ( t − 1) , p ( t − 1) | e θ , e p ) f ( x | θ ( t − 1) , p ( t − 1) ) π ( θ ( t − 1) , p ( t − 1) ) q ( e θ , e p | θ ( t − 1) , p ( t − 1) ) , 1.3 Generate u ∼ U [0 , 1] If r > u then ( θ ( t ) , p ( t ) ) = ( e θ , e p ) else ( θ ( t ) , p ( t ) ) = ( θ ( t − 1) , p ( t − 1) ) . The ma jor difference with the Gibbs sampler is that we need to c hoose the prop osal distribution q , whic h can be a priori an ything, and this is a mixed blessing! The most generic proposal is the random w alk Metropolis–Hastings algorithm where each unconstrained parameter is the mean of the prop osal distribution for the new v alue, that is, e θ j = θ ( t − 1) j + u j where u j ∼ N (0 , ζ 2 ). Ho wev er, for constrained parameters lik e the w eights and the v ariances in a normal mixture model, this prop osal is not efficien t. This is indeed the case for the parameter p , due to the constrain t that P J j =1 p j = 1. T o solv e this difficult y , Capp´ e et al. (2003) propose to o verparameterise the mo del (1) as p j = w j J X l =1 w l , w j > 0 , th us removing the sim ulation constrain t on the p j ’s. Obviously , the w j ’s are not iden tifiable, but this is not a difficulty from a sim ulation p oint of view and the p j ’s remain identifiable (up to a p erm utation of indices). P erhaps parado xically , using ov erparameterised representations often helps with the mixing of the corresponding MCMC algorithms since they are less constrained b y the dataset or the likelihoo d. The proposed mov e on the w j ’s is log ( f w j ) = log( w ( t − 1) j ) + u j where u j ∼ N (0 , ζ 2 ). 17 Example 11. (Example 2 contin ued) W e now consider the more realistic case when the degrees of freedom of the t distributions are unknown. The Gibbs sampler cannot be implemented as suc h given that the distribution of the ν j ’s is far from standard. A common alternativ e (Rob ert and Casella 2004) is to introduce a Metrop olis step within the Gibbs sampler to ov ercome this difficult y . If we use the same Gamma prior distribution with h yp erparameters ( α ν , β ν ) for all the ν j s, the full conditional density of ν j is π ( ν j | V , z ) ∝ ( ν j / 2) ν j / 2 Γ( ν j / 2) n j Y z i = j V − ( ν j / 2+1) i e ν j / 2 V i G ( α ν , β ν ) . Therefore, w e resort to a random walk prop osal on the log ( ν j )’s with scale ς = 5. (The hyperparameters are α ν = 5 and β ν = 2.) In order to illustrate the p erformances of the algorithm, t wo cases are considered: (i) all parameters except v ariances ( σ 2 1 = σ 2 2 = 1) are unkno wn and (ii) all parameters are unknown. F or a sim ulated dataset, the results are given on Figure 8 and Figure 9, respectively . In b oth cases, the p osterior distri- butions of the ν j ’s exhibit very large v ariances, whic h indicates that the data is very weakly informativ e ab out the degrees of freedom. The Gibbs sampler do es not mix well-enough to recov er the symmetry in the marginal approximations. The comparison betw een the estimated densities for b oth cases with the setting is giv en in Figure 10. The estimated mixture densities are indistinguishable and the fit to the sim ulated dataset is quite adequate. Clearly , the corresp onding Gibbs samplers hav e recov ered correctly one and only one of the 2 symetric modes. ! 0.5 0 0.5 0 2 4 6 8 0 5 10 15 20 0 0.1 0.2 0.3 0.4 0.25 0.3 0.35 0 10 20 30 40 4.8 5 5.2 0 5 10 15 0 5 10 15 20 0 0.05 0.1 0.15 0.2 0.25 0 1 2 3 x 10 4 ! 10 3.618 ! 10 3.619 ! 10 3.62 Figure 8: Histograms of the parameters µ 1 , ν 1 , p 1 , µ 2 , ν 2 when the v ariance parameters are kno wn, and ev olution of the log-likelihoo d for a sim ulated t mixture with 2 , 000 p oints, based on 3 × 10 4 MCMC iterations. ! 0.5 0 0.5 0 2 4 6 8 10 0.5 1 1.5 0 2 4 6 8 10 0 10 20 0 0.1 0.2 0.3 0.4 0.2 0.3 0.4 0 10 20 30 40 4.8 5 5.2 0 5 10 15 0.5 1 1.5 0 5 10 15 0 10 20 0 0.1 0.2 0.3 0.4 0 1 2 3 x 10 4 ! 10 3.62 ! 10 3.63 Figure 9: Histograms of the parameters µ 1 , σ 1 , ν 1 , p 1 , µ 2 , σ 2 , ν 2 , and evolution of the log-likelihoo d for a sim ulated t mixture with 2 , 000 p oin ts, based on 3 × 10 4 MCMC iterations. 18 ! 10 ! 5 0 5 10 15 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 Density Figure 10: Histogram of the simulated dataset, compared with estimated t mixtures with known σ 2 (r e d) , known ν (gr e en) , and when all parameters are unknown (blue) . µ 1 µ 2 σ 1 σ 2 ν 1 ν 2 p 1 Studen t 2.5624 3.9918 0.5795 0.3595 18.5736 19.3001 0.3336 Normal 2.5729 3.9680 0.6004 0.3704 - - 0.3391 T able 2: Estimates of the parameters for the aerosol dataset compared for t and normal mixtures. W e no w consider the aerosol particle dataset described in Example 2. W e use the same prior distri- butions on the ν j ’s as b efore, that is G (5 , 2). Figure 11 summarises the output of the MCMC algorithm. Since there is no lab el switching and only tw o components, w e choose to estimate the parameters b y the empirical a verages, as illustrated in T able 2. As shown by Figure 2, b oth t mixtures and normal mixtures fit the aerosol data reasonably well. J 2 2.5 3 0 2 4 6 8 10 0 0.5 1 0 5 10 15 0 50 0 0.02 0.04 0.06 0.08 0 0.5 0 5 10 15 20 25 3.8 4 0 5 10 15 20 25 0.2 0.4 0.6 0 10 20 30 40 0 50 0 0.02 0.04 0.06 0.08 0.1 0 1 2 3 x 10 4 ! 10 3.32 ! 10 3.37 Figure 11: Histograms of parameters ( µ 1 , σ 1 , ν 1 , p 1 , µ 1 , σ 2 , ν 2 ) and log-likelihoo d of a mixture of t distri- butions based on 30 , 000 iterations and the aerosol data. 5 Inference for mixture mo dels with an unknown n um b er of comp onen ts Estimation of J , the n umber of comp onen ts in (1), is a sp ecial t yp e of model choice problem, for which there is a num ber of p ossible solutions: (i) direct computation of the Ba yes factors (Kass and Raftery 1995, Chib 1995); 19 (ii) ev aluation of an en tropy distance (Mengersen and Robert 1996, Sah u and Cheng 2003); (iii) generation from a joint distribution across mo dels via rev ersible jump MCMC (Richardson and Green 1997) or via birth-and-death pro cesses (Stephens 2000) ; dep ending on whether the persp ective is on testing or estimation. W e refer to Marin et al. (2005) for a short description of the reversible jump MCMC solution, a longer survey b eing a v ailable in Rob ert and Casella (2004) and a sp ecific description for mixtures–including an R pac k age—b eing provided in Marin and Robert (2007). The alternativ e birth-and-death processes prop osed in Stephens (2000) has not generated as m uc h follo w-up, except for Capp ´ e et al. (2003) who sho w ed that the essen tial mec hanism in this approach was the same as with reversible jump MCMC algorithms. W e fo cus here on the first t w o approaches, b ecause, first, the description of rev ersible jump MCMC algorithms require m uch care and therefore more space than we can allow to this pap er and, second, this description exemplifies recent adv ances in the deriv ation of Bay es factors. These solutions p ertain more strongly to the testing p erspective, the en tropy distance approach being based on the Kullback–Leibler div ergence betw een a J comp onen t mixture and its pro jection on the set of J − 1 mixtures, in the same spirit as in Dupuis and Rob ert (2003). Given that the calibration of the Kullback divergence is open to v arious in terpretations (Mengersen and Robert 1996, Goutis and Robert 1998, Dupuis and Rob ert 2003), w e will only co ver here some prop osals regarding appro ximations of the Ba y es factor orien ted tow ards the direct exploitation of outputs from single mo del MCMC runs. In fact, the ma jor difference b etw een approximations of Ba yes factors based on those outputs and appro ximations based on the output from the reversible jump chains is that the latter requires a suf- ficien tly efficient c hoice of proposals to mo ve around mo dels, which can b e difficult despite significant recen t adv ances (Bro oks et al. 2003). If we can instead concentrate the sim ulation effort on single mo dels, the complexity of the algorithm decreases (a lot) and there exist wa ys to ev aluate the p erformance of the corresp onding MCMC samples. In addition, it is often the case that few mo dels are in comp etition when estimating J and it is therefore p ossible to visit the whole range of p otentials mo dels in an exhaustive manner. W e ha ve f J ( x | λ J ) = n Y i =1 J X j =1 p j f ( x i | θ j ) where λ J = ( θ , p ) = ( θ 1 , . . . , θ J , p 1 , . . . , p J ). Most solutions (see, e.g. F r ¨ uhwirth-Sc hnatter 2006, Section 5.4) rev olve around an imp ortance sampling appro ximation to the marginal likelihoo d in tegral m J ( x ) = Z f J ( x | λ J ) π J ( λ J ) d λ J where J denotes the model index (that is the n umber of comp onents in the present case). F or instance, Liang and W ong (2001) use bridge sampling with sim ulated annealing scenarios to ov ercome the label switc hing problem. Steele et al. (2006) rely on defensive sampling and the use of conjugate priors to reduce the integration to the space of laten t v ariables (as in Casella et al. 2004) with an iterative construction of the imp ortance function. F r ¨ uhwirth-Sc hnatter (2004) also centers her approximation of the marginal likelihoo d on a bridge sampling strategy , with particular attention paid to identifiabilit y constrain ts. A different possibility is to use Gelfand and Dey (1994) representation: starting from an arbitrary densit y g J , the equality 1 = Z g J ( λ J ) d λ J = Z g J ( λ J ) f J ( x | λ J ) π J ( λ J ) f J ( x | λ J ) π J ( λ J ) d λ J = m J ( x ) Z g J ( λ J ) f J ( x | λ J ) π J ( λ J ) π J ( λ J | x ) d λ J implies that a p otential estimate of m J ( x ) is ˆ m J ( x ) = 1 1 T T X t =1 g J ( λ ( t ) J ) f J ( x | λ ( t ) J ) π J ( λ ( t ) J ) 20 when the λ ( t ) J ’s are produced b y a Monte Carlo or an MCMC sampler targeted at π J ( λ J | x ). While this solution can b e easily implemen ted in lo w dimensional settings (Chopin and Robert 2007), calibrating the auxiliary densit y g k is alw ays an issue. The auxiliary densit y could b e selected as a non-parametric estimate of π k ( λ J | x ) based on the sample itself but this is v ery costly . Another difficult y is that the estimate may ha ve an infinite v ariance and th us be to o v ariable to be trust worth y , as experimented b y F r ¨ uh wirth-Schnatter (2004). Y et another approximation to the integral m J ( x ) is to consider it as the exp ectation of f J ( x | λ J ), when λ J is distributed from the prior. While a brute force approach sim ulating λ J from the prior distribution is requiring a huge n um b er of sim ulations (Neal 1999), a Riemann based alternativ e is proposed by Skilling (2006) under the denomination of neste d sampling ; ho wev er, Chopin and Rob ert (2007) hav e sho wn in the case of mixtures that this technique could lead to uncertainties about the quality of the appro ximation. W e consider here a further solution, first proposed by Chib (1995), that is straightforw ard to imple- men t in the setting of mixtures (see Chib and Jeliazk o v 2001 for extensions). Although it came under criticism by Neal (1999) (see also F r ¨ uhwirth-Sc hnatter 2004), w e sho w b elow how the dra wback p oin ted b y the latter can easily be remo ved. Chib’s (1995) metho d is directly based on the expression of the marginal distribution (lo osely called mar ginal likeliho o d in this section) in Bay es’ theorem: m J ( x ) = f J ( x | λ J ) π J ( λ J ) π J ( λ J | x ) and on the property that the rhs of this equation is constant in λ J . Therefore, if an arbitrary v alue of λ J , λ ∗ J sa y , is selected and if a go o d appro ximation to π J ( λ J | x ) can b e constructed, ˆ π J ( λ J | x ), Chib’s (1995) appro ximation to the marginal likelihoo d is ˆ m J ( x ) = f J ( x | λ ∗ J ) π J ( λ ∗ J ) ˆ π J ( λ ∗ J | x ) . (8) In the case of mixtures, a natural approximation to π J ( λ J | x ) is the Rao-Blackw ell estimate ˆ π J ( λ ∗ J | x ) = 1 T T X t =1 π J ( λ ∗ J | x , z ( t ) ) , where the z ( t ) ’s are the laten t v ariables simulated by the MCMC sampler. T o b e efficient, this metho d requires (a) a go o d choice of λ ∗ J but, since in the case of mixtures, the likelihoo d is computable, λ ∗ J can b e c hosen as the MCMC approximation to the MAP estimator and, (b) a goo d approximation to π J ( λ J | x ). This later requiremen t is the core of Neal’s (1999) criticism: while, at a formal lev el, ˆ π J ( λ ∗ J | x ) is a con verging (parametric) appro ximation to π J ( λ J | x ) by virtue of the ergodic theorem, this ob viously re- quires the chain ( z ( t ) ) to conv erge to its stationarit y distribution. Unfortunately , as discussed previously , in the case of mixtures, the Gibbs sampler rarely conv erges b ecause of the lab el switc hing phenomenon describ ed in Section 3.1, so the appro ximation ˆ π J ( λ ∗ J | x ) is un trustw orthy . Neal (1999) demonstrated via a numerical experiment that (8) is significantly differen t from the true v alue m J ( x ) when lab el switc hing do es not o ccur. There is, ho wev er, a fix to this problem, also explored by Berkhof et al. (2003), whic h is to reco ver the label switching symmetry a posteriori, replacing ˆ π J ( λ ∗ J | x ) in (8) ab ov e with ˆ π J ( λ ∗ J | x ) = 1 T J ! X σ ∈ S J T X t =1 π J ( σ ( λ ∗ J ) | x , z ( t ) ) , where S J denotes the set of all permutations of { 1 , . . . , J } and σ ( λ ∗ J ) denotes the transform of λ ∗ J where comp onen ts are switched according to the p ermutation σ . Note that the p ermutation can equally b e applied to λ ∗ J or to the z ( t ) ’s but that the former is usually more efficient from a computational p oin t of view given that the sufficien t statistics only hav e to be computed once. The justification for 21 J 2 3 4 5 6 7 8 ˆ ρ J ( x ) -115.68 -103.35 -102.66 -101.93 -102.88 -105.48 -108.44 T able 3: Estimations of the marginal lik eliho o ds b y the symmetrised Chib’s approximation (based on 10 5 Gibbs iterations and, for J > 5, 100 p erm utations selected at random in S J ). this mo dification either stems from a Rao-Blackw ellisation argument, namely that the p ermutations are ancillary for the problem and should b e in tegrated out, or follo ws from the general framew ork of Kong et al. (2003) where symmetries in the dominating measure should b e exploited tow ards the improv ement of the v ariance of Monte Carlo estimators. Example 12. (Example 8 contin ued) In the case of the normal mixture case and the galaxy dataset, using Gibbs sampling, label switc hing do es not occur. If w e compute log ˆ m J ( x ) using only the original estimate of Chib (1995) (8), the [logarithm of the] estimated marginal lik eliho o d is ˆ ρ J ( x ) = − 105 . 1396 for J = 3 (based on 10 3 sim ulations), while introducing the p erm utations leads to ˆ ρ J ( x ) = − 103 . 3479. As already noted by Neal (1999), the difference b etw een the original Chib’s (1995) appro ximation and the true marginal lik eliho o d is close to log( J !) (only) when the Gibbs sampler remains concentrated around a single mo de of the p osterior distribution. In the curren t case, we hav e that − 116 . 3747 + log(2!) = − 115 . 6816 exactly! (W e also chec k ed this numerical v alue against a brute-force estimate obtained b y sim ulating from the prior and av eraging the lik eliho o d, up to fourth digit agreemen t.) A similar result holds for J = 3, with − 105 . 1396 + log(3!) = − 103 . 3479. Both Neal (1999) and F r ¨ uhwirth-Sc hnatter (2004) also pointed out that the log( J !) difference was unlikely to hold for larger v alues of J as the mo des b ecame less separated on the p osterior surface and th us the Gibbs sampler was more lik ely to explore incompletely several mo des. F or J = 4, we get for instance that the original Chib’s (1995) appro ximation is − 104 . 1936, while the a verage ov er p ermutations giv es − 102 . 6642. Similarly , for J = 5, the difference b etw een − 103 . 91 and − 101 . 93 is less than log(5!). The log( J !) difference cannot therefore b e used as a direct correction for Chib’s (1995) approximation because of this difficulty in con trolling the amoun t of ov erlap. Ho wev er, it is unnecessary since using the permutation av erage resolv es the difficult y . T able 3 sho ws that the prefered v alue of J for the galaxy dataset and the current c hoice of prior distribution is J = 5. J When the num ber of components J grows to o large for all p ermutations in S J to be considered in the av erage, a (random) subsample of p erm utations can b e simulated to keep the computing time to a reasonable level when k eeping the iden tity as one of the permutations, as in T able 3 for J = 6 , 7. (See Berkhof et al. 2003 for another solution.) Note also that the discrepancy b etw een the original Chib’s (1995) approximation and the a verage o ver p erm utations is a goo d indicator of the mixing prop erties of the Mark ov chain, if a further conv ergence indicator is requested. Example 13. (Example 6 contin ued) F or instance, in the setting of Example 6 with a = b = 1, b oth the approximation of Chib (1995) and the symmetrized one are identical. When comparing a single class mo del with a tw o class mo del, the corresp onding (log-)marginals are ˆ ρ 1 ( x ) = 4 Y i =1 Γ(1) Γ(1 / 2) 2 Γ( n i + 1 / 2)Γ( n − n i + 1 / 2) Γ( n + 1) = − 552 . 0402 and ˆ ρ 2 ( x ) ≈ − 523 . 2978, giving a clear preference to the tw o class model. J Ac kno wledgemen ts W e are grateful to the editors for the in vitation as w ell as to Gilles Celeux for a careful reading of an earlier draft and for imp ortan t suggestions related with the laten t class model. References Berkhof, J., v an Mechelen, I., and Gelman, A. (2003). A Bay esian approac h to the selection and testing of mixture mo dels. Statistic a Sinic a , 13:423–442. 22 Bro oks, S., Giudici, P ., and Rob erts, G. (2003). Efficient construction of reversible jump Marko v chain Mon te Carlo prop osal distributions (with discussion). J. R oyal Statist. So ciety Series B , 65(1):3–55. Capp ´ e, O., Rob ert, C., and Ryd ´ en, T. (2003). Reversible jump, birth-and-death, and more general contin uous time MCMC samplers. J. R oyal Statist. So ciety Series B , 65(3):679–700. Casella, G., Rob ert, C., and W ells, M. (2004). Mixture models, latent v ariables and partitioned imp ortance sampling. Statistic al Metho dolo gy , 1:1–18. Celeux, G., Hurn, M., and Rob ert, C. (2000). Computational and inferential difficulties with mixtures posterior distribution. J. Americ an Statist. Asso c. , 95(3):957–979. Chib, S. (1995). Marginal lik eliho o d from the Gibbs output. J. Americ an Statist. Asso c. , 90:1313–1321. Chib, S. and Jeliazko v, I. (2001). Marginal likelihoo d from the Metrop olis–Hastings output. J. Americ an Statist. Asso c. , 96:270–281. Chopin, N. and Rob ert, C. (2007). Con templating evidence: properties, extensions of, and alternatives to nested sampling. T ec hnical Rep ort 2007-46, CEREMADE, Universit ´ e Paris Dauphine. Dempster, A., Laird, N., and Rubin, D. (1977). Maxim um likelihoo d from incomplete data via the EM algorithm (with discussion). J. R oyal Statist. So ciety Series B , 39:1–38. Dieb olt, J. and Robert, C. (1990). Bay esian estimation of finite mixture distributions, Part i: Theoretical aspects. T echnical Report 110, LST A, Universit ´ e P aris VI, Paris. Dieb olt, J. and Robert, C. (1994). Estimation of finite mixture distributions by Bay esian sampling. J. R oyal Statist. Society Series B , 56:363–375. Dupuis, J. and Robert, C. (2003). Mo del choice in qualitative regression mo dels. J. Statistic al Planning and Infer enc e , 111:77–94. Escobar, M. and W est, M. (1995). Bay esian prediction and density estimation. J. Americ an Statist. Asso c. , 90:577–588. F earnhead, P . (2005). Direct simulation for discrete mixture distributions. Statistics and Computing , 15:125–133. F eller, W. (1970). A n Intr o duction to Pr ob ability The ory and its Applic ations , v olume 1. John Wiley , New Y ork. F r ¨ uh wirth-Schnatter, S. (2004). Estimating marginal lik eliho o ds for mixture and Mark ov switc hing models using bridge sampling techniques. The Econometrics Journal , 7(1):143–167. F r ¨ uh wirth-Schnatter, S. (2006). Finite Mixtur e and Markov Switching Mo dels . Springer-V erlag, New Y ork, New Y ork. Gelfand, A. and Dey , D. (1994). Ba yesian model c hoice: asymptotics and exact calculations. J. R oyal Statist. So ciety Series B , 56:501–514. Gew eke, J. (2007). Interpretation and inference in mixture mo dels: Simple MCMC works. Comput. Statist. Data Analysis . (T o app ear). Goutis, C. and Rob ert, C. (1998). Mo del choice in generalized linear mo dels: a Bay esian approac h via Kullbac k– Leibler pro jections. Biometrika , 85:29–37. Iacobucci, A., Marin, J.-M., and Rob ert, C. (2008). On v ariance stabilisation by double Rao-Blackw ellisation. T echnical report, CEREMADE, Universit ´ e Paris Dauphine. Kass, R. and Raftery , A. (1995). Bay es factors. J. Americ an Statist. Asso c. , 90:773–795. Kong, A., McCullagh, P ., Meng, X.-L., Nicolae, D., and T an, Z. (2003). A theory of statistical mo dels for Monte Carlo integration. J. R oyal Statist. So ciety Series B , 65(3):585–618. (With discussion.). La vine, M. and W est, M. (1992). A Bay esian metho d for classification and discrimination. Canad. J. Statist. , 20:451–461. Liang, F. and W ong, W. (2001). Real-parameter evolutionary Mon te Carlo with applications to Ba yesian mixture mo dels. J. Americ an Statist. Assoc. , 96(454):653–666. 23 MacLac hlan, G. and P eel, D. (2000). Finite Mixture Mo dels . John Wiley , New Y ork. Magidson, J. and V ermun t, J. (2000). Laten t class analysis. In Kaplan, D., editor, The Sage Handbo ok of Quantitative Methodolo gy for the So cial Scienc es , pages 175–198, Thousand Oakes. Sage Publications. Marin, J.-M., Mengersen, K., and Rob ert, C. (2005). Bay esian mo delling and inference on mixtures of distribu- tions. In Rao, C. and Dey , D., editors, Handb o ok of Statistics , volume 25. Springer-V erlag, New Y ork. Marin, J.-M. and Rob ert, C. (2007). Bayesian Cor e . Springer-V erlag, New Y ork. Mengersen, K. and Rob ert, C. (1996). T esting for mixtures: A Ba yesian entropic approac h (with discussion). In Berger, J., Bernardo, J., Dawid, A., Lindley , D., and Smith, A., editors, Bayesian Statistics 5 , pages 255–276. Oxford Universit y Press, Oxford. Moreno, E. and Liseo, B. (2003). A default Bay esian test for the num ber of components in a mixture. J. Statist. Plann. Inferenc e , 111(1-2):129–142. Neal, R. (1999). Erroneous results in “Marginal likelihoo d from the Gibbs output”. T ec hnical rep ort, Univ ersity of T oronto. Nilsson, E. D. and Kulmala, M. (2006). Aerosol formation o ver the Boreal forest in Hyyti¨ al¨ a, Finland: monthly frequency and annual cycles - the roles of air mass characteristics and synoptic scale meteorology . Atmospheric Chemistry and Physics Discussions , 6:10425–10462. P ´ erez, J. and Berger, J. (2002). Exp ected-p osterior prior distributions for model selection. Biometrika , 89(3):491– 512. Ric hardson, S. and Green, P . (1997). On Bay esian analysis of mixtures with an unknown num b er of comp onents (with discussion). J. R oyal Statist. So ciety Series B , 59:731–792. Rob ert, C. (2001). The Bayesian Choic e . Springer-V erlag, New Y ork, second edition. Rob ert, C. and Casella, G. (2004). Monte Carlo Statistic al Metho ds . Springer-V erlag, New Y ork, second edition. Rob ert, C. and Titterington, M. (1998). Reparameterisation strategies for hidden Marko v mo dels and Ba yesian approac hes to maximum likelihoo d estimation. Statistics and Computing , 8(2):145–158. Ro eder, K. and W asserman, L. (1997). Practical Bay esian densit y estimation using mixtures of normals. J. Americ an Statist. Asso c. , 92:894–902. Sah u, S. and Cheng, R. (2003). A fast distance based approach for determining the n um b er of components in mixtures. Canadian J. Statistics , 31:3–22. Skilling, J. (2006). Nested sampling for general Ba yesian computation. Bayesian A nalysis , 1(4):833–860. Steele, R., Raftery , A., and Emond, M. (2006). Computing normalizing constants for finite mixture mo dels via incremental mixture imp ortance sampling (IMIS). Journal of Computational and Graphic al Statistics , 15:712–734. Stephens, M. (1997). Bayesian Metho ds for Mixtur es of Normal Distributions . PhD thesis, Universit y of Oxford. Stephens, M. (2000). Ba yesian analysis of mixture models with an unknown n umber of comp onents—an alter- nativ e to reversible jump metho ds. Ann. Statist. , 28:40–74. Stouffer, S. and T oby , J. (1951). Role conflict and personality . Americ an Journal of So ciolo gy , 56:395–406. T anner, M. and W ong, W. (1987). The calculation of p osterior distributions by data augmentation. J. Americ an Statist. Assoc. , 82:528–550. V erdinelli, I. and W asserman, L. (1992). Ba yesian analysis of outliers problems using the Gibbs sampler. Statist. Comput. , 1:105–117. W asserman, L. (2000). Asymptotic inference for mixture models using data dep endent priors. J. R oyal Statist. So ciety Series B , 62:159–180. 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment