The Rate Loss of Single-Letter Characterization: The "Dirty" Multiple Access Channel
For general memoryless systems, the typical information theoretic solution - when exists - has a "single-letter" form. This reflects the fact that optimum performance can be approached by a random code (or a random binning scheme), generated using in…
Authors: Tal Philosof, Ram Zamir
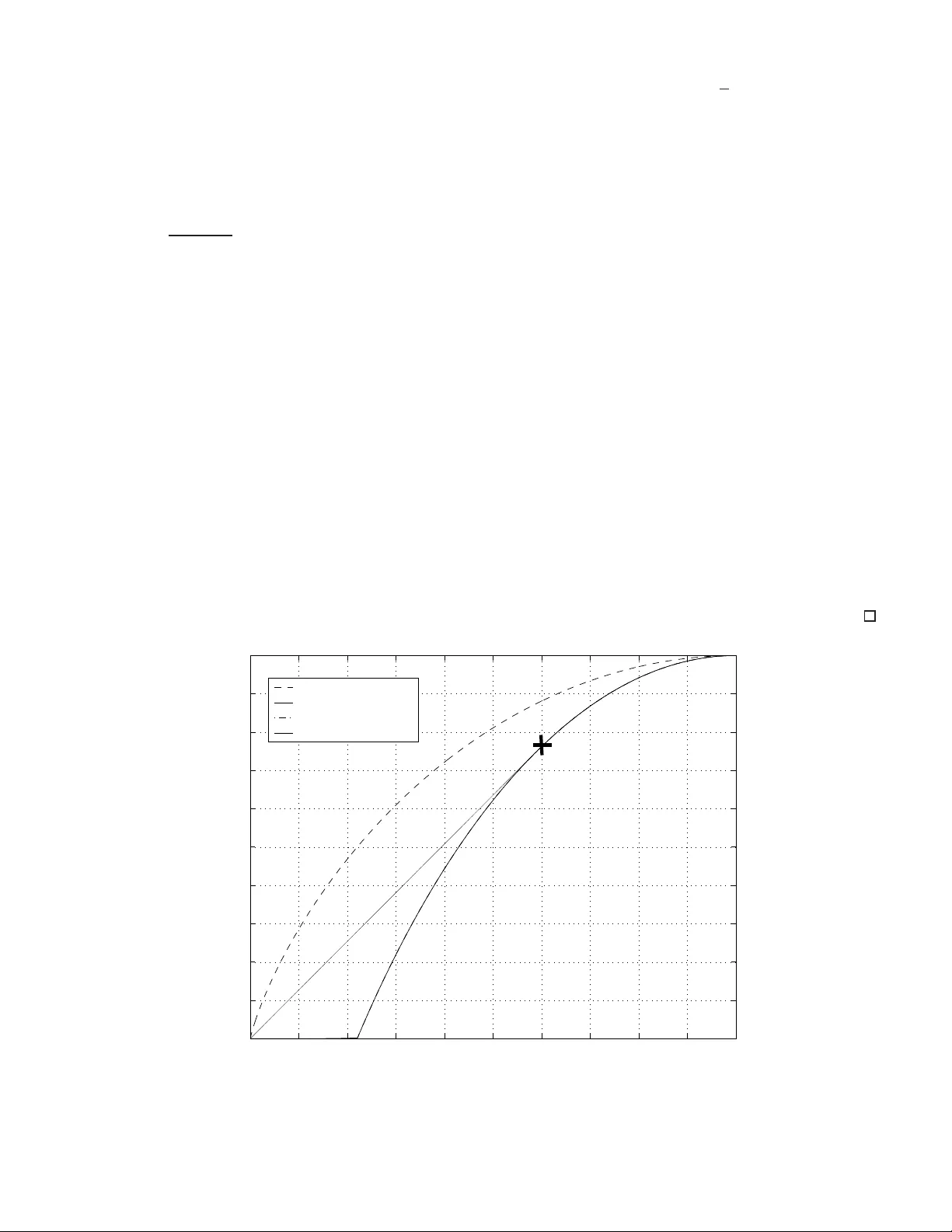
1 The Rate Loss of Single-Letter C haracteriz ation: The “ Dirty” Multiple Access Ch annel T al Philosof and Ram Zamir † Dept. of Electrical Enginee ring - Sy stems, T el-A viv Univ ersity T e l-A viv 69978, ISRAEL talp,zamir@eng.tau.a c.il Submitted to IEEE T rans. on Information The ory Mar ch 2008 Abstract For general memo ryless systems, the typical informa tion theoretic solution - when exists - h as a “single-letter” form. This r eflects the fact that optimum p erform ance can be approached b y a ran dom c ode (or a rand om binning scheme), generated using independ ent and identically distributed c opies o f som e single- letter d istribution. Is that the form o f th e solution of any (infor mation theor etic) pro blem? In fact, some counter examp les are known. The most famous is th e “two he lp one” problem: K orn er and Marton showed that if we want to deco de the modulo-two sum of two binary sour ces fr om their independen t encoding s, then linear coding is better than rand om coding . In this paper we provide an other counter example, th e “doub ly-dirty” multiple access chann el ( MA C). Like th e K or ner- Marton problem, this is a multi-term inal scenario where side inform ation is distributed am ong se veral terminals; each transmitter knows part of the channel inte rference but the receiver is not aw are of any part of it. W e give an explicit solution for the capacity region of a bina ry version of the doubly-dir ty MAC, demo nstrate ho w the capacity region can be appro ached using a line ar co ding scheme, and prove that the “best kn own single-letter region” is strictly co ntained in it. W e a lso state a c onjecture regarding a similar rate loss of single letter characterization in the Gau ssian case. Index T erms Multi-user informa tion theory , random binning , line ar lattice binn ing, dirty paper coding , lattice strategies, K orner-Marton problem. I . I N T RO D U C T I O N Consider the two-user / double-state memoryless multi ple acc ess channel ( MA C) with transition and state probability dis trib utions P ( y | x 1 , x 2 , s 1 , s 2 ) and P ( s 1 , s 2 ) , (1) † This research was partially supported by BSF grant No-2004 398 2 Enc. 1 Enc. 2 Dec S 1 X 1 X 2 W 1 W 2 S 2 Z Y ˆ W 1 ˆ W 2 Fig. 1. Doubly-dirty MA C respectively , where the states S 1 and S 2 are known non-causally to user 1 an d user 2 , res pectively . A special case of (1) is the additi ve chann el sho wn in Fig. 1 . In this channel, called the doubly-dirty MA C (after Costa’ s “ writing on dirty paper” [1]), the total c hanne l noise cons ists of three indep endent components: S 1 and S 2 , the interference signals, that are kno wn to us er 1 and user 2 , res pectively , a nd Z , the unknown noise, which is known to neither . The ch annel inputs X 1 and X 2 may be subject to some average cost constraint. Neither the c apacity region o f (1 ) n or tha t o f the sp ecial case of Fig. 1 are known. In this pa per we co nsider a particular binary version of the doubly-dirty MA C of Fig. 1, w here all variables are in Z 2 , i.e., { 0 , 1 } , and the unknown noise Z = 0 . Th e cha nnel output of the binary doubly-dirty MA C is given by Y = X 1 ⊕ X 2 ⊕ S 1 ⊕ S 2 , (2) where ⊕ denotes the mod 2 ad dition (xor) , and S 1 , S 2 are Bernoulli (1 / 2) and independen t. Each of the co dewor ds x i ∈ Z n 2 is a function of the message W i and the interference vector s i ∈ Z n 2 , and must satisfy the input co nstraint, 1 n w H ( x i ) ≤ q i , i = 1 , 2 , where 0 ≤ q 1 , q 2 ≤ 1 / 2 and w H ( · ) is the Hamming weight. The cod ing rates R 1 and R 2 of the two users are g i ven as usual by R i = 1 n log |W i | , where W i is the set of mes sage s of u ser i , and n is the length of the cod ew ord. The d ouble state MA C (1) generalizes the po int to point chan nel with side information (SI) at the transmitter considered by Ge l’fand and Pinsker [2]. They prove the ir direct co ding theorem us ing the framework of random binning, which is widely used in the a nalysis of multi-t erminal source and chann el co ding problems [3]. They obtain a general ca pacity expression which in volv es an auxiliary random variable U : C = max P ( u,x | s ) { H ( U | S ) − H ( U | Y ) } (3) where the maximization is ov er all the joint distributions of the form p ( u, s, y , x ) = p ( s ) p ( u, x | s ) p ( y | x, s ) . The chann el in (1) with only on e informed encoder (i.e., where S 2 = {∅} ) w as considered recently by Somekh- Baruch et a l. [4] and K otagiri and Lanema n [5]. The common me ssage ( W 1 = W 2 ) cap acity of this channel is known [4], and it in v olves us ing ra ndom binning by the informed u ser . For the binary “ one d irty user” case (i.e., 3 (2) with S 2 = 0 ) , we show that Some kh-Baruch’ s common-mes sage capacity be comes (see Ap pendix I) C com = H b ( q 1 ) , (4) where H b ( x ) , − x log 2 ( x ) − (1 − x ) log 2 (1 − x ) is the binary e ntropy fun ction. Clearly , the d oubly-dirty indi vidu al- messag e case is h arder . Thu s, it follo ws from (4) that the rate-sum in the setting of Fig. 1 is upper bound ed by R 1 + R 2 ≤ min n H b ( q 1 ) , H b ( q 2 ) o . (5) In The orem 1 we show that this upper bound is in fact tight. One approach to find a chievable rates f or the doubly-dirty MA C, is to extend the Gel’f and and Pinsker solution [2] to the two-user / d ouble-state c ase. As s hown by Jafar [6], this extension leads to the follo wing pe ntagona l inner b ound for the capac ity region of (1): R ( U 1 , U 2 ) , ( ( R 1 , R 2 ) : R 1 ≤ I ( U 1 , Y | U 2 ) − I ( U 1 ; S 1 ) R 2 ≤ I ( U 2 , Y | U 1 ) − I ( U 2 ; S 2 ) (6) R 1 + R 2 ≤ I ( U 1 , U 2 , Y ) − I ( U 1 ; S 1 ) − I ( U 2 ; S 2 ) ) for s ome P ( U 1 , U 2 , X 1 , X 2 | S 1 , S 2 ) = P ( U 1 , X 1 | S 1 ) P ( U 2 , X 2 | S 2 ) . In fact, by a stan dard time-sharing ar gument [3], the closure of the con vex hull of the s et o f all rate pairs ( R 1 , R 2 ) sa tisfying (7), R B S L , cl conv ( ( R 1 , R 2 ) ∈ R ( U 1 , U 2 ) : P ( U 1 , U 2 , X 1 , X 2 | S 1 , S 2 ) = P ( U 1 , X 1 | S 1 ) P ( U 2 , X 2 | S 2 ) ) , (7) is also achiev able 1 . T o the best of our knowledge, the s et R B S L is the best currently known sing le-letter charac- terization for the rate region of the MA C with side information a t the trans mitters (1), and in particular , for the doubly-dirty MA C (2) 2 . The achie vabilit y of (7) can be prov ed, as us ual, by an i.i.d rand om binning scheme [6]. A dif ferent method to c ancel known interference is by “linear s trategies”, i.e, binning based on the cosets of a linear code [8], [9], [10]. In the se quel, we show tha t the outer bound (5) ca n indeed be achieved by a linear coding scheme . Hence , the set of rate pairs ( R 1 , R 2 ) s atisfying (5) is the capacity region of the binary d oubly-dirty MA C. In contrast, we s how that the single-letter region (7) is strictly c ontained in this capa city re gion. Hence, a rand om binning sc heme bas ed on this extension of the Gel’f and-Pinsker solution [2] is no t optimal for this prob lem. A simil ar observation ha s b een mad e b y Korner -Marton [11] for the “two help one” source coding problem. For a spec ific binary version known as the “mo dulo-two sum” problem, they showed that the minimum pos sible 1 As i n the Gel’fand and Pi nsker solution, for a fi nite alphabet system it is enough t o optimize ov er auxiliary variables U 1 and U 2 whose alphabet size is bou nded in terms of the size of the input and state alphab ets. 2 For the case where the users ha ve also a common message W 0 to be transmitted j ointly by both enc oders, (7) can be improve d by adding another auxiliary random variable U 0 which plays the role of the common auxiliary r .v . in Marton’ s i nner bound for the non-de graded broadcast channel [7]. In this case, the joint distribution of ( U 0 , U 1 , U 2 ) is given by P ( U 0 , U 1 , U 2 ) = P ( U 0 ) P ( U 1 | U 0 ) P ( U 2 | U 0 ) , i.e, U 1 and U 2 are cond itionally independent giv en U 0 . 4 rate sum is achieved b y a linear coding scheme, while the best known single -letter express ion for this problem is strictly h igher . See the discuss ion in [11, Section IV] a nd in the end o f Sec tion III. Although the “ single-letter characterization ” is a fundamental c oncep t in information theory , it has not b een gen- erally de fined [12, p.35]. Csiszar an d K orner [13, p.259] sugges ted to define it through the n otion of computability , i.e., a problem h as a single-letter so lution if there exists a n algorithm which ca n dec ide if a point b elongs to an ε -neighborhood of the ach iev a ble rate region with polyno mial complexity in 1 / ε . Sinc e we are not aware of any other computable solution to our problem, we shall refer to (7) as the “best known single-letter characterization” . An extension of these obs ervations to continuous chan nels would be of interest. Co sta [1] con sidered the single- user case of the dirty cha nnel problem Y = X + S + Z , where the interference S a nd the noise Z are as sumed to be i.i.d. Ga ussian with variances Q and N , resp ectiv ely , and the input X is sub ject to a power constraint P . He showed that in t his case, the tr ansmitter side-information c apacity (3) c oincides w ith the z ero-interference capacity 1 2 log 2 (1 + S N R ) , wh ere S N R = P / N . Selecting the auxiliary random v ariable U in (3) such that U = X + αS, (8) where X and S are independe nt, a nd taking α = P P + N , the formula (3) and its associated random binning scheme are ca pacity achieving. The continuous (Gauss ian) version of the doubly-dirty MA C of F ig. 1 was considered in [10]. It was shown that by us ing a linear structure, i.e., lattice strategies [8], the full ca pacity region is ac hiev ed in the limit of high SNR and high lattice dimension. In contrast, it was shown that for Q → ∞ n o positi ve rate is achiev able by using the natural generalization of Co sta’ s strategy (8) to the tw o user case, while a (sc alar) modulo addition version of (8) looses ≈ 0 . 254 bit in the sum capacity . W e shall further elaborate on this issue in Sec tion IV. Similar obs ervations regarding the advantage of mo dulo-lattice modu lation with respect to a separation base d solution were made by Naz er and Gastpar [14], in the context of compu tation over linear Gauss ian networks, and also by Krit hiv as an an d Pradha n [15] for multi-termi nal rate distortion problems. The paper is or g anized as foll ows. In Se ction II the ca pacity re gion for the b inary doubly-dirty MA C (2) is deriv ed, and linear coding is shown to be optimal. Section III develops a closed form expression for the bes t known sing le-letter characte rization (7) for this chann el, and demonstrates tha t it is strictly contained in the the true capacity region. In Section IV we consider the Gauss ian doubly-dirty MA C, and s tate a conjecture re garding the c apacity loss of single-letter ch aracterization in this case. I I . T H E C A P A C I T Y R E G I O N O F T H E B I N A RY D O U B L Y - D I RT Y M AC The following theorem c haracterizes the capacity region of the binary doubly-dirty MA C of Fig. 1 . Theorem 1. The capacity re gion of the binary d oubly-dirty MAC (2) is the set of a ll rate pairs ( R 1 , R 2 ) satisfying C ( q 1 , q 2 ) , ( ( R 1 , R 2 ) : R 1 + R 2 ≤ min n H b ( q 1 ) , H b ( q 2 ) o ) . (9) Pr o of: The con verse pa rt: As explained in the Introduc tion (5), o ne way to deri ve an upper bou nd for the rate-sum is through the gene ral one-dirty-user capacity formula [4], which we derive explicitly for the binary ca se 5 in Appendix I. Here we s how directly the con verse part, which is similar to the proof of the o uter bound for the Gaussian case in [16], [10]. W e assume that user 1 and user 2 intend to transmit a common mess age W . An u pper bound on the rate of this me ssage clearly upper boun ds the sum rate R 1 + R 2 in the individual mes sages case. Thus, n ( R 1 + R 2 ) ≤ H ( W ) = H ( W | Y n ) + I ( W ; Y n ) ≤ I ( W ; Y n ) + nǫ n (10) = H ( Y n ) − H ( Y n | W ) + nǫ n = H ( Y n ) − H ( Y n | W , S n 1 , S n 2 ) − I ( S n 1 , S n 2 ; Y n | W ) + nǫ n = H ( Y n ) − I ( S n 1 , S n 2 ; Y n | W ) + nǫ n (11) = H ( Y n ) − H ( S n 1 , S n 2 | W ) + H ( S n 1 , S n 2 | W , Y n ) + nǫ n ≤ − n + H ( S n 1 | W , Y n ) + H ( S n 2 | W , Y n , S n 1 ) + nǫ n (12) ≤ H ( X n 1 ⊕ X n 2 ⊕ S n 1 | W , Y n , S n 1 ) + nǫ n (13) = H ( X n 2 | W , Y n , S n 1 ) + nǫ n (14) ≤ nH b ( q 2 ) + nǫ n , (15) where (10) follows fr om Fano’ s inequality where ǫ n → 0 as the error p robability P ( n ) e goes to ze ro for n → ∞ ; (11) follows since Y is fully known gi ven W , S 1 and S 2 ; (12) follo ws from the ch ain rule for e ntropy , a nd due to H ( Y n ) ≤ n and H ( S n 1 , S n 2 | W ) = H ( S n 1 ) + H ( S n 2 ) = 2 n since W , S n 1 and S n 2 are mutually indep endent; (13) follo ws since H ( S n 1 | W , Y n ) ≤ n and Y n = X n 1 ⊕ X n 2 ⊕ S n 1 ⊕ S n 2 ; (14) foll ows s ince X n 1 is a function of ( W , S n 1 ) , finally (15) follo ws since H ( X n 2 | W , Y n , S n 1 ) ≤ H ( X n 2 ) ≤ nH b ( q 2 ) . In the sa me way we ca n show that R 1 + R 2 ≤ H b ( q 1 ) + ǫ n . The con verse part follows since for n → ∞ we have tha t ǫ n → 0 , thus P ( n ) e → 0 . The dire ct part is based on the scheme for the point-to-point b inary d irty pape r channe l [9]. W e de fine q , min { q 1 , q 2 } . In view of the c on verse part, it is sufficient to sh ow ach iev ab ility of the po int ( R 1 , R 2 ) = ( H b ( q ) , 0) , since the outer bound may be achieved by time sharing with the symmetric point ( R 1 , R 2 ) = (0 , H b ( q )) . The corner point ( R 1 , R 2 ) = ( H b ( q ) , 0) corresponds to the “helper problem”, i.e., us er 2 tries to help use r 1 to trans mit at its highest rate. Th e encoders an d decoder are desc ribed using a b inary linear c ode C ( n, k ) with pa rity c heck ma trix H . Let v ∈ Z n − k 2 be a syndrome of the co de C , where we n ote that ea ch syndrome represe nts a dif ferent cos et of the linear c ode C . Let f ( v ) de note the “ leader” of (or the minimum weight vector in) the cose t asso ciated with the s yndrome v [17, Chap. 6], hence f : { 0 , 1 } n − k → { 0 , 1 } n . For a ∈ Z n 2 , we define the n -dimensional mo dulo operation over the c ode C as a mod C , f ( H a ) , 6 which is the lead er of the coset to which the vector a belongs. • Encoder of user 1 : Let the transmitted mes sage v 1 ∈ Z n − k 2 be a syndrome in C , and let ˜ x 1 = f ( v 1 ) b e its coset leader . In pa rticular v 1 = H ˜ x 1 . T ran smit the modulo of the code C with res pect to the dif ference between ˜ x 1 and s 1 , i.e., x 1 = ( ˜ x 1 ⊕ s 1 ) mod C = f ( v 1 ⊕ H s 1 ) . • Encoder of user 2 : (functions as a “ helper” for user 1 ). Transmit x 2 = s 2 mod C = f ( H s 2 ) . • Decoder: 1. R econstruct ˜ x 1 by ˆ ˜ x 1 = y mod C . 2. R econstruct the transmitted cos et of use r 1 by ˆ v 1 = H ˆ ˜ x 1 . In fact, the transmitted coset ca n be reconstructed directly as ˆ v 1 = H ˆ ˜ x 1 = H ( y mo d C ) = H y , where the last e quality follows since y mod C an d y are in the same coset. It follows that the decode r correctly decod es the mes sage cose t v 1 , s ince ˆ v 1 = H · y mo d C = H · [ ˜ x 1 ⊕ s 1 ⊕ s 2 ⊕ s 1 ⊕ s 2 ] mo d C = H ˜ x 1 = v 1 , where the third equality follows since ˜ x 1 and ˜ x 1 mo d C are in the same coset. It is left to relate the coding rate R 1 = 1 n log { 0 , 1 } n − k = 1 − k /n to the inpu t constraint q . Form [18], the re exists a binary linear cod e with covering radius ρ that s atisfies k n ≤ 1 − H b ( ρ/n ) + ǫ where ǫ → 0 as n → ∞ . The a chiev ability o f the point ( H b ( q ) , 0) follows by using q = ρ/n , thus R 1 = 1 − k /n ≥ H b ( q ) − ǫ , while w H ( x 1 ) = w H ( f ( v 1 ⊕ H s 1 )) ≤ ρ and w H ( x 2 ) = w H ( f ( H s 2 )) ≤ ρ , h ence 1 n E w H { x 1 } = 1 n E w H { f ( v 1 ⊕ H s 1 ) } ≤ q 1 n E w H { x 2 } = 1 n E w H { f ( H s 2 ) } ≤ q . This comp letes the proof of the direct part o f the theorem. As stated a bove, the a chiev ability for the ca pacity region follo ws by ti me sharing the corner points ( H b ( q ) , 0) and (0 , H b ( q )) where q = min { q 1 , q 2 } . It is a lso interesting to see h ow to ac hieve the rate sum H b ( q ) for an arbitrary rate pa ir ( R 1 , R 2 ) without time sharing. For that, let the message o f use r 1 be m 1 ∈ Z l 1 2 and the mess age of user 7 2 be m 2 ∈ Z l 2 2 where l 1 + l 2 = n − k . W e defi ne the foll owing syndromes in C v 1 , [ m 1 0 0 . . . 0 | {z } l 2 ] ∈ Z n − k 2 v 2 , [0 0 . . . 0 | {z } l 1 m 2 ] ∈ Z n − k 2 v , v 1 ⊕ v 2 . Clearly , gi ven the sy ndrome v the sy ndromes v 1 and v 2 are fully known a nd the messages m 1 and m 2 as well. Let ˜ x i = f ( v i ) be the cos et leader o f v i for i = 1 , 2 . In this case the trans mission sc heme is as follo w: • Encoder of user 1 : trans mit x 1 = ( ˜ x 1 ⊕ s 1 ) mod C = f ( v 1 ⊕ H s 1 ) . • Encoder of user 2 : trans mit x 2 = ( ˜ x 2 ⊕ s 2 ) mod C = f ( v 2 ⊕ H s 2 ) . • Decoder: reconstruct ˆ v = H · y mod C . Therefore, we ha ve that ˆ v = H · y mo d C = H · ˜ x 1 ⊕ ˜ x 2 = v 1 ⊕ v 2 = v . The su m c apacity is achiev ed since R 1 + R 2 = l 1 + l 2 n = n − k n ≥ H b ( q ) − ǫ where ǫ → 0 as n → ∞ which satisfie s the inp ut cons traints. I I I . A S I N G L E - L E T T E R C H A R AC T E R I Z A T I O N F O R T H E C A PAC I T Y R E G I O N In this sec tion we charac terize the best known single-letter re gion (7) for the b inary doub ly-dirty MA C (2), and sho w that it is strictly containe d in the cap acity region (9) . For simplicity , we s hall as sume ide ntical input constraints, i.e., q 1 = q 2 = q . Definition 1 . F or a given q , the best known single-letter rate r e gion for the bina ry doubly-dirty MA C (2) , denoted by R B S L ( q ) , is the set of all rate p airs ( R 1 , R 2 ) satisfying (7) w ith the ad ditional constraints that E X 1 , E X 2 ≤ q . In the follo wing theorem we gi ve a closed form expression for R B S L ( q ) . Theorem 2 . Th e best kn own single-letter rate r e gion for the bina ry doubly-dirty MA C (2) is a trian gular re gion given by R B S L ( q ) = ( ( R 1 , R 2 ) : R 1 + R 2 ≤ u.c.e h 2 H b ( q ) − 1 i + ) , (16) where u.c .e is the uppe r con vex en velope with r espect to q , and [ x ] + , max { 0 , x } . Fig. 2 s hows the su m capacity of the binary dou bly-dirty MA C (9) versus t he best known single-letter rate sum (16) for equ al input co nstraints. T he latt er is s trictly contained in the capacity region which is ach iev ed by a linea r code. The quantity [2 H b ( q ) − 1] + is not a conv ex - ∩ function with respec t to q . The upper co n vex en velope of 8 [2 H b ( q ) − 1] + is achieved by time-sharing between the points q = 0 and q = q ∗ , 1 − 1 / √ 2 , therefore it is gi ven by R 1 + R 2 ≤ ( 2 H b ( q ) − 1 , q ∗ ≤ q ≤ 1 / 2 C ∗ q , 0 ≤ q ≤ q ∗ , (17) where C ∗ , 2 H b ( q ∗ ) − 1 q ∗ . Pr o of: The direct part is shown by choosing in (6) U 1 = S 1 ⊕ X 1 and U 2 = S 2 ⊕ X 2 , where X 1 , X 2 ∼ Bernoulli ( q ) and X 1 , X 2 , S 1 , S 2 are ind epend ent. From (6) the achiev able rate sum is giv en by R 1 + R 2 = I ( U 1 , U 2 ; Y ) − I ( U 1 , U 2 ; S 1 , S 2 ) = H ( U 1 | S 1 ) + H ( U 2 | S 2 ) − H ( U 1 , U 2 | U 1 ⊕ U 2 ) (18) = H ( U 1 | S 1 ) + H ( U 2 | S 2 ) − H ( U 1 | U 1 ⊕ U 2 ) − H ( U 2 | U 1 ⊕ U 2 , U 1 ) (19) = H ( X 1 ) + H ( X 2 ) − H ( U 1 | U 1 ⊕ U 2 ) (20) = 2 H b ( q ) − 1 , (21) where (18) follows since Y = U 1 ⊕ U 2 ; (19) follo ws from the chain rule for en tropy; (20) foll ows since U 2 is fully known given U 1 ⊕ U 2 , U 1 thus H ( U 2 | U 1 ⊕ U 2 , U 1 ) = 0 ; (21) follows since H ( X i ) ≤ H b ( q ) and since U 1 , U 2 are independ ent with P ( U i = 1) = 1 / 2 thus H ( U 1 | U 1 ⊕ U 2 ) = H ( U 1 ) = 1 . The con verse p art of the proof is gi ven in App endix II. 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 q Rate Sum capacity − H b (q) Best known single letter [2Hb(q)−1] + F max (q,q) H b (q) u.c.e{[2H b (q)−1] + } q * Fig. 2. The rate sum of binary doub ly-dirty MA C vs. best known si ngle-letter rate sum wi th input constraints E X 1 , E X 2 ≤ q . 9 W e see that the binary doubly-dirty MA C is a memoryless channel c oding problem, where the capacity re gion is ach iev ab le b y a linea r code , while the be st known single-letter rate region is strictly co ntained in the capacity region. This may be explained b y the f act that each user has only pa rtial side informati on, and distrib uted random binning is unable to c apture the linear structure of the channel. In order to und erstand the limitation of rando m b inning versus a linear code , we consider these two schemes for high enoug h q , that is 2 H b ( q ) − 1 ≥ 0 . The random binning sche me u ses U i = X i ⊕ S i where X i ∼ Bernoulli ( q ) and S i ∼ Bernoulli (1 / 2) are independ ent, the refore Y = U 1 ⊕ U 2 where U i ∼ Bernoulli (1 / 2) f or i = 1 , 2 . Each transmitter maps the me ssag e (bin) W i into a codeword u i which is with high p robability at a Hamming distance of nq from s i . Therefore, giv en the vectors ( s n 1 , s n 2 ) , the a vail able input space is approximately 2 nH ( U 1 ,U 2 | S 1 ,S 2 ) = 2 nH ( X 1 ,X 2 ) = 2 2 nH b ( q ) . Given the received vector y , the residual a mbiguity is giv en b y 2 nH ( U 1 ,U 2 | Y ) = 2 n [ H ( U 1 | Y )+ H ( U 2 | Y ,U 1 )] = 2 n , since H ( U 1 | Y ) = 1 and H ( U 2 | Y , U 1 ) = 0 . As a result, the a chiev able rate s um is gi ven by R 1 + R 2 = 1 n log 2 | input sp ace | | residual ambigu ity space | ≈ 2 H b ( q ) − 1 . The linear c oding sch eme shown in Theorem 1 ha s the same inp ut sp ace size as the random binning sc heme, i.e., 2 2 nH b ( q ) , since each user has 2 nH b ( q ) cosets. Howe ver , given the recei ved vector y the re are 2 nH b ( q ) possible pairs of cosets, i.e., the residual ambiguity is only 2 nH b ( q ) . Therefore, the linear code achie ves rate sum of R 1 + R 2 ≈ 2 H b ( q ) − H b ( q ) = H b ( q ) . T he advantage of the linear coding sche me res ults from the “ordered structure” of the linear co de, which d ecreas es the residu al ambiguity from 1 bit in random co ding to H b ( q ) . The followi ng example illustrates the above ar guments for the cas e tha t user 2 is a “helper” for user 1 , i.e, R 2 = 0 , a nd use r 1 t ransmits at his highest rate for each tech nique (random binning or li near c oding). T a ble I summarizes the rates and codebooks sizes for each use r for q = 0 . 3 , that is H b ( q ) ≈ 0 . 8 8 b it. Random binning Linear code Rate sum 2 H b ( q ) − 1 = 0 . 76 bit H b ( q ) = 0 . 88 bit Code word s per bin/coset 2 nI ( U i ; S i ) = 2 n [1 − H b ( q )] = 2 0 . 12 n 2 n [1 − H b ( q )] = 2 0 . 12 n Helper (user 2 ) - codebook size 2 nI ( U 2 ; S 2 ) = 2 n [1 − H b ( q )] = 2 0 . 12 n 2 n [1 − H b ( q )] = 2 0 . 12 n User 1 - cod ebook size 2 0 . 76 n 2 0 . 12 n = 2 0 . 88 n 2 0 . 12 n 2 0 . 88 n = 2 n Number of po ssible codew ord pairs 2 0 . 88 n 2 0 . 12 n = 2 n 2 n 2 0 . 12 n = 2 1 . 12 n T ABLE I R A N D O M B I N N I N G A N D L I N E A R C O D I N G S C H E M E S C O D E B O O K S S I Z E S F O R T H E H E L P E R P R O B L E M W I T H q = 0 . 3 . K orner an d Marton [11 ] observed a similar behavior for the “two h elp one” source coding problem shown in Fig. 3. In this p roblem, there are three b inary sources X , Y , Z , wh ere Z = X ⊕ Y , and the joint d istrib ution of X and Y is symmetric with P ( X 6 = Y ) = θ . The goal is to encode the source s X and Y separately suc h that Z c an 10 Dec. Enc. X Enc. Y Enc. Z ˆ Z Y X Z = X ⊕ Y Fig. 3. The K orner-M arton configuration. be reco nstructed lossles sly . K orner and Marton s howed that the rate sum required is at lea st R x + R y ≥ 2 H ( Z ) , (22) and furthermore, this rate sum can be a chieved by a linear c ode: each e ncode r transmits the s yndrome of the observed source relative to a g ood linea r binary code for a BSC with crossover probability θ . In con trast, the “one help one ” problem [19 ], [20] has a c losed single-letter expre ssion for the rate region, which correspond s to a random binning coding scheme. K o rner and Marton [11] ge neralize the expre ssion of [19], [20] to the “two help one ” problem, and show that the minimal rate su m required u sing this expression is given by R x + R y ≥ H ( X, Y ) . (23) The region (23 ) c orresponds to Slepian-W olf e ncoding o f X and Y , and it c an also be de ri ved from the Burger -T ung achiev able region [21] for distrib uted coding for X and Y with one recons truction ˆ Z under the distortion measure d ( X, Y , ˆ Z ) , X ⊕ Y ⊕ ˆ Z . Clea rly , the region (6) is strictly c ontained in the K orner-Marton region R x + R y ≥ 2 H ( Z ) (22) (since H ( X , Y ) = 1 + H ( Z ) > 2 H ( Z ) for Z ∼ Bernoulli ( θ ) , where θ 6 = 1 2 ). For further background on related source cod ing problems, see [15]. I V . T H E G AU S S I A N D O U B L Y - D I RT Y M AC In this section we introdu ce our conjec ture re garding the rate loss of the be st known single-letter characterization for the capa city region of the two-user Gaussian dou bly-dirty MA C at high SNR. The Gaussian doubly-dirty MA C [10] is gi ven by Y = X 1 + X 2 + S 1 + S 2 + Z , (24) where Z ∼ N (0 , N ) is ind epende nt o f X 1 , X 2 , S 1 , S 2 , an d wh ere user 1 and u ser 2 must satisfy the power constraints, 1 n P n i =1 X 2 1 i ≤ P 1 and 1 n P n i =1 X 2 2 i ≤ P 2 see Fig. 1. The interference s ignals S 1 and S 2 are known non-caus ally to the transmitters o f u ser 1 and user 2 , res pectively . W e shall as sume that S 1 and S 2 are independent Gaussian with variances going to infinity , i.e., S i ∼ N (0 , Q i ) where Q i → ∞ for i = 1 , 2 . T he signal to noise ratios for the two us ers are S N R 1 = P 1 N and S N R 2 = P 2 N . 11 The ca pacity region at high SNR, i.e ., S N R 1 , S N R 2 ≫ 1 , is given by [10], R 1 + R 2 ≤ 1 2 log 2 min { P 1 , P 2 } N ! , (25) and it is a chiev able by a modulo lattice coding scheme of d imension going to infin ity . In contrast, it was shown in [10] that at high SNR and strong independent Gaus sian interference s, the natural generalization o f Co sta’ s strate gy (8) for the two users case, i.e., with au xiliary random v a riables U 1 = X 1 + S 1 and U 2 = X 2 + S 2 , is not a ble to achieve any positive rate . A be tter choice for U 1 and U 2 sugges ted in [10] is a modulo version of Costa’ s strate gy (8), U ∗ i = [ X i + S i ] mod ∆ i , (26) where ∆ i = √ 12 P i , and where X i ∼ Unif [ − ∆ i 2 , ∆ i 2 ) is independent of S i , for i = 1 , 2 . In this c ase the rate loss with respe ct to (25) is 1 2 log 2 π e 6 ≈ 0 . 2 54 bit . The best known single-letter cap acity region for the Gaussian doubly-dirty MA C (24) is de fined as the set of all rate pairs ( R 1 , R 2 ) s atisfying ( 7), where X 1 and X 2 are res tricted to the power cons traints E X 2 1 ≤ P 1 and E X 2 2 ≤ P 2 . W e believ e that for high SNR and strong interference, the modulo- ∆ strategy (26) is a n o ptimum choice for ( X 1 , X 2 , U 1 , U 2 ) in (7) for the Gaussian doubly-dirty MA C. This implies the foll owi ng c onjecture abou t the rate loss of the best kn own single-letter charac terization. Conjecture 1. F or the Gaussian doubly-dirty MA C, at high SNR and str on g interfer e nce, the best known single-letter expr e ssion R sum B S L (7) loose s C sum − R sum B S L = 1 2 log 2 π e 6 ≈ 0 . 2 54 bit , (27) with respect to the sum capacity C sum (25) . Note tha t the right hand side of (27 ) is the well known “shap ing loss” [22] (equiv alent to a 1 . 53 dB po wer loss). A heuristic approac h to a ttack the proof of this con jecture is to foll ow the steps of the proo f of the co n verse part in the binary c ase (The orem 2) . First, in Lemma 6 we deri ve a simplified sing le-letter formula, G max ( P 1 , P 2 ) , which is a nalogous to Lemma 1 in the bina ry case . The next step would be to o ptimize this expression. However , an optimal cho ice for the auxiliary random vari ables V 1 , V ′ 1 , V 2 , V ′ 2 (provided in the binary cas e by Lemma 2 and Lemma 3) is unfortunately still missing for the Gau ssian case. The expression in Lemma 6 is close in spirit to the point-to-point dirty tape capac ity for high SNR and strong interference [8]. In [8] it is shown that optimizing the capac ity is eq uiv ale nt to minimum e ntr op y-constrained scalar qu antization in high resolution, which is ac hiev ed by a lattice quantizer . Clea rly , if we co uld show a s imilar lemma for the two variable pairs in the maximization of Lemma 6, i.e., that it is a chieved by a p air of lattice quantizers, then the conjecture would be a n immediate conseq uence . It should be noted tha t the above discussion is valid only for strong interferenc es S 1 and S 2 . For interference with finite power , it see ms that cancelling the interference pa rt of the time and s taying silence the rest o f the time (like in the time-sharing region 0 ≤ q ≤ q ∗ in the binary case) ma y ach iev e better rates. 12 V . S U M M A RY A memoryless information theo retic problem is conside red open as long as we are miss ing a gene ral single-letter characterization for it s informati on performance. This goes ha nd in hand with the optimality of the random coding approach for those problems whic h are currently solved. W e examine d this traditional vie w for the me moryless doubly-dirty MA C. In the b inary cas e, we showed tha t the bes t known s ingle letter ch aracterization is strictly co ntained in the region achiev able by linear coding , a nd that the latter is in f act the full capa city region of the problem. In the Gaussian case, we conjectured that the best known single-letter ch aracterization s uff ers an inherent rate loss (equal to the well known “s haping loss” 0 . 5 log ( πe/ 6) ), and we provide a partial proof. This is in co ntrast to the as ymptotic optimality (dimension → ∞ ) of lattice strate gies, as rec ently sho wn in [10]. The unde rlying reason for these performance gaps is tha t random binning is in general not optimal wh en side information is distrib uted amo ng more tha n on e terminal in the ne twork. In the specific cas e of the doubly-dirty MA C (like in K orner -Marton’ s modulo-two sum problem [11 ] and similar settings [14 ], [15] ), the linear structure of the network allows to show that linear binning is not only b etter , b ut it is capacity ach ieving. A P P E N D I X I A C L O S E D F O R M E X P R E S S I O N F O R T H E C A P AC I T Y O F T H E B I N A RY M AC W I T H O N E D I RT Y U S E R W e consider the b inary dirty MA C (2) with S 2 = 0 , Y = X 1 ⊕ X 2 ⊕ S 1 , (28) where S 1 ∼ Bernoulli(1/2) is known non -causally at the e ncoder of u ser 1 with the inpu t c onstraints 1 n W H ( x i ) ≤ q i for i = 1 , 2 . W e show that the co mmon mes sage ( W 1 = W 2 = W ) capacity of this channel is gi ven by C com = H b ( q 1 ) . (29) T o prove (29), conside r the general expression for the c ommon messa ge capacity of the MA C with on e informed user [4], gi ven by C com = max U 1 ,X 1 ,X 2 { I ( U 1 , X 2 ; Y ) − I ( U 1 , X 2 ; S 1 ) } , (30) where the maximization is ov er al the joint distrib utions P ( S 1 , X 1 , X 2 , U 1 , Y ) = P ( S 1 ) P ( X 2 ) P ( U 1 | X 2 , S 1 ) P ( X 1 | S 1 , U 1 ) P ( Y | X 1 , X 2 , S 1 ) . The conv erse part of (29) follows since for any U 1 , X 1 , X 2 , the commo n message rate R com can be uppe r b ounded 13 by R com = I ( U 1 , X 2 ; Y ) − I ( U 1 , X 2 ; S 1 ) = H ( S 1 | U 1 , X 2 ) − H ( Y | U 1 , X 2 ) + H ( Y ) − H ( S 1 ) ≤ H ( S | U 1 , X 2 ) − H ( Y | U 1 , X 2 ) (31) = H ( S 1 | U 1 , X 2 ) − H ( X 1 ⊕ S 1 | U 1 , X 2 ) (32) = H ( S 1 | T ) − H ( X 1 ⊕ S 1 | T ) (33) = E T n H ( S 1 | T = t ) − H ( X 1 ⊕ S 1 | T = t ) o (34) = E T n H b ( α t ) − H b ( β t ) o , (35) where (31) follows s ince H ( Y ) ≤ 1 and H ( S 1 ) = 1 ; (32) follows s ince Y = X 1 ⊕ X 2 ⊕ S 1 ; (33) follows the d efinition T , ( U 1 , X 2 ) ; (34) follo ws from the definition of the conditional entropy; (35 ) follows from the follo wing definitions α t , P ( S 1 = 1 | T = t ) and β t , P ( S 1 ⊕ X 1 = 1 | T = t ) for any t ∈ T . W e a lso defin e q 1 | t , P ( X 1 = 1 | T = t ) = E { X 1 | T = t } , therefore the input constraint of user 1 can be written as E X 1 = E T E { X 1 | T = t } = E T { q 1 | t } ≤ q 1 . (36) W ithout loss of generality , we can on ly conside r α t , β t , q 1 | t ∈ [0 , 1 / 2] in (35) for any t ∈ T . Thus, R com ≤ E T n H b ( α t ) − H b [ α t − q 1 | t ] + o (37) ≤ E T n H b ( q 1 | t ) o (38) ≤ H b E T { q 1 | t } (39) ≤ H b ( q 1 ) , (40) where (37) follo ws from (35) an d since H b ( β t ) ≥ H b [ α t − q 1 | t ] + , where [ x ] + = max { x, 0 } ; (38 ) follows since H b ( α t ) − H b [ α t − q 1 | t ] + is increasing in α t for α t ≤ q 1 | t ≤ 1 / 2 a nd decrea sing in α t for q 1 | t < α t ≤ 1 / 2 , thus the maximum is for α t = q 1 | t ; (39) follows from Jense n’ s inequality since H b ( · ) is conv ex- ∩ ; (40) foll ows from the input constraint for user 1 (36). The co n verse part follo ws since the outer bound is valid for any U 1 and X 1 , X 2 that sa tisfy the input cons traints. The d irect pa rt is shown by using U 1 = X 1 ⊕ S 1 where X 1 and S 1 are independen t with X 1 ∼ Bernoulli ( q 1 ) , thus U 1 ∼ Bernoulli (1 / 2) . Furthermore, X 2 ∼ Bernoulli ( q 2 ) which is ind epende nt of X 1 , U 1 , S 1 . In this case Y = U 1 ⊕ X 2 , henc e Y ∼ Bernoulli (1 / 2) . Using this ch oice for U 1 , X 1 , X 2 , the achievable common messag e ra te is given by R com = I ( U 1 , X 2 ; Y ) − I ( U 1 , X 2 ; S 1 ) = H ( S 1 | U 1 , X 2 ) − H ( Y | U 1 , X 2 ) + H ( Y ) − H ( S 1 ) = H ( X 1 ) (41) = H b ( q 1 ) , 14 where (41) follo ws since H ( S 1 | U 1 , X 2 ) = H ( S 1 | U 1 ) = H ( X 1 ) , H ( Y | U 1 , X 2 ) = 0 , H ( Y ) = 1 and H ( S 1 ) = 1 . A P P E N D I X I I P RO O F O F T H E C O N V E R S E P A RT O F T H E O R E M 2 The proof of the c on verse part foll ows from Le mma 1, Le mma 2 and Le mma 3, whereas Le mma 5 and L emma 4 are techn ical results which assist in the deriv ation of Le mma 3. Let u s defin e the following func tions: F ( P V 1 ,V ′ 1 , P V 2 ,V ′ 2 ) , h H ( V 1 ) + H ( V 2 ) − H ( V ′ 1 ⊕ V ′ 2 ) − 1 i + , (42) where [ x ] + = max(0 , x ) ; its ( q 1 , q 2 ) -constrained maximization with respe ct to V 1 , V ′ 1 , V 2 , V ′ 2 ∈ Z 2 where ( V 1 , V ′ 1 ) and ( V 2 , V ′ 2 ) are independent, i.e., F max ( q 1 , q 2 ) , max V 1 ,V ′ 1 ,V 2 ,V ′ 2 F ( P V 1 ,V ′ 1 , P V 2 ,V ′ 2 ) (43 ) s.t P ( V i 6 = V ′ i ) ≤ q i , for i = 1 , 2; and the upper con vex en velope of F max ( q 1 , q 2 ) with respect to q 1 , q 2 F max ( q 1 , q 2 ) , u.c.e n F max ( q 1 , q 2 ) o . (44) In the follo wing lemma we give a n outer boun d for the single-letter region (7) of the binary doub ly-dirty MA C in the s pirit of [23 , Le mma 3] and [8, Proposition 1]. Lemma 1. Th e bes t known sing le-letter rate sum (7) of the binary do ubly-dirty MA C (2) with input con straint q 1 and q 2 is up per boun ded by R 1 + R 2 ≤ F max ( q 1 , q 2 ) . (45) Pr o of: An outer bound on the best known single-letter re gion (7) is giv en by R sum B S L ( U 1 , U 2 ) , h I ( U 1 , U 2 ; Y ) − I ( U 1 , U 2 ; S 1 , S 2 ) i + (46) = h H ( S 1 | U 1 ) + H ( S 2 | U 2 ) − H ( Y | U 1 , U 2 ) + H ( Y ) − H ( S 1 ) − H ( S 2 ) i + (47) ≤ h H ( S 1 | U 1 ) + H ( S 2 | U 2 ) − H ( Y | U 1 , U 2 ) − 1 i + (48) = " E U 1 ,U 2 n H ( S 1 | U 1 = u 1 ) + H ( S 2 | U 2 = u 2 ) − H ( Y | U 1 = u 1 , U 2 = u 2 ) − 1 o # + (49) ≤ E U 1 ,U 2 ( h H ( S 1 | U 1 = u 1 ) + H ( S 2 | U 2 = u 2 ) − H ( Y | U 1 = u 1 , U 2 = u 2 ) − 1 i + ) (50) ≤ E U 1 ,U 2 ( F P S 1 ,S 1 ⊕ X 1 | U 1 = u 1 , P S 2 ,S 2 ⊕ X 2 | U 2 = u 2 ) (51) ≤ E U 1 ,U 2 n F max q 1 | u 1 , q 2 | u 2 o (52) ≤ F max E U 1 q 1 | u 1 , E U 2 q 2 | u 2 (53) ≤ F max q 1 , q 2 , (54) 15 where (48) follo ws since H ( S 1 ) = H ( S 2 ) = 1 and H ( Y ) ≤ 1 ; (49) follo ws from the definition of the conditional entropy; (50) follows since [ E x ] + ≤ E { x + } ; (51) follows from the de finition of the func tion F ( P V 1 ,V ′ 1 , P V 2 ,V ′ 2 ) (42), likewise (52) follows from the definition of the function F max ( q 1 , q 2 ) (44), and from the definition q i | u i , P ( S i 6 = X i ⊕ S i | U i = u i ) = P ( X i = 1 | U i = u i ) , f or i = 1 , 2; (53) follo ws from Jens en’ s inequality since F max ( q 1 , q 2 ) is a conc av e func tion; (54) follows from the input constraints wh ere E X i = E U i P ( X i = 1 | U i = u i ) = X u i ∈ U i P ( u i ) P ( X i = 1 | U i = u i ) = X u i ∈ U i P ( u i ) q i | u i ≤ q i , for i = 1 , 2 . (55) The lemma now follows since the upper bound (54) for the rate su m is independe nt o f U 1 and U 2 , hen ce it also bounds the single-letter region R B S L ( q ) . A simplified expression for the function F max ( q 1 , q 2 ) of (43) is s hown in the follo wing lemma. Lemma 2. Th e function F max ( q 1 , q 2 ) (43) is given by F max ( q 1 , q 2 ) = max α 1 ,α 2 ∈ [0 , 1 / 2] h H b ( α 1 ) + H b ( α 2 ) − H b [ α 1 − q 1 ] + ∗ [ α 2 − q 2 ] + − 1 i + , (56) where ∗ is the binary con volution, i.e., x ∗ y , (1 − x ) y + (1 − y ) x . Pr o of: The function F max ( q 1 , q 2 ) is defined in (42) and (43) whe re V 1 , V ′ 1 , V 2 , V ′ 2 are binary random variables. Let u s defin e the following probabilities: α i , P ( V i = 1) δ i , P ( V ′ i = 1 | V i = 0) γ i , P ( V ′ i = 0 | V i = 1) , for i = 1 , 2 . W e thus have P ( V ′ i = 1) = (1 − α i ) δ i + α i (1 − γ i ) , g ( α i , δ i γ i ) P ( V i 6 = V ′ i ) = α i γ i + (1 − α i ) δ i , h ( α i , δ i , γ i ) , for i = 1 , 2 . The maximization (43 ) can be written as F max ( q 1 , q 2 ) = max α 1 ,α 2 h H b ( α 1 ) + H b ( α 2 ) − min γ 1 ,δ 1 ,γ 2 ,δ 2 h ( α i ,δ i ,γ i ) ≤ q i , i =1 , 2 H b g ( α 1 , δ 1 , γ 1 ) ∗ g ( α 2 , δ 2 , γ 2 ) − 1 i + . (57) This maximization has tw o eq uiv a lent solutions ( α o 1 , α o 2 ) and (1 − α o 1 , 1 − α o 2 ) where 0 ≤ α o 1 , α o 2 ≤ 0 . 5 , sinc e any other ( α 1 , α 2 ) can only inc rease the inne r minimi zation in (57) which resu lts in a lower F max ( q 1 , q 2 ) . Therefore, without loss of gene rality we ma y ass ume that 0 ≤ α 1 , α 2 ≤ 0 . 5 . 16 T o p rove the lemma we need to show that for any α i the inn er minimization is achieved b y δ i = 0 , γ i = min { 1 , q i /α i } , i = 1 , 2 . In other words, V ′ i has the smallest poss ible probability for 1 under the con straint that P ( V i 6 = V ′ i ) ≤ q i , implying that the trans ition from V i to V ′ i is a “Z c hannel”. The inner minimization re quires that P ( V ′ i = 1) will be minimi zed restricted to the constraint P ( V i 6 = V ′ i ) ≤ q i , there fore it is equiv alent to the following minimization min γ i ,δ i h ( α i ,δ i γ i ) ≤ q i g ( α i , δ i γ i ) , i = 1 , 2 . For α i ≤ q , the solution is δ i = 0 a nd γ i = 1 s ince in this case g ( α i , γ i , δ i ) = 0 and the constraint is s atisfied. For q ≤ α i ≤ 0 . 5 , in order to minimize g ( α i , γ i , δ i ) , it is required that δ i ∈ [0 , q / (1 − a i )] will be minimal and γ i ∈ [0 , q /α i ] will be maximal s uch that the constraint is sa tisfied. Clearly , the bes t choice is for δ i = 0 a nd γ i = q /α i , in this cas e the constraint is sa tisfies and g ( α i , γ i , δ i ) = α i − q . The next lemma giv es an explicit u pper bound for F max ( q 1 , q 2 ) (43) for the case that q 1 = q 2 . Le t f ( x ) = x − 1 1 + 1 x − 1 2 , (58) and let q c , max x ∈ [0 , 1 / 2] f ( x ) . (59) Since f ( x ) is diff erentiable, we can characterize q c by dif ferentiating f ( x ) with respect to x and equating to zero, thus we get that 4 x 4 − 8 x 3 + 10 x 2 − 6 x + 1 = 0 . This fourth order polynomial has two complex roo ts and two real roots, where one of its rea l roots is a local minimum a nd the other root is a local maximum. Sp ecifically , this local maximum ma ximizes f ( x ) for the interv al x ∈ [0 , 1 / 2] and it a chieves q c ≃ 0 . 1 501 wh ich occ urs at x ≃ 0 . 257 . Lemma 3. F o r q 1 = q 2 = q , we hav e that: F max ( q , q ) = 2 H b ( q ) − 1 , q c ≤ q ≤ 1 / 2 F max ( q , q ) ≤ C ∗ q , 0 < q < q c F max (0 , 0) = 0 , q = 0 , (60) where q c is de fined in (59) , while C ∗ = 2 H b ( q ∗ ) − 1 q ∗ and q ∗ , 1 − 1 / √ 2 ≃ 0 . 3 ar e defined in (17) . Note that in the fi rst case ( q c ≤ q ≤ 1 / 2 ) in (56) is achieved by α 1 = α 2 = q , while in the third case ( q = 0 ) (56) is achieved b y α 1 = α 2 = 1 / 2 as sho wn in Fig. 5. Although, we do not hav e an explicit expres sion for F max ( q , q ) in the range 0 < q < q c , the bound F max ( q , q ) ≤ C ∗ q is su f ficient for the purpo se of proving Theorem 2 becaus e q c ≤ q ∗ . In Fig. 4 a numerical c haracterization of F max ( q , q ) is plotted. 17 0 0.02 0.04 0.06 0.08 0.1 0.12 0 0.05 0.1 0.15 0.2 0.25 0.3 q Rate Sum capacity − H b (q) Best known single letter [2Hb(q)−1] + F max (q,q) H b (q) u.c.e{[2H b (q)−1] + } F max (q,q) Fig. 4. Numerical results of F max ( q , q ) (56) for q ∈ [0 , 0 . 12] (Fig. 2 is t he same plot for q ∈ [0 , 0 . 5] ) . Pr o of: Define F ( α 1 , α 2 , q ) , H b ( α 1 ) + H b ( α 2 ) − H b [ α 1 − q ] + ∗ [ α 2 − q ] + − 1 . From the discus sion above about the cas es of equality in (60), Lemma 3 will follow by showing that F ( α 1 , α 2 , q ) is othe rwise smaller , i.e., F ( α 1 , α 2 , q ) ≤ ( C ∗ q , 0 ≤ q ≤ q c 2 H b ( q ) − 1 , q c ≤ q ≤ 1 / 2 (61) for a ll 0 ≤ α 1 , α 2 ≤ 1 / 2 . It is eas y to see that for α 1 , α 2 ≤ q the function F ( α 1 , α 2 , q ) is monoton ically increasing with α 1 , α 2 , and thus F ( α 1 , α 2 , q ) ≤ F ( q , q , q ) = 2 H b ( q ) − 1 . For α 1 ≤ q and q < α 2 ≤ 1 / 2 , F ( α 1 , α 2 , q ) is increasing with α 1 and de creasing wit h α 2 , an d thu s F ( α 1 , α 2 , q ) ≤ F ( q , q , q ) = 2 H b ( q ) − 1 . Clearly , from symmetry , also for α 2 ≤ q and q ≤ α 1 ≤ 1 / 2 , F ( α 1 , α 2 , q ) ≤ 2 H b ( q ) − 1 . As a consequ ence, we have to show that (61) is satisfied only for q ≤ α 1 , α 2 ≤ 1 / 2 . Likewise, in the sequel we may a ssume without loss of gene rality that q ≤ α 2 ≤ α 1 ≤ 1 / 2 . The bound for the interval q c < q ≤ 1 / 2 : in this case (61) is equiv a lent to the follo wing bound H b ( α 1 − q ) ∗ ( α 2 − q ) − H b ( α 1 ) − H b ( α 2 ) + 2 H b ( q ) ≥ 0 , for q c ≤ q ≤ α 2 ≤ α 1 ≤ 1 / 2 . (62) 18 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 q α Fig. 5. The optimal α 1 = α 2 = α ( q ) which maximizes (56). The LHS is lower bounde d by H b ( α 1 − q ) ∗ ( α 2 − q ) − H b ( α 1 ) − H b ( α 2 ) + 2 H b ( q ) ≥ H b ( α 1 − q ) − H b ( α 1 ) − H b ( α 2 ) + 2 H b ( q ) (63) ≥ H b ( α 1 − q ) − 2 H b ( α 1 ) + 2 H b ( q ) (64) ≥ 0 , (65) where (63) follo ws since H b ( α 1 − q ) ∗ ( α 2 − q ) ≥ H b ( α 1 − q ) ; (64) foll ows since α 2 ≤ α 1 ≤ 1 / 2 ; (65) follows from Lemma 4 below . The bound for the interval 0 ≤ q ≤ q c : in this case (61 ) is equi valent to the following boun d H b ( α 1 − q ) ∗ ( α 2 − q ) ≥ H b ( α 1 ) + H b ( α 2 ) − 1 − C ∗ · q , f or 0 ≤ q ≤ α 2 ≤ α 1 ≤ q c . (66) For fixed α 1 and α 2 , let us denote the RHS and the LHS o f (66) as g l ( q ) , H b ( α 1 − q ) ∗ ( α 2 − q ) g r ( q ) , H b ( α 1 ) + H b ( α 2 ) − 1 − C ∗ · q . The func tion g l ( q ) is c on vex- ∩ in q , s ince it is a compos ition of the func tion H b ( x ) which is non-de creasing con vex- ∩ in the range [0 , 1 / 2] a nd the function [ α 1 − q ] ∗ [ α 2 − q ] wh ich is co n vex- ∩ in q [24]. Since g r ( q ) is linear function in q a nd g l ( q ) is con vex- ∩ function in q , the bound ( 66) is satisfied if the interval e dges ( q = 0 an d 19 q = α 2 ) satisfy this bound. For q = 0 , (66) ho lds since g l ( q = 0) = H b ( α 1 ∗ α 2 ) ≥ max { H b ( α 1 ) , H b ( α 2 ) } ≥ min { H b ( α 1 ) , H b ( α 2 ) } ≥ H b ( α 1 ) + H b ( α 2 ) − 1 = g r ( q = 0) . For q = α 2 where 0 ≤ q ≤ q c , the bound (66) is satisfied s ince g r ( q = α 2 ) = H b ( α 1 ) + H b ( α 2 ) − 1 − C ∗ · α 2 (67) ≤ H b ( α 1 ) − H b ( q ∗ ) + H b (0 . 5 q ∗ ) − 0 . 5 (68) ≤ H b ( α 1 ) − H b ( q c ) (69) ≤ H b ( α 1 ) − H b ( α 2 ) (70) ≤ H b ( α 1 − α 2 ) (71) = g l ( q = α 2 ) , (72) where (68) follows from Lemma 5 since arg max α 2 ∈ [0 , 1 / 2] g r ( α 2 ) = 0 . 5 q ∗ , and sinc e C ∗ = 2 H b ( q ∗ ) − 1 q ∗ ;(69) follo ws since for q ∗ = 1 − 1 / √ 2 and q c defined in (59), we ha ve H b 1 − 1 / √ 2 − H b 0 . 5(1 − 1 / √ 2) +0 . 5 ≃ 0 . 68 ... ≥ H b ( q c ) ; (70) follo ws since q c ≥ α 2 , thus H b ( q c ) ≥ H b ( α 2 ) ; (71) follows since H b ( α 1 ) − H b ( α 1 − α 2 ) is decreing in α 1 , thus H b ( α 1 ) − H b ( α 1 − α 2 ) ≤ H b ( α 2 ) for α 2 ≤ α 1 ≤ 1 / 2 . Therefore, the bo und (66) follo ws which co mpletes the proof. Lemma 4 and Lemma 5 are auxiliary lemmas use d in the proof of Lemma 3. Lemma 4. F o r q c ≤ q ≤ α 1 ≤ 1 / 2 , the following ine quality is satisfied f 1 ( α 1 ) , H b ( α 1 − q ) − 2 H b ( α 1 ) + 2 H b ( q ) ≥ 0 . (73) Pr o of: Since f 1 ( α 1 = q ) = 0 , it is sufficient to show that f 1 ( α 1 ) is non-decrea sing function in α 1 , i.e., d dα 1 f 1 ( α 1 ) ≥ 0 for q c ≤ q ≤ α 1 ≤ 1 / 2 , therefore d dα 1 f 1 ( α 1 ) = log 2 1 α 1 − q − 1 − 2 log 2 1 α 1 − 1 ≥ 0 . (74) Due to monotonicity of the log function (74) is equi valent t o q ≥ α 1 − 1 1 + 1 α 1 − 1 2 = f ( α 1 ) , (75) where f ( · ) was de fined in (58). Sinc e b y the defin ition of q c (59) f ( x ) ≤ q c ∀ x ∈ [0 , 1 / 2] , it follows that f ( α 1 ) ≤ q ∀ α 1 if q c ≤ q , and in particular for q c ≤ q ≤ α 1 , whic h implies (75) as de sired. 20 Lemma 5. Le t f 2 ( x ) = H b ( x ) − 1 − C ∗ · x, (76) where x ∈ [0 , 1 / 2] , and C ∗ = 2 H b ( q ∗ ) − 1 q ∗ where q ∗ = 1 − 1 / √ 2 . The maximum of f 2 ( x ) is achieved by arg max x f 2 ( x ) = 0 . 5 q ∗ = 1 2 (1 − 1 / √ 2) . (77) Pr o of: By differentiati ng f 2 ( x ) with respect to x and co mparing to z ero, we get that 0 = d dx f 2 ( x ) = log 2 1 − x x − C ∗ , (78) thus x o = 1 2 C ∗ +1 maximizes f 2 ( x ) sinc e the s econd deriv ati ve is negativ e, i.e., d 2 x 2 f 2 ( x ) | x = x o < 0 . The lemma is follo wed since x o = 1 2 C ∗ +1 = 0 . 5 q ∗ . W e are now in a position to s ummarize the proof of Th eorem 2. Proof of Theorem 2 - Con verse Part. The rate sum is up per boun ded by R 1 + R 2 ≤ u.c.e n F max ( q , q ) o (79) ≤ u.c.e ( C ∗ · q , 0 ≤ q ≤ q c 2 H b ( q ) − 1 , q c < q ≤ 1 / 2 ) (80) = u.c.e n [2 H b ( q ) − 1] + o , (81) where (79) follows f rom Lemma 1; (80) follows from Lemma 3; and (81) follo ws since (80) is equa l to the upper con vex en velope of [2 H b ( q ) − 1] + . A P P E N D I X I I I A S I M P L I FI E D O U T E R B O U N D F O R T H E S U M C A P A C I T Y I N T H E S T R O N G I N T E R F E R E N C E G AU S S I A N C A S E Lemma 6. The bes t known s ingle-letter s um capa city (7) of the Gaussian dou bly-dirty MA C (24) with p ower constraints P 1 , P 2 , an d str ong interferences ( Q 1 , Q 2 → ∞ ) is upp er bound ed by R 1 + R 2 ≤ u.c.e sup V 1 ,V ′ 1 ,V 2 ,V ′ 2 h h ( V 1 ) + h ( V 2 ) − h V ′ 1 + V ′ 2 + Z + h ( S 1 + S 2 ) − h ( S 1 ) − h ( S 2 ) i + , (82) where u.c.e is the upper con vex en ve lope operation wit h respect to P 1 and P 2 , and [ x ] + = max(0 , x ) . T he supremum is over a ll V 1 , V ′ 1 , V 2 , V ′ 2 such that ( V 1 , V ′ 1 ) is independen t o f ( V 2 , V ′ 2 ) , and E n ( V i − V ′ i ) 2 o ≤ P i , h ( V i ) ≤ h ( S i ) , for i = 1 , 2 . Pr o of: Let u s defin e the following functions (co rresponds to F ( P V 1 ,V ′ 1 , P V 2 ,V ′ 2 ) of (42)) G f V 1 ,V ′ 1 , f V 2 ,V ′ 2 , h h ( V 1 ) + h ( V 2 ) − h V ′ 1 + V ′ 2 + Z + h ( S 1 + S 2 ) − h ( S 1 ) − h ( S 2 ) i + . (83) 21 The se cond function is the following maximization o f (83) with respe ct to V 1 , V ′ 1 , V 2 , V ′ 2 . G max ( P 1 , P 2 ) , sup V 1 ,V ′ 1 ,V 2 ,V ′ 2 G f V 1 ,V ′ 1 , f V 2 ,V ′ 2 (84) s.t E n ( V i − V ′ i ) 2 o ≤ P i , h ( V i ) ≤ h ( S i ) , for i = 1 , 2 . Finally , we defi ne the upper con vex en velope of G max ( P 1 , P 2 ) with respect to P 1 and P 2 : G max ( P 1 , P 2 ) , u.c.e n G max ( P 1 , P 2 ) o . (85) Clearly if we take only the rate sum e quation in (6) we ge t an o uter bound on the bes t k nown sing le-letter region, R sum B S L ( U 1 , U 2 ) , h I ( U 1 , U 2 ; Y ) − I ( U 1 , U 2 ; S 1 , S 2 ) i + (86) = h h ( S 1 | U 1 ) + h ( S 2 | U 2 ) − h ( Y | U 1 , U 2 ) + h ( Y ) − h ( S 1 ) − h ( S 2 ) i + (87) ≤ h h ( S 1 | U 1 ) + h ( S 2 | U 2 ) − h ( Y | U 1 , U 2 ) + h ( S 1 + S 2 ) − h ( S 1 ) − h ( S 2 ) i + + o (1) (88) = " E U 1 ,U 2 n h ( S 1 | U 1 = u 1 ) + h ( S 2 | U 2 = u 2 ) − h ( Y | U 1 = u 1 , U 2 = u 2 ) + h ( S 1 + S 2 ) − h ( S 1 ) − h ( S 2 ) o # + + o (1) (89) ≤ E U 1 ,U 2 ( h h ( S 1 | U 1 = u 1 ) + h ( S 2 | U 2 = u 2 ) − h ( X 1 + S 1 + X 2 + S 2 + Z | U 1 = u 1 , U 2 = u 2 ) + h ( S 1 + S 2 ) − h ( S 1 ) − h ( S 2 ) i + ) + o (1) (90) = E U 1 ,U 2 ( G f S 1 ,S 1 + X 1 | U 1 = u 1 f S 2 ,S 2 + X 2 | U 2 = u 2 ) + o (1) (91) ≤ E U 1 ,U 2 n G max P 1 | u 1 , P 2 | u 2 o + o (1) (92) ≤ G max E U 1 P 1 | u 1 , E U 2 P 2 | u 2 + o (1) (93) ≤ G max P 1 , P 2 + o (1) , (94) where (88 ) follows since h ( Y ) ≤ h ( S 1 + S 2 ) + o (1) where o (1) → 0 as Q 1 , Q 2 → ∞ ; (89) follows from the definition of the cond itional entropy; (90) follo ws sinc e [ E x ] + ≤ E { x + } and since Y = X 1 + S 1 + X 2 + S 2 + Z ; (91) follo ws from the definition of the function G f V 1 ,V ′ 1 , f V 2 ,V ′ 2 (83), like wise (92) follo ws fr om the definition of the fun ction G max ( P 1 , P 2 ) (85), and since h ( S i | U i ) ≤ h ( S i ) and from the definition P i | u i , E n X 2 i | U i = u i o , f or i = 1 , 2; (93) follo ws from Je nsen’ s ine quality s ince G max ( P 1 , P 2 ) is a c oncave function; (94) follows from the input constraints wh ere E X 2 i = E U i E X 2 i | U i = u i = E U i P i | u i ≤ P i , for i = 1 , 2 . (95) The lemma follo ws since the uppe r bound (94) for the rate sum is now ind epende nt o f U 1 and U 2 , hen ce it also bound the single-letter region R B S L ( P 1 , P 2 ) . 22 A C K N O W L E D G M E N T The au thors wish to than k Ashish Kh isti for earlier discussions on the binary case. The authors also would like to than k Uri Erez for he lpful comme nts. R E F E R E N C E S [1] M. Costa, “Writing on dirty paper , ” IEEE T rans. Information T heory , vol. IT -29, pp. 439–441, May 1983. [2] S. Gelfand and M. S. Pinsker , “Coding for channel with rando m parameters, ” Pr oblemy P er ed. Inform. (Problems of Inform. T ran s.) , vol. 9, No. 1, pp. 19–31 , 1980. [3] T . M. Co ver and J. A. Thomas, Elements of Information Theory . New Y ork: Wile y , 1991. [4] A. Somekh-Baruch , S. S hamai, and S. V erdu, “Co operati ve encoding with asymm etric state info rmation at the transmitters, ” in Pr oceeding s 44th Annual Allerton Confer ence on Communication, Contr ol, an d Computing , Univ . of Illinois, Urba na, IL, USA , Sep. 2006. [5] S. K otagiri and J. N. L aneman, “Multiple access channels with state information kno wn at so me encoders, ” IEEE T rans. Information Theory , July 200 6, submitted for publication. [6] S. A. Jafar , “Capacity with causal and non-causal side information - a unified view , ” IEEE T rans. Information Theory , vol. IT -52, pp. 5468–5 475, Dec. 2006. [7] K. Marton, “ A coding t heorem for the discrete memoryless broadcast channel, ” I EEE T ran s. Information T heory , vol. IT –22, pp. 374–37 7, May 1979. [8] U. Erez, S. Shamai, and R. Zamir, “Capacity and lattice st rategies for can celing known interference, ” IEEE T ra ns. Information Theory , vol. IT -51, pp. 3820– 3833, Nov . 200 5. [9] R. Zamir , S. Shamai, and U. Erez, “Nested linear/latt ice codes for structured multiterminal binning, ” IEEE Tr ans. Information Theory , vol. IT -48, pp. 1250– 1276, June 2002. [10] T . Philosof, A . Khisti, U. Erez, and R . Zamir, “Lattice strategies for the dirty multiple access channel, ” in Pr oceeding s of IEEE International Symposium on Informa tion Theory , Nice, F rance , Jun e 2007. [11] J. Korner and K. Marton, “How to enco de the modulo-tw o sum of binary sou rces, ” IEEE T rans. Information Theory , v ol. IT -25, pp. 219–22 1, March 1979. [12] T . M. Co ve r and B. Gopinath, Open Pr oblems in Communica tion and Computation . New Y ork: Springer-V erlag, 1987. [13] I. Csiszar and J. Korn er , Information Theory - Coding Theor ems for Discrete Memoryless Systems . New Y ork: Academic Pr ess, 1981. [14] B. Nazer and M. Gastpar , “Computation ov er multiple-acce ss channels, ” IEEE T rans. Information Theory , vol. IT -53, pp. 3498– 3516, Oct. 2007. [15] D. Krithiv asan and S. S. Pradhan, “Lattices for distributed source coding: Jointly Gaussian sources and reconstruction of a linear function, ” arXiv:cs.IT/0707.3461 V1 . [16] A. Khisti, “Pri v ate communication . ” [17] R. G. Gallager , Information Theory and Reliable Commun ication . Ne w Y ork, N.Y .: W iley , 1968. [18] G. Cohen, I. Honkala, S. Li tsyn, and A. L obstein, Co vering Codes . Amsterdam, The Netherlands: North Holland Publishing, 1997. [19] R. A hlswede and J. K orner , “Source coding with side information and a con verse for the de graded broadcast chann el, ” IEEE T rans. Information Theory , v ol. 21, pp . 629–637, 1975. [20] A. W yner , “On source coding with side information at the decoder , ” IEE E T rans. I nformation Theory , v ol. IT -21, pp. 294 –300, 1975. [21] T . Berger , Multit erminal Sour ce Coding . Ne w Y ork: In G.Longo, editor , the Information Theory Approach to Communications, Springer-V erlag, 1977. [22] L. F . W ei and G. D. Forney , “Multidimensional constellation - part I: Introduction, figures of merit, and generalized cross constellations, ” vol. 7, pp. 877–892, Aug. 1989. 23 [23] A. Cohen and R . Zamir, “Entropy amplification property and the loss for wri ting on dirty paper , ” IE EE Tr ans. Information Theor y , T o appear , April 2008. [24] S. Boyd and L . V andenberg he, Con vex Opti mization . C ambridge: Cambridge Uni versity Press, 2004.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment