Upper Bound on Error Exponent of Regular LDPC Codes Transmitted over the BEC
The error performance of the ensemble of typical LDPC codes transmitted over the binary erasure channel (BEC) is analyzed. In the past, lower bounds on the error exponents were derived. In this paper a probabilistic upper bound on this error exponent…
Authors: Idan Goldenberg, David Burshtein
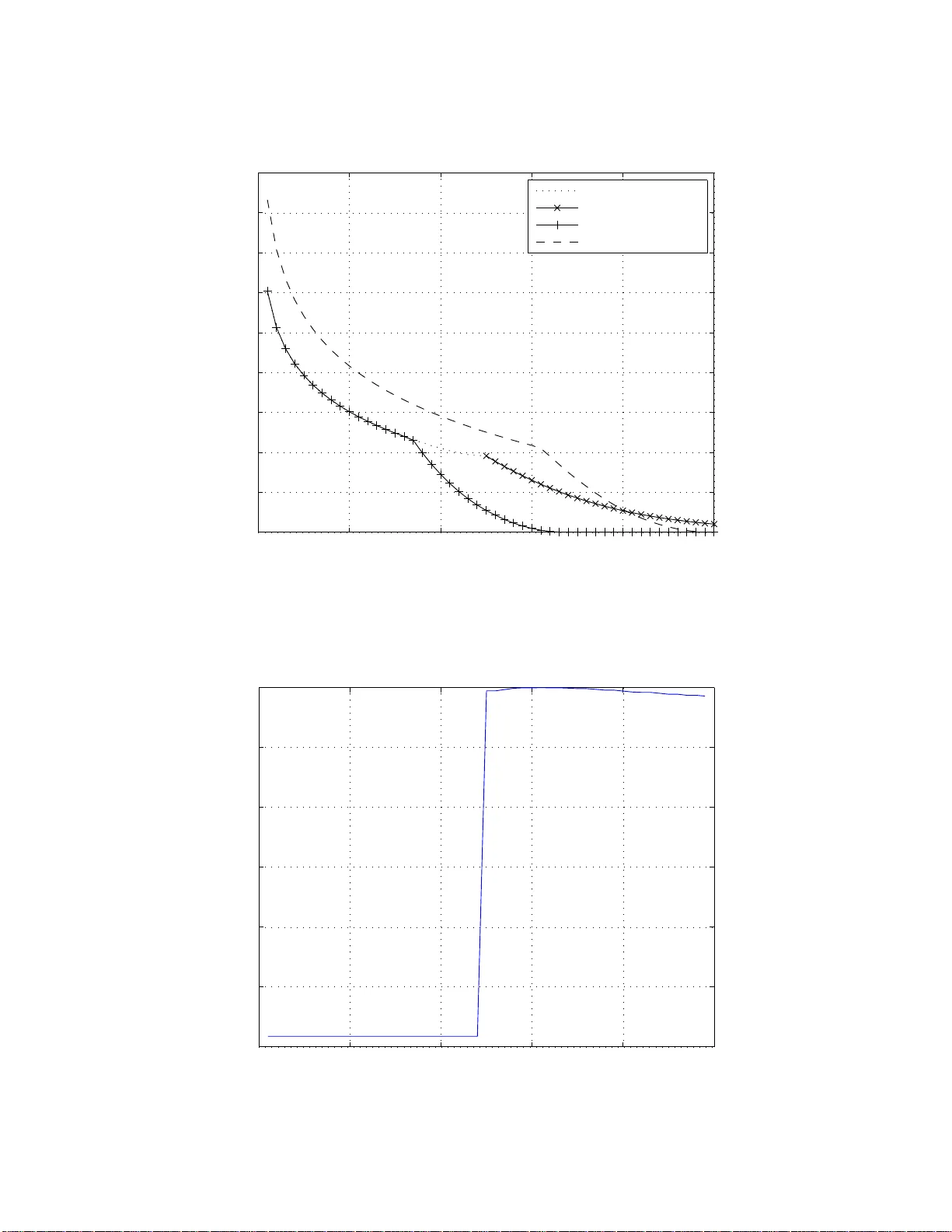
Upper Bound on Err or Expo nent of Regular LDPC Codes T ransmitted ov er the BEC Idan Goldenberg Da vid Burshtein School of Electrical Engineering T el-A viv Univ ersity T el-A viv 69978, Israel E-mail: { idang,bu rstyn } @eng. tau.ac.il Abstract The erro r perfo rmance o f the en semble of ty pical LDPC codes transmitted over th e binar y erasure chan nel (BEC) is analyzed. In the p ast, lower boun ds on the erro r expo nents were derived. In this paper a proba bilistic upper bound on this error exponent is derived. This boun d holds with s ome confide nce le vel. Index T erms: Block codes, error e xponen t, expur gated ensemb le, stopping sets, lo w-density parity-check (LDPC) codes , iterativ e deco ding, binary erasure ch annel (BEC). I . I N T R O D U C T I O N Low-density parity-check (LDPC) codes, discovered by Ga llager [1], h av e bee n widely resea rched over the last decade and a half. Asymptotic results are w idely known for these code s, includ ing results on the performance under max imum-likeli hood (ML) d ecoding [1], [2], [3], [4], [5], average ensemble distance spectra [1], [ 6], [7], [8], [9], stopping set distrib utions [7], [8] , [9], [10], thresholds for iterati ve d ecoding using density ev olution [11], [12], and others. Howev er , accurate finite-length analysis of LDPC co des under iterati ve sum-produc t decoding is currently av ailable only for the binary erasure channel (BEC) [ 13]. This is due to the s implicity of the cha nnel mod el and the graph-bas ed iterative decod er which lend s itself to a more detailed analysis. Analysis of the combinatorial properties of stopping sets and their contributi on to the error pe rformance reveals that the average error performance of the LDPC ense mble is proporti onal to the in verse of a p olynomial in the block length N [7]. This be havior is attrib uted to the existence of “bad” codes which possess small stopping sets, and otherwise w ould decrea se expone ntially with N if these co des were removed from t he ensemble. Fortunately , these “bad ” co des constitute a s mall fraction of the entire ense mble who se size is proportional to the in verse of a polynomial in N . After removing the undesirable c odes, we obtain an e xpurgated ensemble , for which there exists a positiv e error exponent. In [7], lo wer bou nds on this error exponent of typical codes in the regular and irregular LDPC cod e ensembles were deriv ed. In this p aper we obtain an upper bound on this expon ent, and compare it with the above men tioned lo wer bounds. Similar to [5], which conside rs upp er bounds on the error exponent of LDPC c odes under ML decoding, our bound s de pend on some confidence level. The correspondenc e is or ganized a s follows. Section II introduces notation and preliminary material. 1 Section III introduces a lo wer bound on the error (erasure) probability from which an upper bound on the exponen t is deriv ed. S ection IV introduces numerical res ults and comparisons with previous re sults. Section V conc ludes the p aper . I I . P R E L I M I N A R I E S A. Notation W e w ill use the follo wing notation througho ut the paper . • Let { α l } k l =1 be a set of non-negative real numbers, such that P l α l ≤ 1 . The entropy function of { α l } k l =1 is defined as h ( α 1 , . . . , α k ) = − k X l =1 α l log( α l ) − 1 − k X l =1 α l ! log 1 − k X l =1 α l ! where log is the b ase-2 logarithm. W e u se the con ven tion 0 log 0 = 0 . • Gi ven an integer n a nd integers ( n 1 , . . . , n k ) such that P l n l ≤ n , n n 1 , n 2 , . . . , n k , n ! n 1 ! · n 2 ! · . . . · n − P k l =1 n l ! is the multinomial co ef ficient of n over ( n 1 , . . . , n k ) . W e will use the following property of multinomial coefficients log n n 1 , n 2 , . . . , n k = n h n 1 n , . . . , n k n + o (1) (1) which is easily proven using Stirling’ s approximation. • If p ( x ) is a p olynomial, then we will den ote the c oefficient of x i by x i p ( x ) , i.e, p ( x ) = X i x i p ( x ) x i The same notation is extende d for use with multiv ariate polynomials, e.g., p ( x, y , z ) = X i,j,k h x i y j z k i p ( x, y , z ) x i y j z k B. A Seco nd-Or der Inequality for Pr obabilities Dawson and Sankoff [14] obtained a lower boun d on the proba bility of a fin ite union of ev ents. Their result asserts the following. Le t { A i } M i =1 be a finite family of events in a p robability s pace (Ω , P ) . Deno te ˜ S 1 = X i ∈ I Pr( A i ) ˜ S 2 = X i,j ∈ I i>j Pr( A i ∩ A j ) where I = { 1 , . . . , M } . Then Pr [ i ∈ I A i ! ≥ 2 r + 1 ˜ S 1 − 2 r ( r + 1) ˜ S 2 (2) 2 for any r ∈ { 1 , . . . , M − 1 } . Follo wing the deriv ation in [14], we deri ve a resu lt which ge neralizes (2). For a p robability event A , denote by 1 { A } to be the indicator (random variable) over A , i.e, for ω ∈ Ω , 1 { A } ( ω ) = 1 ω ∈ A 0 ω / ∈ A Our result ass erts tha t for all ω ∈ Ω , 1 {∪ M i =1 A i } ≥ 2 r + 1 S 1 − 2 r ( r + 1) S 2 (3) where S 1 = X i ∈ I 1 { A i } S 2 = X i,j ∈ I i>j 1 { A i } 1 { A j } By taking the expectation over bo th sides of (3), we ge t (2) as a spec ial case. W e prove (3) i n Ap pendix I. C. LDPC Code Ens embles W e con sider the stand ard bipa rtite gra ph-based ( c, d ) -regular LDPC co de e nsemble with bloc k length N and de sign rate R . In this en semble a randomly chose n permutation is used to match the cN left sockets to the d (1 − R ) N right sockets. The actual rate of the code is a t least R , 1 − c/d . I I I . U P P E R B O U N D O N E R R O R E X P O N E N T F O R T H E B E C Recall tha t a stopping se t S of a bipartite graph representation of an LDPC code is a set of variable nodes, such tha t each ch eck node neighbo r o f S is connec ted to S by at leas t two edges. As explaine d in [13], iterati ve deco ding of LDPC co des succe eds if and only if the set of variable nodes which correspond to erasures does not conta in a subset wh ich is a stopping set. The expurgated ( c, d ) -regular L DPC ensemb le C γ is derived from the ( c, d ) -re gular ensemb le C 0 by removing all the co des containing s topping s ets o f size γ N or less . It was shown in [7] tha t for ensembles with c > 2 , if γ is se lected be lo w a ce rtain thres hold α 0 , then almost a ll co des in C 0 belong to C γ . In other words, if C is drawn at ran dom from C 0 Pr ( C ∈ C γ ) = 1 − o (1) ∀ γ < α 0 (4) The numbe r α 0 N may therefore be cons idered to be the typica l minimum s topping set size of C 0 . Since the b ehavior o f C 0 is dominated b y a small fraction of “b ad” co des, we will be interested in the performance of codes drawn at random from C γ . Let C be suc h a c ode. 3 Consider a BEC with e rasure probability δ ; the probability of uns uccess ful deco ding of any c odeword from C , P C e is giv en by P C e = N X l = γ N δ l (1 − δ ) N − l X m 1 n ∪ 2 l − 1 i =1 A m i o (5) where the index m runs over all sets of variable nod es c ontaining e xactly l n odes; f or a p articular s et S m of l variable node s, { A m i } is the event that the i ’ th (non-empty) subset of S m (where i = 1 , . . . , 2 l − 1 ) is a s topping s et. Note that every set of N (1 − R ) + 1 variable nodes contains the sup port o f a non zero codeword 1 . Hence (since every codeword is a s topping set), every set of N (1 − R ) + 1 variable nod es contains a stopping set. Therefore, the indicator ap pearing in the RHS o f (5) may be replaced by 1 for l > N (1 − R ) , which yields P C e = N (1 − R ) X l = γ N δ l (1 − δ ) N − l X m 1 n ∪ 2 l − 1 i =1 A m i o + N X l = N ( 1 − R )+1 N l δ l (1 − δ ) N − l (6) Next, we us e (3) to lower -bound the indicator func tion in (6), giving 1 n ∪ 2 l − 1 i =1 A m i o ≥ 2 r l + 1 S 1 − 2 r l ( r l + 1) S 2 (7) where r is allo wed to depe nd on the size of the set, and S 1 = 2 l − 1 X i =1 1 { A m i } S 2 = 2 l − 1 X i =1 i − 1 X k =1 1 { A m i } 1 { A m k } (8) Consider a s topping set S c ontaining k variable nodes , whe re k ≤ l . The numbe r of sets of vari able nodes o f s ize l containing S as a subse t is N − k l − k . Hence, ag ain letting m run over all subsets o f s ize l , we have X m 2 l − 1 X i =1 1 { A m i } = l X k =1 N − k l − k S C k = l X k = γ N N − k l − k S C k (9) where S C k is the number of stopping sets w ith k vari able nod es in C ; note that since C belongs to the expurgated ensemble, we hav e S C k = 0 for k < γ N . In a similar fashion we obtain X m 2 l − 1 X i =1 i − 1 X j =1 1 { A m i } 1 { A m j } = X γ N ≤ j ≤ i ≤ l 0 ≤ k ≤ j + min( i − j − 1 , 0) i + j − k ≤ l N − ( i + j − k ) l − ( i + j − k ) S C i,j,k (10) where S C i,j,k is the n umber of pa irs of s topping s ets, ( S 1 , S 2 ) satisfying |S 1 | = i , |S 2 | = j , and |S 1 ∩ S 2 | = k . Re calling that both S 1 and S 2 must be subsets of a particular se t of s ize l , their union must also be a subset, a nd therefore |S 1 ∪ S 2 | = i + j − k ≤ l . Furthermore, the application of ( 3) requires summing over pairs o f distinct ev ents. Conse quently , we cannot have S 1 = S 2 , i.e., when i = j , we must hav e k < j ; 1 This is tantamount to saying that N (1 − R ) + 1 columns i n the parity chec k matrix, regardless of ho w they are chosen, are linearly dependent; t his follows since the matrix has N (1 − R ) ro ws. 4 this re quirement is subsume d by imposing 0 ≤ k ≤ j + min( i − j − 1 , 0) in (10). Plugging (7) -(10) into (6), we get P C e ≥ N (1 − R ) X l = γ N δ l (1 − δ ) N − l 2 r l + 1 l X i ′ = γ N N − i ′ l − i ′ S C i ′ − 2 r l ( r l + 1) X γ N ≤ j ≤ i ≤ l 0 ≤ k ≤ j + min( i − j − 1 , 0) i + j − k ≤ l N − ( i + j − k ) l − ( i + j − k ) S C i,j,k + N X l = N ( 1 − R )+1 N l δ l (1 − δ ) N − l ≥ N (1 − R ) X l = γ N δ N ǫ (1 − δ ) N (1 − ǫ ) 2 r l + 1 max γ ≤ η ≤ ǫ N (1 − η ) N ( ǫ − η ) S C ηN − 2 r l ( r l + 1) ( ǫN ) 3 max γ ≤ η 2 ≤ η 1 ≤ ǫ 0 ≤ β ≤ η 2 η 1 + η 2 − β ≤ ǫ N (1 − ( η 1 + η 2 − β )) N ( ǫ − ( η 1 + η 2 − β )) S C η 1 N ,η 2 N ,β N + max 1 − R ≤ ǫ ≤ 1 N N ǫ δ N ǫ (1 − δ ) N (1 − ǫ ) ( a ) ≥ max γ ≤ ǫ ≤ 1 − R n δ N ǫ (1 − δ ) N (1 − ǫ ) ˆ P C e ( ǫ, N ) o + max 1 − R ≤ ǫ ≤ 1 N N ǫ δ N ǫ (1 − δ ) N (1 − ǫ ) where ˆ P C e ( ǫ, N ) , 2 r ǫN + 1 max γ ≤ η ≤ ǫ N (1 − η ) N ( ǫ − η ) S C ηN − 2 r ǫN ( r ǫN + 1) ( ǫN ) 3 max γ ≤ η 2 ≤ η 1 ≤ ǫ 0 ≤ β ≤ η 2 η 1 + η 2 − β ≤ ǫ N (1 − ( η 1 + η 2 − β )) N ( ǫ − ( η 1 + η 2 − β )) S C η 1 N ,η 2 N ,β N (11) and ǫ , l N , η , i ′ N , η 1 , i N , η 2 , j N , and β , k N ; a sufficient condition in order for (a) to hold is that ˆ P C e ( ǫ, N ) b e non-negative for γ ≤ ǫ ≤ 1 − R . La ter we will c hoose the value of r ǫN so that this condition is fulfilled. By expressing the bound i n exponential form, we get the following uppe r bo und o n the error exponen t − 1 N log P C e ≤ − max γ ≤ ǫ ≤ 1 ǫ log δ + (1 − ǫ ) log (1 − δ ) + 1 N log P C e ( ǫ, N ) γ ≤ ǫ ≤ 1 − R h ( ǫ ) 1 − R ≤ ǫ ≤ 1 + o (1) where we rely upon (1), and P C e ( ǫ, N ) , 2 r ǫN + 1 2 − N E ′ 1 − 2 r ǫN ( r ǫN + 1) 2 − N E ′ 2 (12) E ′ 1 = − max γ ≤ η ≤ ǫ (1 − η ) h ǫ − η 1 − η + 1 N log S C ηN (13) E ′ 2 = − max γ ≤ η 2 ≤ η 1 ≤ ǫ 0 ≤ β ≤ η 2 η 1 + η 2 − β ≤ ǫ (1 − ( η 1 + η 2 − β )) h ǫ − ( η 1 + η 2 − β ) 1 − ( η 1 + η 2 − β ) + 1 N log S C η 1 N ,η 2 N ,β N (14) 5 Let C ′ be a randomly se lected code from C 0 , and let S i and S i,j,k be the averages, over C 0 , of S C ′ i and S C ′ i,j,k , respe cti vely . W e evaluate these average quantities and the n relate them to S C i and S C i,j,k 2 . In order to ev aluate thes e qu antities, we introduce the followi ng nota tion. ψ i ( x ; d ) = d X l = i d l x l = (1 + x ) d − i − 1 X l =0 d l x l (15) Ψ i + ,k + ,j + i − ,k − ,j − ( x, y , z , d ) = X i − ≤ i ≤ i + j − ≤ j ≤ j + k − ≤ k ≤ k + i + j + k ≤ d d i, j, k x i y j z k (16) The average quantities satisfy S i = N i P s, 1 ( i ) (17) S i,j,k = N i − k , k , j − k P s, 2 ( i, j, k ) (18) where P s, 1 ( i ) is the p robability that a specific set o f v ariable nodes, S , is a stop ping set, and P s, 2 ( i, j, k ) is t he probability that a specific p air o f sets - S 1 containing i variable nod es a nd S 2 containing j v ariable nodes, with |S 1 ∩ S 2 | = k , are bo th stopping sets. T o ev aluate P s, 1 ( i ) , we need to fix a se t S of i v ariable nod es and count the number of pos sibilities of c onnecting the ir ic variable sockets to ic c heck so ckets such that ea ch of the L che ck node s is either (a) no t c onnected to any of the ic variable s ockets, or (b) connec ted by at least two ch eck so ckets. This combinatorial problem ca n be solved by means of the enumeration func tion in (15). The total number of ways to conne ct ic variable so ckets to N c c heck sockets is N c ic , therefore P s, 1 ( i ) = x ic (1 + ψ 2 ( x, d )) L N c ic W e procee d with the ev aluation of P s, 2 ( i, j, k ) . Giv en two sets S 1 and S 2 of variable node s with |S 1 | = i , |S 2 | = j , |S 1 ∩ S 2 | = k , we need to count the numbe r o f p ossibilities of con necting ( i − k ) c sockets from S 1 / S 2 , kc sockets from S 1 ∩ S 2 and ( j − k ) c s ockets from S 2 / S 1 to ( i + j − k ) c check sockets, such that both S 1 and S 2 are stopping s ets. This situation is dep icted in Figure 1. Con sider a check nod e α in the graph. From the de finition of a stop ping set, it can be seen that in order to hav e both S 1 and S 2 as stopping sets, α ha s to fall into o ne of the following dis joint categories: • α is no t c onnected at all to node s in S 1 ∪ S 2 . • α is c onnected by at least two edges to nodes in S 1 / S 2 and is not conne cted to nod es in S 2 . • α is c onnected by at least two edges to nodes in S 2 / S 1 and is not conne cted to nod es in S 1 . • α is connec ted by at least t wo e dges to nodes in S 1 / S 2 and by at leas t two edge s to nodes in S 2 / S 1 , but is no t connec ted to any n ode in S 1 ∩ S 2 . 2 recall that in our conte xt C is selected uniformly from C γ 6 d 2 1 α S 1 i nodes k nodes S 2 j nodes S 1 ∩ S 2 Fig. 1. T wo intersecting stopping sets and a check node α • α is con nected by e xactly one ed ge to a no de in S 1 ∩ S 2 , and by at least o ne e dge t o nodes in S 1 / S 2 and in S 2 / S 1 . • α is c onnected by at least two edges to nodes in S 1 ∩ S 2 . This c ombinatorial problem c an be solved us ing the e numeration func tion g i ven in (16). The total numb er of possibilities of connecting ( i − k ) c s ockets from S 1 / S 2 , k c sockets from S 1 ∩ S 2 and ( j − k ) c so ckets from S 2 / S 1 to N c chec k so ckets is N c ( i − k ) c, k c, ( j − k ) c . Therefore, P s, 2 ( i, j, k ) = h x ( i − k ) c y k c z ( j − k ) c i B ( x, y , z , d ) L · N c ( i − k ) c, k c, ( j − k ) c − 1 B ( x, y , z , d ) , 1 + Ψ d, 0 , 0 2 , 0 , 0 ( x, y , z , d ) + Ψ 0 , 0 ,d 0 , 0 , 2 ( x, y , z , d ) + Ψ d − 2 , 0 ,d − 2 2 , 0 , 2 ( x, y , z , d ) +Ψ d − 1 , 1 ,d − 1 1 , 1 , 1 ( x, y , z , d ) + Ψ d,d,d 0 , 2 , 0 ( x, y , z , d ) (19) W e turn o ur a ttention bac k to the relation between the a verage quan tities S i and S i,j,k and t hose o f the randomly selec ted c ode, S C i and S C i,j,k . By ass uming that C is selec ted a t random with uniform probability 7 from C 0 and using cond itioning, we h av e Pr S C i,j,k > N S i,j,k | C ∈ C γ = Pr S C i,j,k > N S i,j,k − Pr C / ∈ C γ , S C i,j,k > N S i,j,k Pr ( C ∈ C γ ) (a) ≤ Pr S C i,j,k > N S i,j,k 1 − o (1) (b) ≤ 1 N (1 − o (1)) (20) where (a) is obtained using (4) and by o mitting the negati ve term, an d (b) is due to Markov’ s inequality . W e conclud e from (20) tha t w .p. (with p robability) 1 − o (1) , for C ch osen randomly with u niform probability from C γ , 1 N log S C i,j,k ≤ 1 N log S i,j,k + o (1) (21) By using conditioning once more we obtain Pr 1 − ǫ ≤ S C i S i ≤ 1 + ǫ C ∈ C γ ≥ Pr 1 − ǫ ≤ S C i S i ≤ 1 + ǫ − Pr ( C / ∈ C γ ) Pr ( C ∈ C γ ) (a) ≥ Pr 1 − ǫ ≤ S C i S i ≤ 1 + ǫ + o (1) (22) where (a) is obtained by us ing (4) a nd replacing the de nominator by 1 . Rathi [8] has o btained a con centration result on the s topping set distribution. His result implies the follo wing. For any ǫ > 0 , Pr 1 − ǫ ≤ S C ηN S ηN ≤ 1 + ǫ ! ≥ 1 − β η,d, c ǫ 2 + o (1) (23) where β η,d, c is a constant gi ven in Eq. (37) in App endix II, independent o f N , which s atisfies β η,d, c → 0 when d → ∞ and c d is kept constant. By setting ǫ → 1 in (23) and using (22 ), we conclude tha t w .p. at least 1 − β η,d,c ǫ 2 + o (1) , for C chose n rand omly w ith uniform probab ility from C γ , 1 N log S C ηN ≥ 1 N log S ηN + o (1) (24) Define E 1 , − max γ ≤ η ≤ ǫ (1 − η ) h ǫ − η 1 − η + 1 N log S ηN (25) E 2 , − max γ ≤ η 2 ≤ η 1 ≤ ǫ 0 ≤ β ≤ η 2 η 1 + η 2 − β ≤ ǫ (1 − ( η 1 + η 2 − β )) h ǫ − ( η 1 + η 2 − β ) 1 − ( η 1 + η 2 − β ) + 1 N log S η 1 N ,η 2 N ,β N (26) then by comb ining (12), (13), (14), (21) a nd (24), we obtain that, w .p. at leas t 1 − β η,d,c ǫ 2 + o (1) , P C e ( ǫ, N ) ≥ 2 r ǫN + 1 2 − N ( E 1 + o (1)) − 2 r ǫN ( r ǫN + 1) 2 − N ( E 2 + o (1)) (27) As we are interested in the asy mptotic behavior of E 1 and E 2 (and thu s the exponential gro wth rate of the stopping set distributions), we use [7, Theo rem 2], which as serts the follo wing 3 : 3 Here we give the m ultiv ariat e version of the t heorem with 3 v ariables; the theorem generalizes to any n umber of variables. 8 Let p ( x, y , z ) be a t ri variate p olynomial with non-negati ve coef ficients. Let α 1 > 0 , α 2 > 0 and α 3 > 0 be some rational numbe rs and let n i be the series of all indice s such that [ x α 1 n i y α 2 n i z α 3 n i ] p ( x, y , z ) n i 6 = 0 Then lim i →∞ 1 n i log [ x α 1 n i y α 2 n i z α 3 n i ] p ( x, y , z ) n i = inf x> 0 ,y > 0 ,z > 0 log p ( x, y , z ) x α 1 y α 2 x α 3 (28) Using (17), (18), (25), (26) an d (28) we obtain E 1 = − h ( ǫ ) − max γ ≤ η ≤ ǫ ǫh η ǫ − ch ( η ) + c d inf x> 0 log 1 + ψ 2 ( x, d ) x ηd (29) E 2 = − h ( ǫ ) − max γ ≤ η 1 ≤ η 2 ≤ ǫ 0 ≤ β ≤ η 2 0 ≤ η 1 + η 2 − β ≤ ǫ ǫh η 1 − β ǫ , η 2 − β ǫ , β ǫ − ch ( η 1 − β , η 2 − β , β ) + c d inf x,y ,z > 0 log B ( x, y , z , d ) x ( η 1 − β ) d y β d z ( η 2 − β ) d If E 2 ≥ E 1 , we c hoose r ǫN = 1 in (27). In this cas e, taking the union bound over all possible stopping se ts yields an exponentially tight bound. In the case tha t E 2 < E 1 , we use (27) with r ǫN = ⌊ 2 N ( E 1 − E 2 + α ) ⌋ , wh ere α > 0 can be made arbitrarily small (hence, the non-negativit y of ˆ P C e ( ǫ, N ) in (11) is establishe d). Thus , we obtain the follo w ing upper bound on the error expon ent − 1 N log P C e < − max γ ≤ ǫ ≤ 1 ǫ log δ + (1 − ǫ ) log(1 − δ ) − E γ ≤ ǫ ≤ 1 − R − h ( ǫ ) 1 − R ≤ ǫ ≤ 1 + o (1) E , E 1 E 2 ≥ E 1 2 E 1 − E 2 E 2 < E 1 (30) This bound holds w .p. at leas t 1 − β η 0 ,d,c ǫ 2 + o (1) , where η 0 is the maximizing value of η in (29). I V . N U M E R I C A L R E S U L T S In this sec tion, we compare our uppe r bound on t he error expo nent of the BEC with pre v iously-known lower bounds . These bou nds were d eri ved in [7, Th eorems 8,12]; one of t hese bou nds app lies for iterative decoding , while the other a pplies for ML decoding. In Figure 2 we exemplify our bo und for the regular (4 , 8) LDPC ensemb le. Rec alling tha t the bo und applies wit h a certain probability , we ha ve marked the plot where the bound has a con fidence level a bove 99% . W e n ote that the entire plot of the upp er b ound is true w .p. at least 70% . Figure 3 shows the confiden ce level bou nd from (23) which correspon ds to the up per bound plot in Figure 2. Looking back at Figure 2 for low values of δ , the uppe r bound on the exponent coincides with the two lower boun ds from [7, Theorems 6,8 ]. That is, o ur results indica te that i n the region δ ∈ [0 , 0 . 17] , the bo und on the error exp onent of the expurgated en semble in [7, Theo rem 6], wh ich coincide s with the bound in [7, Theorem 8] in this region, is tight. Similarly , for the (3, 6) ense mble and δ ∈ [0 , 0 . 26] , 9 0 0.1 0.2 0.3 0.4 0.5 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 Probability of Channel Erasure Error Exponents UB on Exponent UB with Prob.>0.99 LB iterative LB ML Fig. 2. Error exponents for the regular (4,8) LDP C ensemble. 0 0.1 0.2 0.3 0.4 0.5 0.7 0.75 0.8 0.85 0.9 0.95 1 Probability of Channel Erasure Confidence Level Fig. 3. Confidence level bound for the regu lar (4,8) LDPC ensemble. 10 the lo wer bo und o n the error exponent of the expu r gated ensemb le in [7, The orems 6] (which coincides with the lower b ound in [7, Theorem 8] in this region) is tight 4 . Focussing on highe r values of δ where the confid ence le vel is highe r , c omparison of our upp er boun d with the lo wer bound on the ML deco ding expo nent reveals that the re is a gap in performance between iterati ve and ML decoders, at least for most code s in the en semble. V . C O N C L U S I O N A N D F U R T H E R R E S E A R C H W e have de ri ved an upper bound on the error exponent o f LDPC cod es transmitted over the BEC. The upper bou nd relies on Dawso n’ s ine quality and holds with a c ertain confide nce level. It was de monstrated that f or some v alues of the channel erasure probability the re i s a ga p betwe en ou r u pper bo und a nd s ome previously reported lower bo unds. Continued resea rch cou ld focus on extend ing our res ults to irr egular ense mbles of LDPC code s. Th is requires to extend the results of [8], regarding co ncentration o f stopping sets, to ir regular codes. Another possible avenue is to try an d bridge the gap between the lo wer and up per bo unds; with the asymptotic decoding threshold for the (4 , 8) ensemble at a bout 0 . 38 , there is still room for improvement in the bounds . A C K N O W L E D G M E N T The authors wish to than k Iga l Sas on for pointing out the improvement that was implemented in Equation (6), and for stimulating discu ssions. 4 W e note that these lower bounds, as depicted i n [7, F igure 3] do not coincide with each other in t his δ region due to a numerical inaccuracy . 11 A P P E N D I C E S A P P E N D I X I P R O O F O F (3) Gi ven the events A 1 , . . . , A M define the se t B s , s = 1 , . . . , M as the se t of points in S M i =1 A i contained in exactly s sets. W e thus have M X k =1 k 1 { B k } = M X k =1 1 { A k } = S 1 (31) M X k =2 k 2 1 { B k } = M X k =1 k − 1 X i =1 1 { A k } 1 { A i } = S 2 (32) W e will find a lower bound for V = 1 { S M i =1 A i } = M X k =1 1 { B k } (33) First, fix the value o f r . Solving (31) and (32) to isolate 1 { B r } and 1 { B r +1 } we get 1 { B r } = S 1 − 2 S 2 r − 1 { B 1 } − M X k =2 k 6 = r 1 { B k } k ( r + 1 − k ) r (34) 1 { B r +1 } = 1 { B 1 } r − 1 r + 1 + 2 S 2 r + 1 − S 1 r − 1 r + 1 − M X k =2 k 6 = r +1 1 { B k } k ( k − r ) r + 1 (35) Substituting (34) and (35) into (33) we g et V − 2 S 1 r + 1 + 2 S 2 r ( r + 1) = r − 1 r + 1 1 { B 1 } + M X k =2 1 { B k } ( r − k )( r − k + 1) r ( r + 1) (36) Note that the RHS of (36) c ontains only n on-negati ve eleme nts. Thus, if the RHS of (36) is replaced b y zero, we obtain the inequa lity V ≥ 2 r + 1 S 1 − 2 r ( r + 1) S 2 which is the des ired result. A P P E N D I X I I C O N FI D E N C E I N T E RV A L O F S T O P P I N G S E T D I S T R I B U T I O N Rathi [8] ha s obtained a result asserting the c oncentration of the s topping set distribution. T o state his result, we introduce some notation. • Denote β ( x ) , 1 + ψ 2 ( x, d ) , wh ere ψ is defined in (15). • The equation x (1 + x ) d − 1 − 1 β ( x ) = η has a sing le rea l positiv e so lution; denote this solution by x η . 12 • Define a β ( x ) , x β ( x ) d β ( x ) d x and b β ( x ) , x d a β ( x ) d x • Let x = ( x 1 , x 2 , x 3 ) . For a multi variate func tion f ( x ) , de note a f ( x ) to be a 3-element vector whose elements a re a f ( i ) = x i f ∂ f ∂ x i . Le t C f ( x ) denote a 3 × 3 matrix whose eleme nts are giv en by C f ( i,j ) = x j ∂ a f ( i ) ∂ x j = C f ( j, i ) . The conce ntration result is as follo ws. The number of s topping s ets S C ηN in a randomly s elected code C satisfies Pr 1 − ǫ ≤ S C ηN S ηN ≤ 1 + ǫ ! ≥ 1 − β η,d, c ǫ 2 + o (1) (37) where β η,d, c = b β ( x η ) √ dη (1 − η ) σ c ( η 2 ) q | C ˜ B ( x η , x 2 η , x η ) | ( η 2 (1 − η ) 2 − ( c − 1) σ 2 c ( η 2 )) − 1 σ 2 c ( η 2 ) = 1 cd | ( − 1 , 1 , − 1) · C ˜ B ( x η , x 2 η , x η ) − 1 · ( − 1 , 1 , − 1) T | ˜ B ( x ) , B ( x 1 , x 2 , x 3 , d ) and B ( · , · , · , d ) is d efined in (19). R E F E R E N C E S [1] R. G. Gallager , Low-Density P arity-Check Codes , Cambridge, MA, USA, MIT Press, 1963. [2] D. J.C. MacKay , “Good error-correcting cod es based on very sparse matrice s”, IEEE T ransactions o n Information Theory , vol. 45, no. 2, pp. 399–43 1, March 199 9. [3] A. Montanari, “The glassy phase of Gallager codes”, Eur o p. Phys. J .B., , vol. 23, pp. 121–136, 2001. [4] D. Burshtein and G. Miller , “Bound s on the max imum-likelihoo d decod ing error pro bability of lo w-density parity-ch eck codes”, IEEE T ransac tions on Info rmation Theory , vol. 4 7, no . 7, pp. 2696 –2710 , November 2001. [5] O. Barak an d D. Burshtein, “Lower Bound s o n the Spectru m and Erro r Rate of LDPC E nsembles”, IEEE T ransactions on Information Theory , V ol. 53, no. 11, pp. 422 5–423 6, November 20 07. [6] S. Litsyn, V . Shevele v , “On Ensembles o f Low-Density Parity-Check Codes: Asym ptotic Distance Distribu- tions”, IEEE T ransactions on Information Theory , vol. 48, no. 4, pp.887– 908, April 20 02. [7] D. Burshtein and G . Miller, “ Asymp totic en umeration m ethods fo r ana lyzing LDPC c odes”, IEEE T ransactio ns on Information Theory , vol. 50, no. 6, pp. 1115–1 131, June 20 04. [8] V . Rathi, “O n the Asympto tic W eight and Stopping Set Distribution of Regular LDPC En sembles”, I EEE T ransactions on Information Theory , vol. 52, no. 9, pp. 4212–42 18, September 2006 . [9] C. Di, T . Richardso n, and R. Urb anke, “W eigh t Distribution of Low-Density Parity-Chec k Codes”, IEEE T ransactions on Information Theory , vol. 52, no. 11, pp. 4839–485 5, November 2006. [10] A. Orlitsky , K. V iswanathan, J. Z hang, “Stopping Set Distribution o f LDPC Code Ensembles”, IEEE T ransactions on Information Theory , vol. 51, no. 3, pp.929–9 53, March 200 5. [11] M. Lu by , M. Mitzenmach er , A. Sho krollahi a nd D. Spielm an, “Imp roved lo w-density p arity-check cod es using irregular graphs”, IEEE T ransactions on Information Theory , v ol. 47, no. 2, pp. 585-5 98, February 2001. [12] T . Richardson and R. Urbanke, “T he Capacity of Low-Density Parity-Check Codes Under Message-Passing Decoding ”, IEEE T ransactio ns on Information Theory , vol. 4 7, no. 2, pp. 599–6 18, February 2 001. [13] C. Di, D. Proietti, T . Richa rdson, E. T elatar, an d R. Urbanke, “Finite L ength An alysis of Low-Density Parity- Check Code s on the Binary Erasur e Ch annel”, IEEE T ransactio ns o n Information Theory , vol. 48 , no. 6, pp.15 70–15 79, Ju ne 2002 . [14] D.A. Dawson an d D. San koff, “ An in equality for probab ilities”, P r oc. Amer . Math. Soc. , vol. 18, pp. 50 4–507 , 1967.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment