Local Information Based Algorithms for Packet Transport in Complex Networks
We introduce four algorithms for packet transport in complex networks. These algorithms use deterministic rules which depend, in different ways, on the degree of the node, the number of packets posted down each edge, the mean delivery time of packets…
Authors: ** Bernard Kujawski, G.J. Rodgers, Bosiljka Tadić **
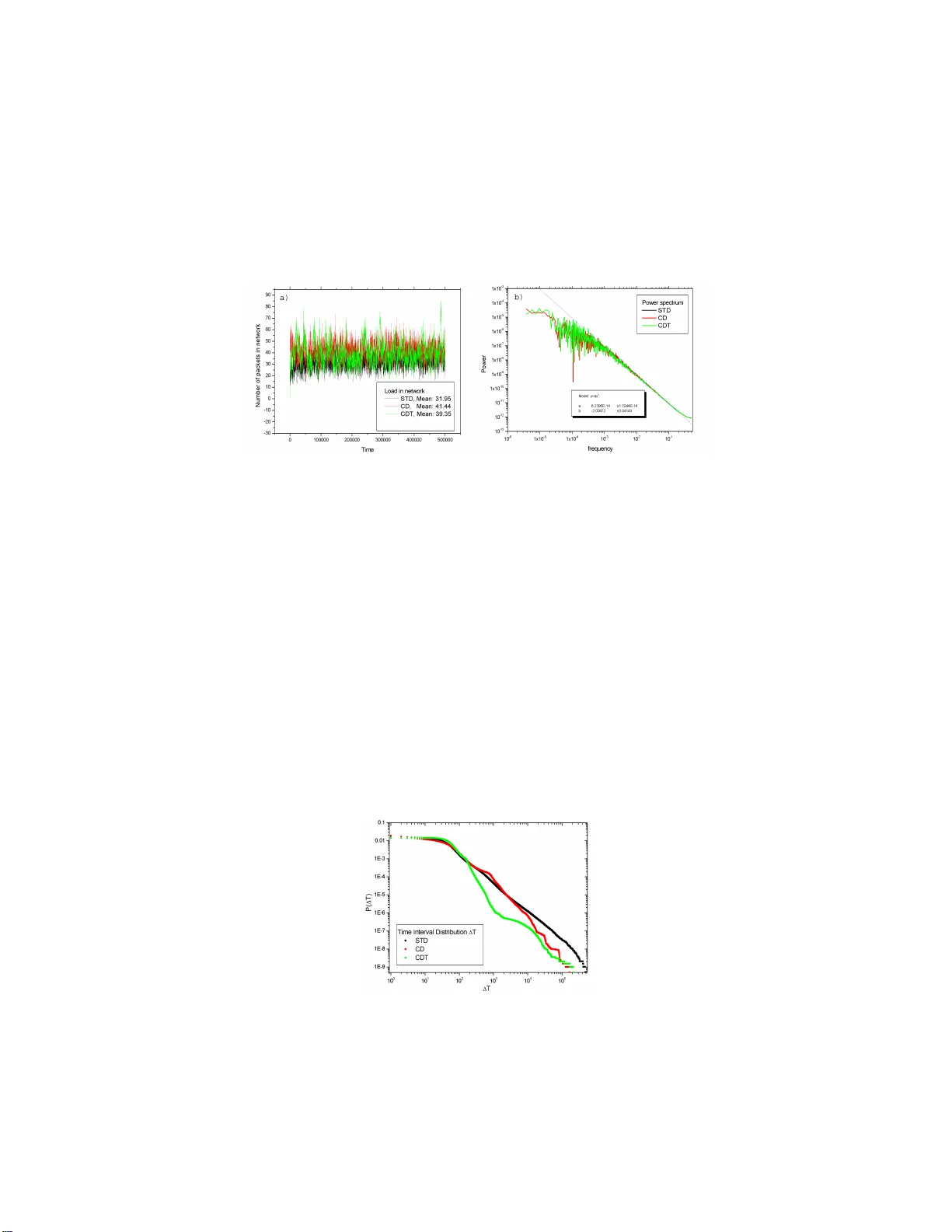
Lo cal Information Based Algorithms for P ac k et T ransp ort in Complex Net w orks Bernard Kujawski 1 , G.J. Ro dgers 1 , and Bosiljk a T adi´ c 2 1 Department of Ma thematical Sciences; Brunel Universit y , Uxb ri dge; Middlesex U B8 3PH; UK { bernard. kujawski,g.j.rod gers } @brunel.ac.uk 2 Department for Theo retical Ph ysics; Jo ˇ zef Stefan Institute, P .O. Bo x 3000; SI-1001 Ljub lj ana; Slo venia bosiljka.t adic@ijs.si Abstract. W e introduce four al gorithms for pac ket tra nsp ort in com- plex netw orks. These algorithms use deterministic rules whic h dep end, in different wa y s, on th e degree of the n ode, the num b er of pac kets p osted dow n eac h e dge, the mean delivery time of pac kets sen t down eac h edge to eac h destination and th e time since an edge last transmitted a pack et. On scale-free netw orks all our algorithms are considerably more efficient and can handle a larger load than the random w alk algori thm. W e consider in detail v arious attributes of our alg orithms, for instance w e sho w that an algorithm that bases its decisio ns on the mean delivery time jams unless it in corp orates in formation ab o ut the degree of th e destination no de. 1 In tro duction Complex net works can be used to mo del a wide range of ph ysical and tec h- nological systems. One of the most interesting dynamica l problems on net work is tra nsport, which can g iv e us some insight into the transp ort of information in tec hnolog y based comm unication net works lik e the in ter net [1], the W orld Wide W eb [2],[3] or pho ne call netw ork s [4]. Here we use the term tr ansp ort to mean transp ort of particles , which are pack ets in a net work. Thus our mo del falls within the Netw ork La yer of the O SI Reference Mo del a nd the algor ithms describ ed in section 3 are ro uting alg orithms that belo ng to t he Net work Lay er of the OSI Reference Mo del. Of par ticula r in terest is the pheno menon of load in a netw ork, as a function of the rate of pack et creation R, which has be en in- vestigated for models of co mmunication netw ork s [5 ],[6],[7] and in real net works [8]. Typically the problem of transp ort is inv es tigated using either a random walk algorithm [5], or the shortest path algorithm used b y mo s t int ernet proto cols. The difficult y with these approa c hes is that random w alk algor ithm is very inefficient for tra ns port in technology based communication net works and shortest pa t h algorithm requires, for its implemen tation, informatio n about all connections in net work. In this pap er w e fo cus on algorithms that use lo cal information abo ut the to p ology , along with information a bout the flux of pack e t s b et ween neighbors, 2 Bernard K uja wski et al. the link loa d and the time taken to deliv er pack ets. W e prop ose fo ur algorithms that use some or all of these prop erties to deliv er pack ets in a net work. In sectio n 2 we describ e the algor ithm that we use to p erform num eric a l simulations of our models. In section 3 we dis cuss the algorithms that pac kets use to find their destina tio ns and in sectio n 4 we show our results. In section 5 we summar ise o ur r esults. 2 The Progr a m A progr a m was written to s im ula t e pack et transp ort on a netw ork that do es not depend on the size of the netw ork or its top ology . A t the beginning of the progra m an external file with the adjac ency matrix of the netw ork is rea d in. W e focus on t he in ternet and co nsequen tly we t rea t nodes in our netw ork as if they w ere routers. The connections b et ween the routers hav e the same ca pacit y for all net works. Suc h a mo del can not only b e used to mo del in ternet pack et transp ort but also for a ra ng e of transp ort netw orks in which the no des have lo cal routing information. Eac h no de : – Generates a new pack et with pr obabilit y r = R/ N and with a randomly chosen des tination, where R is a fixed rate for the whole netw ork, and N is the num b er of nodes in netw or k. – Stores pack ets in a queue, which has maxim um length is L = 1000. Pac kets are despatched from the q ueue in a first in first o ut (FIFO) order. – Sends pack ets to its neigh b ours. Eac h no de has information about : – The address of all its neighbours (they hav e unique indices j ). – The degree of its neighbours - k ( i ). – Flow throug h all its neighbo urs, which is measured b y • The n umber of pack ets p osted down each edge to neigh b our i - the Link Load - C ( i ). • The n umber of pac kets sends through neighbour i , which ha ve reached their destination - N P ( i ). • The sum of the delivery times of all the packets sent through neighbour i that hav e reached their destinatio n - T P ( i ). • The time int er v al since an edg e last trans mitted a packet to neighbour i and current time step - ∆T ( i ). The index i enumerates each neigh b our of no de k and ea c h no de k eeps a ll the statistics ab out its neig h b ours. Quantities C ( i ), N P ( i ), T P ( i ) and ∆T ( i ) describ e no de i from the p erspective of no de k . Each node is describ ed by its neighbours a nd all pro perties can b e different for all neighbo urs that descr ib e no de i . The initializa tion pa r t of the progr am sets up the netw ork topolog y , the no des a nd all the ta bles use d by them. Inside the ma in lo op a time step is Lecture Notes in Computer Science 3 incremented, a nd wit hin that a lo op over a ll no des calculates and updates the statistics. The loo p o ver all no des includes three basics r o utines, whic h ar e run for ea c h no de; generating new pack ets, chec king its queue for pack ets with its address and s ending pack ets to its neighbo urs. E ac h no de gener a tes a packet with a randomly chosen destination with probabilit y R/ N . The node chec ks its own queue f or pack ets addressed to itself. When it find s one of these it deletes it from the queue and up dates the statistics N P ( i ) and T P ( i ) for all the nodes on the pack e t ’s pa th . Eac h packet k eeps tr a c k of its own path. The node sends pack ets to its neighbour s by ta king the first pack et in its queue and c hecking the pack et destination address . I f the pack et is addressed to one of its neighbour, the no de will send it t o the neigh b our. If it is no t, the no de will use the algorithm to find where to s end the packet. Du ring this p osting step the C ( i ) proper t y is upda ted. When no de k s e nd s pa c kets to no de i , the num b er of sent pac kets C ( i ) increases. After this lo op ov er all the nodes is completed the quantities ∆T ( i ) and the mean delivery time of pack ets sent down each edge N P ( i ) /T P ( i ) are upda ted fo r a ll nodes. 3 Algorithms The most impo rtan t element in tr ansport is the rule that determines the dire c t ion in which a pack et is sen t. A transp ort net work without a rule is a random walk net work. W e call this rule the algorithm . It describ es how no des deal with pack e ts and s ho uld help packets to get to their des t ination. Not all algor it hms help pack- ets to rea ch destinations, po or algor ithms can ea sily b e worse than the random walk algorithm. All algorithms considered in this pap er work with‘deterministic rules. The shortest time (ST) algo rithm is our basic alg orithm that uses informatio n ab out the mean delivery time T P ( i ) / N P ( i ) and the time interv al b et ween the last pack et that came to no de i and actual time step. The ST algo r ithm finds the minim um v alue S k = min T P ( i ) N P ( i ) 1 ∆T ( i ) i =1 ...n (1) in o rder to deter m ine which no de to send the pac ket to. The idea of this algorithm is to tr y and find the minim um tra vel time for each pac ket betw een so urce a nd destination. At the s ta rt of the simulation S is e q ual to 0 for all neighbours . Because the up date of T P ( i ) / N P ( i ) only o ccurs when a pack et a rriv es at its destination, it can tak e a num b er of time steps befor e T P ( i ) / N P ( i ) b ecomes non- zero. The inclusion of the re ciprocal of ∆T ( i ) in S ensures that the algorithm do es not get in to a state where it nev er sends a pack et do wn cer ta in links which hav e a lar g e mean deliv ery time. This state is particularly likely to o ccur at the start of the s im ulatio n. The inclusion of the re ciprocal of ∆T ( i ) in S a lso preven ts ov ercrowding when a node finds a no de which is clearly b etter tha n all its other neighbours. Hence, becaus e of the inclusion o f ∆T ( i ) mo re no des take part in the transp ort and in this wa y the large node do not bec o me ov ercrowded. Because the algorithm with T P ( i ) / N P ( i ) is looking for minim um delivery time we call it the 4 Bernard K uja wski et al. shortest time (ST) algorithm. T o start this algorithm, and the STD alg o rithm, which we will in tro duce shortly , we use the r andom walk algorithm. W e only use the deterministic alg orithms a t a no de when a ll the v alues of S of its neighbours are grea t er than 0. Without this initial rando m w alk pro cedure b oth the ST and the STD alg orithms would jam almost immediately . The shortest time and de gr e e (STD) algorithm is a modificatio n of the ST algor ithm. It uses information ab out the lo cal top ology , the degree. This helps pack ets avoid the no des with the lar gest degree, which ar e mo stly ov ercr o wded. The idea of incorp orating information abo ut the degree of no des in the transpo rt algorithm w as disc ussed in [9] and [10]. In these pap ers mo dels were introduce d in which no des were selected at a r ate prop ortional to a p o wer of their degree. It was found that the most efficient algorithm was one in which the the probability o f selecting a no de of degr ee k was prop ortional to 1 /k [9] and [10]. The STD algorithm is defined by S k = min T P ( i ) N P ( i ) 1 ∆T ( i ) k ( i ) i =1 ...n (2) where k ( i ) is a degree of node i and k ( i ) > 1. This last assumption allo ws the algorithm to av oid dead-end nodes. A no de with degree k = 1 can only receive a pack et that is addressed to its e lf. The STD algorithm use s b oth tempo ral prop erties a nd a lso informa t ion ab out the local connectivity . F or transp ort in a scale-free net work the mo st imp ortan t nodes are those with the largest degree. But b ecause their neighbours send these no des a large num b er of pa c kets the queues at these no des can become overcrowded. Information ab out the degree helps the algorithm to av oid these no des, but it do es not mean than they ar e not used. The c onne ctions and de gr e e (CD) algorithm and the c onne ctions, de gr e e and shortest t i me (CDT) a lg orithm use information ab out the link load C ( i ). Because of this the random w alk starting pr ocedure used in the ST and STD algorithms is not r equired for the CD and CDT alg orithms. The CD alg o rithm uses only information ab out the link load and the degree. The CD algorithm is defined b y S k = min [ C ( i ) k ( i )] i =1 ...n (3) where C ( i ) is a num b er of pac kets that no de k sends to node i . F or this a lgorithm S equals 0 at the start, but C ( i ) is up dated almost imme- diately . When no de k sends a pack et then it automatically increases the v alue of C ( i ). Ther e is no need to wait for information from the destination ab out the delivery time like in the ST a nd STD algor ithm s. In this w ay CD algo- rithm improv e s v ery quickly and the random w alk is not needed. The link load, C ( i ), quantit y helps the algo rithm to deliver pa c kets and ensures that almost all no des tak e part in the transp ort. The degree quan tity helps to preven t the largest nodes from becoming overcro wded. In this algorithm there is no proper t y that c an b e o ptimised, unlike in the ST and STD algorithms where the delivery time is optimised. The CDT a lgorithm is intermediate b et ween the CD a nd the ST alg orithms. It o ptimises the delivery time and does not need the random the walk starting Lecture Notes in Computer Science 5 pro cedure b ecause it includes a dep e nda nce on the link load, C ( i ). The de- pendenc e on degree preven ts large no des becoming overcrowded. F o r the CDT algorithm, the s tarting pro cedure is the s a me as for the CD a lgorithm except that we set T P ( i ) N P ( i ) 1 ∆T ( i ) (4) equal to 1 at the start to a void 0 v a lue. This means that we do not need to start off with a rando m w alk algorithm as in the ST and STD algorithms. The CDT algorithm is defined by S k = min T P ( i ) N P ( i ) 1 ∆T ( i ) C ( i ) k ( i ) i =1 ...n with k ( i ) > 1 . (5) W e use the lear ning pr operty to describ e b eha vior o f an algo rithm in the beg inning. By learning we mean the prop ortion of links whose v alue of S has changed since t = 0. The CD and CDT algor ithms learn the most quickly . After 5000 time s teps they tried 9 5% of links . This is b ecause the link lo ad, C ( i ), c hang es when a pac ket is sent down it whereas T P ( i ) / N P ( i ), used b y the ST a nd STD algo rithms, only changes when a packet sen t down it gets to its destination. That is way the ST and STD alg o rithms need the random walk starting procedur e . With this pro cedure after 5000 time steps 35% of links were tried. F or the ST algorithm without the random w alk starting pro cedure it was 5%. The spee d of learning is impo rtan t beca use when a netw o rk lear ns slowly , the netw ork only uses a sma ll pro portion of its link s for transp ort ov er a long per iod of time, which means that the netw ork is easily jammed when a region of the netw o rk b ecomes o vercrowded. 4 Results W e consider tra nsport on the B a rabasi and Alb ert mo del of a netw ork [11] with N = 1000 no des and m = 2. The p ar ameter m is th e n umber of links of a new no de that is added to netw ork . When m = 2 the netw ork includes lo ops and has r elativ e s mall num b er o f connections. Our resea r c h show that this netw ork jams for low er v alues of the po sting rate than net works with m = 1 or m = 3 and hig her. In this work we use a p osting rate of R = 0 . 1. This means that each no de crea tes a pac ket with pro babilit y R/ N . The nu mber of time steps for all our simulations is 500 , 0 00. W e pres en t results for the STD, CD and CDT algorithms. W e do not co nsider the ST algor ith m any further beca use it isn’t stable and alwa ys jams. In figure 1a w e show the load in the net work, the num b er of pack ets that are still in the netw ork. All three algorithms are stable. W e compared the level of load by finding the mea n v alue of the num b e r of pack ets in the netw or k. The bes t algor ithm with sma llest mean v alue is the STD algorithm. F or the CD and CDT the v alues ar e almo st the sa me. The n umber of pack ets in netw ork can be treated as a noise in the net work. Measuring the p o wer spectr um of this noise sho ws that there are corr elations in 6 Bernard K uja wski et al. the num b er of pa c kets in netw o rk. F or all our a lgorithms the p ow er sp ectrum (Fig.1b) is the same and the slope has − 2. It means that the noise in net work is like 1 /f 2 ; uncorrelated noise with short-range cor relations only . W e measured Fig. 1. The lo ad properties. a ) Load in the netw ork fo r the STD,CD and CDT algo- rithms. b ) T he p o w er sp ectrum for all algorithms is the same and show s sho ws that noise in netw ork is un co rrelated. the distribution of the time interv al ∆T ( i ), the time that no des wait for pack ets, and the r esults ar e shown in figure 2. This is a n impo rtan t q ua n tity for the SDT and CDT algorithms as without the ∆T ( i ) ter m these netw orks easily jam. F or the STD alg orithm the dis t ribution of ∆T ( i ) has a tail and on a double logarithmic scale ha s a slope b = − 3 / 2. The cut-off comes from the finite t ime of the simulation. The first part of the distribution for all algorithms is flat. F o r the CDT a lgorithm the function falls faster than for the STD. This is connec t ed with the inclusion of the link load in the CDT alg orithm, whic h means that mo re links are used and long time in terv als of ∆T ( i ) do not oc cur a s freq ue ntly as in the STD a lgorithm. The CD algo rithm do es not use ∆T ( i ) but w e m eas ured it to compare it to the other mo dels. Fig. 2. Distribution of time interv al ∆T ( i ). Lecture Notes in Computer Science 7 The distribution of pac ket delivery time (Fig.3a) is similar for all the algo - rithms. Ho wev er the distribution sho ws that the n umber of pack ets delivered in a short time is differen t for ea c h algorithm F or the STD alg o rithm pack ets ar e delivered quickly mo re fr equen tly than for the CD and CDT alg orithms. The STD algo rithm finds the paths with the shortest delivery time b ecause, whilest the CD and CDT algor ithms ar e distributing the transpor t across the netw ork, bec ause their algorithms use the link load C ( i ) , the STD a lg orithm is look ing for shortest deliv ery times. The dis t ribution for the CDT a lgorithm is in termediate betw een the STD and CD algo rithms b ecause the CDT algo rithm dep ends on the link load C ( i ) and the shortest time statistics. Fig. 3. The time delivery quan tities for the STD, CD and CDT algorithms. a ) The time interv al d is tribut i on for pac kets b etw een a source and a d es tination. b ) The mean delivery time. The tim e series for the ov era ll mean d elivery time (Fig.3 b) show that algo- rithms inv olving the statistics for T P ( i ) / N P ( i ) do not learn. The mean delivery time for CD and CDT is almost the same. The alg orithms r eac h a stable mean delivery time and do not o ptimise it. Obviously for the CD algorithm no o pti- misation is p ossible because there is no quantit y that could b e optimized. The res ult for the STD and CDT algor ith ms a rise through tw o effects. The first is the inclus ion of ∆T ( i ) in S that send pack ets to rarely used links that often are no t the b est ones for tra nsport. O n the other hand without ∆T ( i ) all the algorithms with the mean time property start ja mm ing. Secondly is the inclusion of the deg ree in S , which means that alg orithms pre f er to send pac kets to no des with a s mall deg r ee which mak es the delivery time long. 5 Conclusions The a lgorithms STD, CD and CDT work well; for the same netw ork and for the same v alue o f R the r andom w alk a lgorithm jams, and these algor ithms do not. One migh t exp ect that including the mean delivery time of pac kets sent to no de i , T P ( i ) / N P ( i ), in S would optimize the delivery time. This do es not happ en 8 Bernard K uja wski et al. bec ause o f the dep endence of S o n the delivery time, link load and degree. But on the other hand without dependence on these terms the algorithms cannot w ork prop erly . This the case in the ST a lgorithm, whic h works be tter than the ra ndom walk algorithm, but muc h w o rse than the other a lg orithms. When the shortest time prop erty is used in the scale-free net work it needs to b e balanced be degree quantit y . T he existence o f nodes with large degrees causes traffic co ng estion for the shortest time algorithm. Using an a lgorithm which dep ends on loca l degree information but without dep endence on the mean time (CD algorithm) works cor rectly but an algor it hm without lo cal degr ee dep endence and with the mea n time dep endence (ST algorithm) jams easily . The biggest problem in implemen ting the STD and CDT algorithms is in finding accur ate v alue for the edge dep enden t prop e r ties. A no de needs a lot of connections through one link to find it pr oper time s t atistics . Bec a use the mea n delivery time is v er y long, it ta k es a lot of time to set up the edges dependent prop erties for all no des. In particular, the algo rithms that dep end on the time ∆T ( i ) and the degree k ( i ) do not jam but the cost is in learning and the mean delivery time. The inclusion of the ∆T ( i ) quantit y in S , av oids jamming but destro ys the learning behavior promoted b y the inclusio n of the mean time pr operty in S . The degree prop ert y helps the algorithm to a void nodes with large degree, and hence helps preven t ov ercrowding, but it also results in long deliv ery times. Our results show that in scale free net works w e cannot av oid using no des with la rge degr ee. In future w o rk, it may b e possible to develop an algo rithm that uses infor- mation o n the mean lo cal delivery time to find the optimal path for tra nsport. One p ossible extens ion of this work w ould b e to use an a lgorithm that allows a num b er of pack ets to b e sent to a no de in one time step, dep ending on the degree of the no de. This is realis t ic b ecause normally routers can use all their outputs almost in a parallel way . The biggest pr o blem in netw ork s is that no des with a very high degree can receive as many pac kets a s they have inputs in one time step, but they usually send only one pac ket. W hen we allo w them to use all their outputs in one time step then jamming will disapp ear. References 1. M. F aloutsos, P . F aloutsos a nd C. F aloutsos, (1999) Comp. Comm. Rev. 29 , 251. 2. R. Alb ert, H. Jeo ng and A.-L. Barabasi, (1999) Natu re 401 , 130 . 3. B. Hu berman and L. Adamic, (1999) Nature 401 , 131. 4. L. A . Adamic, R. M. Luko se, A. R . Puniyani and B. A. Hub erman, Phys. Rev. E (2001) 64 , 046135 . 5. B. T adic, S. Thurner and G. J. R o dgers, ( 2 004) Phys. Rev. E 69 , 036102. 6. A. Arenas, A. Diaz-Guilera and R. Guimera, (2001) Ph ys. Rev. Lett. 86 , 3196. 7. R. Sole and S. V alverde, (2001) Ph ysica A 289 , 595. 8. V. Jacobson, in Pro ceedings of SIGCOMM ’88 (ACM , Standford, CA, 1988). 9. G. Y an, T. Zhuo, B. H u, Z.-Q. F u and B.-H. W ang, (20 05) cond-mat/0505366. 10. C.-Y. Yin, B. -H . W ang, W.-X. W ang, T. Zhou and H.-J. Y ang, (2005) co nd - mat/05062 04. 11. R. Alb ert and A.-L. Barabasi, (2002 ) Rev. Mod. Ph ys. 74 , 47.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment