Small Is Not Always Beautiful
Peer-to-peer content distribution systems have been enjoying great popularity, and are now gaining momentum as a means of disseminating video streams over the Internet. In many of these protocols, including the popular BitTorrent, content is split in…
Authors: ** Paweł Marciniak (Poznań University of Technology, Pol, ) Nikitas Liogkas (UCLA
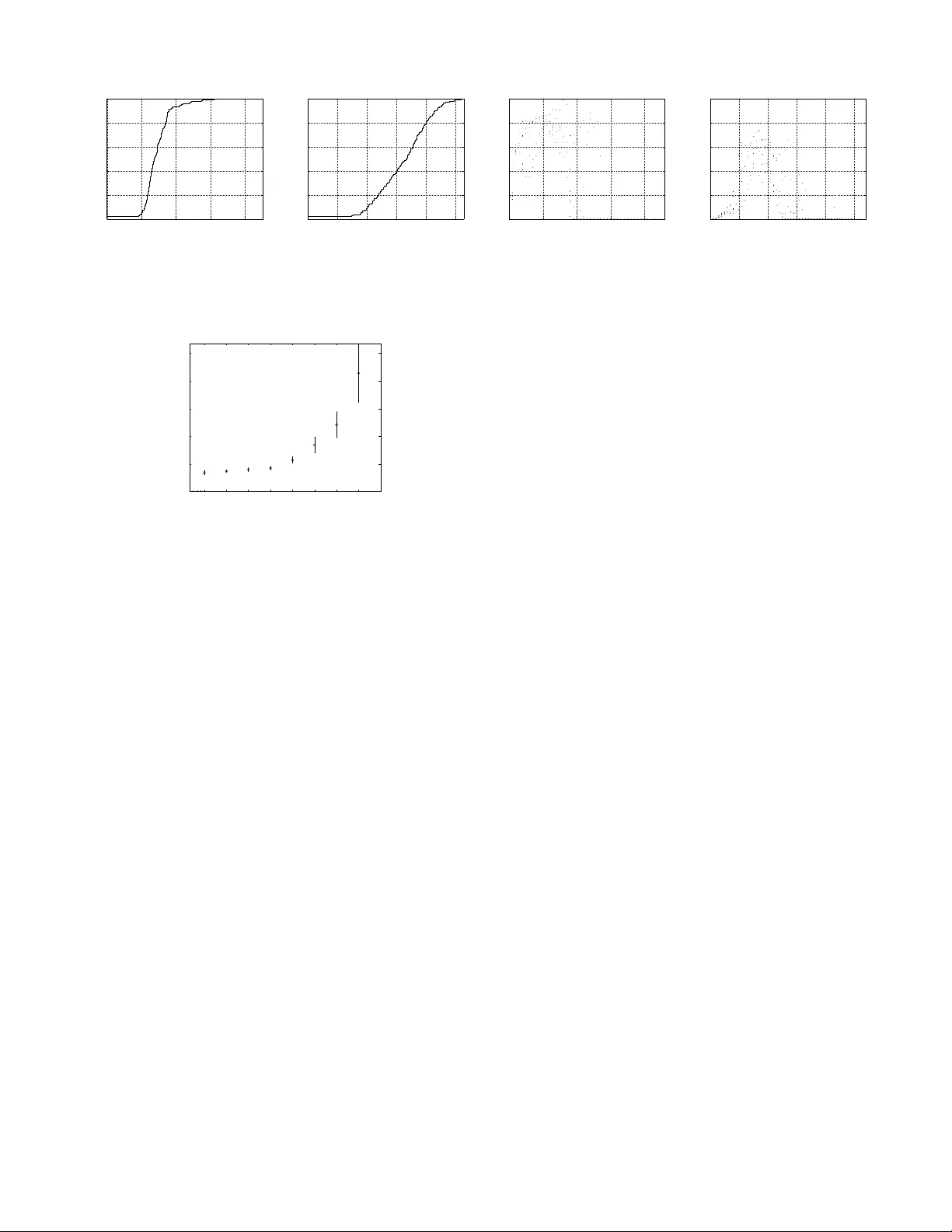
Small Is Not Alw a ys Beau tiful ∗ P aweł Mar ciniak † P oznan University of T echnology , P oland pa wel.ma rciniak@gmail.com Nikitas Liogkas UCLA Los Angeles, CA nikitas@cs.ucla.edu Arna ud Legout I.N.R.I.A. Sophia Antipolis , F rance ar naud.legout@sophi a.inria.fr Eddie K ohler UCLA Los Angeles, CA kohl er@cs.ucla.edu Abstract P eer-to- p eer con tent distribution systems ha v e b een enjo ying great p opularity , and are no w gain- ing moment um as a means of disseminating video streams o ver the In tern et. In man y of these proto- cols, including the p opular BitT orrent, con tent is split i n to mo stly fixed-size pieces, allo wing a client to do wnload data from many p eers sim ultaneously . This mak es pie c e size p oten tially critical for p er- formance. Ho w ev er, pr evious researc h e fforts hav e largely o v erlo oked this parameter, opting to fo cus on others instead. This pap er presents th e resu lts of real exp er i- men ts with v arying piece sizes on a con trolled Bit- T orren t testb ed. W e demonstrate that this parame- ter is indeed critical, as it determines the degree of parallelism in the system, and we inv estigate op- timal piece sizes for distrib uting small and large con tent. W e also pin p oin t a related design trade- off, and explain ho w BitT orrent’s c hoice of dividing pieces in to sub pieces atte mpts to address it. 1 In tro duction Implemen tation v ariatio ns and p arameter settings can seve rely affect th e service ob s erv ed b y the clien ts of a p eer-to-peer s ystem. A b etter under- standing of proto col parameters is needed to im- pro v e and stabilize service, a particularly imp or- tan t goa l fo r emerging p eer-to- p eer applications suc h as streaming vid eo. BitT orrent is w id ely regarded as one of the most successful swarming proto cols, wh ic h divide the con tent to b e distributed in to distinct pieces and enable p eers to share these pieces efficien tly . P re- vious researc h efforts ha ve fo cused on th e algo- rithms b eliev ed to b e the ma jor factors b ehind Bi t- T orren t’s go o d p erformance, su c h as the p iece and p eer selection strategies. Ho w ever, to the b est of our knowledge , no stu dies hav e lo oked in to the op- ∗ App eared in IPTPS’2008, T ampa Bay , Florida, US A. † W ork done while an intern at INRIA Sophia Antipolis. timal size of con tent piece s b eing exc h anged among p eers. Th is pap er inv estigates this parameter by runn in g real exp erimen ts with v arying piece sizes on a con trolled testb ed, and d emonstrates that pie c e size is critic al for p erformanc e , as it d eter- mines the d egree of parallelism a v ailable in the sys- tem. Our results also show that, for s mall-sized con- ten t, smaller pieces enable s horter do wnload times, and as a result, BitT orr ent’s design choic e of fur- ther dividing c ontent pie c es into subpie c es is un- ne c essary for such c ontent . W e ev aluate th e o ver- head that small pieces incur as con ten t size grows and demonstrate a trade-off b et we en piece size and a v ailable parallelism. W e also explain how this trade-off motiv ates th e use of b oth p ieces and su b- pieces for distribu ting large con ten t, the common case in BitT orrent sw arms. The rest of th is pap er is organized as follo ws. Section 2 provides a brief description of th e Bit- T orren t proto col, and describ es our exp erimen tal metho dology . Section 3 then p resen ts the results of our exp eriments with v arying p iece sizes, wh ile Sec- tion 4 discusses p oten tial reasons b ehind the p o or p erforman ce of small piece s when distrib uting large con tent. Lastly , Section 5 describ es related work and Sectio n 6 concludes. 2 Bac kground and Metho dology BitT orren t Overview BitT orrent is a p opular p eer-to-p eer con ten t distribution proto col that has b een shown to scale w ell with the num b er of par- ticipating clien ts. Prior to distrib ution, the con tent is divided in to multiple pie c es , while eac h piece is further divid ed int o m ultiple subpie c es . A metainfo file con taining information necessary for initiat- ing the downloa d pro cess is then created by the con tent pro vider. This information includes eac h piece’s SHA-1 hash (used to v erify receiv ed data) and the addr ess of the tr acker , a centraliz ed com- p onent that facilitates p eer disco very . In order to join a torr ent —the collecti on of p eers participating in the download of a particular con tent—a clien t retriev es the metainfo fi le out of band, usually from a W eb site. It then conta cts th e trac ker, whic h r esp onds with a p e er set of r andomly selected p eers. These might include b oth se e ds , w ho already ha v e the entire con tent and are sharin g it with others, and le e chers , who are still in the p ro- cess of downloading. Th e new clien t can then s tart con tacting p eers in this set and r equest d ata. Most clien ts now ada ys implemen t a r ar est-first p olicy for piece r equests: they fir st ask for th e pieces that ex- ist at the smallest n um b er of p eers in their p eer set. Although p eers alw ays exc hange jus t subpieces with eac h other, th ey only make d ata a v ailable in the f orm of complete p ieces: after downloading all subpieces of a piece, a p eer notifies all p eers in its p eer set w ith a have message. P eers are also able to determine which pieces others hav e based on a b i t- field message, exc hanged up on the est ablishmen t of new connections, which cont ains a b itmap denoting piece p ossession. Eac h leec h er indep enden tly decides who to ex- c h ange d ata w ith via the choking algorithm , whic h giv es preference to those wh o upload d ata to the giv en leec her at the highest rates. Thus, once p er r e choke p erio d , typically ev ery ten s econds, a leec her consider s the receiving data rates from all leec hers in its p eer set. It then p ic ks out the fastest ones, a fixed n um b er of them, and only uploads to those for the d u ration of the p erio d. Seeds, wh o do not need to do wnload any pieces, follo w a d if- feren t un chok e strategy . Most cur r en t implementa - tions unchok e those leec hers that downlo ad data at the highest rates, to b etter u tilize seed capac it y . Exp erimental Metho dology W e ha v e p er- formed all our exp erimen ts with p riv ate torren ts on the PlanetLab platform [5]. T hese torren ts com- prise 40 leec hers an d a sin gle initial seed sharing con tent of different sizes. Leec hers do not c h ange their a v ailable up load bandwidth during the do wn- load, and disconnect after receiving a complete cop y of the con tent. The initial seed sta ys con- nected for the duration of the e xp eriment, w hile all leec hers join the torren t at the same time, em ulat- ing a flash cro wd scenario. The num b er of p arallel upload slots is set to 4 for th e leec hers and seed. Although system b eha vior migh t b e different with other p eer arriv al patterns and torren t configu r a- tions, there is no reason to b eliev e that th e conclu- sions w e draw are predicated on these parameters. The a v ailable bandwidth of most PlanetLab no des is relativ ely high for t yp ical real-w orld clien ts. W e imp ose up load limits on th e leec hers and seed to mo del more realistic scenarios, bu t do not imp ose any do wnload limits, as we w ish to ob- serv e differences in do w nload completion time with v arying piece sizes. The upload limits f or leec hers follo w a uniform distrib ution fr om 20 to 200 kB/s, while the seed’s u pload capacit y is set to 200 kB/s. W e colle ct our m easuremen ts using the offi- cial (mainline) BitT orrent implementa tion, instru - men ted to record interesting eve n ts. Our client is based on v ersion 4.0.2 of the official implementa- tion and is p ublicly a v ailable for do w nload [1]. W e log the clien t’s in ternal state, as w ell as eac h mes- sage sent or receiv ed along with the conte n t of the message. Unless otherwise sp ecified, w e ru n our ex- p eriments with the default parameters. The proto col do es not strictly define the piece and subp iece sizes. An u nofficial BitT orrent s p eci- fication [3] states th at th e con v entional wisd om is to “p ick the sm allest p iece size that r esu lts in a metainfo fi le no greater than 50– 75 kB”. T he most common p iece s ize for pub lic torrent s seems to b e 256 kB. Additionally , most implementa tions now a- da ys use 16 kB sub pieces. F or our exp erimen ts, we alw ays keep the su bpiece s ize constan t at 16 kB, and only v ary the p iece s ize. W e h a v e r esu lts for all p ossible com binations of different con tent sizes (1 MB, 5 MB, 10 MB, 20 MB, 50 MB, a nd 100 MB) and piece sizes (16 kB, 32 kB, 64 kB, 128 kB, 256 kB, 512 kB, 1024 kB, and 204 8 kB). 3 Results Our results, p resen ted in th is section, demonstrate that small pieces are preferable for the d istr ibu- tion of small-sized conte n t. W e also d iscu ss the b enefits and dra wbac ks of s mall pieces for other con tent sizes, and ev aluate the comm unication and metainfo file ov erhead that different piece sizes in- cur for large r con ten t. 3.1 Small C on ten t Ev en th ough most con ten t distribu ted with Bit- T orren t is large , it is still inte resting to examine the impact of piece size on d istributing smaller conte n t. In addition to gaining a b ette r u nderstand in g of th e trade-offs in v olve d, it ma y also sometimes b e desir- able to utilize BitT orrent to a v oid s erv er o verload when distributing small con ten t, e.g., in the case of w ebsites that s u ddenly b ecome p opular. Figure 2 sho ws the median d o w nload completion times of the 40 leec h ers downloading a 5 MB file, for dif- feren t num b ers of pieces, along with standard d e- viation err or bars. Clearly , smal ler pie c e sizes en- able faster downlo ads . In particular, p erformance 0 50 100 150 200 0 0.2 0.4 0.6 0.8 1 Completion time (s) Cumulative fraction of peers Download Completion Time (a) Piece size of 16 kB 0 50 100 150 200 250 0 0.2 0.4 0.6 0.8 1 Completion time (s) Cumulative fraction of peers Download Completion Time (b) Piece size of 512 kB 0 10 20 30 40 0 0.2 0.4 0.6 0.8 1 Time slot (5s) Upload utilization Average Peer Upload Utilization (c) Piece size of 16 kB 0 10 20 30 40 50 0 0.2 0.4 0.6 0.8 1 Time slot (5s) Upload utilization Average Peer Upload Utilization (d) Piece size of 512 kB Figure 1 : CDFs of p eer d ow nload completion times and scatterplots of av erage upload utilization for five-second time interv als when distributing a 5 MB conten t (a verages o ver 5 runs). Smal l pie c es shorten downlo ad time and enable higher utilization. 16 32 64 128 256 512 1024 2048 0 100 200 300 400 500 Piece size (kB) Download completion time (s) Peer Performance (5 MB content) Figure 2 : Download completion times for a 5 MB con ten t (medians ov er 5 runs and stand ard deviation error bars). Smal ler pie c es cle arly impr ove p erformanc e. deteriorates rapidly w h en increasing the piece size b eyo nd 256 kB. The same observ ations hold for ex- p eriments with other sm all con tent (1 and 10 MB ). T o b etter illustr ate the b enefits of sm all pieces, Figure 1 sh o ws the cum ulativ e distr ibution func- tions (CDF) of leec her downloa d completion times for 16 and 512 kB pieces (graphs (a) a nd (b)). With small pieces, most p eers complete their do wnload within the fi rst 100 seconds. With larger pieces, on the other hand, the median peer completes in more than t wice the time, and there is greater v ariabil- it y . T he r eason is that smal ler pie c es let p e ers shar e data so oner. As mentio ned b efore, p eers send out have messages announcing new pieces only after do wnloading and verifying a complete p iece. De- creasing piece size allo ws p eers to downloa d com- plete p ieces, and thus start sh aring th em with oth- ers, so oner. T his increases the a v aila ble parallelism in th e system, as it enables more opp ortunities for parallel do wn loading from m u ltiple p eers. This b enefi t is also evident when considering p e er uplo ad utilization , whic h constitutes a reliable met- ric of efficiency , since the total p eer upload capac- it y represen ts the maximum through p ut the sys tem can ac hiev e as a whole. Figure 1 s h o ws utilization scatterplots for all fiv e-second time inte rv als dur- ing the do wnload (graphs (c) and (d)). Average upload u tilization for eac h of 5 exp erim ent ru ns is plotted once every 5 seconds. Thus, there are fiv e d ots for every time slot, repr esen ting the a v- erage p eer upload u tilization for that slot in the corresp ondin g run. The metric is torr ent-wide: for those fiv e s econds , we sum the up load bandw idth exp ended by leec hers and d ivide by the a v ailable upload capacit y of all leec hers still connected to the system. T h us, a u tilizatio n of 1 r epresen ts tak- ing full adv an tage of the av ailable upload capacit y . As p reviously obs er ved [9], utiliza tion is low at th e b eginning and end of the session. During th e ma- jorit y of the d o w nload, ho w ev er, a smaller piec e size increases the n um b er of pieces p eers are in terested in, whic h leads to higher upload utilizati on. These conclusions are reinforced b y the fact that small pieces enable the seed to u p load less d uplicate pieces durin g the b eginning of a torren t’s lifetime. Figure 3 indeed plots the num b er of pieces (un ique and total) up loaded b y the single seed in our 5 MB exp eriments, for t w o represen tativ e r uns. Although the seed finish es uploading the first copy of the con tent at appro ximately the same time in b oth cases (v ertical lin e on the graphs), it uploads 139% more d uplicate data w ith larger p ieces (5120 kB for 512 kB pieces vs. 2144 kB for 16 kB p ieces), th us making less efficient use of its v aluable upload bandwidth . Av oiding this waste can lead to b etter p erforman ce, esp ecially for low-ca pacit y seeds [9]. This b eh a vior can b e explained a s follo ws. The offi- cial BitT orrent imp lemen tatio n we are u s ing alwa ys issues requests for the r arest pieces in the same or- der . As a result, while a leec her is do wnloading a giv en piece, other leec h ers m igh t end up requesting the same piece from th e seed. With smaller pieces, the time in terv al b efore a piece is completely do wn - loaded and shared b ecomes sh orter, mitigati ng this problem. Th is could b e resolv ed by having leec hers request rarest pieces in ran d om ord er instead. In sum m ary , small pieces enable significantly 0 50 100 150 0 200 400 600 800 1000 1200 Time (s) Cumulative number of pieces Pieces Uploaded by the Seed Unique Total (a) Piece size of 16 kB 0 50 100 150 200 0 10 20 30 40 50 60 Time (s) Cumulative number of pieces Pieces Uploaded by the Seed Unique Total (b) Piece size of 512 kB Figure 3 : Nu mber of p ieces uploaded b y th e seed when dis- tributing a 5 MB content, for tw o represen tativ e runs. The Unique line represents the p ieces that had not b een pre- viously uploaded, while the T otal line represents the total num ber of pieces up loaded so far. The vertical line denotes the time the seed finished up loading the first copy of the conten t to the system. The duplic ate pie c e overhe ad is sig- nific antly lower for smal l pi e c es. b etter p erf ormance wh en distributing small con- ten t. As a result, the distinction of pie c es and sub- pie c es that the BitT orr ent design dictates is unne c- essary for such c ontent . F or instance, in our 5 MB exp eriments, pieces that are as small as subp ieces (16 kB) are optimal. Thus, the conte n t could just b e d ivid ed into pieces with no loss of p erformance. 3.2 Piece Size Impact Before inv estigating the imp act of piece size on the distribution of larger conte n t, let us fir s t examine the adv an tages and dra wbac ks of sm all pieces. W e ha v e s een that th eir b enefits for small con ten t are largely due to th e increased p eer upload utilizatio n suc h pieces enable. Since sm all p ieces can be do wn- loaded so oner than large ones, leec hers are able to share small pieces so oner. In this manner, there is more data av ailable in the system, wh ic h giv es p eers a w ider c hoice of pieces to do wnload. In addi- tion to this in cr eased p arallelism, small pieces p ro- vide the follo win g b enefits (some of w h ic h do not affect our exp erimen ts). • They decrease the num b er of dup licate pieces uploaded by seeds, thereby b etter utilizing seed upload b andwidth . • The rarest-first piece selection s tr ategy is more effec tiv e in ensurin g piece replication. A greater num b er of pieces to c ho ose f r om en- tails a lo wer pr obabilit y th at p eers download the same p iece, wh ic h in tu rn imp ro v es the d i- v ersit y of pieces in the system. • There is less w aste w h en do wnloading corrup t data. P eers can disco v er b ad pieces sooner and re-initiate their do w nload. On the other han d , for larger con ten t, th e o v er- head incu r red by small pieces ma y hurt p erfor- mance. This ov erhead includes the f ollo wing. • Meta info files b ecome larger, since they ha v e to include more SHA-1 hashes. This would in- crease the load on a W eb server serving suc h files to clien ts, esp ecially in a flash cro wd case. • Bitfield message s also b ecome larger d ue to the increased n um b er of bits they must contai n. • P eers m u s t send m ore have messages, r esulting in increased comm un ication o verhead. In the next section, we shall see that these draw- bac ks of small pieces out w eigh their b enefits, for larger cont en t. Thus, the c hoice of piece size for a do wnload should tak e the conten t s ize int o accoun t. 3.3 Larger C on ten t Figure 4 shows th e do wnload completion times of the 40 leec hers do wnloading a 100 MB fi le for differ- en t piece sizes. W e ob s erv e that small pieces are no longer op timal. In this p articular ca se, sizes a round 256 kB seem to p erform the b est. Exp erimen ts with other conten t sizes (20 and 50 MB) s ho w that the optimal pie c e size incr e ases with c ontent size . F or instance, for exp erimen ts with a 50 MB con ten t, the optimal piece size is 64 kB. Note that the unoffi- cial guideline for c ho osing the piece s ize, men tioned in Section 2, w ould yield sizes of 32 and 16 kB for a 100 MB and 50 MB con ten t resp ectiv ely , a bit off from the optimal v alues. In an effort to b etter u nderstand this trade-off regarding the c hoice of piece size, we ev aluate the metainfo file and communicatio n o verhead. The former is sh o w n in Figure 5. As exp ected, small pieces pro du ce pr op ortionately larger metainfo fi les (note that the x axis is logarithmic). 16 kB pieces, for in s tance, p r o duce a metainfo file larger than 120 kB, as compared to a less than 10 kB file for 256 kB pieces. F or large con tent in p articular, this migh t ha ve significant negat iv e implications for the W eb server us ed to d istribute suc h files to clien ts. Bitfield messages b eco me prop ortionately larger to o. F or instance, for the 100 MB cont en t, these messages are 805 and 55 b ytes for 16 and 256 kB pieces resp ectiv ely . Figure 6 add itionally sho ws the comm u nication o v erh ead d u e to bitfield and have messages, expressed as a p ercen tage of the total upload traffic p er p eer. The o v erhead ranges f r om less than 1% for larger piece sizes to around 9% for 16 kB pieces. Ho wev er, it is not clear th at this o verhead is r esp onsible for the w orse p erformance 16 32 64 128 256 512 1024 2048 0 500 1000 1500 Piece size (kB) Download completion time (s) Peer Performance (100 MB content) Figure 4 : Do wnload completion t imes for a 100 MB content (medians ov er 5 runs and stand ard deviation error bars). Smal l pie c es ar e no longer optimal. 16 32 64 128 256 512 1024 2048 0 20 40 60 80 100 120 Metainfo File Piece size (kB) File size (kB) Figure 5 : Metai nfo file sizes for distributing a 100 MB con- tent. Smal ler pie c es pr o duc e pr op ortionately lar ger files. of smaller p ieces. Although these con trol messages do o ccupy upload band width, they do n ot necessar- ily affect the data exc hange among p eers, and th us their do wn load p erformance. F or example, looking at the corresp on d ing ov erhead for smaller conte n t, w e observ e that the o verhead curve looks v ery sim- ilar. This indicates th at incr e ase d c ommunic ation overhe ad is most likely neither the c ause of the worse p erformanc e of smal l pie c es for lar ger c on- tent , nor do es it explain the obs er ved trade-off. In the next section, we form ulate t wo h yp otheses that migh t h elp identi fy the true cause of this b eha vior. In summary , w hen distributing larger conte n t, the optimal piece size dep ends on the cont en t size, due to a trade-off b et w een the increased paral- lelism s mall pieces pro vide and their dr a w bac ks. BitT orr ent ar gu ably attempts to addr ess this tr ade- off by further dividing pie c es into subpie c es , to get the b est of b oth wo rlds: subpieces in crease opp or- tunities for parallel do wnloading, wh ile p ieces m it- igate the dra w bac ks of sm all ve rifiable units. 4 Discussion The results pr esented in the p revious section p oin t to a hidden r eason b ehind the p oor p erformance of small pieces when distribu ting large con tent. W e ha v e t w o h yp otheses that migh t help explain th at. 16 32 64 128 256 512 1024 2048 0 2 4 6 8 Piece size (kB) Overhead percentage Communication Overhead Figure 6 : Comm unication ov erhead due to bitfield and have messages when distributing a 100 MB conten t. Smal l pie c es incur c onsider ably lar ger overhe ad. First, small pieces r e duc e opp ortunities for su b - pie c e r e quest pip elining . In order to prev en t dela ys due to request/resp onse latency , and to k eep the do wnload pip e full most of the time, most Bit- T orren t implement ations issue requests for several consecutiv e sub pieces bac k-to- bac k. This pip elin- ing, how ev er, is restricted within the b oundaries of a single piece. This is done in o rder to use a v ailable bandwidth to do wnload complete pieces as so on as p ossible, and share them with the rest of the sw arm. Similarly , p eers d o not t ypically issue a re- quest for subp ieces of another piece to the same p eer b efore completing the previous one. T h us, for a con tent with 32 kB pieces, for instance, only tw o subpiece requests p er p eer can b e p en d ing at an y p oint in time. F or small con tent, the imp act of reduced pip elining is negligible, as th e do wnload completes quic kly anyw ay . F or larger con tent , how- ev er, it might sev erely affect system p erformance, as it limits the total num b er of s im ultaneous re- quests a p eer can issue. Add itionally , this matter gains imp ortance as av ailable peer bandwidth rises, since the request/resp onse latency then starts to dominate time sp en t on data transmission. F ur thermore, small p ieces may incur slowdown due to TCP effe cts . With a small piece size, a giv en leec her is more lik ely to kee p s w itc h ing among p eers to do wnload different p ieces of the con ten t. T his could ha v e t w o adverse TCP-related effects: 1) the congestion window would hav e less time to ramp up than in th e case of do wnloading a large p iece en tirely from a s ingle p eer, and 2) the congestion windo w for unused p eer connections would grad- ually d ecrease after a p erio d of inactivit y , du e to TCP congestion wind o w v alidation [4], whic h is enabled by default in r ecen t Linux k ernels, su c h as the ones run ning on the PlanetLab mac hines in our exp eriments. A large piece size, on the other hand, would enable more efficien t TCP transfers due to the low er probabilit y of switc hing fr om p eer to p eer. Note, ho w ever, that, ev en in that case, there is no guaran tee that all subp ieces of a piece will b e do wn loaded fr om the same p eer. 5 Related W ork T o the b est o f our knowledge , this is th e fir st study that sys tematical ly inv estigates the optimal p iece size in BitT orrent. Bram Cohen, the protocol’s cre- ator, fir st d escrib ed BitT orrent’s main algorithms and their design rationale [6]. In v ersion 3.1 of the official implemen tation he redu ced the default piece size f rom 1 MB to 256 kB [2], alb eit without giv- ing a concrete r eason for doing so. Presumably , he noticed th e p erformance b enefits of smaller pieces. Some p revious researc h efforts hav e lo ok ed into the imp act of piece size in other p eer-to-p eer con- ten t distr ibution systems. Hoßfeld et al. [8] u sed sim ulations to ev aluate v ary in g piece sizes in an eDonk ey-based m obile fi le-sharing sys tem. They found that do wnload time decreases with piece size up to a certain p oin t, confir ming our observ ations, although they did not attempt to explain this b e- ha vior. T he authors of Dandelion [12] ev aluate its p erforman ce w ith d ifferen t piece size s, and ment ion TCP effects as a p oten tial reason for the p o or p er- formance of sm all pieces. Ho w ev er, small pieces in that system may also b e h armful b ecause th ey in- crease the r ate at whic h k ey requests are sent to the cen tr al s er ver. CoBlitz [10] faces a sim ilar problem with s m aller p ieces r equiring more pro cessing at CDN no d es. Th e auth ors end up c ho osin g a piece size of 60 kB, b ecause that can easily fit into the default Lin ux outb oun d k er n el so c k et buffers. T he Slurpie [11] authors b riefly allude to a piece size trade-off, an d mentio n TCP o v erhead as a dra w- bac k of small p ieces. Lastly , dur ing the ev aluation of the CREW system [7], the authors find a piece size of 8 kB to b e optimal for distributing a 800 kB con tent, but they do n ot attempt to explain that. 6 Conclusion This pap er presents results of real exp eriment s with v arying piece sizes on a con trolled BitT orren t testb ed. W e show that piece size is critical for p er- formance, as it determines the degree of parallel ism in the system. Our results explai n why small p ieces are the optimal c hoice for small-sized cont en t, and wh y fur ther dividing cont en t pieces in to subp ieces is unnecessary for such cont en t. W e also ev aluated the o v erh ead small pieces in cu r for larger con ten t, and discuss ed the design trade-off b et wee n p iece size and a v ailable p arallelism. It w ould b e in teresting to in v estiga te our t wo h y- p otheses r egardin g the p oor p erformance of small pieces with larger con tent. W e wo uld also like to extend our conclusions to different scenarios, suc h as video streaming, whic h imp oses additional real- time constrain ts on the proto col. Ac knowledgmen ts W e are grateful to Mic hael Sirivianos, Himabindu Pu c ha, and the anon ymous review ers for their v aluable feedback. References [1] BitT orr ent instrumented client. http:/ /www- sop .inria.fr/planete/Arnaud.Legout/Projec t s / p 2 p _ c d . h t m l # s o f t w a r e . [2] BitT orr ent mailing list: Poor Per- formance with V er sion 3.1? (po int 4), access ed o n January 2 4 , 2008. http:/ /tech .grou ps.yahoo.com/group/BitTorrent/messag e / 1 2 6 0 . [3] BitT orr ent sp ecification wiki. http:/ /wiki .theo ry.org/BitTorrentSpecification . [4] TCP Congestion Window V alidation. http:/ /www. ietf. org/rfc/rfc2861.txt . [5] A. Bavier, M. Bowman, B. Ch un, D. Culler, S. K ar- lin, S. Muir, L. Peterson, T. Rosco e, T. Spalink, and M. W awrzoniak. Oper ating System Supp ort for Planetary-Sca le Netw o rk Services. In NSDI’04 . [6] B. Cohen. Incentiv es Build Robustnes s in Bit- T orr ent. In P2PEc on ’03 . [7] M. Deshpande, B. Xing, I. Lazardis, B. Hore, N. V enk atasubramanian, and S. Mehr otra. CREW: A Gossip-ba s ed Flash-Disseminatio n System. In ICDCS’06 . [8] T. Hoßfeld, K. T utschku, and D. Sc hlosser. Influ- ence of the Size of Swapping En tities in Mobile P2P File-Sharing Netw orks. In Pe er-to-Pe er-Systeme und -Anwendungen ’05 . [9] A. Legout, N. Lio gk as, E. Kohler, and L. Zhang . Clustering and Sharing Incentiv es in BitT or rent Systems. In SIGMET RICS’07 . [10] K. Park a nd V. S. Pai. Sca le and Performance in the CoBlitz Large-File Distribution Service. In NSDI’06 . [11] R. Sherwoo d, R. Br aud, and B. Bhattacharjee. Slurpie: A Co oper ative Bulk Data T rans fer Pr o- to col. In INFOCOM’04 . [12] M. Sirivianos , J. H. P ark, X. Y ang, and S. J a recki. Dandelion: Co o p er ative Co nten t Distribution with Robust Incentiv es. In USENIX’07 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment