A greedy approach to sparse canonical correlation analysis
We consider the problem of sparse canonical correlation analysis (CCA), i.e., the search for two linear combinations, one for each multivariate, that yield maximum correlation using a specified number of variables. We propose an efficient numerical a…
Authors: Ami Wiesel, Mark Kliger, Alfred O. Hero III
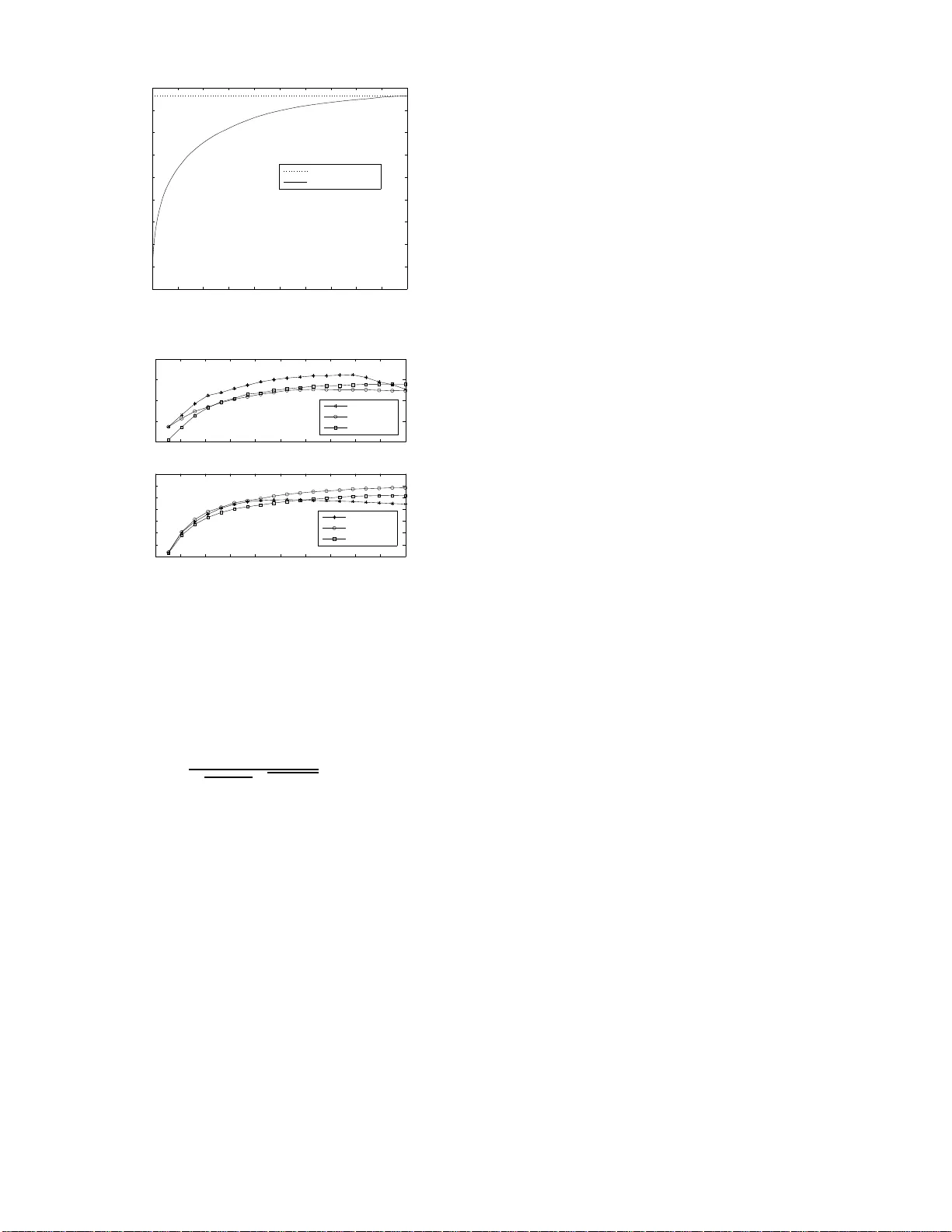
1 A greedy approach to sparse canonical correlation analysis Ami W iesel, Mark Kliger a nd Alfred O. Hero III Dept. of Electrical Enginee ring and Computer Science Univ ersity of Michigan , Ann Arbor , MI 481 09-2122, USA Abstract — W e consider the problem of sparse canonical corre- lation analysis (CCA), i.e., the searc h f or two linear combinations, one f or each multivariate, that yield m aximum corr elation usin g a specified number of variables. W e p ropose an efficient numerical approximation based on a direct gr eedy approach whi ch b ounds the correlation at each stage. The meth od is specifically designed to cope with lar ge data sets and its computational complexity depends only on the sparsity levels. W e analyze th e algorithm’ s perfo rmance t hrough th e tradeoff between correlation and par - simony . The results of n umerical simulation suggest that a significant portion of the cor relation ma y be captured usin g a relati vely small number of v ariables. In addition, we exam i ne the use of sparse CCA as a regularization method when the n umber of a vailable samples is small compar ed to the dimensions of the multivar iates. I . I N T R O D U C T I O N Canonical correla tion analysis (CCA), intro duced by Haro ld Hotelling [1 ], is a stand ard techniq ue in mu lti variate data anal- ysis for e x tracting common features from a pair of data s o urces [2], [3]. Each of these data so urces generate s a rand om vector that we call a multi variate. Unlike classi cal dimen sionality reduction metho ds which a ddress on e multivariate, CCA takes into accoun t the statis tica l relations between samples fro m two spaces of possibly different dimensions and stru cture. In particular, it searches for tw o linear comb inations, o ne for each multiv ariate, in order to maximize their correlation . It is used in dif fer ent disciplines as a stand-alo ne to ol or as a prepro cessing st ep for other statistical m ethods. Furthermore , CCA is a generalized fr amew o rk which includes numerous classical methods in statistics, e.g. , Principal Compone nt Analysis (PCA), Partial Least Squ ares (PLS) and Multiple Linear Regression (MLR) [4 ]. CCA has rec ently regained attention with the advent of kernel CCA and its application to indepen dent co mponen t analysis [5], [6]. The last decade h as witnessed a growing in terest in th e search for sparse representations of sign als and sp arse nu- merical me thods. Thus, we consider the problem of sparse CCA, i.e., th e search fo r linear comb inations with max imal correlation using a sm all number of variables. The quest for sparsity can be motiv a ted through various reasoning s. First is the ability to interp ret an d visualize the results. A small numb er of variables allows us to get the “big p icture”, while sacrificing som e of the small de tails. Moreover, sparse representatio ns enable the use of com putationally efficient The first two authors contrib uted equal ly to this manuscript. T his work was supported in part by an AFOSR MURI under Grant F A9550-06-1-0324. numerical methods, compression technique s, as well as n oise reduction algor ithms. The second m otiv ation for sparsity is regularization and stability . One of the m ain vulnera bilities of CCA is its sensitivity to a small num ber of ob servations. Thus, regularized methods such as ridge CCA [7] must be used . In this co ntext, sparse CCA is a subset selectio n scheme wh ich allows us to reduce the dimen sions of the vector s and obtain a stable solution. T o th e be st of our knowledge the first reference to sparse CCA ap peared in [2] wher e backward an d stepwise subset selection were prop osed. Th is discussion was of qualitative nature and no specific n umerical algorithm was propo sed. Recently , increa sing dem ands fo r m ultidimension al data pro- cessing and decreasing comp utational cost ha s caused the topic to rise to prominence once again [ 8]–[1 3]. Th e main disadvantages with the se curren t solutions is th at there is n o direct control over the sparsity and it is difficult (and non- intuitive) to select their optimal hyp erparame ters. I n addition, the computa tional c omplexity o f most of these method s is too high for p ractical app lications with h igh dimension al data sets. Sparse CCA has also been implicitly addressed in [9], [14] and is intimately related to the recent results o n sparse PCA [9], [15]– [17]. Indeed, our p roposed solution is an extension of th e results in [17] to CCA. The main contribution of th is work is twofo ld. First, we derive CCA algorith ms with d irect control over th e sparsity in each of the multi variates an d examine th eir perform ance. Our co mputation ally efficient methods ar e spe cifically a imed at u nderstand ing the relations betwee n two data sets of large dimensions. W e adopt a forward (or backward) greedy ap - proach which is based on sequentially p icking (or dr opping ) variables. At each stage, we bou nd the optimal CCA solution and bypass the need to resolve the full p roblem . Moreover , the co mputatio nal c omplexity of the forward gre edy meth od does no t depe nd on the dimen sions of the data but o nly on the sparsity parameters. Numer ical simu lation results show that a significant portion of the correlation can be ef ficiently captured using a re lati vely lo w number of non-zero coefficients. Our second contr ibution is in vestigation of sparse CCA as a reg- ularization method . Using empirical simu lations we examin e the u se of the different algo rithms when the dimen sions of the multi variates are larger than (or of the s ame order of) the numb er o f samp les and demon strate th e advantage of sparse C CA. In this context, one of th e adv an tages of the greedy approach is that it generates the full sp arsity p ath in a single run and allo ws for efficient parameter tuning using 2 cross validation. The paper is o rganized as follows. W e begin b y describing the standa rd CCA form ulation an d solution in Section II. Sparse CCA is add ressed in Section III where we review th e existing approaches and derive the propo sed g reedy method. In Section IV, we provide performan ce analy sis using nu merical simulations and a ssess the tradeoff between correlation and parsimony , as well as its use in regularization. Finally , a discussion is provided in Section V. The follo win g no tation is used. Boldface upp er case letters denote matric es, bo ldface lower case letters denote column vectors, and standard lower case letters deno te scalars. The superscripts ( · ) T and ( · ) − 1 denote th e tra nspose and in verse operator s, respectively . By I we denote th e identity matrix. The op erator k · k 2 denotes th e L 2 no rm, an d k · k 0 denotes th e cardinality operator . F or two sets of indices I and J , the matrix X I ,J denotes th e submatr ix of X with the ro ws in dexed b y I and colum ns indexed by J . Fina lly , X ≻ 0 o r X 0 means that the matrix X is positive definite or p ositiv e semidefinite, respectively . I I . R E V I E W O N C C A In this sectio n, we pr ovide a revie w of classical CCA. Let x and y be two zero mean random vecto rs of le ngths n and m , respectively , with joint covariance matrix: Σ = Σ x Σ xy Σ T xy Σ y 0 , (1) where Σ x , Σ y and Σ xy are the cov a riance of x , the covariance of y , and their cross covariance, respectively . CC A consider s the problem of finding two linear com binations X = a T x and Y = b T y with maximal correlatio n defined as cov { X, Y } p var { X } p var { Y } , (2) where var {·} an d cov {·} are the variance and covariance operator s, resp ectiv ely , and we define 0 / 0 = 1 . In terms of a and b the correlation can b e easily expressed as a T Σ xy b p a T Σ x a p b T Σ y b . (3) Thus, CCA considers the following optimizatio n pro blem ρ ( Σ x , Σ y , Σ xy ) = max a 6 = 0 , b 6 = 0 a T Σ xy b p a T Σ x a p b T Σ y b . (4) Problem (4) is a multidimensional non-co ncave m aximization and therefo re app ears difficult on first sig ht. Howe ver, it has a simp le closed f orm so lution v ia the genera lized eigenv alue decomp osition (GEV D). Indeed, if Σ ≻ 0 , it is easy to show that the optimal a and b mu st satisfy: 0 Σ xy Σ T xy 0 a b = λ Σ x 0 0 Σ y a b , (5) for some 0 ≤ λ ≤ 1 . Thus, the op timal value of (4 ) is just the principal gen eralized eigen value λ max of the p encil (5) and the optimal solution a and b can be o btained by approp riately partitioning the associated eig en vector . These solu tions are in variant to scaling of a and b and it is customar y to norm alize them s uch that a T Σ x a = 1 and b T Σ y b = 1 . On the other hand, if Σ is rank deficient, then choo sing a and b as the upper and lower partitions of any vector in its nu ll spac e will lead to full correlation, i.e., ρ = 1 . In practice, the covariance matrices Σ x and Σ y and cross covariance m atrix Σ xy are usually unavailable. I nstead, mul- tiple in depend ent observations x i and y i for i = 1 . . . N are measured and used to constru ct sample estimates of the (cr oss) covariance matrices: ˆ Σ x = 1 N X T X , ˆ Σ y = 1 N X T Y , ˆ Σ xy = 1 N X T Y , (6) where X = [ x 1 . . . x N ] and Y = [ y 1 . . . y N ] . Then , these empirical matrices are used in th e CCA formulation: ρ ˆ Σ x , ˆ Σ y , ˆ Σ xy = max a 6 = 0 , b 6 = 0 a T ˆ Σ xy b p a T ˆ Σ x a q b T ˆ Σ y b . (7) Clearly , if N is sufficiently large then t his sample approach perfor ms well. Howev er, in many application s, the nu mber of samples N is not sufficient. In fact, in the extreme case in which N < n + m th e sam ple cov arian ce is rank d eficient an d ρ = 1 in depend ently of the data. The standard app roach in such cases is to regularize the covariance matrices and solve ρ ˆ Σ x + ǫ y I , ˆ Σ y + ǫ x I , ˆ Σ xy where ǫ x > 0 a nd ǫ x > 0 a re small tuning ridge parameters [7]. CCA can b e viewed as a unified framew or k fo r d imensional- ity reduction in mu lti variate data analysis an d generalizes o ther existing m ethods. It is a g eneralization of PCA which seeks th e directions th at maximize the variance of x , and addresses the directions correspon ding to the corr elation between x and y . A special case of C CA is PLS which maximizes the covariance of x an d y (which is equiv a lent to choosing Σ x = Σ y = I ). Similarly , M LR normalizes on ly one of the mu lti variates. In fact, the regularized CCA mention ed above can b e interpreted as a combination of PL S and CCA [4]. I I I . S PA R S E C C A W e consider the pr oblem of spar se CCA, i.e. , fin ding a p air of linear combinatio ns of x and y with prescribed card inality which ma ximize the correlation. Ma thematically , we define sparse CCA as the solution to max a 6 = 0 , b 6 = 0 a T Σ xy b √ a T Σ x a √ b T Σ y b s.t. k a k 0 ≤ k a k b k 0 ≤ k b . (8) Similarly , sparse PL S and sparse MLR are defined as special cases of ( 8) by choo sing Σ x = I and /or Σ y = I . In gene ral, all of these pro blems are difficult com binatorial prob lems. In small dimensions, they can be solved using a brute fo rce search over all po ssible sparsity p atterns and solvin g the a s- sociated subproblem v ia GE VD. Unfortunately , this approach is impractical for ev en moderate sizes o f d ata sets due its exponentially increasing computational complexity . In fact, it is a gener alization o f sparse PCA which h as been proven NP- hard [17 ]. T hus, sub optimal but e fficient a pproach es are in order and will be discussed in th e rest of th is section. 3 A. Existing solutions W e now briefly revie w the different approaches to sparse CCA that a ppeared in th e last f ew years. Most of th e methods are based on the well known LASSO trick in which the difficult comb inatorial cardinality constraints a re approximated throug h the conv ex L1 norm. This ap proach has shown promis- ing per forman ce in the con text of sparse linear regression [18]. Unfor tunately , it is no t sufficient in th e CCA formulation since the objective itself is n ot co ncave. Thus add itional approx imations are requ ired to tr ansform the problems into tractable form. Sparse dime nsionality reduction of rectan gular matrices was con sidered in [9] by co mbining the LASSO trick with semidefinite relax ation. I n our context, th is i s exactly sparse PLS which is a special case of sparse CCA. Altern ati vely , CCA can be form ulated as two constrained simultaneous regressions ( x on y , and y o n x ). Th us, an ap pealing a pproach to sp arse CCA is to use LASSO penalized regression s. Based on th is idea, [8] proposed to approximate th e non con vex con straints using the in finity norm. Similar ly , [10], [11] pr oposed to use two nested iterati ve LASSO type regressions. There are two main disadvantages to the LASSO based technique s. First, there is no math ematical justification for their approximatio ns of the correlation objecti ve. Second, t h ere is no d irect con trol over sparsity . Their p arameter tunin g is difficult as the r elation between the L1 norm and the sparsity parameters is hig hly nonlinear . The algo rithms need to be run for each po ssible value of the param eters and it is tedio us to obtain the full sparsity path. An alterna ti ve appro ach f or sparse CCA is sparse Bayes learning [12], [13 ]. The se meth ods are based o n the prob - abilistic interpretation of CCA, i.e., its formulation a s an estimation problem. It was shown that using different prio r probab ilistic m odels, spar se solutions can be obtain ed. The main disad vantage of this appro ach is again the lack of d irect control on sparsity , and the difficulty in obtainin g its complete sparsity path. Altogether, these works dem onstrate th e g rowing interest in deriving efficient sparse CCA algorithm s aimed at large data sets with simple and intuiti ve parameter tuning. B. Gr eedy appr oach A stand ard ap proach to comb inatorial problem s is the for- ward (backward) greedy solu tion which sequentially picks (or drops) the variables at each stage on e by on e. The backward greedy approach to CCA was proposed in [2 ] b u t no specific algorithm was deri ved or analyzed. In modern applications, the number of d imensions may be mu ch larger than the number of samples and the refore we p rovide the details of the more natural forward strategy . Noneth eless, the backward ap proach can be deri ved in a straigh tforward manner . In addition , we derive an efficient appr oximation to the sub problem s at each stage wh ich significantly reduces the compu tational comp lex- ity . A similar approach in the co ntext of PCA can be found in [17]. Our goal is to find the two sparsity pa tterns, i.e., two sets of ind ices I and J corresponding to the indice s of the chosen variables in x and y , resp ectiv ely . The greedy algor ithm chooses the first elements in b oth sets as the so lution to max i,j Σ i,j xy p Σ ii x q Σ j j y . (9) Thus, I = { i } and J = { j } . Next, th e algorithm sequentially examines all the re maining indices and computes max i / ∈ I ρ Σ I ∪ i,I ∪ i x , Σ J,J y , Σ I ∪ i,J xy (10) and max j / ∈ J ρ Σ I ,I x , Σ J ∪ j,J ∪ j y , Σ I ,J ∪ j xy . (11) Dependin g o n whether (10) is gr eater or less than (11), we add ind ex i or j to I or J , respectiv e ly . W e emphasize that at each stag e, o nly one ind ex is added either to I or J . Once one of the set reac hes its r equired size k a or k b , the algorithm continues to add indices o nly to the oth er set and terminates when this set rea ches its required size as well. It ou tputs the full sp arsity p ath, a nd returns k a − k b − 1 p airs of vectors associated with the sparsity patterns in each of the stages. The com putation al complexity of the alg orithm is poly - nomial in the dimen sions of the problem . At each of its i = 1 , · · · , k a + k b − 1 stages, the algor ithm comp utes n + m − i CCA solutions as expressed in (10) and (1 1) in order to select the pattern s fo r the n ext stage. It is th erefore reasonable f or small problems, but is still impractical for many applications. Instead, we now propose an alternative approa ch that compu tes only one CCA p er stage an d reduces the complexity sig nificantly . An app roximate greedy solution can be easily obtained by approx imating ( 10) and ( 11) instead of solving the m exactly . Consider f or example (1 0) wh ere index i is added to the set I . Let a I ,J and b I ,J denote the op timal solution to ρ Σ I ,I x , Σ J,J y , Σ I ,J xy . In ord er to e valuate (10) we need to recalculate both a I ∪ i,J and b I ∪ i,J for each i / ∈ I . Howe ver, the previous b I ,J is of the same d imension and still fe asible. Thus, we can o ptimize only with respec t to a I ∪ i,J (whose di- mension has increased). This appro ach p rovides the fo llowing bound s: Lemma 1: Let a I ,J and b I ,J be the op timal so lution to ρ Σ I ,I x , Σ J,J y , Σ I ,J xy in (4). Then, ρ 2 Σ I ∪ i,I ∪ i x , Σ J,J y , Σ I ∪ i,J xy ≥ ρ 2 Σ I ,I x , Σ J,J y , Σ I ,J xy + δ I ,J i ρ 2 Σ I ,I x , Σ J ∪ j,J ∪ j y , Σ I ,J ∪ j xy ≥ ρ 2 Σ I ,I x , Σ J,J y , Σ I ,J xy + γ I ,J j , (12) where δ I ,J i = b I ,J T Σ I ,J xy T Σ I ,I x − 1 Σ I ,i x − b I ,J T Σ i,J xy T 2 Σ i,i x − h Σ I ,i x i T h Σ I ,I x i − 1 Σ I ,i x γ I ,J j = a I ,J T Σ I ,J xy Σ J,J y − 1 Σ J,j y − a I ,J T Σ I ,j xy 2 Σ j,j y − h Σ J,j y i T h Σ J,J y i − 1 Σ J,j y , ( 13) 4 and we assume that all the in volved matrix in versions are nonsingu lar . Before proving th e lemma, we note that it pr ovides lower bound s on the in crease in cross cor relation d ue to including an add itional elemen t in x or y without the need o f solving a full GEVD. T hus, we p ropose th e fo llowing approx imate greedy appro ach. For each sparsity pattern { I , J } , one CCA is comp uted via GEVD in order to ob tain a I ,J and b I ,J . Then, the n ext sparsity pattern is o btained by addin g the eleme nt that maximizes δ I ,J i or γ I ,J j among i / ∈ I and j / ∈ J . Pr oof: W e b egin b y rewriting (4) as a quadra tic ma xi- mization with constraints. Thus, we define a I ,J and b I ,J as the solution to ρ Σ I ,I x , Σ J,J y , Σ I ,J xy = max a , b a T Σ I ,J xy b s.t. a T Σ I ,I x a = 1 b T Σ J,J y b = 1 . (14) Now , con sider the problem when we add variable j to the set J : ρ Σ I ,I x , Σ J ∪ j,J ∪ j y , Σ I ,J ∪ j xy = max a , b a T Σ I ,J ∪ j xy b s.t. a T Σ I ,I x a = 1 b T Σ J ∪ j,J ∪ j y b = 1 . (15) Clearly , the vector a = a I ,J is still feasible ( though n ot necessarily optimal) and yields a lo wer boun d: ρ Σ I ,I x , Σ J ∪ j,J ∪ j y , Σ I ,J ∪ j xy ≥ ( max b a I ,J T Σ I ,J ∪ j xy b s.t. b T Σ J ∪ j,J ∪ j y b = 1 . (16) Changing variables b = Σ J ∪ j,J ∪ j y 1 2 b results in: ρ Σ I ,I x , Σ J ∪ j,J ∪ j y , Σ I ,J ∪ j xy ≥ max b c T b s.t. k b k 2 = 1 , (17) where c = Σ J ∪ j,J ∪ j y − 1 2 Σ I ,J ∪ j xy T a I ,J . (18) Using the Cauchy Schw artz inequality c T b ≤ k c k 2 k b k 2 , (19) we obtain ρ Σ I ,I x , Σ J ∪ j,J ∪ j y , Σ I ,J ∪ j xy ≥ Σ J ∪ j,J ∪ j y − 1 2 Σ I ,J ∪ j xy T a I ,J 2 . (20) Therefo re, ρ 2 Σ I ,I x , Σ J ∪ j,J ∪ j y , Σ I ,J ∪ j xy ≥ a I ,J T Σ I ,J xy Σ I ,j xy × Σ J,J y Σ J,j y Σ J,J y Σ J,j y − 1 " Σ I ,J xy T Σ I ,j xy # T a I ,J . (21) Finally , (12) is obtained by using the in version formu la for partitioned matrices and simplifying the terms. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1 percentage of non−zero coefficients ρ forward CCA backward CCA full search CCA Fig. 1. Correlation vs. Sparsity , n = m = 7 . I V . N U M E R I C A L R E S U LT S W e now provide a few numerical examples illustrating the behavior of the greedy s parse CCA method s. In all of the simulations below , we implement the greed y methods using the bou nds in Lemm a 1. In the first experiment w e ev aluate the v alid ity of the approxim ate gr eedy a pproach . In particular, we ch oose n = m = 7 , an d ge nerate 2 00 independ ent rand om realizations of the joint covariance matrix using the W ishart distribution with 7+ 7 degrees of freedom. For each realization, we ru n the approximate gre edy forward a nd bac kward a lgo- rithms a nd calculate the fu ll sparsity path . For comp arison, we also compute the op timal sparse solutions u sing an exhau sti ve search. The results are pr esented in Fig. 1 where the average correlation is plotted as a fun ction of th e n umber of v aria bles (or n on-zer o coefficients). The greedy methods capture a significant po rtion of the possible co rrelation. As expected , the forward greedy ap proach outpe rforms the backward metho d when hig h sparsity is critical. On the other ha nd, the backward method is p referab le if large values of correlatio n are re quired. In the secon d experiment we dem onstrate the perfor mance of the app roximate fo rward greedy a pproach in a large scale problem . W e present re sults for a representative (ra ndomly generated ) cov arian ce matrix o f sizes n = m = 1000 . Fig. 2 shows the full sparsity path of the greed y method. It is easy to see that about 90 perce nt of the CCA correlation v alu e can be captu red using o nly half o f the variables. Fur thermor e, if we ch oose to cap ture on ly 80 percen t of the full corr elation, then about a quarter o f the v ar iables are suf ficient. In the third set o f simu lations, we examine the u se of spar se CCA alg orithms as regularization method s when the numbe r of samples is n ot sufficient to estimate the covariance matrix efficiently . For simplicity , we restrict our attention to CCA an d PLS (wh ich can be interpreted as an extreme case of r idge CCA). In additio n, we show results for an alterna ti ve m ethod in which the samp le cov a riance ˆ Σ x and ˆ Σ y are appro ximated as diagonal matrices with the sample variances (which are easier to estimate) . W e r efer to this method as Diagon al CCA (DCCA). In order to assess the regulariza tion pro perties o f CCA we used the following procedu re. W e randomly g enerate a single “true” cov ar iance ma trix Σ and use it th rough out all the simulations. Then, we gene rate N r andom Gaussian samples o f x and y and estimate ˆ Σ . W e app ly the th ree 5 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 percentage of non−zero coefficients ρ full CCA forward CCA Fig. 2. Correlation vs. Sparsity , n = m = 1000 . 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.25 0.3 0.35 0.4 0.45 Percentage of non−zero variables Correlation ρ sparse CCA sparse DCCA sparse PLS 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.2 0.25 0.3 0.35 0.4 0.45 0.5 Percentage of non−zero variables Correlation ρ sparse CCA sparse DCCA sparse PLS Fig. 3. Sparsity as a regulari zed CCA m ethod, n = 10 , m = 10 and N = 20 . approx imate greedy sparse a lgorithms, CCA, PLS and DCCA, using the s a mple covariance and obtain the estima tes ˆ a and ˆ b . Finally , our pe rforman ce measur e is the “tru e” corr elation value associated with the estimated weigh ts which is defin ed as: ˆ a T Σ xy ˆ b p ˆ a T Σ x ˆ a q ˆ b T Σ y ˆ b . (22) W e then repe at the above procedure (using the same “true” covariance m atrix) 500 times and present the a vera ge v alu e of (22) over th ese Monte Carlo trials. Fig. 3 p rovides th ese av er ages as a function o f par simony f or two representativ e realizations of the “ true” covariance matrix . Examinin g the curves reveals th at variable selection is indee d a pr omising regularization strategy . The a verage correlation in creases with the num ber of variables until it reaches a p eak. After this pe ak, the num ber of samp les are no t sufficient to estimate the full covariance and it is b etter to r educe the number of variables throug h sparsity . DCCA can also be sligh tly improved by u sing fewer variables, and it seems that PLS p erform s best with no subset selection. V . D I S C U S S I O N W e co nsidered the p roblem of sparse CCA an d discussed its implementatio n aspects an d statistical properties. In particular , we deri ved dire ct gr eedy m ethods which are specifically designed to cope with lar ge data sets. Similar to state of the art spar se regression methods, e.g ., Least Angle Regression (LARS) [19], the alg orithms allo w for direct control over the sparsity and provid e the full sp arsity path in a single run. W e have demonstrated their performan ce ad vantage through numerical simulations. There are a few interesting dir ections f or future resear ch in sparse CCA. First, we h av e on ly addr essed the first order sparse ca nonical co mpon ents. In many app lications, analysis of higher order canonical components is pr eferable. Numer - ically , this extension can be implemented by subtracting the first c ompon ents and reru nning the algo rithms. Howev e r , there remain intere sting theo retical q uestions r egarding th e relation s between the sparsity patterns of the different compo nents. Second, while here we consider ed the case of a pair of mul- ti variates, it is possible to genera lize th e setting and addr ess multiv ariate correlations between more th an two data sets. R E F E R E N C E S [1] H. Hotell ing, “Re lations between two sets of variat es, ” B iometrik a , vol. 28, pp. 321–377, 1936. [2] B. Thompson, Canonic al correlat ion ana lysis: uses and inte r pre tation . SA GE publi cations, 1984. [3] T . Anderson, An Intr oduction to Multiva riate Statistica l Analysis , 3rd ed. W iley-Inte rscience, 2003. [4] M. Borga, T . Landel ius, and H. Knutsson, “ A unifie d approach to PCA, PLS, MLR and CCA, ” Report LiTH-ISY -R-1992, ISY , Nove m ber 1997. [5] F . R. Bach and M. I. Jorda n, “Ke rnel independent component analysis, ” J . Mach. Learn. Res. , vo l. 3, pp. 1–48, 2003. [6] A. Gretton, R. Herbrich, A. Smola, O. Bousquet, and B. Sch ¨ olko pf, “K ernel methods for measuring indepen dence, ” J. M ach. Learn. Res. , vol. 6, pp. 2075–2129, 2005. [7] H. D. Vi nod, “Ca nonical ridge a nd econ ometrics of joint product ion, ” J ournal of Econometrics , vol. 4, no. 2, pp. 147–166, May 1976. [8] D. R. Har doon and J. Shawe-T aylor , “ Sparse cano nical correlation analysi s , ” Uni versity Coll ege London, T echnic al Report, 2007. [9] A. d’Aspremont, L. E. Ghaoui, I. Jorda n, and G. R. G. Lanckriet, “ A direct formulation for sparse PCA using semidefinite programming, ” in Advances in Neural Information Pr ocessing Systems 17 . Cambridge , MA: MIT Press, 2005. [10] S. W aaijenbor g and A. H. Zwinderman, “Penalized canonica l correla tion analysi s to quanti fy the association between gene expre ssion and DNA marker s, ” B MC Pr oceedings 2007, 1(Suppl 1):S122 , D ec. 2007. [11] E. Parkho menko, D. Tri tchler , and J. Be yene, “Genome-wide sparse canonic al corre lation of gene expression with genotypes, ” BMC Pro- ceedi ngs 200 7, 1(Suppl 1):S119 , Dec. 2007. [12] C. Fyfe and G. Leen, “T wo meth ods for sparsifying probabi listic canonic al c orrelation analysis, ” in ICONIP (1) , 2006, pp. 361–370. [13] L. T an and C. Fyfe, “Sparse kernel ca nonical correla tion analysis, ” in ESANN , 2001, pp. 335–340. [14] B. K. Srip erumbud ur , D. A. T orres, and G. R. G. Lanckri et, “Sparse eigen methods by D.C. programming, ” in ICML ’07: Pr oceedin gs of the 24th in ternational confer ence on Machine learn ing . Ne w Y ork, NY , USA: A CM, 2007, pp. 831–8 38. [15] H. Zou, T . Hastie, and R. Tibshiran i, “Sparse principa l compone nt analysi s , ” J ournal of Computat ional; Graphical Statistics , v ol. 15, pp. 265–286(22) , June 2006. [16] B. Moghadd am, Y . W eiss, and S. A vidan, “Spectral bo unds for sparse PCA: E xact and gre edy algorithms, ” in A dvances in Ne ural Informatio n Pr ocessing Systems 18 , Y . W eiss, B. Sch ¨ olk opf, and J. Platt, Eds. Cambridge , MA: MIT Press, 2006, pp. 915–922. [17] A. d’Aspremont, F . Bach, and L. E. Ghaoui, “Ful l regu larization path for sparse principal compone nt analysis, ” in ICML ’07: Pr oceedings of the 24th internation al co nferenc e on Mac hine learning . Ne w Y ork, NY , USA: ACM , 2007, pp. 177–184. [18] R. Tibshi rani, “Regression shrinkage and selection via the lasso, ” J. Roy . Statist . Soc. Ser . B , vol. 58, no. 1, pp. 267–288, 1996. [19] B. Efron, T . Hastie, I. Johnstone, and R. T ibshirani, “Least angle regre ss ion, ” Annals of Statist ics (wi th discussion) , vol. 32, no. 1, pp. 407–499, 2004.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment