Adaptive Independent Metropolis-Hastings by Fast Estimation of Mixtures of Normals
We construct an adaptive independent Metropolis-Hastings sampler that uses a mixture of normals as a proposal distribution. To take full advantage of the potential of adaptive sampling our algorithm updates the mixture of normals frequently, starting…
Authors: P. Giordani, R. Kohn
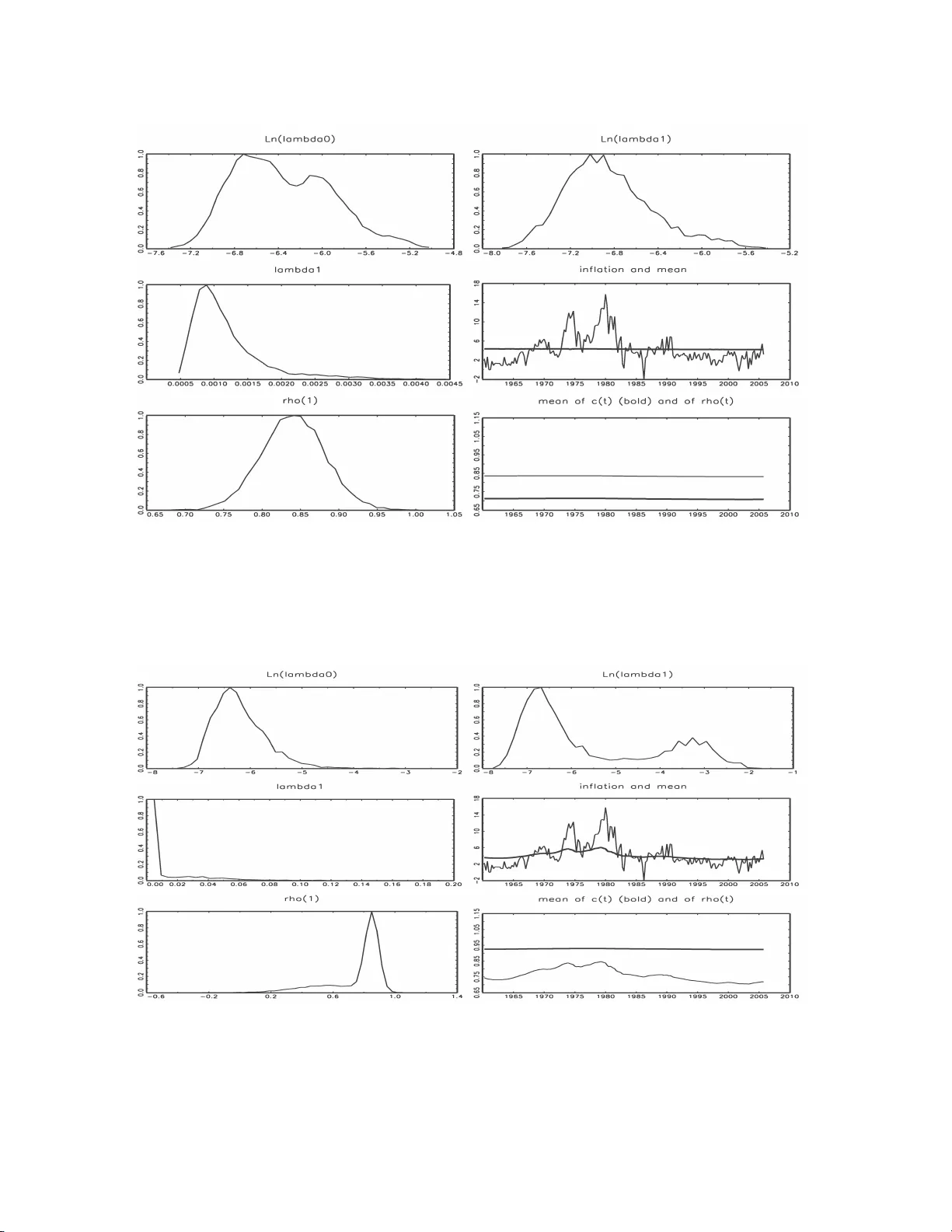
Adaptiv e Indep enden t Metrop o lis-Hastings b y F ast Estimatio n of Mixtures of Norm als P aolo Giordani Researc h D epartmen t, Sve riges Riksbank paolo.giordani@riksbank.se Rob ert Kohn Australian Sc ho ol of Busines s Univ ersit y of New South W ales Octob er 31, 2018 Abstract Adaptive Metrop olis-Hastings samplers use info r mation obta ined from previous draws to tune the pro posa l distribution automatica lly and rep eatedly . Adaptation needs to be done car efully to ensur e conv ergence to the correct ta r get distribution beca use the resulting chain is no t Markovian. W e construct an a daptiv e indep enden t Metro p olis- Hastings sampler that uses a mixture of normals a s a pro posa l distribution. T o take full adv antage of the potential of adaptive sampling our algorithm up dates the mixture of normals frequently , starting early in the chain. The algorithm is built for speed and reliability and its sampling p erformance is e v aluated with real a nd simulated exa mples. Our a rticle outlines co nditions for adaptive sampling to hold and g iv es a r eadily ac- cessible pro of that under these co nditions the sampling scheme g enerates iter ates that conv erge to the target distr ibution. Keyw ords : Clustering; Gibbs sa mpling; Markov c hain Monte Carlo ; Semiparamet- ric r egression mo dels; State s pa ce mo dels. 1 In tro duction Ba yesian metho ds using Mark o v c hain Mon te C arlo (MCMC) sim ulation hav e greatly influ- enced statistical and econometric pr acti ce ov er the past fifteen y ears b ecause of their abilit y to estimate complex mo dels and pr o du ce finite sample inference. A key comp onen t in im- plemen ting MCMC simulatio n is the Metrop olis-Ha stings (MH) metho d (Metrop olis et al. 1953; Hastings 197 0 ), whic h requires the sp ecification of one or more prop osal distributions. The sp eed at wh ich the c hain con verges to the p osterior distribution and its abilit y to mo v e efficien tly across the state sp ace dep end crucially on w h ether the prop osal d istribution(s) pro vide go od appro ximations to the ta rget distrib utions, either locally or globally . Giv en the k ey role p la yed by prop osal distrib u tions, it is natural to u se exp erience f r om p reliminary 1 runs to tune or adap t the prop osal to the target. W e define strict adaptatio n as adaptation that is sub ject to theoretical rules whic h ensure th at the iterates con ve rge to realizatio ns from the correct target (p osterior) distribu tion. All other adaptation of the MH k ern el w ill b e called pr eliminary adaptation, whose pur p ose is either to obtain an adequate prop osal densit y b efore switc hing to non-adaptiv e MCMC sampling, or as the starting p oin t for strict adaptiv e sampling. Despite the different theoretical requirement s of p reliminary an d strict adaptat ion, a great deal of care is needed in constructing b oth t yp es of adaptive sampling sc hemes b ecause the u ltimate goal is to obtain reliable estimates of functionals of the target d istribution as quic kly as p ossible. The literature on adaptive MCMC method s follo ws t wo main strands. Adaptation b y r e gener ation stems from the w ork of Gilks et al. (1998). Ou r article fo cuses exclu- siv ely on diminishing adap tation s c hemes. Imp ortan t theoretical adv ances in dimin ishing adaptation were made b y Holden (1998), Haario et al. (2001), Andrieu an d Rob ert (2001), Andrieu and Moulines (20 06 ), Andrieu et al. (2005), A tc h ad ´ e and Rosen thal (2 005 ), Not t and Kohn (2005) an d Rob erts and Rosenthal (2007). The p ro ofs of conv ergence for st rict adaptiv e sampling are more complex than for the non adap tive case as the iterates are not Mark o- vian b ecause the MH k ernel can dep end on the entire history of the dra ws. Although more theoretical w ork on adaptiv e sampling can b e exp ected, the existing b o dy of results pro- vides sufficient justifi cation and guidelines to build adap tive MH samplers for c hallenging problems. Researc h is no w needed on ho w to d esign efficien t and reliable adaptiv e samplers for broad classes of problems. Th is more applied lit erature mostly fo cuses o n random w alk Metrop olis, see for example R ob erts and Rosen thal (2006). P artial exceptions are G ˚ asem yr (2003) who uses normal pr oposals for an indep end en t Metrop olis-Hastings, but limits the tuning of the parameters to the burn-in p erio d, and Hastie (2005), who mixes random w alk and indep end en t MH in reversible jump problems, in wh at w e call t w o step adaptation in section 2. I ndep enden t MH schemes are implemente d by Nott and Kohn (2005) to sample 2 discrete state sp aces in v ariable selectio n p roblems (e.g. to learn if a v ariable is in or out), and b y Giordani and Kohn (2008) to learn ab out inte rven tions, such as br eaks or outliers, in dyn amic mixture mo dels. Our pap er co ntributes to the dev elopment o f b oth preliminary and strict alg orithms for adaptiv e indep endent MH samp ling in con tinuous state spaces. In creased samp lin g ef- ficiency is ob viously one imp ortan t goal, particularly in cases where cur ren t b est practice (t ypically some v ersion of random w alk Metrop olis or Gibbs sampling) is less than satisfac- tory . But equally imp ortant ac hiev emen ts of adaptiv e sc hemes may b e to expand the set of problems that can b e h andled efficiently b y general purp ose samplers and to reduce cod ing effort. In particular, adaptive sc hemes can r educe dep endence on th e use of conjugate pr i- ors. Such priors make it easier to implemen t MCMC sc h emes, but are less necessary when using adaptive sampling. Our adaptiv e sampling approac h is built on fo ur main idea s. The firs t is to c ombine preliminary and strict adaptation in to one estimati on pr ocedur e. The second is to estimate mixtures o f Ga uss ians from the history of the draws and us e them as prop osal distribu- tions for indep enden t MH in b oth parts of the adaptation. The th ir d is to perform this estimation frequent ly , particularly d uring the pr eliminary adaptation stage, a strategy we call intensive adaptation . The fourth is to ensure that the theoretica l conditions for the correct ergod ic b ehavio r of the sampler are resp ected during strict adaptation. T o app ly these ideas successfully , estimation of the mixtur e parameters needs to b e fast, reliable, and robust. W e achiev e a go o d balance of these goals by carefully selecting and tailoring to our needs algorithms dev elop ed in the clustering literature. W e study the p erform an ce of our adaptive sampler in three examples in whic h commonly used Gibbs sc hemes can b e ve ry inefficien t and compare it with an adaptiv e random walk Metrop olis sampler prop osed by Rob erts and Rosen thal (2006) that builds on the work . Our pap er also pro vid es co nd itions and outlines a pr o of that our strict adaptiv e samp ling sc heme con verges to the correct target distribu tion and giv es con v ergence r ates. 3 2 Tw o-step adaptation and in tensiv e adaptation A necessary cond itio n for a successful adap tive indep endent Metrop olis-Ha stings (AIMH) sampler is t hat, giv en a sizable sample dra wn from the ta rget π ( z ), the suggested al go- rithm can build a prop osal q ( z ) whic h is sufficiently close to the target for IMH to p erform adequately . A t wo- step adaptiv e strategy is also feasible w h enev er th e answer is p ositiv e. W e loosely define two -step adap tation as a samp ling scheme in whic h a r ather thorough exploration of the target d ensit y is carried out in the fi rst part of the c hain by a sampler other than IMH (such as random w alk Metrop olis) b efore switching to a more efficien t IMH sampler with prop osal den s it y tuned on the first-stage draws. An early version of suc h a t w o-step pro cedu re is p rop osed by Gelman and Rubin (1992). Hastie (2005) pro vid es an in teresting application to reve rsib le jump pr ob lems. Tw o-step adaptation is r ela tiv ely simple and safe and in some cases is capable of ac hiev- ing sizable efficiency gains. Ho wev er, it has the follo wing limitatio ns. First, if the first stage sampler fails to adequately explore a regio n of the state space, the prop osal built for the second stage will also inadequately cov er that region. T o redu ce this risk we ma y need a v ery large num b er of iterations in the fir st phase, whic h ma y b e particularly time consuming if the first stage sampler is inefficien t. Second, there ma y b e no sa ving of co ding effort if th e first stage sampler generates from sev eral conditional distributions, as in Gibb s or Metrop olis-within-Gibbs, in order to b e efficien t. W e lo osely defin e intensive adaptation as an AIMH scheme in whic h th e prop osal d is- tribution is up dated frequ en tly , particularly in the early part of the chain. Building a sequence of increasingly goo d prop osal densities in inte nsive adaptation is more demand ing than build ing a prop osal densit y once based on thousands of dra ws. The question is wh ether w e can adequately explore the t arget distr ib utions give n an initial p r op osal g 0 ( z ) bu t no dra ws. The a nswer inevitably dep ends on th e initial prop osal g 0 ( z ), on the target π ( z ), and on the details of th e samp lin g scheme. Ho wev er, it is p ossible to outline some general dangers and opp ortunities offered b y in tensive adaptation. Among the adv anta ges, if the prop osal distrib u tion is sufficien tly flexible, frequen t tuning 4 of its parameters and contin uin g adaptation for the entire length of th e c hain redu ces the risk of a long r un of r eject ions and incr eases the c hances of go od p erformance wh en the initial prop osal approxi mates the target p o orly . Estimating prop osal densities based on a small num b er of d ra ws presen ts some dangers that th e designer of an AIMH scheme should try to m inimize. F or example, supp ose that w e predetermine the iteration, sa y j , at whic h the prop osal is first u p dated. If the first j dra ws ha ve all b een rejected, then a prop osal d istribution based ent irely on these dra ws is degenerate and mak es the c hain reducible. If to o few dra ws ha v e b een accepted, the prop osal ma y b e very p o or. W e employ the follo wing strategy to pr ev ent these outcomes. First, w e initially up d ate the prop osal at a p r edetermined n umb er of ac c epte d dr a ws. Second, after fitting a mixture of normal distributions to past d ra w s , we fatten and stretc h its tails by creating a mixtur e of mixtures a s describ ed in section 3. Thir d , w e let the proposal b e a m ixtu re where one comp onent is the initial pr oposal g 0 ( z ), which should of course ha v e long tails. This is similar to the defensive mixtur es app roac h studied by Hesterb erg (1998 ) for imp ortance samp ling. T he same provisio ns reduce the r isk of adapting to o quickly to a lo cal mo de. 3 Some theory for adaptiv e sampling A diminishing adaptation MH sampler p erform s the accept/ reject step lik e a standard MH, but up dates the prop osal distribution u sing the history of the draws. This up d ating is ‘diminishing’ in the sense that the prop osal distrib ution settles do wn asymptotically (in the n umb er of iterations). This sect ion outlines th e theoretica l framework for s trict adaptiv e indep endent Metrop olis- Hastings samplin g as u sed in our article that giv es some supp ort for our pr acti ce. Th e ap- p endix outlines pro ofs of the theoretical results, whic h extend similar results in Nott and Kohn (2005) for the case of a finite state sp ace. Our aim is to pro vide sim p le accessible pro ofs that will help to p opularize the adaptive metho dology . All densities in this section are with resp ect to Leb esgue measure or coun ting measure, whic h we denote as µ {·} . 5 Let Z b e a sample sp ace and π ( z ) a target d ensit y on Z . W e us e the f ollo wing adaptiv e MH sc heme to construct a sequence of rand om v ariables { Z n , n ≥ 2 } w h ose distribution con v erges to π ( z ). W e assume that Z 0 and Z 1 are generated indep enden tly from some initial densit y q I ( z ). In our examples, this is a heavy tailed v ersion of the Laplace approximat ion to the p osterior d istribution. F or n ≥ 1, let q n ( z ; λ n ) b e a p rop osal d en sit y for generating Z n +1 , where λ n is a parameter v ector that is based on Z 0 = z 0 , . . . , Z n − 1 = z n − 1 . Thus, giv en Z n = z , we generate Z n +1 = z ′ from q n , and then with probabilit y α n ( z , z ′ ) = min 1 , π ( z ′ ) π ( z ) q n ( z ; λ n ) q n ( z ′ ; λ n ) (1) w e tak e Z n +1 = z ′ ; otherwise w e tak e Z n +1 = z . Our choic e of q n ( z ; λ n ) is q n ( z ; λ n ) = ω 1 g 0 ( z ) + (1 − ω 1 ) ¯ g n ( z ; ¯ λ n ) (2) where 0 < ω 1 < 1 and the density g 0 ( z ) do es not d ep end on λ n . W e usually fix ω 1 so that λ n = ¯ λ n ; otherwise λ n = ( ¯ λ n , ω 1 ). The density ¯ g n ( z ; ¯ λ n ) is an app ro ximation to π ( z ) wh ose form is discussed b elo w, in sect ion 5 a nd in app endix 1. W e assume that there exists a constan t K > 0 such that for all z ∈ Z π ( z ) g 0 ( z ) ≤ K, ¯ g n ( z ; ¯ λ n ) g 0 ( z ) ≤ K , and q I ( z ) g 0 ( z ) ≤ K (3) and sup z ∈Z ¯ g n ( z ; ¯ λ n ) − ¯ g n +1 ( z ; ¯ λ n +1 ) /g 0 ( z ) = a n (4) where a n = O ( n − r ) for some r > 0 almost surely . If Z is compact then (3) holds almost automatica lly . If , in add ition, ¯ λ n is b ased on means and co v ariances of th e z iterates then w e can s h o w that || ¯ λ n − ¯ λ n +1 || = O ( n − 1 ) and equation (4) also h olds. In relation to (3), w e note that in th e n on-adaptiv e case, that is q n ( z ; λ n ) = q ( z ) for a ll n , Mengersen and T w eedie (1996) sho w that π ( z ) /q ( z ) ≤ K for all z is a necessary and sufficien t condition f or geometric ergo dicit y . Under cond itio ns (3) and (4), the follo wing resu lts are pr o ved in Ap p endix 2. 6 Theorem 1 F or al l me asur able subsets A sup A ⊂Z | Pr( Z n ∈ A ) − π ( A ) | → 0 as n → ∞ . (5) Theorem 2 Supp ose that h ( z ) is a me asur able fu nction that is sq u ar e inte gr able with r esp e ct to the density g 0 . Then, almost sur ely, 1 n n X j =1 h ( Z j ) → E π ( h ( Z )) as n → ∞ . (6) W e no w describ e the form of ¯ g n ( z ; ¯ λ n ) in (2). F or conciseness, we shall often omit sho wing d ep endence on λ ; e.g. w e w ill write ¯ g n ( z ; ¯ λ n ) as ¯ g n ( z ). Let g ⋆ n ( z ) = g ⋆ n ( z ; λ ⋆ n ) b e a mixture of normals obtained us ing k-harmonic means clustering as describ ed in section 5 and app endix 1, and let ˜ g ⋆ n ( z ) b e a second mixture of norm als ha ving the same comp onen t w eigh ts and means as g ⋆ n ( z ), but with its comp onen t v ariances infl ated b y a factor k > 1. Let ¯ g ∗ n ( z ) = ω ′ 2 ˜ g ⋆ n ( z ) + (1 − ω ′ 2 ) g ⋆ n ( z ) , (7) where ω ′ 2 = ω 2 / (1 − ω 1 ) with ω 1 defined in (2), ω 1 > 0 , ω 2 > 0, and ω 1 + ω 2 < 1. W e note that ¯ g ∗ n ( z ) is also a mixture of normals, and we sa y that ¯ g ∗ n ( z ) is obtained by ‘stretc hing and f atte ning’ the tails of g ⋆ n ( z ). This strateg y for obtaining hea vier tailed mixtures is used extensiv ely in our pap er. T o allo w for diminish in g adaptation, we in tro duce the sequence β n , where 0 ≤ β n ≤ 1, and d efine ¯ g n ( z ) = (1 − β n ) ¯ g ∗ n ( z ) + β n ¯ g n − 1 ( z ) (8) with ¯ g n ( z ) = ¯ g n ( z ; ¯ λ n ), wh ere ¯ λ n is a function of λ ⋆ n and β n . Alternativ ely , we can defi ne ¯ λ n = (1 − β n ) λ ⋆ n + β n ¯ λ n − 1 (9) and ¯ g n ( z ) = ¯ g n ( z ; ¯ λ n ). 7 If we restrict Z to b e compact and let β n → 1 at an appropriate r ate then it is straigh t- forw ard to chec k in most cases th at the dominance and diminish ing adaptatio n conditions, (3) and (4), hold. If Z is unconstrained bu t we restrict th e λ ⋆ n to lie in a b ound ed set then w e can do r ough empir ica l c hec ks that (3) and (4) hold b y taking g 0 ( z ) to b e sufficientl y hea vy tailed. In our empirical examples we often find that we can tak e β n = 0 for a ll n b ecause λ ⋆ n con v erges to a λ ⋆ at a sufficien tly fast rate as n increases. This means that if g 0 ( z ) is sufficien tly hea vy tailed th en (3) and (4) hold as n increases. Section 7 and app endix F of Andrieu and Moulines (2006) giv e general co nv ergence results for adaptive indep enden t Metrop olis-Hastings and Rob erts and Rosenthal (2007 ) giv e an elegan t pro of of the con vergence of adaptiv e s ampling schemes. How eve r, we b eliev e that readers ma y fi nd the conditions (3) and (4) and the pro ofs of Theorems 1 and 2 easie r to un derstand for the metho dology pr op osed in our article. 4 Implemen tation of the adaptiv e sampling sc heme This section outlines ho w our sampling sc heme is implemen ted. W e an ticipate that readers will use this as a basis for th eir o wn exp erimen tation. In the preliminary phase the densit y g 0 ( z ) in (2) is a mixtur e of the Laplace approximat ion to the p osterior and a h ea vier tailed v ersion of t he Laplace ap p ro xim ation, using w eigh ts of 0.6 and 0.4. By a heavie r tailed v ersion we mean a distribu tion with the same mean b ut with a co v ariance matrix that is 25 times larger. If the Laplace appr oximati on is una v ailable, then w e u se the prior. At the end of the preliminary phase, g 0 ( z ) is constructed as a mixture of the last estimated m ixture, whic h w e call g last ( z ) sa y , and a hea vier tailed ve rsion of g last ( z ). Th at is, the comp onen t w eigh ts and means are set to those of g last ( z ), and its comp onen t v ariances equal to k = 25 times the comp onen t v ariances of g last ( z ). In our empirical work w e set the weig hts ω 1 = 0 . 05 , and ω 2 = 0 . 15 in (2) and (7). W e also inflate the comp onent v ariances of g ∗ n ( z ) by a factor of k = 16 to obtain the corresp onding v ariances of e g ∗ n ( z ). These v alues ha v e b een foun d to w ork well bu t are n ot optimal in an y sp ecific sense. W e conjecture that the sp eed of con verge nce and efficiency of our sampler could b e further impro ve d w ith a m ore careful (and p ossibly adaptiv e) c hoice of th ese parameters. An y other v alue of k in the r an ge 9-25 and of ω 1 and ω 2 in the r an ge 8 0 . 05 − 0 . 3 w orked w ell for the examples give n in th is pap er, and ω 1 could b e set to 0 in the preliminary p hase without affecting the results. In our empirical w ork, during the preliminary ph ase, when th ere are 2 to 4 unkn o wn parameters as in the in fl atio n a nd stoc hastic vola tilit y examples, w e first r e-estimate the k-harmonic means mixture after 20 ac c epte d dra w s in order to ensure th at the estimated co v ariance matrices are p ositiv e defin ite. If our parameter sp ace is b igge r then w e w ould increase that n u m b er appropriately . W e then re-estimate the mixture after 50, 100, . . . , 350, 400, 500, . . . , 1000, 1500, . . . , 3000 draws and then ev ery 1000 draws thereafter. W e also recommend up dating the pr oposal follo wing a p erio d of lo w acceptance pr obabilitie s in the MH s tep. Sp ecifically , w e re-estimate the mixture parameters if the a verag e acceptance probabilit y in the last L iterations is lo wer than α L , w here we set α L = 0 . 1 and L = 10. Lo w acce ptance probabilities signal a p o or fit of th e prop osal, and it is therefore sensible to up d ate th e prop osal to giv e it a b etter c hance of co v ering th e area around the current parameter v alue. Since it is unclear that this do es not violate an y of the conditions required for the er go dicit y of our adaptive sampler, we limit the up dating of the pr op osal at endogenously chosen p oints to a pr eliminary p erio d, after which the prop osal is up dated only at predetermined in terv als. The end of the preliminary adaptation p erio d could b e set ex-an te, b u t we prefer to determine it endogenously by requirin g the smallest acceptance probabilit y in the last M iteratio ns to b e higher than α M , wher e M is set to 500 and α M to 0.02. During the p erio d of strict adaptation, we up date the prop osal ev ery 1000 d ra w s . W e conjecture that Th eorems 1 and 2 will still hold if w e up d ate th e p rop osal after a sequ en ce of lo w acceptance probabilities so that w e could also use this up d ate strategy during the p erio d of strict adap tation. How eve r, w e ha v e not implemen ted this in our empirical analyses. The estimation of the mixture of n ormals ca n b ecome slo w when the num b er of iterati ons is large. T o av oid th is prob lem, after 1000 accepted dra ws we only add every j - th draw to the sample used to estimate the mixture parameters, where j is c hosen so that the mixture is not estimated on more than 10000 observ ations. When most parameters are nearly normally d istributed, fitting a mixture of normals to all th e p aramete rs is prob lematic in the sense that the c hances of findin g a lo cal m o de 9 with all p aramete rs normally distributed is qu ite high (though d ep ending on the starting v alue of course). This is true of clustering alg orithms and also of EM-based algorithms. T o impro ve the p erformance of the sampler in these situatio ns, we divide the parameter v ector θ in to t wo groups , θ 1 and θ 2 , where parameters in θ 1 are classified as appr o ximately normal and p aramete rs in θ 2 are skew ed. 1 A n ormal is then fi t to the fi r st group and a mixture of p normals to the second. F or θ 1 , we can compu te th e mean µ θ 1 and co v ariance matrix Σ θ 1 inexp ensiv ely fr om the draws. F or θ 2 , we fit a mixture of norm als as detailed b elo w, estimating probabilities π 1 , ..., π p , means µ 1 , ..., µ p , and cov ariance matrices Σ 1 , ..., Σ p . W e then need to bu ild a mixtur e for θ = { θ 1 , θ 2 } . The mean is straigh tforwa rd: f or the normal parameters, all comp onents ha v e the same mea n. The diagonal blocks of the co v ariance matrices Ω i corresp onding to v ar( θ 1 ) and v ar( θ 2 ) for comp onent i are also straigh tforward. The off-diagonal blo c k s of Ω i , corresp ond ing to co v ( θ 1 , θ 2 ) is computed as Ω 12 i = n X t =1 π ∗ i,t [( θ 1 ,t − µ θ 1 )( θ 2 ,t − µ i )] / n X t =1 π ∗ i,t , wher e π ∗ i,t = Pr( K t = i | θ 2 ,t ) is the p robabilit y of θ 2 ,t coming fr om the i -th comp onent . 5 A clustering algorithm for fast estimatio n of mixtures of normals in adaptiv e IMH Finite mixtures of normals are an attractiv e option to constr u ct th e prop osal densit y b eca use they can appr o ximate any con tin uous dens it y arbitrarily we ll and are fast to samp le from and ev aluate. See McLac hlan and Peel (2000) for an extensiv e treatmen t of finite mixtur e mo dels. Ho wev er, estimating mixtur es of normals is already a diffi cu lt problem when an indep en- den t and iden tically distributed sample f rom the target is giv en and estimation needs to b e p erformed only once: the lik eliho o d go es to in finit y whenever a comp onen t has zero v ariance (an ev en more concrete p ossibility if, as unav oidable in I MH, s ome observ ations app ear more 1 Our rule of thumb is to place a parameter in the ‘normal’ group if its marginal distribution has | s | < 0 . 2 , where s is t he sk eweness. Ou r fattening the tails of the mixtu re should handle the kurt osis, though this w ould optimally b e done with mixtures of more flexible d istributions than the normal. 10 than once), and its maximization, whether by the EM algorithm or directly , is plagued by lo cal mo des. Although several authors ha v e mad e substan tial adv ances in dealing with these problems (e.g. Figuereido and Jain 2002; Ueda, Nak ano, Ghahramani, and Hin ton 2000; V erb eek, Vlassis, and K rose 2003), in our exp erience the EM algorithm do es not seem to b e suffi cien tly reliable when the samp le is small and con tains a non-trivial share of rejected dra ws. The inevitable sh ort runs of rejections give rise to small clusters with zero co v ariance matrix at whic h the EM algorithm f r equen tly gets s tu c k. Moreo v er, EM-based algorithm are computationally exp ensiv e and slo w to conv erge, whic h mak es them less attractiv e when the p rop osal is to b e up dated fr equ en tly . W e ha v e therefore limited our atte ntio n to algorithms that estimate mixtures of n ormals quic kly and without explicitly computing the co v ariance matrix of eac h comp onent (for ro- bustness). Within this class, the k-me ans is the most p opu lar algorithm. W e emplo y the k-harmonic me ans , an extension of the k-means algorithm that allo ws for soft m emb ership. Degeneracie s can b e easily preve nted, so the algo rithm is remark ably r obust ev en in the presence of a long series of rejections. The num b er of clusters is c h osen w ith the BIC crite- rion. The increase in sp eed and reliabilit y is paid for w ith a decreased fit to the target, as the family of k-means algorithms p erforms b est when an optimal fit requires all comp onents of the mixture to hav e the same probabilit y and co v ariance matrix (see Bradly and F ayy ad 1998, for a discussion). Ha merly and Elk an (2002) sho w that the p erformance of k-harmonic means deteriorates less rapidly than alternativ es of similar computational cost with dep ar- tures from these ideal conditions. An outline of the k-harm onic means algorithms is given in App en d ix 1. Although the k-harmonic m eans algorithm is less sen sitiv e to initialization than either k-means or EM (Hamerly and Elk an 2002), in an un sup ervised en vironment it is imp ortan t to h a ve go o d starting v alues. W e ha v e found the algorithm of Bradly and F a yyad (1998 ) to p erform ve ry we ll and at a low computational cost. If the prop osal d istribution is normal then it is computationally inexp ens iv e to up d ate it at ev er y iteration. It is tempting to u p date a mixture of normals pr oposal with an on-line estimation pro cedure su c h as the on-line EM algorithm pr op osed in Andrieu and Moulines (2006). The adv anta ge of on-line estimation is that the parameters of the mixture are 11 up dated recursiv ely , so the prop osal itself is up dated at eac h iteration at a very small com- putational cost. Ho wev er, on -line estimation of the mixture parameters in A IMH has a n umb er of serious s hortcomings. Th e estimates are inefficien t compared to batc h estima- tors b ecause eac h data p oin t is used only once, which corresp onds t o r equiring a batc h optimization to con verge in one step. The loss of efficiency is m ore sev ere in small samples, that is, in the early ph ases of the c hain. Direct estimation of the mixture comp onen t co v ari- ance matrices often leads to numerical problems in the early p hases of the c hain give n th at rejections in MH pr od uce d ege nerate clusters. Finally , a limitatio n of on-line estimators is related to the fact that they are a form of sto c hastic grad ient descent (see Spall (2003) for an introd uction). When the fu nction to b e maximized is m ultimo dal (as t ypically the case with mixtures) on-line estimates are in general sensitiv e to the order of the d ra ws , with in itia l dra ws ha vin g hea vier influence than later d ra w s in dete rmin ing the mode at whic h estimates settle d own. W e hav e verified empirically that the qu alit y of solutions giv en by sev eral on-line algorithms d ete riorates rapidly if the initial obser v ations are not represent ativ e of the en tire target d istribution. Th is mak es on-line algorithms un suitable for u se in the early , exploratory p hases of the chain, though they can w ork w ell if the in itia l prop osal distribution already pr o vides a reasonably go o d app ro ximation of the target and the acceptance rates are sufficiently high. Since w e are opting for batc h estimators, it is too costly to up date the p rop osal at eac h iteration. W e u p date i t at predetermined num b ers of iteratio ns, m ore frequently in the earlier stages of th e chain. Imp lemen tation details for the emp irical examp les are giv en in section 4. W e mak e tw o f urther comments on Andr ieu and Moulines (2006). First, they prop ose to k eep the num b er of comp onents in the mixture constant, whereas we hav e fou n d it adv ant ageous to s elect the num b er adaptiv ely as outlined in app end ix 1. Second, they outline a prop osed app r oac h to u sing mixtur es as prop osal densities, but do not rep ort on the emp irical p erformance of their prop osal. 12 6 Discussion In order to understand the strengths and limitations of our sampler, w e ha v e foun d it u seful to consider t wo desirable qualities of an adaptiv e I MH sc heme. First, giv en a suffi ciently large sample dr awn from the target, we wish to construct a prop osal densit y which fits the target as we ll as p ossible. This is an approximati ng abilit y: we w ant to dr aw an accurate ‘map’ of th e areas th at w e h a ve already explored. Second, we w ish the samp ler to p erform as well as p ossible when the initial p rop osal fails to co ver p art of the supp ort of the target distribution. This is an exploring ability: w hen we prop ose in a region where our map is p o or, w e wan t to explore that region and quic kly up date our map. F or example, using a norm al prop osal when the target is highly non-norm al resu lts in little appro ximating abilit y . Up dating the pr oposal only once or v ery rarely results in little exploring ab ility , since the prop osal reacts slowly or not at all to the information that it is fitting p o orly at a given p oint. Our sampler h as seve ral c haracteristics designed to enhance its exploring abilit y . F re- quen t up d ating, p articularly at early iterations, and u p dating f ollo wing a sequ ence of lo w MH acceptance probabilities quic k en the pace at whic h the prop osal adapts to the infor- mation that it is not fitting well in a certain area. Long tails are u seful not only to satisfy (3) and (4), but also to impro v e the c h ances of ve nturing into u n explored parts of the state space. Finally , mixtures are ideally suited for this exploration b ecause a new comp onen t can b e cente red on a v alue causing a se quence of rejections. Th e long runs of rejections that can plague standard IMH are therefore m uch less lik ely using our AIMH sampling sc heme b ecause th e prop osal distribution is up dated frequently and will accommod ate th e cluster of rejections b y c hanging the mixture parameters or adding a new comp onent. If our sampler makes a mov e in a region wh ere the prop osal fits p o orly , it should therefore b e able to exp lore it. O f course as the p arameter d imension increases, if the initial pr oposal fails to co v er a region w e may nev er exp lore that region simply b ecause th e probabilit y of making a prop osal there is to o small. The next example shows that in lo w dimensions we can often get a wa y with a v ery p oor initial prop osal distribution. 13 Example 1 Supp ose that the target is th e univ ariate mixture π ( z ) = 0 . 5 φ ( z ; 0 , 1) + 0 . 3 φ ( z ; − 3 , 4) + 0 . 2 φ ( z ; 6 , 0 . 5) , and the initial prop osal is φ ( z ; − 5 , 4) . This prop osal has very high imp ortance we ight s π /g in a large p art of the supp ort of z , but we still quic kly con ve rge to a go o d ap p ro xim ation of the target. Figure 1 sho ws that the acceptance rates increase fast initially and then s tabilize as the prop osal distribu tion also settles do wn. The next example sh o ws that as the d imension incr eases a go od initial prop osal distri- bution b ecomes m ore v aluable. Example 2 Consider the fif teen dimensional target distribution w h ic h is the mixture of t wo normals π ( z ) = 0 . 7 φ ( z ; 0 , I ) + 0 . 3 φ ( z ; µ 2 , 2 I ) , where φ ( z ; µ, Σ ) is a multiv ariate n ormal densit y with mean µ a nd co v ariance matrix Σ ev aluated at z . The vecto r µ 2 has element s µ 2 ,i = 0 for i = 1 , ..., 14 , and µ 2 , 15 = − 3 . The fi rst fourteen marginals are th erefore symmetric but sligh tly leptokurtic, wh ereas the fifteen th is also skew ed. Th e prop osal distrib u tion is initializ ed by fattening and stretching the tails of the Laplace approximati on, that is, a norm al d istribution cen tered at the mo de and with co v ariance set to minus the in v erse of the Hessian of the log-lik eliho od at the mo de. The Laplace appr oximati on is nearly equal to φ ( z ; 0 , I ), s o w e ha ve g 0 ( z ) ≃ 0 . 6 φ ( z ; 0 , I ) + 0 . 4 φ ( z ; 0 , 16 I ). Figure 2 shows that the acceptance rates at the initial prop osal are not high, but sufficien t to start the learning pro cess. T he AIMH learns the marginal distribution of the n on -n ormal v ariable rather w ell a nd , since most v ariables are normal, a t very lo w computational cost sin ce w e only estimate the mixture p arameters on v ariables that app ear sk ew ed. In cont rast, an in itial prop osal suc h as φ ( z ; m, 4 I ) , where m = − 5 generates suc h lo w accepta nce rates for this fifteen dimensional distribution that th e learning pro cess cannot get successfully started. 14 7 Applications State space mo dels and nonp arametric mo dels are ideal initial applications for AIMH sc hemes. Although they can hav e a la rge num b er of parameters, it is often the case th at, con- ditional on a small su bset, most p aramete rs can b e inte grated out or ha ve known analytical form. Therefore it is often p ossible to d ra w all parameters in one or t wo blocks. Exploit ing these features, it is also often inexp ens ive to find the p osterior mo de, p ossibly for a simp li- fied version of the mo del, and therefore obtain a r easo nable initialization of the prop osal distribution. Finally , the standard app roac h based on Gibb s and Metropolis-within-Gibb s can b e very inefficient , particularly for state space mo dels (see F ru h wirth-Schnatte r 2004). F or eac h of our app lications we c hec k ed the results of the adaptiv e samp lin g sc h eme b y re-runnin g the sampler at a num b er of differen t starting p oin ts u sing a fixed prop osal based on the last mixture in the strict adaptation p h ase. In all cases w e got very similar r esults to those obtained using strict adaptation. F or our examples we defin e the inefficiency of a sampling sc heme as the factor by which the n umb er of iterat es w ould n eed to increase to giv e the same precision (standard err or) as a sampler generating indep end en t draws. F or t w o sampling sc hemes A and B sa y , w e d efine the in efficiency of sc heme B relativ e to A as the factor by which it is n ecessary to increase the ru nning time of B in ord er for it to obtain the same accuracy as A. It is computed as the inefficiency facto r of B times its r u n time p er iteration divided by the inefficiency facto r of A times its run time p er iteration. In the examp les b elo w w e compare the p erformance of the AIMH sampler to the follo wing v ersion of th e Haario et al. (2001) adaptive random walk Metrop olis sampler prop osed on page 3 of Rob erts and Rosenthal (2006 ). Sp ecifica lly , let θ b e the p aramete rs in the mo d el, ˆ θ the p osterior mo de and V the v ariance cov ariance matrix of the Laplace appr o ximation to the p osterior. Then at iteration j the p rop osal distribution is giv en b y Q j ( θ c , · ) = N ( θ c , (0 . 1) 2 V /d ) if j < 5 d, Q j ( θ c , · ) = (1 − β ) N ( θ c , (2 . 38) 2 Σ j /d ) + β N ( θ c , (0 . 1) 2 I d /d ) if j ≥ 5 d, where N ( θ , V ) is the normal densit y with mean θ and co v ariance matrix V , θ c is the cu r ren t 15 v alue of θ , d is the dimension of θ , β = 0 . 05 and Σ j is the curren t empirical estimate of the co v ariance matrix of th e target distribu tion based on the iterates thus far. In all cases w e initialized this sampler at the p osterior mo de. 7.1 Time-v arying param eter autoregressiv e mo dels Consider the f ollo wing time-v arying parameter first order autoregressiv e (A R(1)) process (the extension to a more general autoregressiv e pro cess is straigh tforw ard): y t = c t + ρ t y t − 1 + σ ǫ ǫ t , c t = c t − 1 + λ 0 σ ǫ u t and ρ t = ρ t − 1 + λ 1 v t , (10) where ǫ t , u t , v t are all nid (0 , 1) . The mo del has th ree parameters ( σ 2 ǫ , λ 2 0 , λ 2 1 ) , w hile c 0 and ρ 0 can b e treated either as parameters or (our c h oic e) as states. Giv en co nju gat e priors (in v erse gamma for the parameters, and n orm al for c 0 and ρ 0 ), Gibbs samplin g is straigh t- forw ard (Carter and Kohn 199 4). F ruhwirth-Sc hnatter (20 04 ) r ep orts that based on the auto correlat ions of th e iterates, Gibbs sampling can b e very inefficien t for these mo dels. In the f ollo wing app licat ion w e also fi nd that the Gibbs draws are highly au to correlated and, b y comparing p osterior statistics fr om Gibbs sampling and from our AIMH, we also find that the auto correlations d o not revea l the full exten t of th e problem. 7.1.1 Application: US CPI infla t ion W e apply the mo del to quarterly U.S. CPI infl ation for the p erio d 1960-20 05 (184 observ a- tions). 2 W e use rather disp ersed in v erse gamma p riors for σ 2 ǫ , λ 2 0 , λ 2 1 with a common shap e parameter of 1. Th e s cal e parameters are d efined b y setting the mo des of the pr iors close to maxim um likel iho o d estimates: σ 2 O LS for σ 2 ǫ (where σ 2 O LS is the residu al v ariance from an AR(1) mo del estimated b y OLS), at 0 . 01 σ 2 O LS for λ 2 0 and at 0 . 00 1 2 for λ 2 1 . Th e mo des of λ 2 0 and λ 2 1 are cen tered at the maxim um lik eliho o d estimates to ens ure th at the bimo dalit y in the p osterior distribution of the log of λ 2 1 do cumen ted in Figure 4 is not induced by the prior. 2 Annualized quarterly CPI infl ation, defined as 400( P t /P t − 1 − 1) , where P t is aggregated from monthly data (av erages) on Consumer Price Index F or A ll U rban Consumers: All Items, seasonally ad justed , Series ID CPIAUCSL, Source: U .S. Department of Lab or: Bureau of Lab or St atistics . 16 F or giv en parameters, the likeli ho o d is easily compu ted via the Kalman filter. I t is therefore simple to fin d th e p osterior mod e, at wh ic h th e chain is initialize d. P osterior mo de v alues suggest th at time v ariation is nearly absent. Starting with Gibbs sampling, w e dra w 40 000 times after a bu rn-in of 5000 . The re- cursiv e parameter means seem to settle do w n (not rep orted) and the p osterior distributions are in line with a normal approxi mation tak en at the mo de, suggesting a p ersistent AR(1) with little sign of parameter v ariation (see Figure 3). It ma y therefore seem reasonable to assume that the c h ain has pro duced a sample representat ive of the ent ire p osterior. Ho wev er, the AIMH sc heme tells a differen t story . The prop osal is initialized at a mixture of t w o normals g 0 ( z ) = 0 . 5 φ ( z ; b µ , b Σ) + 0 . 5 φ ( z ; b µ , 16 b Σ), w here b µ is the p osterior m o de and − b Σ is the inv erse of the Hessian of the log-p osterior ev aluated at b µ . The AIMH so on disco v ers that the p osterior distribution of log( λ 2 1 ) , not to men tion λ 2 1 , is highly non-norm al (see Figure 4), with substantia l probabilit y mass around a second mo de corresp onding to non-trivial amounts of time v ariation in ρ t and a lo w er ρ 1 . W e also ran th e adaptive random wa lk Metrop olis sampler outlined at the start of the section. The sampler settles do wn to a n acceptance rate of 20% and obtains the correct p osterior distrib u tion, and i n partic ular finds b oth mo des. T able 1 give s the inefficiency factors for all t hr ee samp lers as w ell as t he in efficie ncy facto rs of the G ibbs and AR WM relativ e to AIMH. The table shows that the AIMH samp ler is appreciably more efficien t than the other tw o samplers. 7.2 Additiv e semiparametric Gaussia n models In th is exa mple we consider the additive semiparametric regression mo del with Gaussian errors, with some of the co v ariates en tering linearly and the others en tering more flexibly y i = m X j =1 γ j z j i + H X h =1 f h ( x h,i ) + σ ǫ ǫ i ; (11) 17 the ǫ i are nid (0 , 1) and z is a ve ctor of regressors that en ter linearly . The x h , h = 1 , ..., H are co v ariates that enter more fl exibly b y using th e quadratic p olynomial spline fu nctions f h ( x h,i ) = β 0 ,h x h,i + J X j =1 β h,j ( x h,i − ˜ x h,j ) 2 + = β 0 ,h x i + g h ( x h,i ) , (12) where x + = x if x > 0 and 0 otherw ise a nd { e x h, 1 , ..., e x h,k } are p oints (or ‘knots’) on the abscissae of x h suc h that min( x h ) = e x h, 1 < ... < e x h,J < max( x h ). In this pap er we choose 30 knots so that e ac h in terv al con tains th e same n umb er of observed v alues of x h . F or a discussion of qu adratic spline bases and other related bases s ee c h ap ter 3 of Rupp ert et al. (2003). W e assume th at a global interce pt term is included in z in (11) and for simplicit y w e include the parameters β h, 0 , h = 1 , . . . , H in the v ector γ and x h , h = 1 , . . . , H as part of the vecto r z . This transforms the non p arametric mo del into an highly parametrized linear mo del y = e Z e γ + ǫ. (13) The prior for the linear parameters γ is n orm al w ith a diagonal co v ariance matrix γ ∼ N (0 , v 2 γ I ), w here v γ can b e s et to a large n umber. It is also con ve nient to assume a normal prior for the nonparametric part, with all parameters indep enden t and β h,j ∼ N (0 , τ 2 h ) , , j = 1 , ..., J, h = 1 , ..., H. Ho wev er, with th is pr ior there is a high risk of o v er-fitting if w e simply set τ 2 h to a large num b er. The v ariance τ 2 h is often c hosen by cross-v alidation, b ut in a fully Ba yesian setting w e can treat τ 2 h as a p aramete r. T o illus tr ate the adv antag e of AIMH in w orking with d ifferen t priors, w e exp erimen t with tw o options for the pr ior τ 2 h . Th e first prior is log-normal and rather disp ersed: ln( τ 2 h ) ∼ N (0 , 5 2 ), th e second is inv erse g amma with shap e parameter 1 a nd scale parameter implied b y setting the mo de at 0 . 1 2 . Th e prior for σ 2 ǫ is in verse gamma w ith shap e p aramete r one a nd scale p aramete r im p lied b y setting the p rior mo de at the OLS residual v ariance estimated on (13). The p rior for e γ = ( γ , β 1 , ..., β H ) is therefore join tly normal conditional on τ 2 = { τ 2 1 , .., τ 2 H } , e γ | τ ∼ N ( 0 , V e γ ( τ )), where V e γ ( τ ) = diag( v 2 γ I , τ 2 1 , I , . . . , τ 2 H I ) is a b lock diagonal matrix. O n e wa y t o estimate the posterior densit y of the semiparametric mo del is to use Gi bb s or Metrop olis-within- Gibbs sampling as pr op osed by W ong and Kohn (1996). In this app roac h the parameters 18 e γ = { γ , β 1 , ..., β H } are conju gate giv en θ = { σ 2 ǫ , τ 2 1 , ..., τ 2 H } , and σ 2 ǫ is conjugate giv en e γ . Eac h v ariance τ 2 h can b e u p dated with a Gibbs step f or the inv erse gamma prior, or w ith a Metrop olis-Ha stings step for the log-normal prior. In this second case, w e use a Laplace appro ximation of p (ln( τ 2 h ) | β h ), wh ic h is very fast to compute us in g analytical deriv ativ es. Ho wev er, the correlation b et w een τ 2 h and { β h, 1 , .., β h,J } could b e quite high using either prior for τ 2 h . In addition, using a log normal pr ior for τ 2 h leads to high r ejecti on rates in the Metrop olis-Ha stings step w hen generating the τ 2 h . Both p roblems are elega ntly solv ed b y in tegrating out e γ and generating θ as a blo c k usin g an efficien t AIMH sampler. The next example sho ws ho w to up date all paramet ers in one blo c k wit h a n efficient AIMH sampler. W e first note that, conditional on θ , e γ can b e in tegrated out, ma king it p ossible to compute p ( θ | y ) ∝ p ( y | θ ) p ( θ ) , where y | θ ∼ N ( 0 , σ 2 ǫ I + e Z V e γ ( τ ) e Z ′ ). 7.2.1 Application: Boston housing data W e use the Gaussian semiparametric mo del to s tudy the Boston hous ing data in tro duced b y Harrison and Rubinfield (1978) and analyzed semiparametrically b y Smith and K oh n (1996). 3 There are 506 observ ations. The dep endent v ariable is the log of M V , the median v alue of o wner-o ccupied homes. W e u se all 13 av ailable co v ariates (see Sm ith and Kohn or the web-site for a fu ll description) in the linear part an d the follo wing six in the nonparametric p art (S mith and Kohn u se only the first five ): X 5 = N O X , n itroge n o xide concen tration, X 6 = R M , a ve rage n umb er of ro oms, X 8 = D I S, logarithm of the distance from fiv e emplo yment cen ters, X 10 = T AX , prop ert y tax rate, X 13 = S T AT , prop ortion of the p opulation that is lo w er status, X 1 = C R I M , p er capita crime rate b y to wn. The p rop osal distribu tion for the seven parameters θ = { ln( σ 2 ǫ ) , ln ( τ 2 5 ) , ..., ln ( τ 2 1 ) } is initialized b y fattening the tails of th e Laplace appr o ximation. T o find the L ap lace ap- pro ximation, w e simply apply Newton-Raphson op timization (with numerical deriv ative s) to ln p ( y | θ ) + ln p ( θ ) , which inv olv es no extra co ding effort since b oth densities are needed to compute the MH acceptance ratio. Fig ure 5 pro vides results for the case of a log-normal prior on τ 2 h , h = 1 , ..., H and shows th at the acceptance r ate quic kly impro ve s and stabi- lizes at aroun d 60% when all s even parameters are u p dated jointly . Most parameters are 3 The dataset is av ailable at www.cs.utoron to.ca/˜delv e/data/boston. 19 appro ximately lognormally distributed, except those connected to the v ariables T AX and C R I M , whic h b enefit from the added flexibilit y of m ixtures. The correla tion matrix of the smo othing parameters { ln( τ 2 5 ) , ..., ln ( τ 2 1 ) } is nearly diagonal. This s uggests that the AIMH could han d le large n umbers of smo othing parameters efficien tly b y u p dating them in blo c ks (with a different prop osal densit y estimated adaptiv ely on eac h blo c k), since the blo c k s w ould b e nearly ind ep enden t of eac h other. T able 1 rep orts the inefficiency facto rs for b oth the Gibbs sampler and the AIMH samp ler for b oth in v erse gamma and log normal priors, as w ell as the inefficiency of the Gibb s sampler relativ e to the AIMH sampler. The table sho ws that in terms of relativ e efficiency (defined at the b eginning of sec tion 7), the AIMH is ab out 40% more efficien t than the Gib b s sampler when b oth samp lers use the inv erse gamma prior on τ 2 h , a nd nearly sev en times more efficient wh en b oth samplers use th e log-normal prior. Rep orted r esults are f or the a v erage inefficiency factors (o ver b oth h and i ) of f h ( x h,i ). Lo oking at the auto corr elation of th e log-parameters give s similar inefficiency ratios. W e also app lied the adaptiv e random w alk Metrop olis sampler to this data set, but could not m ake it work we ll. With the sampler initialized at the p osterior mo de, the acceptance rate started at o ver 50%, bu t w ith in a few hundred iterations fell to b elo w 1% and sta y ed there ind efinitely . W e d o not rep ort an y inefficiency factors for this sa mpler b ecause w e do not b eliev e that inf er en ce is reliable with su ch a low acceptance rate. W e c onjecture that the p o or b ehavio r of the AR WM sampler in th is example compared to the other t w o examples i s b eca use this example has 7 parameters wh ereas the other t w o ha ve 3 and 2 parameters. In addition, the second deriv ative s of the log p osterior in this example are far from constan t, so a unique co v ariance matrix may do v ery p o orly . By contrast, a mixture of normals allo ws for lo cal correlations b et w een the p aramete r and therefore may b e less affected. 7.3 Sto c hastic volatilit y models The simp lest stochastic v olatilit y mo del can b e written for mean corrected data as y t = e 0 . 5 h t ǫ t , h t = µ + ρ ( h t − 1 − µ ) + σ v t , (14) 20 Boston mean f h ( x h,i ) Inflation log( σ 2 ǫ ) log( λ 2 0 ) log( λ 2 1 ) AIMH, IG 2.6 AIMH 6.7 2.8 6.1 Gibbs, IG 6.3 (1.4) Gibbs 9.4 (1.3) 113.3 (37.4) 156.4 (23.7 ) AIMH, LN 1 .6 (6.8) AR WM 21.5 (3.1) 23.5 (8.3) 23.6 (3.8) M-Gibbs, LN 18.4 T able 1: In efficiency factors for the semiparametric (Bo ston) and sta te space (inflation) mo dels, together with the inefficiencies of th e Gibbs sampler and the AR WM relativ e to the AIMH sampler in brac k ets. AIMH: adaptive indep endent Metrop olis-Hastings; M-Gibbs: Metrop olis-within-Gibbs; and AR WM: adaptiv e random walk Metrop olis. IG and LN: in v erse gamma and log-normal priors f or the Boston data. where ǫ t is nid (0 , 1) and the mo del p arameters are θ = { µ, ρ, σ } . W e squ are and tak e logs of the observ ation equation, and we appr oximate the distribution of ln( ǫ 2 t ) , w hic h is the log of a c hi-squared 1, b y a mixture o f normals as in Kim et al. (1998) . This model has a conditionally Gauss ian state sp ace form e y t = g ( K t ) + h t + G ( K t ) u t , h t = µ + ρ ( h t − 1 − µ ) + σ v t , (15) where ǫ t is nid (0 , 1) , e y t = ln( y 2 t ) , and g ( K t ) and G ( K t ) are kno wn giv en K t . The indicators K can b e sampled in one blo c k give n θ and h as in C arter and K ohn (1994 ). The distribution of θ giv en h is conjugate, but Kim et al. (1998) sh o w that θ and h are hig hly c orrelated and recommend drawing θ giv en y and K but integ rating h out. This is accomplished with a Metrop olis-Hastings step, wh ere p ( y | K , θ ) is computed via the Kalman filter. Since the p osterior mo de is not readily a v ailable, Kim et al. (1998) u se IMH, where the p rop osal d istr ibution is calibrated once from d ra w s obtained with a less efficien t sampling scheme. This is less efficien t t han our sc heme and requires co ding tw o different samplers. An alternativ e we no w explore is to u se AIMH fr om the b eginning of the c h ain. 7.3.1 Application: USD-GBP daily returns W e an alyze daily U.S. dollar - British p ound returns (defin ed as the first difference of the log of th e nominal exc hange rate) for the p erio d January 1990 to Marc h 2004. T he parameter µ can b e in tegrated out (see K im et al. (1998 )). T o initialize the prop osal distr ib ution, w e appro ximate the distribution of ln( ǫ 2 t ) as a normal w ith mea n − 1 . 27 and v ariance 2 . 22 2 . This giv es a sta ndard Gaussian state space mo del, for which the Laplac e appro ximation 21 is easily a v ailable. W e also use the mo de to cen ter the pr iors for ρ and ln( σ 2 ), wh ic h are normal and disp ersed. The prior for ρ is tru ncated at 1. With fattened ta ils, the initial prop osal giv es an acceptance rate of around 10%, and Figure 6 sh o ws th at it tak es only a few h un dred iteratio ns for the accepta nce rates to increase to around 50%. This n umb er is satisfactory giv en that the p rop osal approximat es p ( θ | y ) wh ile the acceptance probabilit y is computed on p ( θ | y , K ). The adaptiv e random wa lk Metrop olis samp ler also quic kly settled down to an accep- tance rate of around 15%, with the c hain mixing we ll. Th e inefficiency factors for ρ and σ 2 for b oth samplers are giv en in table 2, together with the in efficiency factors for the adaptiv e random walk Metrop olis relativ e to AIMH. T h e table s h o ws that AIMH compares fa v ourably with AR WM. Sampling Scheme ρ σ 2 AIMH 7.6 9.2 AR WM 21.1 (2.7) 26.5 (2.86) T able 2: Inefficie ncy factors for the sto c h astic v olatilit y mo del for th e adaptiv e indep enden t Metrop olis-Ha stings (AIMH) sampler an d the adaptiv e random w alk Metrop olis (AR WM) sampler, with the r elat ive in efficie ncy of the A WRM in br ac ke ts. 8 Conclusion This pap er sho ws that it is p ossible to build adaptive ind ep end en t Metrop olis-Ha stings samplers that can d o b etter than tw o-step adaptation b ecause they ad ap t throughout the sampling p erio d . The most in teresting applications arise when curren t b est p ractic e is inefficien t or cum b ersome and , in our opinion, wh en adaptation starts early . Our article pro vides a fast and reliable algorithm wh ic h p erforms well in three in teresting mo dels and compares fa v orably on these examples with a standard Mark o v c hain Mon te Carlo sampler and an adaptiv e random walk Metrop olis samp ler. Ac kno wledgemen t W e w ould like to th an k Luk e Tierney , C hristophe Andrieu and An tonietta Mira for helpfu l suggestions and questions that help ed improv e the accuracy and presentat ion of a previous 22 v ersion of the pap er. Rob ert Kohn’s researc h was partially su pp orted b y an AR C gran t. References Andrieu, C. and Moulines, D. (2006 ), “On th e ergo dicit y p rop erties of some adaptiv e MCMC algorithms,” Annals of A ppl ie d Pr ob ability , 16, 1462–150 5. Andrieu, C., Moulines, D., and Doucet, A. (2005), “Stability of sto c hastic appro ximation under verifiable conditions,” SICON , 44, 283–31 2. Andrieu, C. and Rob ert, C. P . (200 1), “Con trolled MCMC for optimal sampling,” T ec hn ica l rep ort, Unive rsity of Bristol. A tc had ´ e, Y. and Rosen thal, J. (200 5), “On adaptiv e Mark o v chain Mon te Carlo algorithms,” Bernoul li , 11, 815–828. Bradly , P . and F a yyad, U. (1998) , “Refining initial p oin ts for k-means clustering,” Pr o c e e d- ings of the 15th International Confer enc e on Machine L e arning , 91–99. Carter, C. and Kohn, R. (1994), “On Gibbs sampling for state- space mo dels,” Biometrika , 83, 589–601 . Figuereido, M. and J ain, A. (200 2), “Unsup ervised learning of fi nite mixture mo dels,” IEEE T r ansactions on P attern Analysis and Machine Intel ligenc e , 24, 381–396. F ruhwirth-Sc h natter, S. (200 4), “Efficie nt Ba y esian parameter estimation,” in State sp ac e and unobserve d c omp onent mo dels , eds. Harv ey , A., K o opman, S ., and Shephard , N., Cam bridge: Cambridge Univ ersit y Press, pp. 123–151 . G ˚ asem yr, J. (200 3), “On an adaptiv e ve rsion of the M etrop olis-Hastings algorithm with indep endent p rop osal distribution,” Sc andinavian Journal of Statistics , 30, 159–173. Gelman, A. and Ru bin, D. B. (1992), “Inferen ce from iterativ e sim ulation usin g m ultiple sequences,” Statistic al Sc i enc e , 7, 473– 83. Gilks, W., Rob erts, G., and Sah u, S. (1998 ), “Adaptive Mark o v c hain Mon te Carlo through regeneration,” Journal of the Americ an Statistic al Asso ciation , 93, 1045 –1054. 23 Giordani, P . and Kohn, R. (2008), “Efficient Ba y esian inference for m ultiple c hange-p oin t and mixture innov ation mo dels,” Journal of Bus in ess and Economic Statistics, 26, 66–77 . Haario, H., Saksman, E., and T amminen, J . (2001), “An adaptive Metrop olis algorithm,” Bernoul li , 7, 223–242. Hamerly , G. and Elk an, C. (2002) , “Alternativ es to the k-means algorithm that find b etter clusterings,” in Pr o c e e dings of the Eleventh Internatio nal Confer enc e on Information and Know le dge Management , eds. Kalpakis, K., Goharian, N., and Gr ossm ann, D., New Y ork: Academic P r ess, pp. 600–607 . Harrison, D. and Rubinfield, D. ( 1978), “Hedonic p rices and the demand for clean air,” Journal of Envir onmental E c onomics and Management , 5, 81–102. Hastie, D. (2005 ), “T o w ards automatic reve rsible j u mp Mark o v c hain Monte Carlo,” Un- published PhD dissertation, Departmen t of Mathematics, Univ ersity of Br istol. Hastings, W. (1970) , “ Mont e Carlo sampling metho ds usin g Marko v c hains an d their ap- plications,” Biometrika , 57, 97–109. Hesterb erg, T. C . (1998), “W eigh ted av erage imp ortance sampling and defensive mixture distributions,” T e chnometrics , 37, 185– 194. Holden, L. (1998) , “Adaptiv e c hains,” Man uscript, Norw egian Computing Center, Oslo. Kim, S., S h epherd, N., and Chib, S. (1998), “Sto c hastic v olatilit y: lik eliho od inference and comparison with AR CH mo dels,” R eview of Ec onomic Studies , 65, 361–394. McLac hlan, G. and P eel, D. (2000), Finite Mixtur e Mo dels , New Y ork: Wiley . Mengersen, K. L. and Tw eedie, R. L. ( 1996), “Rate s of con v ergence of the Hastings and Metrop olis algorithms,” The Annals of Statistics , 24, 101–21. Metrop olis, N., Rosen bluth, A. W., Rosen blu th, M. N., H., T. A., and T eller, E. (1953), “Equation of state calculations b y fast compu ting mac hines,” Journal of Chemic al Physics , 21, 1087– 1092. 24 Nott, D. and Kohn, R. (2005 ), “Adaptiv e sampling for Ba yesia n v ariable selection,” Biometrika , 92, 747–76 3. Rob erts, G. O. and Rosen thal, J. S. (2006), “Examples of adaptive MCMC,” Preprint (h ttp://probabilit y .ca/jeff/ftp d ir/adaptex.p d f ). — (2007), “Coupling and ergo dicit y o f adaptiv e MCMC,” Journal of Applie d Pr ob ability , 44, 458–475 . Rupp ert, D., W and , M., , and Carroll, R. (2003), Semip ar ametric r e gr e ssion , Cam br id ge: Cam bridge Univ ersit y Press. Smith, M. and Kohn , R. (1996), “Nonparametric regression u sing Ba yesia n v ariable selec- tion,” Journal of Ec onometrics , 75, 317–3 43. Spall, J. (2003), Intr o duction to Sto chastic Se ar ch and Optimization , New Y ork: Wiley . Ueda, N., Nak ano, R., Ghahramani, Z., and Hinton, G. (20 00), “SMEM algorithm for mixture mo dels,” Neur al Computation , 12, 2109–2128 . V erb eek, J., Vlassis, N., and K rose, B. (2003), “Efficien t Greedy Learning of Gaussian Mixture Mo dels,” Neur al Computation , 15, 469–4 85. W ong, C. and Kohn, R. (1996), “A Ba y esian appr oac h to additiv e semip arametric regres- sion,” Journal of E c onometrics , 74, 209–23 5. App endix 1: k-h armonic means clustering W e estimate the mixture of normal parameters using the k-harm on ic means clustering al- gorithm whic h can b e describ ed as follo ws. (See Hamerly an d Elk an 200 2 , for a discussion). Let p b e the num b er of clusters. 1. In itia lize the algo rithm with c 1 , ..., c p , the comp onen t cen ters. The starting v alues are c hosen with the pro cedure of B radly and F ayy ad (1998) . W e depart slightly from Bradley and F ayy ad in using the harmonic k-means algorithm (rather than k-means) in the initializatio n pro cedure. 25 2. F or eac h data p oin t θ t , compute a weigh t function w ( θ t ) and a memb ership fun ction m ( c i | θ t ) for t = 1 , ..., p as w ( θ t ) = P p i =1 || θ t − c i || − p − 2 ( P p i =1 || θ t − c i || − p ) 2 and m ( c i | θ t ) = || θ t − c i || − p − 2 P p i =1 || θ t − c i || − p − 2 , where || θ t − c i || is the E u clidean or Mahalanobis distance. F ollo w in g Bradly and F ayy ad (1998), we pu t a low er b oun dary ǫ on || θ t − c i || (to a vo id d egenerac ies when trying || c i − c i || ). The memb ership function softens the sh arp membersh ip of the k-means al- gorithm, so one observ ation can b elong to more than on e cluster in differing degrees. The w eigh t function giv es more w eigh t to observ ations that are current ly co v ered p o orly (i.e. that are far from the nearest cent er). 3. Up d ate eac h cente r c i c i = P n t =1 m ( c i | θ t ) w ( θ t ) θ t P n t =1 m ( c i | θ t ) w ( θ t ) . 4. Rep eat u n til con vergence. This give s the cluster cen ters, whic h we take as estimates of th e comp onen t means. The other mixture parameters can th en b e estimated for i = 1 , ..., k as V i = P n t =1 m ( c i | θ t ) w ( θ t )( θ t − c i )( θ t − c i ) ′ P n t =1 m ( c i | θ t ) w ( θ t ) and π i ∝ n X t =1 m ( c i | θ t ) w ( θ t ) . 5. Th e num b er of clusters is c hosen with the BIC criterion giv en a maxim um n umb er (5 in our examples). W e n otice that the co v ariance matrices V i are only estimated once, after con ve rgence. k-means t yp e algorithms also differ from t he EM algorithm in that they d o not ev aluate the li kel iho o d p ( θ | c 1 , ..., π 1 , V 1 , ... ). Th is s ub-optimal us e of inform ation in fact turns out to b e a great a dv an tage for our p urp oses. F ew er iterations than for EM are needed for con v ergence, and eac h iteration is faster. Ev en m ore imp ortan tly , the algorithm do es n ot get s tu c k in the small degenerate clusters caused by rejections in the sense that, un lik e for the EM algo rithm with freely estimated co v ariances, these small clusters are not absorbing. If k-harmonic means do es find a degenerate cluster, this causes no trouble for con ve rgence, and after con v ergence we can use a predefined matrix in place of an y non -p ositive -defin ite 26 co v ariance matrix (for example, if V i is not p ositive definite we set it to 0 . 5 2 V ar ( θ )). If desired, the mixtu re parameters can b e refined with a few steps of the EM algorithm. In this case, w e r eco mmend not u p dating the the co v ariance matrices f or the reasons just discussed. App endix 2: Pro ofs The one-step transition k ernel for Z n +1 in section 3 is giv en by T n ( z , dz ′ ) = α n ( z , z ′ ) q n ( z ′ ) µ { dz ′ } + δ z ( dz ′ )(1 − ν n ( z )) (16) where δ z ( dz ′ ) = 1 if z ∈ dz ′ and is 0 otherwise, and ν n ( z ) = Z Z α n ( z , z ′ ) q n ( z ′ ) µ { dz ′ } . (17) By the construction of the MH transition k ernel, Z Z π ( z ) T n ( z , dz ′ ) µ { dz } = π ( z ′ ) µ { dz ′ } . (18) In th is section K is a generic constant, indep endent of n , z and z ′ . It is con v enient to write h n ( z ; λ n ) as h n ( z ) Without loss of generalit y w e assume throughout this section that Z is a discr ete space. Exactly the s ame pr oof goes t hr ough for the contin uous ca se with summations replaced by integral s. W e u se th e n otation z s : t to mean { z s , . . . , z t } for s ≤ t , with a similar in terpretation for Z s : t . T o pro v e Theorem 1 w e first obtain the follo wing tw o lemmas. Lemma 1 Under the assumptions of Se ction 2, for any n, k > 0 and z , z ′ ∈ Z , (a) q n ( z ) ≤ K g 0 ( z ) . (b) α n ( z , z ′ ) q n ( z ′ ) ≤ K g 0 ( z ′ ) (c) Ther e exists an ǫ 1 , 0 < ǫ 1 < 1 , such that α n ( z , z ′ ) q n ( z ′ ) > ǫ 1 π ( z ′ ) for al l z , z ′ ∈ Z . (d) ν n ( z ) > ǫ 1 for al l z ∈ Z , wher e ν n ( z ) is define d by (17) . 27 (e) F or k ≥ 1 , let ∆ n ( z , z ′ ) = α n ( z , z ′ ) q n ( z ′ ) − α n +1 ( z , z ′ ) q n +1 ( z ′ ) . Then, | ∆ n ( z , z ′ ) | ≤ K g 0 ( z ′ ) + π ( z ′ ) π ( z ) g 0 ( z ) a n . (19) (f ) | ν n ( z ) − ν n +1 z ) |≤ K 1 + g 0 ( z π ( z ) a n (20) Pro of. (a) q n ( z ) /g 0 ( z ) = ω 1 + (1 − ω 1 ) ¯ g n ( z ) /g 0 ( z ) and th e r esult follo ws from (3). (b) follo ws from (a) and α n ( z , z ′ ) ≤ 1. T o show (c), note that q n ( z ) /π ( z ) ≥ ω 1 g 0 ( z ) /π ( z ). F rom (3), there is an ǫ 1 suc h that q n ( z ) /π ( z ) > ǫ 1 for all z ∈ Z . It is n o w straigh tforwa rd to show that α n ( z , z ′ ) q n ( z ′ ) /π ( z ′ ) > ǫ 1 for all z , z ′ ∈ Z . (d) follo ws from ν ( z ) = X z ′ α n ( z , z ′ ) q n ( z ′ ) > ǫ 1 X z ′ π ( z ′ ) = ǫ 1 T o obtain (e), it is necessary to consider the follo wing four cases. Case 1. α n ( z , z ′ ) = 1 and α n +1 ( z , z ′ ) = 1. Then, | ∆ n | = | q n ( z ′ ) − q n +1 ( z ′ ) | ≤ K g 0 ( z ′ ) a n b y (4). Case 2. α n ( z , z ′ ) < 1 and α n +1 ( z , z ′ ) < 1. | ∆ n ( z , z ′ ) | = π ( z ′ ) π ( z ) | q n ( z ) − q n +1 ( z ) | ≤ K π ( z ′ ) π ( z ) g 0 ( z ) a n . Case 3 . α n ( z , z ′ ) = 1 and α n +1 ( z , z ′ ) < 1. In this case ∆ n ( z , z ′ ) = q n ( z ′ ) − π ( z ′ ) q n +1 ( z ) /π ( z ). If ∆ n ( z , z ′ ) ≥ 0, then 0 ≤ ∆ n ( z , z ′ ) ≤ π ( z ′ ) π ( z ) q n ( z ) − q n +1 ( z ) ≤ K g 0 ( z ) a n c k . If ∆ n ( z , z ′ ) < 0, then 0 < − ∆ n ( z , z ′ ) = π ( z ′ ) π ( z ) q n +1 ( z ) − q n ( z ′ ) ≤ q n +1 ( z ′ ) − q n ( z ′ ) 28 Th us, | ∆ n ( z , z ′ ) | ≤ K g 0 ( z ′ ) + π ( z ′ ) π ( z ) a n . Case 4. α n ( z , z ′ ) < 1 and α n +1 ( z , z ′ ) = 1. This case is similar to case 3. T o obtain (f ), we note that | ν n ( z ) − ν n +1 ( z ) | ≤ X z ′ | ∆ n ( z , z ′ ) | , and the result follo ws from (e). With ǫ 1 as in Lemma 1, c ho ose 0 < ǫ < ǫ 1 and let R n ( z , z ′ ) = T n ( z , z ′ ) − ǫπ ( z ′ ) 1 − ǫ (21) Then, R n ( z , z ′ ) is a one-step transition k ernel with the follo w ing prop erties. Lemma 2 (a) X z π ( z ) R n ( z , z ′ ) = π ( z ′ ) . (b) R n ( z , z ′ ) ≤ K g 0 ( z n ) + η δ z ( z ′ ) wher e 0 < η < 1 . (c) | R n ( z , z ′ ) − R n +1 ( z , z ′ ) | ≤ K a n g 0 ( z ′ ) + π ( z ′ ) π ( z ) g 0 ( z ) + 1 + g 0 ( z ) π ( z ) δ z ( z ′ ) (d) X z n − m +1 · · · X z n − 1 m Y k =1 R n − k ( z n − k , z n − k +1 ) ≤ K g 0 ( z n ) + η m δ z n − m ( z n ) 29 (e) F or 1 ≤ l ≤ j − 1 and j = 1 , . . . , n , X z n − l − 1 · · · X z n − j +1 π ( z n − j +1 ) j − 1 Y k =1+1 R n − j ( z n − k , z n − k +1 ) = π ( z n − l ) (f ) F or j = 1 , . . . , n and l = 1 , . . . , j − 1 , | X z n − j +1 · · · X z n − 1 π ( z n − j +1 ) j − 1 Y k = l +1 R n − j ( z n − k , z n − k +1 ) × R n − l ( z n − l , z n − l +1 ) − R n − j ( z n − l , z n − l +1 ) l − 1 Y k =1 R n − k ( z n − k , z n − k +1 ) | ≤ K g 0 ( z n ) a n − j ( j − l ) − 1 Pro of. (a) follo ws fr om (21) and (18). (b) follo ws fr om (21). (c) follo ws from (19) and (20). (d) is tru e for m = 1 and is obtained in general b y in d uction. (e) follo ws fr om part (a). (f ) follo w s from parts (a) to (e). Pro of of Theorem 1. Let ∆ j , j = 1 , 2 , . . . b e an indep end en t Bernoulli process such that ∆ j = 1 with probability ǫ and ∆ j = 0 with p robabilit y 1 − ǫ . F rom (21), T n ( z , z ′ ) = (1 − ǫ ) R n ( z , z ′ ) + ǫπ ( z ′ ) so that we can interpret T n ( z , z ′ ) as a mixture of transition ke rn els, suc h that T n ( z , z ′ ) = R n ( z , z ′ ) if ∆ n = 0 and T n ( z , z ′ ) = π ( z ′ ) if ∆ n = 1. F or j = 1 , . . . , n , let A n,j b e the eve nt that ∆ n − j +1 = 1 , ∆ k = 0 , k = n − j + 2 , . . . , n . Let B n b e the eve nt that ∆ j = 0 for j = 1 , . . . , n . T hen Pr( A n,j ) = ǫ (1 − ǫ ) j − 1 and Pr( B n ) = (1 − ǫ ) n , and Pr( Z n = z n ) = n X j =1 Pr( Z n = z n | A n,j ) Pr( A n,j ) + Pr( Z n = z n | B n ) Pr( B n ) . As in th e pro of of Theorem 1 in Nott and Koh n (2005), we can write Pr( Z n = z n | A n,j ) = C 0 ,j + C 1 ,j + · · · + C j − 1 ,j , where C l,j = X z 0 · · · X z n − 1 Pr( Z 0: n − j = z 0: n − j ) π ( z n − j +1 ) j − 1 Y k = l +1 R n − j ( z n − k , z n − k +1 ) R n − l ( z n − l , z n − l +1 ) − R n − j ( z n − l , z n − l +1 ) l − 1 Y k =1 R n − k ( z n − k , z n − k +1 ) F rom part (e) of Lemma 2, C 0 ,j = π ( z n ) a nd b y part (f ) of Lemma 2, | C j,n |≤ K g 0 ( z n ) a n − j ( j − 30 l ) − 1 for j > 1. Using a similar argument to that in Nott and Kohn (200 5 ), this imp lies that j − 1 X l =0 C l,j ≤ π ( z n ) + K g 0 ( z n )( n − j ) − r 1 j 2 . Th us, n X j =1 Pr( Z n = z n | A n,j ) Pr( A n,j ) = π ( z n ) − (1 − ǫ ) n π ( z n ) + η n where | η n | ≤ K n − r 1 n − 1 X j =1 1 − j n − r 1 j 2 ǫ (1 − ǫ ) j − 1 . W e also hav e that Pr( Z n = z n | B n ) = X z 0 · · · X z n − 1 q I ( z 0 ) q I ( z 1 ) n − 1 Y k =1 R k ( z k , z k +1 ) ≤ K g 0 ( z n ) + η n − 1 q I ( z n ) ≤ K g 0 ( z n ) . using Lemma 2 (c) and (3). Hence, | Pr( Z n = z n ) − π ( z n ) | ≤ K g 0 ( z n ) (1 − ǫ ) n + n − r 1 (22) The p r oof of Theorem 1 follo ws. The p r oof of Theorem 2 is similar to that in Nott an d Kohn (2005) if we use (22). 31 Figure 1: Example 1. Left panel: Prop osal distribution (b old) after 15 000 iteratio ns, initialized with a normal φ ( z ; − 5 , 4). The target density (thin) is a u niv ariate mixtur e 0 . 5 φ ( z ; 0 , 1) + 0 . 3 φ ( z ; − 3 , 4) + 0 . 2 φ ( z ; 6 , 0 . 5) . Right p anel: Recursive u p dates of the accep- tance rate in the last 500 iterations. Figure 2: Examp le 2. Prop osal distribution after 35 000 iterati ons. Th e target distribu tion is a 15-dimensional mixture. The graph plots th e tr u e marginal d istributions (thin) for the first and last v ariable together with th e corresp ondin g marginal distributions (b old) implied b y the mixture of n ormals estimated on the f ull history of the dra ws, and with recurs ive up dates of the acceptance rate in the last 500 iteratio ns. 32 Figure 3: Inference for a time v arying p arameter AR(1) mo del for US inflation by Gibb s sampling. (a) marginal distribution of ln( λ 0 ) (b) marginal distribu tion of ln( λ 1 ) (c) marginal distribution λ 1 (d) infl ation plot and mean, estimated as E [( c t / 1 − ρ t ) | y ] (e) m arginal distribution of ρ 0 | y (f ) E ( c t | y ) (b old line) and E ( ρ t | y ) . Figure 4: Inference f or the mo del of figure 3 by adaptive I MH. T he in terpretation of the panels is the same as in figure 3 . 33 Figure 5: Inference for semiparametric mo del of hous in g prices b y adaptive IMH. First ro w: recursiv e acceptance rate for the last min(it,500 ) iterations, recursiv e means of ln( τ i ) , marginal of σ ǫ . Second and third r o ws: marginals of ln( τ i ) . F our th and fifth ro ws: means of β i x + g i ( x ) . 34 Figure 6: Inf er en ce for the daily US-GBP exc hange rate b y AIMH. (a) exc hange rate returns (b) mean of 0 . 5 ln( h t ) (c) marginal of σ v (d) marginal of 0 . 5 exp ( µ ) (e) marginal of ρ (f ) mo ving windo w of the accepta nce rate for the last min(it,500) iterations. 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment