Batch kernel SOM and related Laplacian methods for social network analysis
Large graphs are natural mathematical models for describing the structure of the data in a wide variety of fields, such as web mining, social networks, information retrieval, biological networks, etc. For all these applications, automatic tools are r…
Authors: Romain Boulet (IMT), Bertr, Jouve (IMT)
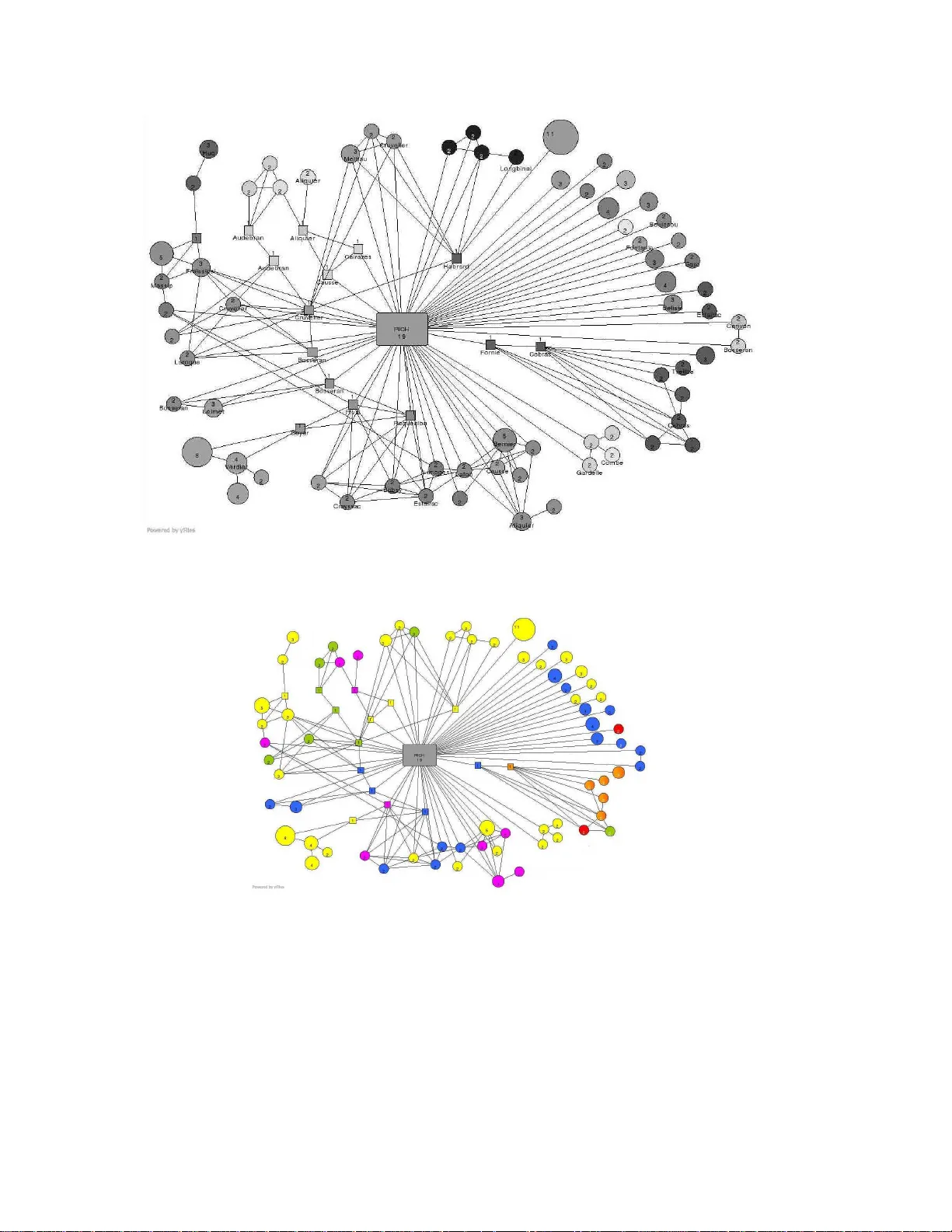
Batc h k ernel SOM and related Laplaci an metho ds for so cial net w ork analysis 1 Romai n Boulet a , Bertr and Jouv e a , F abrice Rossi b , and Nathal ie Villa c a Institut de Math ´ ematiques, Universit´ e de T oulouse et CNRS (U MR 5219), 5 al l´ ees Antonio Machado, 31058 T oulouse c e dex 9, F r anc e b Pr ojet A xIS, IN RIA R o c quenc ourt, Domaine de V oluc e au, R o c quenc ourt, B. P. 105, 78153 L e Chesnay c e dex - F r anc e c Institut de Math ´ ematiques, Univ ersit ´ e de T oulouse et CNRS (UM R 5219), 118 r oute de Narb onne, 31062 T oulouse c e dex 9, F r anc e Abstract Large graph s are natural mathematical mo dels for describ in g the structure of the data in a wid e v ariet y of fields, s uc h as web mining, so cial netw orks, information retriev al, biologica l netw orks, etc. F or all these applications, automat ic tools are required to get a syn thetic view of th e graph and to reac h a go o d understanding of the underlying problem. In particular, disco v ering g roup s of tig htly connected v ertices and understand ing the relations b et w een those groups is ve ry imp ortant in practice. This p ap er sh ows ho w a k ernel version of the batc h Self Organizing Map can b e used to ac hiev e these goals via k ernels deriv ed from the Laplacia n matrix of th e graph, esp ecially when it is used in conjun ction with more classical metho ds based on the sp ectral analysis of the g raph. Th e prop osed method is used to explore the structure of a med iev al so cial net work mo deled through a w eigh ted graph that has b een directly built from a large corpus of agrarian cont racts. Key wor ds: ∗ Corresp ond ing author. Email addr ess: nat halie.vil la@math. univ-toulouse.fr (Na thalie Villa). 1 This wo rk was partially sup p orted b y ANR Pro ject “Graph-Comp”. Preprint submitted to Neuro compu ting 24 Octob er 2018 1 In tro duction Complex networks are lar ge graphs with a non trivial orga nization. They arise naturally in n umerous con text [7], suc h as, to name a few, the W orld Wide W eb (whic h give s a p erfect example of how large a nd complex suc h a netw or k ma y grow), metab o lic path w ay s, citation net w orks betw een scien tific articles or more general social net w orks that model in teraction b et w een individuals and/or organizations, etc. Complex netw orks share common pro p erties that hav e allow ed the emergence of mathematical descriptions suc h as smal l world gr aphs or p ower law gr aphs . The structure of these graphs oft en giv es some k ey s to understand the com- plex net w ork underlined. T o study suc h a structure, one often b egins with a metrology pro cess a pplied to the graph that describ es the degree distribu- tion, t he n um b er of comp onents, the densit y , etc. The second step consists in the searc h o f subgraphs that hav e particular adj a cency , in pa rticular highly connected parts of the gra ph whic h are at the same time lightly connected b e- t w een them. Suc h pa rts are called c omm unities 2 [41,13]. More rece ntly , sev era l directions ha v e b een explored to g o further in mo delling larg e real net w orks, taking into account their dynamics [47], t he at t ributes of the data [35], a more formal definition of the comm unities [42,38 ,3 7], or the relatio ns b et w een com- m unities [40]. Ho w ev er, it should b e noted that dealing with v ery large graphs (millions of vertice s) is still a n op en question (see [9] for an example of an efficien t algorithm to explore tha t kind of data sets). Sev eral w a ys ha v e b een explored to cluster the v ertices of the gr a ph into comm unities [43] and some of them hav e in common the use of the L apla- cian matrix. Indeed, there a re important relationships betw een the sp ec- trum of the L aplacian and the g r a ph in v ariants that c haracterize its struc- ture (see , e.g. [32,33]). These properties can be used for buildin g, fro m the eigen-decomp osition of the Laplacian, a similarit y measure or a metric space suc h that the induced dissimilarities b et w een vertice s of the g raph are r elated to its comm unit y structure (see [13], among others). The Laplacian matrix also app ears when the v ertices of the graph are clustered b y the optimiza- tion o f a graph cut quality measure: optimizing suc h a measure is generally a NP-complete problem but using the prop erties of sp ectrum of the Laplacian pro vides a relaxation based heuristic solution with a reasonable complexit y [1]. In the pres en t pap er, the prop erties of the Laplacian are also use d to iden- 2 It should b e noted that this u se of the term “communit y” while quite standard in compu ter science is dispu ted in other disciplines, e.g., so ciology , wh ere a group of individuals highly conn ected in some sense is n ot alw a ys considered as forming a comm unit y . 2 tify and map comm unities, b oth in a rather classical w ay and with a recen tly prop osed batc h v ersion of the k ernel Self O r ganizing Map (SOM). The com- bination of those to ols giv es complem en tary views of a social netw ork. The sp ectral based approach extracts a sp ecific t yp e of comm unities f o r whic h in- terpretation biases a r e limited, but whic h co v er only part of the graph (e.g., one third of the v ertices in the studied gr a ph). The SOM solution giv es a global map of the v ertices clustered into more informal communities , f o r whic h a link analysis mus t be done with care. Com bining the analysis of these clas- sifications helps in getting some g lobal results while limiting the risk of false in terpretation. In b oth cases, the comm unities’ organization is ass o ciated to a t w o dimensional represen tation that eases in terpretation of their relations. It should b e noted that these represe ntations are not inten ded to comp ete with those coming from the la r ge field of graph draw ing [12,23]: the goal in t his pap er is not to dra w the whole g raph but to extract a comm unit y structure and to pro vide a sk etc h of the orga nization of these small homog eneous so cial groups. The rest of this pap er is organized as follo ws. Section 2 defines p erfe ct c om- munities and uses sp ectral analysis of the Laplacian to iden tify them. An alternativ e and complemen tary approac h is describ ed in Sec tion 3, whe re a kernel is derived from the Laplacian via a form of regularization. This kerne l is used in Section 4 to implemen t a batc h k ernel SOM whic h builds less p er- fect comm unities and maps them o n a tw o dimensional structure t hat resp ects their relationships. Section 5 is dedicated to an application of the prop osed metho ds to a social netw o r k that mo dels in teractions b et w een p easan ts in the F renc h mediev al so ciety . The historical sources (a g rarian con tracts) are first presen ted together with the corresponding so cial netw o rk mo del. Meth- o ds prop osed in Sections 2 and 4 are then a pplied to this graph. Results are compared and confron ted to prior historical knowle dge. 2 Clustering through the searc h of p erfect comm unities Understanding the structure of a large net w ork is a ma jor c hallenge. F ortu- nately , many real world graphs ha v e a no n uniform link densit y: some g roups of v ertices are densely connected b etw een them but sparsely connected to out- side ve rtices. Iden tifying those c o mmunities is v ery useful in practice [38] as they can prov ide a sort of summary which can in turn b e analyzed more easily than the or ig inal graph, especially when h uman exp ertise is requested. How- ev er, there is no cons ensus on a f o rmal definition of a comm unity (see e.g., [41,43]). In the con text of visualization, a particular (and somehow restrictiv e) t yp e of comm unities, the so called p erfe ct c ommunities , leads to interesting results. In addition, this precise form o f commun ities, easy to define and un- 3 derstand, ma y b e view ed as the elemen tary blo c k of the comm unities, in their general meaning. A p erfect comm unit y of a non-w eigh ted graph is a complete subgraph (in suc h a subgraph all v ertices are pairwise link ed by an edge), with at least 2 v ertices, and suc h that all its v ertices ha v e exactly t he same neigh b ors outside the comm unit y . The p erfect comm unities of a w eigh ted graph are obtained as the p erfect comm unities of its induced non- w eigh ted graph (i.e., o f the gra ph ha ving same v ertices and edges but no weigh ts on the edges). In [49], V an den Heuv el and P ejic prop osed that particular form of communit y f or non- w eigh ted gr a phs in the case of frequenc y assignme nt problems. They g ive a differen t definition for w eigh ted graphs; this last one w as not fo llo w ed b ecause it app ears as t o o restrictiv e for more general g r aphs suc h a s those coming from so cial net w orks. A nice a dv an tage of p erfect comm unities ov er lo oser ones is tha t they ha v e simple non am biguous visual represen tations. Indeed p erfect communities can b e represen ted by simple glyphs (circles fo r instance) together with their con- nections to o t her p erfect comm unities without lo osing information: the no des in a p erfect communit y are fully connected (hence eac h simple g lyph sym b ol- izes a complete subgraph) and share the same connections with the outside of the comm unit y (hence the unique represen tation of these connections b y a simple link b et w een t w o glyphs). Ho w ev er, p erfect commun ities don’t pro vide a complete summary of a g r aph. One of their main w eaknesses is that , on real applications, the set of p erfect comm unities can contain only a part (and sometimes a little par t ) of the whole graph. Moreo v er, some of the v ertices that don’t b elong to a perfect comm unit y can play a cen tral role in the structure of the so cial netw ork. Tw o parameters are usually used in so cial net w ork analysis to c haracterize these imp ortant ve rtices: high degree and hig h b et w eenness measure (the definition is giv en b elow). The v ertices with the highest degrees are like ly to ha v e a main role in the graph as they are link ed to a large n um b er of other v ertices. These v ertices ma y a pp ear in a rich-club [56] if it exists . The rich-club o ccurs when the v ertices with highest degree form a dense subgraph with a small diameter. The diameter of a graph is the lo ngest of the shortest path b et w een any tw o giv en v ertices o f a graph and the densit y of a graph is the r a tio b eet w en the nu mber of its edges and the n um b er of the total p ossible edges. The construction of a ric h-club starts from the highest degree v ertices whic h are totally connec ted and follo ws b y adding the next v ertices in t he decreasing order of their degrees. The pro cess stops when the diameter reache s the fixed limit or when the densit y sharply decreases. In practice, the c hosen limit f o r the diameter of the ric h club is v ery small: for a graph having sev eral h undred of v ertices, as the 4 one studied in Section 5 , a diameter of 2 giv es satisfactory r esults. As t he rich club is a subgraph with a small dia meter and a high densit y and as it shares man y connections with the other v ertices of the graph, it can b e se en as a set of p eople ha ving a main so cial ro le by knowing almost ev erybo dy in the comm unit y . All the v ertices of the graph don’t belong to a p erfect comm unity or to the r ich club and some of t hem can still be imp ortant to obtain a go o d summary of the graph. Another intere sting feature to lo calize relev ant v ertices is to lo ok at the b etwe enn ess me asur e of the vertice s. The b et w eenness measure of a v ertex is the frequency of the shortest paths of a ny tw o v ertices o f the graph in whic h this v ertex o ccurs. These v ertices also ha v e a main role a s they ar e es sen tial to connect t he whole gr aph. In so cial net w orks, they can b e seen as mediating p ersons that link together subgroups that w ould b e otherwise unrelated. The n umber of high b etw eenness v ertices is c hosen according to the follow- ing heuristic. V ertices are sorted in decreasing order of b et w eenness and the n um b er of connected comp o nen ts of eac h subgraph S k induced b y the p erfect comm unities, the rich -club and the first k v ertices with highest b et w eenness measure is computed. In general, the decrease of this num ber with k is non uniform: sharp dro ps are separated b y constan t (flat) regions (see Figure 3 for an example). As imp ortant vertice s a re those that significantly reduce the n um b er of connected comp onen ts, it seems logical to consider a v alue of k that lies just after a significan t drop. The actual selection of k remains ho w ev er a matter of compromise as there are generally se v eral significan t decreases in the n um b er of comp onents: adding to o m uc h no des will clutter the visualization while leaving out to o many will miss some imp ortant individuals. Section 5.3 pro vides an example of suc h compromise. The final set of selected ve rtices a r e called c e n tr al vertic es . Adding the ric h-club and the cen tral v ertices to p erfect comm unities enhances the cov erage of the original graph while main taining an easy visual represen- tation. The first step consists in using adding glyphs for central v ertices. As already explained ab o v e, links from a p erfect comm unit y to an y v ertex is un- am biguous and therefore the edges betw een perfect communities and cen tral v ertices (as w ell as b et w een tho se v ertices) can b e added without difficult y . The only compromise concerns the ric h-club. It is also represen ted b y a sp ecific glyph whic h do es not show therefore its substructure. Another simplific ation is used for links: an edge b et w een the ric h-club and a n y o ther elemen t (a cen tral v ertex or a comm unit y) summarizes a p ossibly complex link structure. P erfect comm unities are not only easy to visualize; their computation is also straigh tforward, as describ ed b elo w. Let us first introduce some notations. G denotes a connected graph with v ertices V = { x 1 , . . . , x n } and a set of undirected edges E , with p ositiv e we ights, w i,j = w j,i ( w i,j = 0 is equiv alen t 5 to { x i , x j } / ∈ E ). The degree of a v ertex x i is denoted d i = P n j =1 w i,j . The structure of G can b e summarized through a symmetric n × n matrix called the L apla c ian of G . This matrix has been in tensiv ely studie d the past y ears b ecause many imp orta n t structural and top ological prop erties can b e deduced from it. The Laplacian of G is defined as the p ositiv e and semi-definite ma t rix L = ( L i,j ) i,j =1 ,...,n suc h that L i,j = − w i,j if i 6 = j, d i if i = j. W e will also consider the Laplacian, denoted b y e L , of t he non-weigh ted graph induced b y G , e G . Sp ectral prop erties of the L a placian can b e used t o cluste r the v ertices of a graph. First of all, it is w ell kno wn that the eigen v alue 0 is related to the minim um n um b er of connected sub graphs in G [32]. In the same w a y , a sp ectral analysis of the Laplacian allow s one to find p erfect communities , using the follo wing prop ert y (a set of v ertices is called non- stable if it contains at least t w o adjacent vertice s): Theorem 1 ([49]) A non-stable set S of vertic es is a p erfe ct c o mmunity if and on l y if ther e is a non -zer o eigenvalue, λ , of e L whose multiplicity is at le a s t k − 1 and such that the k − 1 as s o ciate d eigenve ctors vanis h for the same n − k c o or dinates. Then, the c ar dinal of S is k , the c o or dinates fo r w hich the k − 1 eigenve ctors ar e not 0 r epr esent the vertic es b elong i n g to S and λ = d + 1 wher e d is the de gr e e of a v ertex of S . As a conseque nce, lo oking at n ull co ordinat es of the eigen v ectors of e L is a simple and efficien t w ay to ex tract p erf ect commu nities. Moreo v er, we also ha v e the following prop ert y , that will help to understand the link b et w een this approac h and the w ell-know n sp ectral clustering metho d: Corollary 2 I f a set of vertic es, S , is a p erfe ct c ommunity then the n − k + 1 eigenve ctors that do no t define S have c onstant c o or dinates for the in dic es of the vertic es of S . Pro of Without loss of generality , S is ren um b ered as S = { 1 , . . . , k } . An eigen v ec tor u defining S can b e written as u = ( u 1 , ..., u k , 0 , 0 , ..., 0). Let z = ( z 1 , ..., z k , z k +1 , ..., z n ) b e an eigen v ector that do es no t define S and note ˜ u = ( u 1 , ..., u k ), ˜ z = ( z 1 , ..., z k ). As e L is symmetric, z is orthogonal to the k − 1 eigen v ectors that define S so ˜ z is orthogonal to the k − 1 v ectors ˜ u for u defining S . But u is an eigenv ector of e L , so it is orthog onal to the vec tor 6 1 n = (1 , 1 , . . . , 1) (related to the eigen v a lue 0) and so, ˜ u is orthogonal to the v ec tor 1 k in R k . The orthogonal complemen t, in R k , of the v ector space spanned b y the k − 1 v ectors ˜ u has dimension one and is spanned by 1 k ; it follo ws that ˜ z is co-linear to 1 k whic h concludes the pro of. 3 Similarit y measures built from t he Laplacian Some weakne sses of a represen tation b y p erfect comm unities are the absence of a lot of v ertices ( f or instance, only 35 % of the whole graph b elongs to a p erfect comm unit y in the social net w ork studied in Section 5) and the presenc e of a lot of v ery small comm unities. Moreov er, some r elev an t groupings of p er- fect communities might b e missed and a bia s of the in terpretation can o ccur from these lac ks. In this sense, the definition of perfect comm unities giv es a to o restrictiv e clus tering of the v ertices. It is therefore reasonable to comple- men t it with the help of another clustering algorithm chos en in the numerous metho ds prop osed f o r this task [43]. A broad class o f those metho ds consists in building a (dis)similarity measure b et w een v ertices that capture the notion of comm unit y and then on applying a n adapted clustering algorithm to the dissimilarit y matrix. T o pursue this goal, this section in tro duces existing similarit y measures based on the Laplacian. Section 3.1 explains how to build a similarit y measure that is able to separate comm unities from eac h others and Section 3.2 follo ws a similar idea to define a kernel that maps the v ertices in a hig h dimensional space. The purp ose of the those sections is to emphasize the links and also t he differences b et w een the eigen v alue approach describ ed in the previous section, the usual “sp ectral clustering” approac h a nd the w ell-kno wn diffusion kernel whic h can b e considered as a smo oth sp ectral clustering. 3.1 F r om almost p erfe ct c o m munities to gr aph cuts One wa y to o btain an optimal clustering of t he v ertices of a g raph is t o mini- mize the follow ing gr aph cut qualit y measure cut( S 1 , . . . , S p ) = p X i =1 W ( S i , G \ S i ) , where S 1 , . . . , S p is a par t ition of V (for a c hosen p in N ∗ ), and where W ( S, S ′ ) = P i ∈ S,j ∈ S ′ w i,j for t w o giv en sets of v ertices S and S ′ included in V . This optimization problem is NP complete fo r p > 2 but it can b e r elaxe d 7 in to a simpler problem (see, e.g., [53]): min H ∈ R n × p T r( H T LH ) sub ject to H T H = I p . (1) The k ey p oin t in the relaxation approach is to extend the searc h space from a discrete set in whic h the co efficien ts of H define a partition of { 1 , . . . , n } , to R n × p . F or a connected gr aph, the solution of the relaxed problem is the matrix H whic h con tains the p eigen v ectors asso ciated to the p smallest p ositiv e eigen v alues of L as columns. O f course, the real-v a lued solution pro vided by the matrix H has to be con v erted in to a discrete partition of p clusters. A usual w a y to do do is to consider the solution matrix H as a w ay to map v ertices of the graph in R p as follo ws: F L : x i ∈ V → ( h (1) i , . . . , h ( p ) i ) ∈ R p , (2) where ( h ( j ) ) j is an ortho no rmal set of eigen v ectors asso ciated to the p smallest p ositiv e eigenv alues ( λ j ) j =1 ,...,p ( h ( j ) i denotes the i th co ordinate of the j th small- est p ositiv e eigen v alue). Then a standard clustering alg o rithm in R p (e.g., the k -means algor it hm) is applied to the mapp ed no des (this can b een seen as a clustering of the ro ws of H ), leading to one v a rian t of sp e ctr al clustering . This metho d is strongly related to p erfect comm unities calculation. Corollary 2 sho ws that ve rtices that belong to the same p erfect commun ities hav e the same co ordinates for man y eigen v ectors. As a consequence, any clustering algorithm applied on nodes mapp ed via F L will tend to gather v ertices from a p erfect comm unitiy in the same cluster. In this sense, sp ectral clustering can b e seen as a r elaxed v ersion of the searc h of p erfect comm unities. It should b e noted tha t t he sp ectral clus tering metho d summarized ab o v e giv es equal w eigh ts to the first p eigen v ectors of the Laplacian, whereas the smaller the eigen v alue is, the more imp o r t a n t the corresponding eigen vector is. Moreov er, only the first p eigen v a lues are used and, hence, this approac h do esn’t use the entire information provided by the Laplacian. T o a v oid these problems, a regula r ized v ersion of the La placian can b e used, as sho wn in the follo wing section. 3.2 Diffusion kernel In [46], the authors in v estigate a family of k ernels on graphs based o n t he notion of regular izat io n op erators: a regularizatio n f unction is applied to the Laplacian and g ives a family of matrices that are also k ernels on V × V . In the presen t pap er, we fo cus on the diffusion kernel : 8 Definition 3 The diffusion m atrix of the g r ap h G for the p ar ameter β > 0 is D β = e − β L . The di ffusion kern el of the gr aph G is the function K β : ( x i , x j ) ∈ V × V → D β i,j ∈ R The diffusion matrix is easy to compute for graphs ha ving less than a few h undred of v ertices b y the w a y of an eigen-decomp osition of the Laplacian: if ( h ( i ) ) i =0 ,...,n − 1 are orthonormal eigenv ectors asso ciated to the eigen v alues 0 = λ 0 < λ 1 ≤ λ 2 ≤ . . . ≤ λ n − 1 of L , t hen D β = n − 1 X k =0 e − β λ k h ( k ) h ( k ) T . (3) This diffusion k ernel has b een in tensiv ely studied through the past y ears. In particular, [29] sho ws that this k ernel is t he con tin uous limit of a diffusion pro cess on the graph: K β ( x i , x j ) can b e view ed as the v alue of the energy obtained in v ertex x j after a time tending to infinit y if energy ha s b een injected in v ertex x j at time 0 and if diffusion is con tin uously done among the edges of the g raph. In this case, β is r elat ed to the in tensit y of the diffusion (see also [8] for a complete description of the prop erties of this op erator). It is easy t o pro v e tha t the k ernel K β is symmetric and definite p ositiv e. Then, from Aronsza jn’s Theorem [4,6], there is a Repro ducing Kernel Hilb ert Space (RKHS), ( H β , h ., . i β ), called t he feature space, and a mapping f unction, φ β : V → H β suc h that: for all i, j, h φ β ( x i ) , φ β ( x j ) i β = K β ( x i , x j ) . As in the previous section, this mapping pro vides a w ay to apply standard clustering algorithms to the v ertices of a g raph, simply b y w orking on their mapp ed v alues. In addition, a kernel trick can b e used in man y cases to av oid calculating explicitly the mapping (see Section 4.3 for details). Equation (3) sho ws that the mapping induced by the kerne l is equiv a lent to the follo wing one: F β K : x i ∈ V → ( h (1) i , . . . , h ( n ) i ) ∈ ( R n , h ., . i β n ) , (4) where R n is considered with a sp ecific inner pro duct giv en by h z , z ′ i β n = P n − 1 k =0 e − β λ k z k z ′ k for all z and z ′ in R n . Once again, a s stated b y Corollary 2, the v ertices that b elong to the same p erfect communit y hav e v ery close images b y F β K . How eve r t he em b edding 9 pro vided b y F L (see equation (2)) uses only a part of the spectrum and will therefore lo o se some neigh b orho o d informations. F or ex ample, v ertices that b elong t o t w o different p erfect communities can b e indistinguishable. On the con trary , F β K uses the whole eigen-decomp osition but with a mo dified metric that con tains non lo cal informat io n. This approach is v ery flexible b ecause the parameter β p ermits t o control the degree of smo o thing: a small v a lue of β regula r izes heav ily and totally forbid to cluster together tw o v ertices that are not directly linke d to eac h others whereas a large β allo ws to cluster v ertice s that are not directly connected but share a large n um ber of common neigh b ors. This mak es this k ernel an attractiv e to ol whic h is quite p opular in the computational biology area wh ere it has b een used with success t o extract pathw a y activit y from gene expression data through a graph of genes [50,45]. 4 Kernel SOM for clustering the v ertices of a graph 4.1 Motivations for the use of the SOM algorithm Our purp ose is to pro vide a description of the graph by clustering its v ertices in to relev an t comm unities. How eve r, clu stering a lo ne do esn’t alw ays provid e a clear picture of the glob al structure of a graph. As already men tioned, on the one hand, p erfect communitie s are easy to understand but generally don’t co v er the whole graph, while, on the other hand, clusters that are not p erfect comm unities hav e complex relations o ne to another: a link b etw een t w o clus- ters hides a p oten tially complex link structure b et w een individuals in those clusters. A solutio n to circum v en t those pro blems is t o cluster the v ertices of the graph in a wa y that b oth leads to imp erfect communities but also tak es in to accoun t relations b et w een clusters. T o ac hiev e these goals, one can lev erage the top ology preserv ation prop er- ties of the Se lf Organizing Map (SOM). This algo rithm, first introduced b y Kohonen [27], is an unsup ervised metho d tha t performs at the same time a clustering and a non linear pro jection of a dataset. The SOM is based on a set of mo dels (also called neur ons or units ) arra ng ed according to a low di- mensional structure (generally a regular g r id in one or tw o dimensions). The original data are partit ioned in to as many homogeneous clusters as t here are mo dels, in suc h a w a y that close clusters (according to the prior structure) con tain close data p oints in the orig ina l space. The analysis of the v ertices of a graph with a SOM will therefore pro vide a t yp e o f relaxed comm unities (the clusters) ar ranged in a wa y that is consisten t 10 with the link structure of the mem b ers of those comm unities, as long as the graph structure can b e turned in to a top ology tha t the SOM will preserv e. 4.2 SOM for non ve ctor data The standard SOM algo r ithm uses the euclidean structure of the da t a space and therefore cannot b e applied directly to v ertices of a gra ph. As non vec tor data arise naturally in man y real w orld problems, adapted v arian ts of the SOM hav e receiv ed a lot of atten tion in the pa st ten y ears. It should first b e noted that the general structured data framew ork prop o sed in [21] cannot b e applied to v ertices of a gra ph: the framew ork is adapted to the case where eac h observ ation is a whole graph, not to the one that fo cuses on the no des of a single graph. A possible solution in this situation (explored in [51]) w ould b e to use one of the v arian ts of the Me dian SOM (also called the dissimilarity SOM , see [2,26,25,28,14]). Mem b ers of this class o f algorithms can b e applied to an y dataset on which a dissimilarit y measure can b e defined: num erous diss imi- larit y measures for graph no des hav e b een prop o sed for g r a ph clustering (see [43]) and could therefore b e used with a dissimilarity SO M. Those SOM al- gorithms are ba sed on a generalization of the notio n of cen ter of mass called a generalized median ( f ast implemen tations are a v ailable [10]). Another v ari- an t of the SOM for dissimilarit y data, based on mean field annealing, could also b e used [17,18], as well a s the r ecen tly in tro duced r elat io nal to p ographic mappings [19,20]. The solution prop osed in this pap er is to rely on a k ernelized v ersion of the SOM: this is a natural c hoice in t he sense that graphs are w ell described b y their Laplacian and the corresponding heat k ernels. As show n in [52 ], if the dissimilarit y b et w een ob jects is defined via a ke rnel, the median SOM is a ty p e of constrained k ernel SOM. Moreo v er, the constrain ts of t he median SOM generally induce maps of lesser quality than those obtained b y the ke rnel v ersion. F urther links b etw een b oth approach es ar e outlined in [19,2 0]. In the prop osed ke rnel approac h, detailed in the next paragraph, the vertice s are first implicitly mapp ed in to a feature space whose geometry reflects the graph structure. This implicit mapping is p erformed via the so called “k ernel tric k”, b y using the diffus ion ke rnel. Then, a batc h SOM is applied in this space to p erform a nonlinear pro jection of the v ertices and, at the same time, a clustering, that will b oth respect the to p ology of the feature space and therefore of the graph. An alternativ e (and in fact quite similar) solution w ould be to rely on a n em b edding, i.e., on a n explicit mapping of the no des of the graph to R p , exactly 11 as this is done in the sp ectral clus tering approac h (see [11,16,53]). Rather than applying a k -means algorithm to the v ector represen tation of t he v ertices obtained via the mapping F L (see equation (2)), one can simply use a standard SOM. F or the applicatio n studied in this pap er ( the so cial net w ork presen ted in Section 5), this solution p erformed p o orly . While the ov era ll organization of the obtained map w as go o d, the clusters w ere m uc h more un balanced: a large cluster con tained t w o third of the v ertices , while other clusters were quite small (one or tw o vertice s). This is not ve ry surprising as the heat k ernel helps to distinguish b et w een v ertices tha t could seem similar if they are represen ted b y t he informatio n restricted to the smallest eigen v ectors of the Laplacian (as explained in Sections 3.1 and 3.2). Nev ertheless , it should b e noted that the imp o rtan t aspect of the prop o sed metho d is to rely on an adapted v ariant of the Self-Orga nizing Map to p erfo rm at the same time graph clustering and graph visualization. In the particular application studied in Section 5, the heat ke rnel (and therefore the bat ch k ernel SOM) giv es inte resting results. In ot her applications, b etter results might b e obtained with other k ernels, with dissimilarities (via a dissimilarit y SOM) or with em b edding (via a standard SOM). The n umerous SOM v arian ts provide a general framew ork for gra ph mining: the presen t article explores only one of its p ossible concrete implemen tation. 4.3 Batch ke rnel SOM Sev eral kerneliz ed v ersion of the SOM hav e b een pro p osed [30,3 ,52]. The presen t pap er uses a batc h v ersion of the k ernel SOM pr o p osed in [5 2 ,20]. An adv an tage of the batch k ernel SOM, with respect to the stochastic v er- sions prop osed b efore, is that the former generally conv erges m uc h f a ster than the latter. As stated ab ov e, the k ernel batc h SOM first maps the original data in to a high- dimensional Hilb ert space H via a f eat ur e map φ . Then , the standard batc h SOM is applied to the mapp ed data. As with most k ernelized algorithms, the mapping has no t to b e explicitly carried o ut. The batch SOM can b e rewritten in suc h a w a y to use only the inner pro duct of the Hilb ert space: rather than defining H and φ , one has o nly to sp ecify a kernel K o n the o riginal data set, as this generates an asso ciated Repro ducing Kernel Hilb ert Space. Let us first describ e the batc h SOM on the mapp ed data. The prior structure consists in M neurons. The distance b et w een neurons i and j in the prior structure is denoted h ( i, j ). It is transformed into a neighborho o d function via a decreasing function R , fro m R + to R + , with R (0) = 1 and lim s → + ∞ R ( s ) = 0. The influenc e of the grid is annealed through time: at iteration l , the algorithm 12 uses a function R l , based on R , that is more and mor e concentrated in 0. A t iteratio n l , neuron j is asso ciat ed to a proto t yp e (also called a co de b o ok v ector) p l j , c hosen in H , but constrained to b e a linear com bination o f the mapp ed data (as suggested in [30]), i.e. p l j = n X i =1 γ l ij φ ( x i ) . The batc h k ernel SOM is then give n by Algorithm 1. It can b e simplified b y Algorithm 1 The Batch Kernel SOM in feature space 1: c ho ose initial v alues f or γ 0 j i in R 2: p 0 j ← P n i =1 γ 0 j i φ ( x i ) 3: for l = 1 to L do 4: for i = 1 to n do { represen tation step } 5: assign the observ ation x i to it s closest neuron: f l ( x i ) = a rg min j =1 ,...,M k φ ( x i ) − p l − 1 j k 6: end for 7: for j = 1 to M do { assignmen t step } 8: up date prototype p j according to p l j = ar g min p = P n i =1 γ i φ ( x i ) , γ ∈ R n n X i =1 R l ( h ( f l ( x i ) , j )) k φ ( x i ) − p k 2 9: end for 10: end for using the so called “ke rnel trick”, whic h simply consists in expressing op era- tions in H solely via K . In Algorithm 1, the v alue of k φ ( x i ) − P n j =1 γ j φ ( x j ) k has to b e computed fo r an y linear combination P j γ j φ ( x j ). This can b e done via the follo wing formulation φ ( x i ) − n X j =1 γ j φ ( x j ) 2 = k φ ( x i ) k 2 + n X j =1 γ j φ ( x j ) 2 − 2 n X j =1 γ j h φ ( x i ) , φ ( x j ) i . By definition, k φ ( x i ) k 2 = K ( x i , x i ) and h φ ( x i ) , φ ( x j ) i = K ( x i , x j ). Moreov er n X j =1 γ j φ ( x j ) 2 = n X j =1 n X j ′ =1 γ j γ j ′ h φ ( x j ) , φ ( x j ′ ) i = n X j =1 n X j ′ =1 γ j γ j ′ K ( x j , x j ′ ) . Therefore, the assignmen t step of Algorit hm 1 simply reduces to f l ( x i ) = arg min j =1 ,...,M n X u,v =1 γ l − 1 j u γ l − 1 j v K ( x u , x v ) − 2 n X u =1 γ l − 1 j u K ( x u , x i ) , 13 as K ( x i , x i ) is fixed. Moreov er, the solution of the minimization problem of the represen tation step is giv en b y p l j = P n i =1 R l ( h ( f l ( x i ) ,j )) φ ( x i ) P n i =1 R l ( h ( f l ( x i ) ,j )) 3 and therefore the represen tation step can b e simplified into γ l j i = R l ( h ( f l ( x i ) , j )) P n u =1 R l ( h ( f l ( x u ) , j ) . In practice, the p l j don’t hav e to b e explicitly calculated, as f l is computed directly from the γ l j i . It app ears also clearly that φ has not t o b e use d and therefore that Algorithm 1 can b e rewritten into the simpler Algor ithm 2. Algorithm 2 The Batch Kernel SOM (simplified ve rsion) 1: c ho ose initial v alues f or γ 0 j i in R 2: for l = 1 to L do 3: for i = 1 to n do { assignmen t step } 4: assign the observ ation x i to it s closest neuron: f l ( x i ) = arg min j =1 ,...,M n X u,v =1 γ l − 1 j u γ l − 1 j v K ( x u , x v ) − 2 n X u =1 γ l − 1 j u K ( x u , x i ) 5: end for 6: for j = 1 to M do { represen tation step } 7: up date prototype co or dina t es γ j i according to γ l j i = R l ( h ( f l ( x i ) , j )) P n u =1 R l ( h ( f l ( x u ) , j ) . 8: end for 9: end for 4.4 Implementation details It is w ell kno wn that the results of ba tc h SOM strongly dep end on the init ia l- ization p oint, and also, but with a more limited scale, on the sp ecific imple- men tation c hoice. In the presen t pap er, the prior structure is a bi-dimensional regular square grid for whic h h is giv en by the euclide an distance b et w een the neurons. The neigh b orho o d function R is a Gaussian function and generates a fam- ily R l ( x ) = exp( − x 2 /T l ). The parameter T l is a temp erature lik e parameter whic h decreases ov er time in a geometrical annealing pro cess (i.e., of the form 3 this sho ws that c ho osing p r otot yp es in the subspace spanned b y the mapp ed data in tro du ces in fact no constrain t on them. 14 T l = T 0 λ l ). The temp erature is ke pt constan t until stabilization of the assign- men t step (i.e., until f l = f l − 1 ) and then decreased. This pro cess is rep eated un til the temp erature is low enough to ha v e R l ( x ) = 1 for x = 0 and R l ( x ) ≃ 0 for x > 0: this ensures that the algorithm will end with a final lo cal org a ni- zation b eha vior. This pro cedure is quite standard for batc h v ariants of the SOM. Tw o classical initialization s trategies ha v e b een tested. In the first one, the initial prototy p es ar e rando mly c ho sen among the original mapp ed data. In practice, this is do ne b y setting γ 0 j i to δ i,k j , where δ u,v = 1 if and only if u = v and where k j is ra ndomly c hosen in 1 , . . . , n . The second initialization is a ke rnelization of the classical Principal Compo nen t based metho d [27]. A Principal Comp onen t Analysis (PCA) is conducted on the mapp ed data (this is therefore a k ernel-PCA [44]) to disco v er the tw o principal directions. Then a regular square g r id is built on the tw o dimensional subspace spanned b y tho se directions. Co ordinates of the v ertices of the g r id a re used as initial v alues for the pro tot yp es: this can b e done easily as the principal directions are g iv en as linear com binations of the mapp ed dat a . 4.5 Comp aring Maps A final pro blem is to c ho ose the free pa rameters of the SOM, most imp ortantly the size of the grid and, in our case, the parameter β o f the diffusion ke rnel. This latter parameter induces sp ecific difficulties a s the RKHS asso ciated to differen t v alues of β use differen t metrics and cannot therefore b e directly compared. It is also w ell know that the final quantiz ation erro r E = n X i =1 k φ ( x i ) − p L f L ( x i ) k 2 , decreases with the n um b er of clusters and fails also to measure t o p ology preser- v atio n. The problem of assess ing the qualit y of a SOM has generated a large literature. Among all the prop osed top olo g y preserv ation measures, the one prop osed b y Kaski and Lagus in [24] seemed to b e we ll adapted to the considered problem. F or the ke rnel SO M, the criterion is given by KL = 1 n n X i =1 φ ( x i ) − p L f L ( x i ) + min ( j 0 ,...,j q ) ∈C i q − 1 X k =0 p L j k − p L j k +1 , where C i is the set of all paths in the prior structure star t ing from j 0 = f L ( x i ) (the b est match ing unit for x i ), ending with j q the second b est matching unit for x i and suc h that j k and j k +1 are direct neighbors in the prior structure. 15 The first part of the criterion is exactly the quan tization error, whe reas the second term correspo nds to a t yp e of contin uit y measure. This term is small when close p oints in the mapp ed space hav e con tiguous b est matching units in the map. In the gra ph con text, this translates to the follo wing statemen t: v ertices that are close to eac h others in the feature space giv en b y equation (4) should b e mapp ed to close units on the map. It should b e noted that ev en if the first term of this criterion decreas es with the size of the map, this is balanced by the second term as a small quantization error cannot b e ac hiev ed with v ery close protot yp es. The criterion can therefore b e used to compare differen t sizes for the map, ev en if it ’s likely to fav or larg e maps. In addition to Kaski and La g us’ measure, the q -mo dularity [36] w as also con- sidered. This graph clustering p erformance criterion is defined by Q modul = P M j =1 ( e j − a 2 j ) 1 − P M j =1 a 2 j , where e j is the fraction of edges in the graph that connect t w o vertice s in cluster j and a j is the f raction of edges in the graph that connect to one v ertex in cluster j . A high q -mo dularity means that vertice s are we ll clustered in to dense su bgraphs ha ving few edges b etw een t hem. T he measure is only based o n the clustering r esult and can therefore b e used to compare e.g., t w o differen t v alues of the β parameter. 5 Mining a mediev al so cial net w ork 5.1 Motivations In the F renc h mediev al so ciet y , peasants constitute 90% of the w hole p opu- lation. Despite this ma jorit y p osition, historic studies are mainly conce rned b y the dominan t classes (nobilit y a nd clergy) b ecause peasants left v ery few written do cumen ts compared to the w ell-educated part of the p opulation. As a consequence, historic studies o n these p erio ds often describ e a n anon ymous p easan t comm unity related to a master, a seignory or a c h urch . In order to circum v en t this difficult y , another ap- proac h has b een pursued. The main principle is t o rely on agrarian contracts as a source of infor ma t io n ab o ut so cial b ounds b etw een p ersons. W e fo cus o n a tin y geographical lo cation (sev eral thousand hectares) for whic h a large do cumen tation has b een collected (see [22] for a complete pre- sen tation). This do cumen tation is made from abo ut 1000 agrarian contracts 16 coming from ab out 10 villages lo cated in the Castelnau-Mon tratier s eignory whic h is a small area (ab out 30 km times 30 km) lo cated in So uth W est of F rance (Lot , in the rectangle on the right sided map). These contracts w ere first written betw een 1250 and 135 0 and esp ecially during the first 20 y ears of the XIV ◦ cen tury . After 1350, the do cumentation suddenly decreases be- cause of the Hundred Y ears’ W ar. All the con tracts share common pro p erties: they describ ed land hiring , sales, legations and so on, they men tion the name of the peasant (or the p easan ts) conce rned b y t he transaction, the names of the lord a nd the notary with whom the p easants are related to , some of the neigh b ors of the p easan ts a nd v a rious other informations (suc h as the t yp e of transaction, the lo cation, the date, and so on). Ab out 50 00 additional similar con tracts ar e still to b e recorded. T he whole corpus, whic h is k ept at Cahors (Arc hiv es Nationales du Lot, F rance), has b een totally rewritten during the XIX ◦ cen tury and is therefore a v ery inte resting source for historians as most of these types of contracts ha v e b een destroy ed, esp ecially during the frenc h rev olution. A so ciability net w ork of this p easan t so ciet y can b e constructed from the corpus. Because of the size and the com- plexit y of the obtained graph, automatic to o ls are needed to understand it. The sp ecific goal is to help his torians to ha v e a synthe tic view of the so cial organization of the p easan t comm unities during the Middle Ages. 5.2 First description o f the gr aph The corpus of agra rian con tracts has partia lly b een sav ed on a databa se. F rom this database, a relational g r a ph is built according to directiv es pro vided b y the historians and summarized b elo w. Eac h v ertex of the graph corresp onds to o ne p erson named in the contracts. First, nobles and notaries are remo v ed from the analyzed graph b ecause they are named in almost eve ry con tracts: they a r e o bvious cen tral individuals in the so cial relatio nships and could mask other imp ortant tendencie s in the organization of the p easan t so ciet y . Then, t w o p ersons a re link ed together if: • they app ear in a same contract, • they app ear in tw o differen t con tracts whic h differ from less than 15 y ears and on whic h they a re related to the same lord or t o the same nota ry . The three main lords of the area (Calstelnau Ra t ier I I, I I I and Aym eric de Gourdon) are not tak en into a ccount for this last rule b ecause almost all the peasants are related to o ne of these lords. The links are w eigh ted b y the n um b er o f con tracts satisfying one of the sp ecified conditions. F ina lly , the a nalysis is restricted to the largest connected comp onen t of the obtained graph: it con tains more than 80% o f its ve rtices. 17 This graph G has 615 v ertices a nd 4 193 edges. The sum of the w eigh ts is 40 329, but almost 50% of the edges ha v e a w eight 1 and less than 2% ha v e a w eight greater than 100. A simple represen tation of the graph is giv en in Figure 1 (this figure has b een made by the use of a force directed algorithm p erformed b y the op en source gr a ph drawing soft w are T ulip 4 [5] ). Fig. 1. Repr esen tation of the m ediev al so cial netw ork with force directed algorithm As this is frequen tly the case, the obtained s o cial net w ork is a s mall-world net w ork with lo w global connectivit y and a high lo c al c onne ctivity [55 ,54]. Indeed the diameter of G is 10 and the mean of the shortest paths b et w een t w o v ertices is 3 . 9. The lo cal connectivity , measured b y a v eraging the densit y of subgraphs induced b y the direct neigh b ors of a v ertex [54], is 77% whereas the dens ity of the graph is only 2 . 2%. The degree distribution also ob eys to standards (see [15,39,34]): t he cumulativ e degree distribution for the w eigh ted graph fits a p o w er-law with a fast deca ying tail as sho wn in Figure 2. It follo ws that the n um b er of v ertices ha ving a degree k is decreasing v ery fast (exp onen tially) when k increases and is not centere d on a mean v a lue: most of the p easan ts hav e a small n um b er of relationships and a tin y num ber of them ha v e nume rous relationships. 5.3 Clustering the me die val gr aph into p erfe ct c ommunities and rich-club By the use of Theorem 1 , all the p erfect communities of a graph G can be computed. They emphas ize the main dense pa r ts of the so cial net w orks but also discriminate individuals b y their relationships (direct neigh b ors). 76 p er- fect comm unities w ere found in G , most of them b eing v ery small ( only 2 or 3 p ersons). 4 a v aliable at http: //www.la bri.fr/pe rso/auber/projects/tulip/ 18 0 1000 2000 3000 4000 0.0 0.2 0.4 0.6 0.8 1.0 k Frequency of vertices having a degree higher than k Fig. 2. Cu m ulativ e d egree distrib u tion (solid) of the we igh ted graph fi tting P ( k ) = 1 . 12 k − 0 . 37 e − 0 . 0009 k (dashed). Then, as describ ed in Section 2, the ric h-club and cen tral v ertices are ex- tracted. The vertice s in the rich club corresp onds to the largest subgraph with highest degrees v ertices ha ving a diameter equal to 2. The ric h club contains 3% of the v ertices of the whole gra ph which corresp onds to 19 vertices . This subgraph has a high densit y as sho wn in Figure 3. Cen t r al v ertices are c ho- 0.2 0.5 1.0 2.0 5.0 20.0 50.0 0.02 0.05 0.10 0.20 0.50 1.00 percentage of vertices with highest degrees density of the induced subgraph 0.00 0.02 0.04 0.06 0.08 0.10 2 4 6 8 10 12 14 16 percentage of vertices of highest betweenness centrality number of components in the subgraph of perfect communities Fig. 3. Left: Densit y of the indu ced subgraph as a function of the num b er of highest degrees ve rtices (lo g scale) and Righ t: Nu m b er of comp onen ts of th e subgraph of p erfect communit y and r ic h club as a function of th e num b er of vertic es with high b et wee nness measure added (in b oth cases, th e n umb er of vertic es un der consid er - ation is giv en as a p ercen tage of the total num b er of vertic es in the graph). 19 sen t o b e the 4% of the highest b et w eenness measure v ertices o f t he whole graph (i.e., 24 v ertices). As show in Figure 3, it is a go o d compromise for this application: t he deriv ed subgraph con tains 8 comp onen ts and a large num ber of v ertices is needed to decrease this n um b er aga in. Moreo v er, except for one of them, these comp o nen ts a r e t iny single p erfect communities that won’t b e considered in the follo wing. Figure 4 5 pro vides a represen t ation of the p erfect communities structure o f the mediev al so cial netw ork together with the ric h-club and cen tral ve rtices. The visual represen tation of eac h p erfect comm unit y ha s sev eral features. The surface o f each disk is prop ortional to the size of the p erfect communit y (i.e., to the num ber of p easants in the p erfect comm unit y) which is also rec alled explicitly by a num ber written inside the circle. The gray lev el of the disk en- co de the mean date of the contracts in whic h the members of the comm unit y are inv o lved (from black, 1260 , to white, 1340). In addition a family name is added when the corresp onding p erfect comm unit y comes from a single family . The comm unities are set at random p ositions but efforts ha v e b een done to represen t p erfect comm unities that a re linked b y an edge at nearby p ositions. Tw o p erfect comm unities that are link ed by an edge form a complete subgraph but the p easan ts in t his subgraph do not necessarily hav e the same outside relationships; on the con trary , t w o peasants con tained in the same p erfect com- m unit y hav e exactly the same outside links. Links starting from a comm unit y are therefore v alid f o r all the mem b ers of this comm unit y . Sev en comm unities, that are still not connected with another p erfect comm unit y , with the ric h club or with one of the v ertices with a high b etw eenness measure, w ere not considered for this represen tation. Figure 5 6 pro vides an alternative repre sen tation of the comm unities of the graph. Noting that the peasants of a p erfect communit y liv ed at the same geographical lo cation, eac h perfect comm unit y is colored to represe nt this lo cation. The comm unities are set a t the same p ositions as in Figure 4. Of course, these represen tations ha v e to be interpre ted with care; some of their prop erties could induce interpre tatio n bia ses. One of the main limitatio n is that only a part of the v ertices of the o r ig inal graph is represen ted on it (35 % o f them). Moreo v er, the resp ectiv e p ositions of the p erfect comm unities can b e relev an t (if their ar e linke d) o r not (if they are not). Nev ertheless , these “maps” of the g r a ph allo ws to understand some imp ort a n t facts a b out the mediev al so ciety . First of all, the “small w orld” structure o f the gra ph is emphasized b y the star shap ed structure of the p erfect communitie s around the 5 This figure, and simila r ones, h av e b een made wit h the help of the free graph dr a wing softw are yED, a v ailable at http://w ww.yworks .com/en/products_yed_about.htm 6 All colored figures are a v aila ble on the pub lisher site. 20 Fig. 4. Graph of the p er f ect comm unities (circles) , the ric h-club (recta ngle) and cen tral vertic es (squares). Other details ab out the fi gure are give n in the text. Fig. 5. Graph of the p erfect comm unities b y geographical locations (ye llo w: Flaugnac, blue: Sain t-Julien, green: Pern, pink: Cornus, red: Ganic and orange: Divilhac). ric h-club: some p ersons seem to b elong to small groups (a p erfect commu nity or link ed p erfect comm unities) whic h are only related to eac h others b y the w a y of the main individ uals (the ric h-club or peasants with a high b etw ee nness measure). Then, family links seem to ha v e a great imp ortance in the mediev a l so ciet y as 21 all individuals in the p erfect comm unities of t en share the same family name (this is the case for 30 p erfect comm unities) but g eographical prox imities are ev en more imp ortant: as shown in Fig ure 5, a ll the p erfect communitie s ha v e homogeneous lo catio ns and v ery o ften, link ed p erfect comm unities also share the same geographical lo cation. Finally , it app ears that p ersons with a high degree of b et w eenness share the same geogra phical lo cation as the p erfect comm unities they are link ed to. Thes e individuals can b e seen as p easan ts making the link betw ee n sev eral villages or betw ee n a village and one o f the cen tral p erson fr o m the rich-club. 5.4 Mapping the me dieval gr ap h with the SOM The so cial netw ork was ana lyzed with the batch ke rnel SOM as fo llows. The parameter β v aried b etw een 0 . 0 1 to 0 . 05. V alues ab o v e 0 . 05 lead to instability in the calculation of the diffusion mat rix in the sense that the obtained k ernel is no more p ositiv e. V alues smaller than 0 . 01 lead t o hard clustering (the diffusion matrix is close to the iden tity matrix) that are not relev a n t (see [52]). F or a fixed k ernel (i.e., a v alue o f β ), all squared ma ps from 5 × 5 to 10 × 1 0 w ere tested as prior structures of the grid. F or eac h prior structure, sev eral random initial configurations, the kerne l PCA based initial configuration and sev eral initial temperatures w ere compared via Kaski and Lagus’ quality measure, leading to the selection of a single final map fo r each size (it should b e not ed that k ernel PCA, asso ciated to an optimal choice of the initial temp erature, leads t o m uc h b etter r esults than random initia lizat io n). In terms of q -mo dularit y , the qualit y of clustering results increases with the v alue of β (f or almost all map sizes). As a consequence, the v alue of β = 0 . 05 w as selected. Among t he 6 maps built with this ke rnel, tho se of size 6 × 6 and 7 × 7 a r e the most in teresting. The first one has the highest q -mo dularit y , whereas the second ha s the smallest v alue of K L criterion together with a high v alue of the q -mo dularity . W e decided to fo cus on the 7 × 7 map as it seems to b e the most in teresting. It con tains 35 non empt y clusters and is given in the left part of Figure 6. In this graphical represen tation, the surface o ccupied b y a square is prop ortional to the size of the corresponding cluster, while the width of the connection betw een t w o squares is prop ortional to the total w eigh t of the edges connecting v ertices of the t w o clusters. The righ t part of Figure 6 is the U-matrix [48] of the map. It visualizes dis- tances b et w een prototypes (in the mapp ed space): dark colors corresp ond to close protot yp es a nd light colors to a large distanc e b et w een the corresp o nding 22 Fig. 6. Final self-organizing map (7 × 7 square grid) protot yp es. The map is divided into three dense subparts: top-left, top- righ t and b ot t o m- righ t. The num ber of edges is small b etw een these three parts and m uc h more dense inside the clusters of the same part, whic h seems to be relev an t. The most dense part of the map is the b o ttom-right one: one of its clusters con tains 255 v ertices, whic h represen ts more than one third of the whole graph. This part is connected to the t w o others whic h are not connected t o each others. As the larg est cluster still seems to b e to o la rge to b e relev an t, anot her batc h k ernel SOM was constructed on the subgraph induced b y the v ertices of this cluster; this metho dology is kno wn as a hier ar chic al fe atur e maps [3 1 ]. As b efore a 7 × 7 map is selected. It is represen ted in Figure 7. This map seems Fig. 7. Self-organizing map of the main cluster 23 to b e w ell connected except 3 little clusters that are not connected t o t he rest of the map. The final map is sparse and well organized. Once again, the main cluster of this map con tains a high num ber of v ertices, 81, whic h represe nts almost one third of the whole subgraph. Suc h a phenomen reflects the cum ulativ e degree distribution described in Sec- tion 5 .2. An analysis of the degree distribution on the map of Figure 6 shows that the 10% of the v ertices ha ving the highest degrees are all clustered in three clusters of the b ottom righ t part of the map (but not in the largest one, GC 7 ). Then, lo o king at the degrees of the subgraph made from the v er- tices in cluster G C, w e see that , once again, their cum ulativ e distribution is a p ow er-law cum ulativ e distribution but with another scale (the densit y of this subgraph is 5 times smaller than the one of the initial graph). The same phenomenon o ccurs in the subgraph GC: the 10% of the v ertices that hav e the highest degrees are all a ssigned to the three mainly connected clusters of Figure 7 and the largest cluster of this subgraph (GC20 6 ) also has a densit y 4 times less t ha n the whole subgraph G C. 5.5 Historic a l pr op erties of the self-or ganizing map The ana lysis mimics what has b een done f or the p erfect comm unities, starting with the distribution of the dates on the map. The mean date for eac h cluster is depicted on Fig ure 8 using a g ra y scale. Eac h cluster has a small standard deviation; clus ters ha ving the highest standard deviations are the most con- nected clusters of the b o ttom righ t part of the map. The three pa rts of the Kohonen map emphasized by the U-matrix hav e homogeneous dates: t o p righ t is the oldest part, b ottom righ t ha v e middle dates and top left, the most rece n t dates. The clusters a re con tin uously connected to eac h others b y the date, in the se nse that connexion clusters hav e intermediate dates. The organization pro vided b y the SOM is therefore relev a n t. But, since the studied perio d is only 100 y ears long, this also seems to sho w that v arious generations (sons, fathers, grand-fathers,. . . ) are not highly mixed; particularly , the earlier part of the map is only connected to the rest b y a v ery few n umber of individuals (1 t o 3 ) . The geographical lo cations of the persons b elonging to t he same cluster are generally homogeneous. More precisely , they are exactly the same for p eas- an ts b elonging to the same little cluster a nd the la rgest clusters o f ten ha v e a dominan t geographical lo cation but also con tain peasants that don’t liv e in this geographical lo cation. The family names are generally not the same for p easan ts in the same cluster, with some exceptions as, fo r example, cluster 10 6 whic h corresp onds to “ Aliquier” family , just as one of its closest cluster, 7 The w a y the clusters are referenced is indicated in Figure 9. 24 Fig. 8. Mean date for eac h cluster f r om blac k, 1260, to white, 1340 11 6 . Th us, as already men tioned in the ana lysis of the p erfect communities , geographical pro ximities seem t o hav e a main role in the p easan t’s relation- ships. 5.6 Comp arison with the work on p erfe c t c ommunities A comparison o f the se lf-o rganizing map with the p erfect comm unit y repre- sen tation (Figure 4) is pro vided by Figure 9: the v ertices that b elong to the same p erfect comm unity are almost a lw a ys in the same cluster of the self- organizing maps (exce pt f or three small p erfect comm unities). T o study the rev erse mapping, an a rbitrary color was a ssigned to eac h cluster that contains at least one p erfect communit y a nd then used to color the same w ay the p er- fect comm unities of Figure 4. The n um b er assigned to each p erfect communit y is the num ber of the cluster in one of the tw o maps (prefixed by “GC” for the clusters of t he la r gest cluster of the initial SOM). Figure 9 emphasize s the great similarit y b etw een the tw o approaches : p er- fect comm unities that share links oft en b elong to the same cluster of the self organizing map. A similar remark can b e made ab out p easan ts with a high b et w eenness measure: they a r e often assigned to the same cluster as the p er- fect comm unity that they link to the rich-club. Moreo v er, p erfect communitie s that share a link o r that a r e link ed to the same p easant with a high b et w een- ness measure but ha v e differen t colors often b elong to nearb y clusters on the 25 Fig. 9. Comp arison of the representa tion of the graph th rough p erfect communities and self-organizing maps (left : of th e whole graph; right : of the largest cluster of the initial SOM. More details ab out this figur e are giv en in the text) SOM: this is the case, fo r example, for clusters 44 and 37, for clusters 0 and 7, for clusters 26, 33 and 34, etc. It is also in teresting to no te that some of the p ersons hav ing a high b et w eenness measure also ha v e an imp ortant p osition on the SOM: f or example, p easan ts 17 and 34 are emphasized b y the fact that they link the b ottom righ t part of the map with the top righ t part and the 26 top left part, respectiv ely . All these similarities a re evidence that there is a strong consensus b et w een b oth appro a c hes and, as a consequence, that they offer a realistic represen tation of the o rganization of the p easan t so ciety in the Middle Ages. Nev ertheless , there are also some in teresting differences b et w een the t w o a p- proac hes. First of all, it is suprising that t he ric h-club is separated in sev eral clusters (37, 38 and 44) in which some p erfect comm unities can also b e found. Arguably , these three clusters are v ery close on the SOM and hav e strong connectivit y (depicted by the tic k lines b etw een them). Moreo v er, the three clusters of the SOM correspo nd to differen t geographical lo catio ns: cluster 37 contains a ma jority of p easan ts living in “Cornus ”, cluster 38 and 44 in “Sain t Julien”. In addition, Clus ters 38 and 44 also con tains peasants that ha v e different family na mes: “Belisie”, “ Bernier”, “Bosseran”, “Cruv elier”, “Laro que”, “Ratier” a nd “Sirv en” are found sev eral t imes in cluste r 38 but none in cluster 44 and “Amilhau”, “Camberan”, “Labarthe”, “Limoges”, “ Ri- v al” a nd “T essendie” are found sev eral times in cluster 44 but none in cluster 38. How ev er, families “Estairac” and “F ague” are w ell represen ted in b oth clusters 38 a nd 4 4 . It is therefore not ve ry clear whether the separation of the ric h-club in to three clusters is relev an t or not . An adv an tage of the ric h-club approac h o v er the SOM based a na lysis is to emphasize the mem b ers of this group who clearly ha v e a sp ecial so cial r ole, while there is nothing v ery sp ecific ab out the corresp onding clusters in t he ma p. It app ears also tha t some perfect communitie s share the same color whereas they don’t seem to b e “close”. Sometimes, this is due to the fact that the p ositions of thes e p erfect comm unities are partially random despite the fact they are link ed to eac h ot hers ( this is the case , for instance, for the pink group of p erfect comm unities 44 at the b ottom of the figure and the p erfect comm unit y of the same color at t he left part of it). Sometimes, this can b e explained b y links that are not represen ted on t he figure: for example, cluster 38 is separated into three groups of p erfect comm unities that a r e not link ed t o eac h other but these groups share some common relatio nships with ve rtices in cluster 38 in the r ich-club. Ho w ev er this argumen t is less con vincing to explain wh y cluster 37 contains tw o groups of p erfect comm unities . Finally , in some cases, there is no simple reason t o explain wh y sev eral p erfect comm unities are group ed in the same cluster: for example, GC20 is still a large cluster that con tains sev eral p erfect comm unities that are not linke d to eac h ot hers on the p erfect comm unities represen tation. 27 5.7 Conclusion The remarks made a b out the similarities and differences b etw een the t w o approac hes sho w that they can bot h pro vide elemen ts to help the historians to understand the organization of the mediev a l society . Mor eov er, they hav e distinct adv an tages a nd w eaknes ses. On the one hand, represe nting the graph through its p erfect communitie s induces the question of the wa y these comm unities ha v e to b e represen ted in a t w o-dimensional space, ev en if the restrictiv e definition c hosen f o r comm unities partly reduces this problem. This question is difficult (a nd related to t he field of graph dra wing) but of a great importa nce to a v oid interpretation bias. F or t his p oin t, the k ernel SOM can app ear as an alternative that prov ides a notion o f proximit y , organization and ev en distance b et w een the comm unities. Moreo v er, k ernel SOM allows to organize a ll the v ertices of the graph and not only the v ertices that b elong to a p erfect comm unit y . On the other hand, the links inside and outside the clusters of the k ernel SOM are not clear: some of the vertice s in a cluster can ha v e no edge in common with the other ve rtices of the cluster (it is the case, e.g., for one of the cluster of the largest cluster as is show n b y Figure 7) and tw o v ertices in the same cluster are not necessarily related to the same v ertices outside the cluster. These tw o facts seem to sho w that k ernel SOM probably prov ides a b etter macroscopic view o f the graph, whereas the p erfect commu nity approac h is more reliable for lo cal interpretations: as the definition of a p erfect communit y is restrictiv e, it emphasizes v ery close so cial g r oups that share the same geographical lo cat io n and also often the same family name. The interpretation of such so cial gro ups is then easier. It should b e noted that in b o th cases, the so cial and historical analysis is only facilitated b y the algorithms rather than someho w b eing automated. In a sense, the problem of understanding the so cial net w ork is simply pushed a little bit further a w a y 8 b y the metho ds, esp ecially in the case of the k ernel SOM. F igures 6 and 7 for instance give broad pictures of the so cial net w ork, but a mor e detailed analysis is needed to extract kno wledge from the netw ork. One of the inte resting asp ect of the com bined metho dology prop osed in the presen t pap er is to help this detailed analysis. T o go further, a n op en question is the wa y the parameters of the ke rnel SOM ha v e to b e c hosen and especially the size of the map, or, in the same spirit, ho w deep a hierarc hical analysis should b e conducted on a larg e cluster. This question is related to finding a relev ant size for eac h comm unit y . The p erfect comm unit y approac h can help driving this w ork b y pro viding an idea of t he 8 The authors are grateful to one reviewe r for p oint ing this out. 28 relev ance o f a give n cluster, a s w e emphasized for cluster GC20. Con v ersely , k ernel SOM could also help to provid e a more realistic represen ta- tion of the p erfect comm unities in creating a drawing alg orithm that can also tak e in to accoun t the distances b et w een clusters in the SOM. This question is curren tly under dev elopmen t. 6 Ac kno wledgmen ts The authors would lik e to thank Florent Hautefeuille, historian (F RAMESP A, Univ ersit ´ e T oulouse Le Mirail, F rance) for giving us the opp ortunity to w ork with this in teresting database and for spending time to explain us its historical con text. W e also w an t to thank F abien Picarougne and Bleuenn Le Goffic (LINA, P olytec h’Nan tes, F rance) fo r manag ing the database registration and P ascale Kun tz f o r her exp ertise in graph vizualisation. W e finally thank the anon ymous review ers for their detailed a nd constructive commen ts that hav e significan tly improv ed this pa p er. References [1] C. Alp ert, A. K ahng, Geo metric embed dings f or faster an d b etter multi-w a y netlist partitioning, in: Pro ceedings of the 30th In ternational Conference on Design Automation (D A C ’93), A CM Press, New Y ork, USA, 1993. [2] C. Ambroise, G. Go v aert, Analyzing dissimilarit y matrices via K ohonen maps, in: Pro ceedings of 5th Conf erence of the Inte rn ational F ederation of Classification So cieties (IFCS 1996), vol. 2, Kob e (Japan), 1996. [3] P . And ras, Kernel-Kohonen net w orks, Inte rn ational Journal of Neural S ystems 12 (2002) 117–1 35. [4] N. Aronsza jn, Theory of repro du cing kernels, T ransactions of the American Mathematica l So ciet y 68 (3) (1950) 337–404 . [5] D. Aub er , T ulip : A h uge graph visualisatio n framew ork, in : P . Mutzel, M. J ¨ unger (eds.), Graph Drawing Softw ares, Ma thematics and Visualizatio n, Springer-V erlag, 2003, pp. 105–126 . [6] A. Berlinet, C. Thomas-Agnan, Repro ducing Kernel Hilb ert Spaces in Probabilit y and Statistics, Kluw er Academic Pu blisher, 2004 . [7] S. Bornholdt, H. Sc huster, Handb o ok of Graphs and Net works - From the Genome to the Inte rnet, Wiley-V CH, Berlin, 2002. 29 [8] F. Chung, Sp ectral Graph Theory , No. 92 in CBMS Regional Conference Series in Mathematics, American Mathematical So ciet y , 1997. [9] A. Clauset, M. E. J. Newman, C. Mo ore, Finding communit y stru cture in v ery large net wo rks, Ph ysical Review, E 70 (2004) 066111. [10] B. Conan-Guez, F. Rossi, A. El Golli , F ast algorithm and imp lemen tation of dissimilarit y self-organizing maps, Neural Net w orks 19 (6-7) (2006) 855–86 3. [11] N. Cristianini, J. Shaw e-T a ylor, J. Kandola, Sp ectral ke rn el metho ds for clustering, in: T. Dietteric h, S. Bec k er, Z. Ghahramani (eds.), Adv ances in Neural Inform ation Pro cessing Systems (NIPS ), v ol. 13, MIT Pr ess, Cam bridge, MA, 2001. [12] G. Di Battista, P . Eades, R. T amassia, I . T ollis, Graph Drawing, Pr en tice Hall, Upp er Saddle Riv er, NJ, USA, 1999. [13] L. Donetti, M. Mu ˜ noz, Detecting net wo rk communities: a new systematic and efficien t algorithm, Journal of Statistical Mec hanics: Theory and Exp erimen t (2004 ) P10012. [14] A. El Golli, F. R ossi, B. Conan-Guez, Y. Lec hev allie r, Une adaptation des ca rtes auto-organisatric es p our d es d onn ´ ees d ´ ecrites par un tableau de dissimilarit ´ es, Revue de Statistique App liqu ´ ee LIV (3) (2006) 33–64. [15] M. F aloutsos, P . F aloutsos, C. F aloutsos, On p o wer-la w relationships of the in ternet top ology , A CM SIGCOMM C omputer Communicatio n R eview 29 (4) (1999 ) 251–262. [16] M. Filipp one, F. Camastra, F. Masulli, S . Ro v etta, A survey of k ernel and sp ectral metho ds for clustering, Patte rn Recognition 41 (2008) 176–190. [17] T. Graep el, M. Burger, K. Ob ermay er, Self-organizing maps: generaliza tions and new optimization tec hniques, Neuro computing 21 (1998) 173–190 . [18] T. Graep el, K. Ob erma y er, A sto c hastic self-organizing map f or pro ximit y data, Neural Computation 11 (1) (1999) 139–155 . [19] B. Hammer, A. Hasenfuss, R elational to p ographic maps, T ec h. Rep. IfI-07-01, Clausthal Univ ersit y of T ec hnology , a v aliable at http://w ww.in.tu- cla usthal.de/fileadmin/homes/techreports/ifi0701hammer.pdf (2007 ). [20] B. Hammer, A. Hasenfu ss, M. Rossi, F. ann d Stric k ert, T op ographic pr o cessing of relational data, in : Pro ceedings of the 6th W orkshop on Self-Or ganizing Maps (WSOM 07), Bielefeld, Germany , 2007, to b e p ublished. [21] B. Hammer, A. Mic heli, M. Stric ke rt, A. Sp erduti, A general framew ork for unsup ervised pro cessing of stru ctured d ata, Neur o computing 57 (2004) 3–35. [22] F. Hautefeuille, Stru ctures d e l’habitat ru ral et te rritoires paroissiaux en bas-Quercy et haut-Toulousain d u VI I ` eme au XIV` eme si ` ecle, Ph .D. thesis, Univ ersit y of T oulouse I I (Le Mirail) (1998). 30 [23] I. Herm an , G. Melan¸ con, M. S cott Marsh all, Graph visualization and na vigat ion in inf ormation visualisation, IEEE T ransactions on Visu alizati on and Comp uter Graphics 6 (1) (2000) 24–43. [24] S. Kaski, K . Lagus, Comparing self-organizing maps, in : C. vo n der Malsburg, W. von Seelen, J . V orbr ¨ ugge n, B. S endhoff (eds.), Pro ceedings of In ternational Conference on Artificial Neural Net w orks (ICANN’96) , v ol. 1112 of Lecture Notes in Computer Science, Sp ringer, Berlin, Germany ,, 1996, p p. 809–81 4. [25] T. K ohohen, P . S omervu o, Self-Organizing maps of sym b ol strings, Neuro computing 21 (1998) 19–30. [26] T. Kohonen, Self-organizing maps of s ym b ol strings, T ec hn ical rep ort a42, Lab oratory of computer and information science, Helsinki Un iv ersit y of tec hnoligy , Finland (1996) . [27] T. K ohonen, Self-Organizing Maps, 3rd Edition, vol. 30, Sp ringer, Berlin, Heidelb erg, New Y ork, 2001. [28] T. K oh on en , P . Somervuo, How to mak e large self-organizing maps f or non ve ctorial data, Neural Net w orks 15 (8) (2002) 945–952 . [29] R. K ondor, J . Laffert y , Diffusion k ernels on graph s and other discrete structures, in: Pro ceedings of the 19 th In ternational Conference on Mac hine Learning, 2002. [30] D. Mac Do nald, C. Fyfe, The k ernel self organising m ap., in: Pro ceedings of 4th In ternational Conf erence on kno wledge-based in telligence engineering systems and applied tec hnologies, 2000. [31] R. Miikkulainen, S cript recognition with hierarc hical feature maps, C onnection Science 2 (1990) 83–101 . [32] B. Mohar, The laplacian sp ectrum of graphs, vol. 2, c hap. Graph Theory , Com binatorics, and Applications, Wiley , 1991, pp. 871–8 98. [33] B. Mohar, S. P oljak, Eigen v alues in combinatoria l optimizatio n, v ol. 50 of IMA V olumes in Mathematics and I ts Applications, c hap. Com binatorial and Grap h - Theoretical Problems in Linear Algebra, Sp ringer-V er lag, 1993, pp. 107–15 1. [34] S. Mossa, M. Barth´ el ´ em y , H. S tanley , L. Nu nes Amaral, T run cation of p ow er la w b ehavi or in “scale-free” net w ork mo d els due to inf orm ation filtering, Physical Review Letters 88 (13) (2002) 138701. [35] J. Nevill e, M. Adler, D. Jensen, Clustering relational data using attribute and link information, in: Pro ceedings of the T ext Mining an d Link Analysis W orksh op, 18th Inte rn ational Joint Conf er en ce on Artificial Intel ligence, 2003. [36] M. Newman, Mixing patterns in net wo rks, Ph ysical Review, E 67 (2003) 02612 6. [37] M. Newman, A. Barab´ asi, D. W atts, Th e Structure and Dynamics of Net w orks, Princeton Unive rsity Press, 2006. [38] M. Newman, M. Girv an, Finding and ev aluating co mmunit y structur e in net w orks, Physic al Review, E 69 (2004) 026113. 31 [39] M. Newman, D. W atts, S. S trogatz, R an d om graph m o dels of so cial net w orks, Pro ceedings of the National Aca demy of S ciences of th e United State s of America 99 (2002) 2566–25 72. [40] G. P alla, I. Derenyi, I. F ark as, T. Vicsek, Unco ve ring th e o v erlapping comm un it y structure of complex n et w orks in n ature and so ciet y , Nature 435 (7043) (2005) 814–8 21. [41] P . Pons, M. Latap y , Computing comm unities in large n et w orks using random w alks, J ournal of Gr ap h Algorithms and Ap plications 10 (2) (2006) 191–21 8. [42] F. Radicc hi, C. Castellano, F. Cecco ni, V. Loreto, D. P arisi, Defin in g and iden tifying communities in net w orks, Pro ceedings of the National Academ y of Sciences of the United States of America 101 (2004) 2658–2663 . [43] S. S c haeffer, Graph clustering, Computer S cience Review 1 (1) (2007) 27–64. [44] B. S c h¨ olk opf, A. Smola, K. M ¨ uller, Nonlinear comp onen t analysis as a k ernel eigen v alue pr oblem, Neur al Comp utation 10 (1998 ) 1299–131 9. [45] B. S c h¨ olk opf, K. Tsuda, J. V ert, Kernel metho d s in computational biology , MIT Press, London, 2004. [46] A. S m ola, R. Kond or, Ker n els and regularization on graphs , in: M. W arm uth, B. Sc h¨ olk opf (eds.), Pro ceedings of the Conference on Learning Theory (COL T) and Kernel Workshop, 2003. [47] S. S trogatz, Exploring complex netw orks, Nature 410 (2001) 268–276. [48] A. Ult sch, H. P . Siemon, Kohonen’s s elf organizing feature m aps for exploratory data analysis, in: Pr o ceedings of International Neur al Net w ork Conference (INNC’90), 1990. [49] J. v an den Heuvel, S. P ejic, Using Laplacian eigen v alues and eigen v ectors in the an alysis of frequency assignment problems, Annals of Op erations Researc h 107 (1-4) (2001) 349–36 8. [50] J. V ert, M. Kanehisa, Extracting activ e path w a ys from gene expression data, Bioinformatics 19 (2003) 238ii–2 44ii. [51] N. Villa, R. Boulet, Clustering a mediev al so cial net w ork b y SOM using a k ernel based distance measur e., in : M. V erleysen (ed.), Pro ceedings of ESANN 2007, Bruges, Belgium, 2007. [52] N. Villa, F. Rossi, A comparison b etw een dissimilarity SOM and k ernel SOM for clustering the v ertices of a graph, in: Pro ceedings of the 6th W orkshop on Self-Organizing Maps (WSOM 07), Bielefield, Germany , 2007, to b e pu blished. [53] U. v on Luxbur g, A tutorial on sp ectral clustering, T ec h. R ep . TR- 149, M ax Planc k Institut f ¨ ur biologisc he K y b ernetik, a v aliable at http://w ww.kyb.mp g.de/pub lications/attachments/luxburg06_TR_v2_4139%5B%1%5D.pdf (2007 ). 32 [54] D. W atts, S mall W orlds - Th e Dynamics of Netw orks b etw een Order and Randomness, Princeton Universit y P ress, Princeton, New Jersey , 1999. [55] D. W atts, S . Strogatz, Collectiv e d ynamics of “small-wo rld” net works, Nature 393 (1998) 440–44 2. [56] S. Zh ou , R. Mondragon, The rich-club phenomenon in the In ternet to p ology , IEEE Comm un ications L etters 8 (3) (2004) 180–1 82. 33
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment