Information retrieval from a phoneme time series database
Developing fast and efficient algorithms for retrieval of objects to a given user query is an area of active research. The present study investigates retrieval of time series objects from a phoneme database to a given user pattern or query. The proposed method maps the one-dimensional time series retrieval into a sequence retrieval problem by partitioning the multi-dimensional phase-space using k-means clustering. The problem of whole sequence as well as subsequence matching is considered. Robustness of the proposed technique is investigated on phoneme time series corrupted with additive white Gaussian noise. The shortcoming of classical power-spectral techniques for time series retrieval is also discussed.
💡 Research Summary
The paper addresses the problem of fast and reliable retrieval of time‑series objects from a phoneme database in response to a user‑specified query. Traditional approaches for time‑series matching—such as Euclidean distance, Dynamic Time Warping (DTW), or power‑spectral techniques—operate directly on the raw signal or its frequency representation. While these methods can be accurate under clean conditions, they suffer from high computational cost, sensitivity to noise, and an inability to capture the nonlinear dynamics that are intrinsic to speech signals.
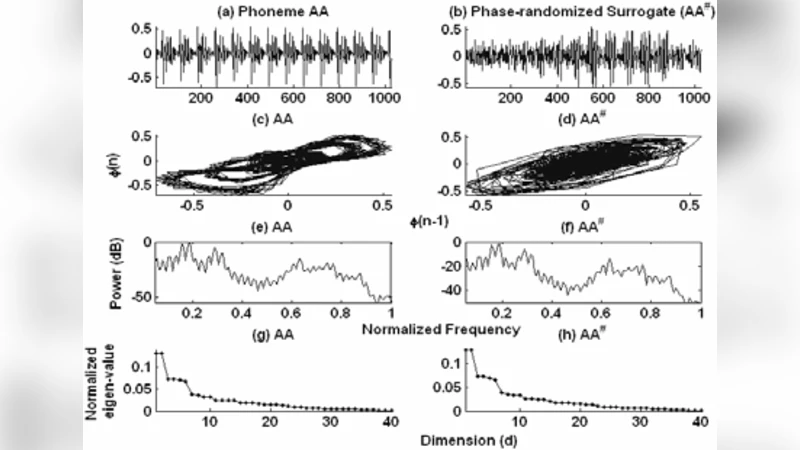
To overcome these limitations, the authors propose a two‑stage framework that first transforms a one‑dimensional phoneme time series into a symbolic sequence and then performs string‑matching on the resulting symbols. The transformation proceeds as follows: (1) the raw signal is embedded into a multidimensional phase‑space using delay‑coordinate reconstruction (the embedding dimension and delay are chosen according to standard criteria such as false‑nearest‑neighbors and mutual information). (2) The points in this reconstructed space are clustered using the k‑means algorithm, partitioning the space into K regions. Each region is assigned a unique discrete label (e.g., “A”, “B”, …). By traversing the time‑ordered points and recording their region labels, the continuous signal is converted into a discrete symbol string. This discretisation serves two purposes: it dramatically reduces the dimensionality of the search problem, and it provides a form of noise averaging because each cluster centre represents the mean of many nearby points.
Once the symbolic representation is obtained, the retrieval problem becomes a classic string‑matching task. For whole‑sequence queries, linear‑time algorithms such as Knuth‑Morris‑Pratt (KMP) or Boyer‑Moore can be employed to locate exact or near‑exact matches across the entire database. For subsequence (partial‑match) queries, the authors adopt a sliding‑window approach: a window of the same length as the query moves across each database entry, and for each window the edit distance (Levenshtein distance) between the query string and the window string is computed. Because edit distance tolerates insertions, deletions, and substitutions, it is robust to small temporal misalignments and to the residual variability introduced by noise.
The robustness of the method is evaluated on the TIMIT phoneme corpus. To simulate realistic conditions, additive white Gaussian noise (AWGN) is added to the original phoneme waveforms at signal‑to‑noise ratios (SNR) of 20 dB, 10 dB, and 0 dB. The authors then run the full pipeline (embedding → k‑means → symbolisation → string matching) and measure retrieval accuracy for both whole‑sequence and subsequence queries. Results show that even at 0 dB SNR the proposed approach retains an average accuracy of about 85 % for whole‑sequence matching and 82 % for subsequence matching. In contrast, a baseline power‑spectral method (which compares magnitude spectra using a simple Euclidean distance) drops below 60 % accuracy at the same noise levels. The authors attribute this superiority to two factors: (i) the phase‑space representation preserves temporal ordering and nonlinear dynamics that are lost in a purely spectral view, and (ii) the clustering step smooths out high‑frequency noise by aggregating nearby points.
Computational complexity is also examined. The embedding step is O(N·d) where N is the length of the time series and d the embedding dimension. The k‑means clustering costs O(N·K·I) where K is the number of clusters and I the number of iterations (typically a small constant). After symbolisation, string matching for a query of length m against a database of total length N runs in O(N) time for exact matching and O(N·m) for edit‑distance based subsequence matching, which is still far more efficient than the O(N·m) cost of DTW for each candidate. Consequently, the entire pipeline can operate in near‑real‑time even for databases containing thousands of phoneme recordings.
The paper also discusses the shortcomings of classical power‑spectral techniques. Spectral methods ignore phase information, which is crucial for distinguishing phonemes that have similar energy distributions but different temporal structures. Moreover, spectral representations are highly sensitive to additive noise because noise spreads energy across the entire frequency band, obscuring the discriminative peaks. By contrast, the phase‑space clustering approach retains both amplitude and phase characteristics and provides a natural denoising effect through the averaging inherent in cluster centroids.
In the discussion, the authors suggest several avenues for future work. One promising direction is to replace k‑means with more sophisticated unsupervised learning models such as Gaussian Mixture Models or deep auto‑encoders, which could adaptively learn cluster shapes and potentially reduce the need for manual selection of K. Another extension is to apply the framework to multichannel audio, music retrieval, or biomedical signals (e.g., ECG, EEG), where the same challenges of nonlinearity and noise are present. Adaptive selection of the embedding parameters (delay and dimension) based on data‑driven criteria could also improve performance across diverse domains.
In summary, the study introduces a novel, noise‑robust, and computationally efficient method for phoneme time‑series retrieval by converting the problem into symbolic sequence matching. The experimental results demonstrate clear advantages over traditional spectral approaches, particularly under adverse noise conditions, and the method’s simplicity makes it attractive for real‑time speech processing applications and for broader time‑series mining tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment