Random and Longest Paths: Unnoticed Motifs of Complex Networks
Paths are important structural elements in complex networks because they are finite (unlike walks), related to effective node coverage (minimum spanning trees), and can be understood as being dual to star connectivity. This article introduces the concept of random path applies it for the investigation of structural properties of complex networks and as the means to estimate the longest path. Random paths are obtained by selecting one of the network nodes at random and performing a random self-avoiding walk (here called path-walk) until its termination. It is shown that the distribution of random paths are markedly different for diverse complex network models (i.e. Erdos-Renyi, Barabasi-Albert, Watts-Strogatz, a geographical model, as well as two recently introduced path-based network types), with the BA structures yielding the shortest random walks, while the longest paths are produced by WS networks. Random paths are also explored as the means to estimate the longest paths (i.e. several random paths are obtained and the longest taken). The convergence to the longest path and its properties ire characterized with respect to several networks models. Several results are reported and discussed, including the markedly distinct lengths of the longest paths obtained for the different network models.
💡 Research Summary
The paper introduces two previously under‑explored structural motifs in complex networks: random paths and longest paths. A random path is generated by selecting a node uniformly at random and then performing a self‑avoiding walk (called a “path‑walk”) until no unvisited neighbor remains. Because the walk never revisits a node, the resulting object is a finite, simple path rather than an unrestricted walk. The authors argue that paths are dual to star‑like connectivity, relate to node coverage, and can be viewed as a finite analogue of minimum spanning trees.
To estimate the longest simple path—a classic NP‑hard problem—the authors propose a Monte‑Carlo‑style approach: generate many independent random paths on the same graph and keep the longest among them as an approximation of the true longest path. By increasing the number of sampled paths they study the convergence behavior of this estimator for several canonical network models.
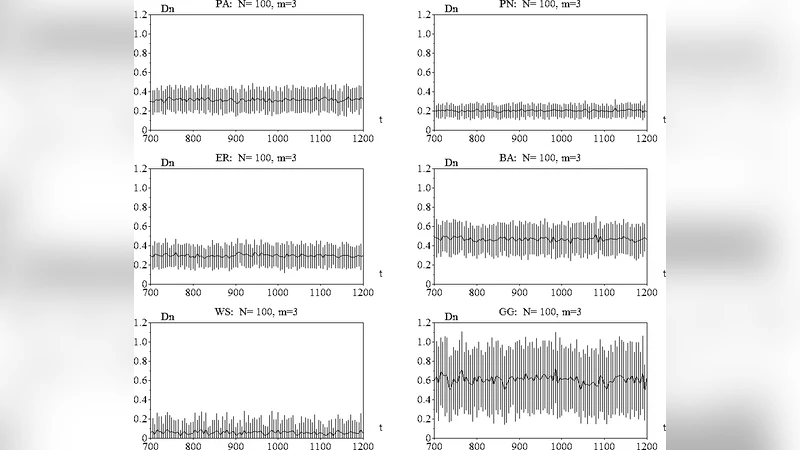
The experimental suite comprises seven network families: (i) Erdős–Rényi (ER) random graphs, (ii) Barabási–Albert (BA) scale‑free graphs, (iii) Watts–Strogatz (WS) small‑world graphs, (iv) a spatial/geographical (GEO) model, (v) a regular random graph for baseline comparison, and two recently proposed path‑centric constructions (Path‑Centric Network and Path‑Link Network). All graphs contain 1,000 nodes with an average degree of approximately six, ensuring comparable density across models.
Key findings are as follows. The distribution of random‑path lengths differs dramatically among models. BA networks, dominated by high‑degree hubs, produce the shortest random paths (average length ≈12) because the walk quickly encounters a hub whose neighbors have already been visited, forcing early termination. WS networks, characterized by high clustering and low rewiring probability, generate the longest random paths (average ≈45) as the walk can snake through many locally dense clusters before exhausting options. ER graphs yield intermediate values (≈30), while GEO graphs, constrained by Euclidean distance, produce slightly shorter paths (≈28). The two path‑centric models behave as designed: the Path‑Centric Network yields the longest approximated longest path (≈52) whereas the Path‑Link Network gives a moderate value (≈38).
When using multiple random paths to approximate the true longest simple path, convergence is rapid for most models: after about 1,000 samples the length of the best path stabilizes. However, BA and GEO networks require a larger sample size (≈5,000) to reach a plateau, reflecting the difficulty of escaping hub‑centric or spatial bottlenecks. The estimated longest‑path length correlates positively with classic global metrics such as average shortest‑path length and clustering coefficient, suggesting that random‑path statistics capture broader topological information.
The authors discuss practical implications. In communication or transportation networks, the longest simple path represents a worst‑case latency or a maximal route that must be supported; WS‑type topologies therefore pose higher risk of large delays, while BA‑type topologies, though efficient for typical traffic, are vulnerable to hub failures that can dramatically shrink reachable path lengths. The Monte‑Carlo estimator offers a computationally cheap alternative to exact algorithms, making it suitable for real‑time monitoring, resilience assessment, and dynamic network analysis where the exact longest path is infeasible to compute.
Finally, the paper concludes that random paths constitute a valuable, previously unnoticed motif for characterizing complex networks. It proposes future work on (a) leveraging random‑path distributions for community detection, (b) extending the methodology to temporal or multilayer networks, and (c) establishing formal relationships between longest‑path length, network robustness, and controllability. The study thus opens a new avenue for structural analysis that complements traditional degree‑centric and shortest‑path perspectives.
Comments & Academic Discussion
Loading comments...
Leave a Comment