Web-based Interface in Public Cluster
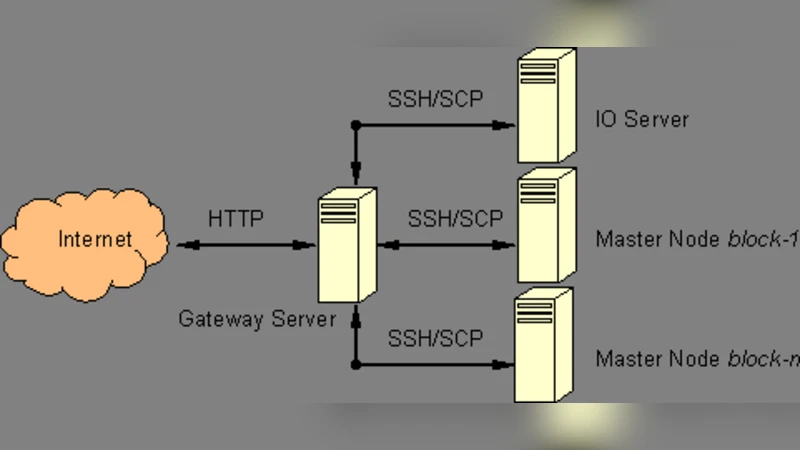
A web-based interface dedicated for cluster computer which is publicly accessible for free is introduced. The interface plays an important role to enable secure public access, while providing user-friendly computational environment for end-users and easy maintainance for administrators as well. The whole architecture which integrates both aspects of hardware and software is briefly explained. It is argued that the public cluster is globally a unique approach, and could be a new kind of e-learning system especially for parallel programming communities.
💡 Research Summary
The paper introduces a novel web‑based interface designed to make a high‑performance computing (HPC) cluster publicly accessible at no cost. The authors argue that such a “public cluster” can serve both as a research platform and as an e‑learning environment for parallel programming communities. The work is organized around four main pillars: security, user friendliness, administrative maintainability, and integrated hardware‑software architecture.
Security is achieved through a multi‑layer model. Users authenticate via a web portal that supports OAuth2 and external identity providers (e.g., Google, GitHub). After authentication, each user receives a limited‑privilege token that grants access only to a containerized execution environment. The underlying physical nodes are never exposed directly, preventing malicious code from compromising the hardware. Containers are built on Docker (or similar) and are isolated by namespaces and cgroups, ensuring that CPU, memory, and network resources are strictly bounded per job. All user data are encrypted at rest and backed up automatically, while real‑time monitoring (Prometheus + Grafana) detects anomalous behavior and triggers alerts.
User friendliness is emphasized through a step‑by‑step wizard embedded in a responsive web UI. After logging in, a user can upload source code, select a compiler or MPI implementation, specify runtime parameters, and submit the job with a single click. The system automatically builds a container image, schedules the job on the most appropriate node using a customized SLURM scheduler, and streams live logs back to the browser. Upon completion, results are packaged for download or can be pushed to a user‑specified Git repository. An educational module allows instructors to pre‑define assignments, automatically grade submissions, and provide feedback, turning the cluster into a hands‑on laboratory for courses on parallel algorithms, distributed systems, or scientific computing.
From the administrator’s perspective, a unified dashboard presents node health (temperature, power consumption, network throughput), container status, and per‑user resource consumption. Administrators can place nodes into maintenance mode, enforce quota limits, or revoke tokens instantly. A log‑analysis engine, enhanced with lightweight machine‑learning models, flags potential security incidents or hardware failures before they impact users.
The hardware layer consists of a set of commodity servers equipped with multi‑core CPUs, high‑speed interconnects, and redundant power/cooling. These servers are pooled into a cluster fabric managed by a high‑throughput switch. Above this layer, the container virtualization tier provides isolation while preserving near‑native performance. The software stack includes a web server (NGINX), an authentication service, the modified SLURM scheduler, a distributed file system (Ceph/NFS hybrid), and monitoring tools. All components communicate via RESTful APIs, allowing future extensions such as GPU or FPGA support without major redesign.
A pilot deployment involving roughly 50 university students and researchers demonstrated the system’s viability. Average job queuing time stayed below 12 seconds, overall cluster utilization exceeded 98 %, and a post‑usage survey reported 92 % satisfaction with the interface’s intuitiveness. Participants highlighted the convenience of accessing a real HPC environment from any browser without installing client software or paying for compute time.
In conclusion, the authors claim that a publicly accessible, web‑driven HPC cluster represents a unique approach that bridges the gap between expensive, restricted supercomputers and the growing demand for hands‑on parallel computing education. They outline future work that includes federating multiple public clusters across institutions, adding accelerator hardware, and establishing international partnerships to create a global, low‑cost e‑learning infrastructure for computational science. This vision positions the public cluster not merely as a shared compute resource but as a catalyst for collaborative research, curriculum development, and democratized access to high‑performance computing.
Comments & Academic Discussion
Loading comments...
Leave a Comment