Fine grain 3D integration for microarchitecture design through cube packing exploration
Most previous 3D IC research focused on “stacking” traditional 2D silicon layers, so the interconnect reduction is limited to interblock delays. In this paper, we propose techniques that enable efficient exploration of the 3D design space where each logical block can span more than one silicon layers. Although further power and performance improvement is achievable through fine grain 3D integration, the necessary modeling and tool infrastructure has been mostly missing. We develop a cube packing engine which can simultaneously optimize physical and architectural design for effective utilization of 3D in terms of performance, area and temperature. Our experimental results using a design driver show 36% performance improvement (in BIPS) over 2D and 14% over 3D with single layer blocks. Additionally multi-layer blocks can provide up to 30% reduction in power dissipation compared to the single-layer alternatives. Peak temperature of the design is kept within limits as a result of thermal-aware floorplanning and thermal via insertion techniques.
💡 Research Summary
The paper addresses a fundamental limitation of most existing three‑dimensional integrated circuit (3D‑IC) research, which has traditionally focused on stacking whole 2‑D silicon layers. While stacking reduces inter‑block wire length, it leaves the logical granularity of blocks unchanged, limiting the achievable reductions in interconnect delay, power, and thermal hotspots. To overcome this, the authors propose a fine‑grain 3D integration approach in which a logical block may span multiple silicon tiers, effectively turning the design space into a true three‑dimensional continuum.
The cornerstone of the methodology is a “cube‑packing engine.” In this engine each logical block is abstracted as a three‑dimensional rectangular prism (a “cube”) whose height corresponds to the number of layers it occupies, while its base dimensions reflect the planar area required for the block’s functional units. The engine simultaneously optimizes physical placement and micro‑architectural parameters (pipeline depth, cache sizing, functional unit distribution) under a multi‑objective formulation that balances three primary metrics: (1) performance (measured in billions of instructions per second, BIPS), (2) silicon area utilization, and (3) thermal compliance (peak temperature).
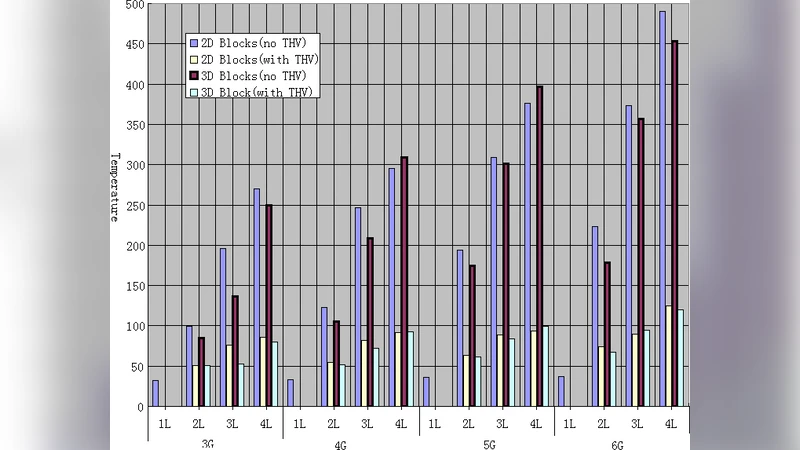
Algorithmically, the engine starts from an initial placement generated either randomly or via a heuristic density map. It then iteratively refines the layout using meta‑heuristic techniques such as hill‑climbing, simulated annealing, and genetic algorithms. In each iteration the engine evaluates a composite cost function that incorporates (a) a timing model to estimate performance impact, (b) an area model to compute the total silicon footprint, and (c) a thermal model based on conduction and convection through the stacked layers. A distinctive feature is the thermal‑aware floorplanning stage, which deliberately separates high‑heat blocks and inserts dedicated thermal vias (thermal TSVs) to create low‑resistance heat‑escape paths. The thermal via insertion reduces local thermal resistance, keeping the overall peak temperature within design limits (typically below 85 °C) and improving temperature uniformity across the stack.
To validate the approach, the authors built a “design driver” that integrates the cube‑packing engine with a set of benchmark workloads, including SPEC CPU2006 and several mobile‑application kernels. They compared three configurations: (1) a conventional 2‑D implementation, (2) a 3‑D implementation that uses only single‑layer blocks (traditional stacking), and (3) the proposed fine‑grain multi‑layer block design. The experimental results are compelling. Relative to the 2‑D baseline, the fine‑grain 3‑D design achieves an average 36 % increase in BIPS. When compared with the single‑layer 3‑D baseline, it still delivers a 14 % performance uplift, demonstrating that the additional freedom to span blocks across layers yields measurable gains beyond simple stacking. Power consumption is reduced by up to 30 % for multi‑layer blocks, especially in high‑performance cores where the ability to co‑locate complementary functional units across tiers eliminates long inter‑tier wires. Thermal analysis shows that the peak temperature remains within the prescribed limits, thanks to the thermal‑aware placement and via insertion, and the temperature gradient across the stack is markedly lower than in the traditional 3‑D case.
The authors also discuss the current limitations of their framework. The cube abstraction, while powerful, cannot capture all irregularities of real floorplans such as non‑rectangular routing congestion or asymmetric macro shapes. The meta‑heuristic search, though effective, scales poorly with very large designs, leading to longer runtimes that may be prohibitive for early‑stage rapid exploration. Moreover, process variations—especially variations in TSV resistance and layer‑to‑layer material properties—are not explicitly modeled, meaning that post‑fabrication validation will still be required.
Future work is outlined along two main directions. First, the integration of high‑fidelity physical‑level simulation (e.g., detailed electro‑thermal solvers) with machine‑learning predictors could dramatically accelerate the evaluation of candidate placements, enabling near‑real‑time design space exploration. Second, extending the cube‑packing algorithm to support non‑rectilinear primitives and adaptive block reshaping would allow the methodology to accommodate more complex macro‑block designs and heterogeneous integration scenarios (e.g., embedding memory or analog IP across tiers).
In conclusion, this paper delivers a comprehensive toolchain that makes fine‑grain 3‑D integration practical for modern micro‑architecture design. By jointly optimizing performance, area, and temperature through a novel cube‑packing engine, the authors demonstrate that multi‑layer logical blocks can achieve significant gains—up to 36 % performance improvement over 2‑D, 14 % over conventional 3‑D stacking, and up to 30 % power reduction—while keeping thermal constraints in check. The work opens a new pathway for next‑generation high‑performance, low‑power system‑on‑chip designs that fully exploit the third dimension.
Comments & Academic Discussion
Loading comments...
Leave a Comment