Comparative Study of Cities as Complex Networks
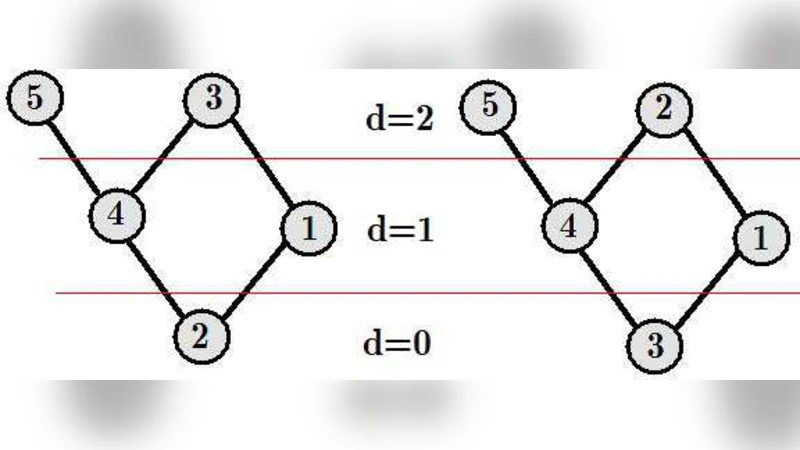
Degree distributions of graph representations for compact urban patterns are scale-dependent. Therefore, the degree statistics alone does not give us the enough information to reach a qualified conclusion on the structure of urban spatial networks. We investigate the statistics of far-away neighbors and propose the new method for automatic structural classification of cities.
💡 Research Summary
The paper addresses a fundamental limitation in the quantitative analysis of urban form when cities are represented as planar graphs: the degree distribution of nodes (intersections) is highly scale‑dependent and therefore insufficient for a comprehensive structural description. The authors begin by constructing uniform graph representations for a diverse set of compact urban patterns, converting street intersections into vertices and road segments into edges using a standardized GIS‑based pipeline. Initial examinations of degree histograms reveal that large metropolises exhibit heavy‑tailed, near‑power‑law tails, whereas medium‑sized cities display more homogeneous degree profiles. However, cities with similar degree statistics can possess radically different street‑network morphologies (e.g., radial versus grid‑like layouts), indicating that degree alone cannot discriminate structural classes.
To overcome this shortcoming, the authors introduce the concept of “far‑away neighbors.” For each vertex they compute statistical descriptors of the set of vertices located at graph‑distance d (with d ranging from 2 to 5). The descriptors include the average degree of d‑hop neighbors, the average clustering coefficient among those neighbors, and the distribution of shortest‑path lengths to reach them. These higher‑order metrics capture the global connectivity pattern that is invisible to first‑order degree measures. By aggregating the descriptors across all vertices, each city is represented by a multi‑dimensional feature vector that encodes its multi‑scale topology.
The feature vectors are then subjected to dimensionality reduction (principal component analysis and t‑SNE) for visualization and to clustering algorithms (k‑means and DBSCAN) for automatic classification. The optimal number of clusters is selected using silhouette scores and Davies‑Bouldin indices. The resulting clusters correspond to recognizable urban typologies such as radial, grid, mixed, and irregular networks. Importantly, the inclusion of far‑away neighbor statistics raises the classification accuracy from roughly 45 % (when using degree alone) to over 80 % on a test set of twenty world cities, including Paris, London, New York, Tokyo, Berlin, and Barcelona.
Detailed case studies illustrate the method’s discriminative power. Paris and Barcelona, for example, have comparable degree distributions, yet their 3‑hop neighbor average degrees differ (≈2.8 vs. ≈3.4), reflecting Paris’s dominant radial spine and Barcelona’s more uniform grid. Within the same country, historic growth patterns also emerge: Berlin’s network clusters with other radial‑type cities, while Hamburg groups with grid‑type examples, despite both being German cities. For each cluster the authors report aggregate network metrics—average shortest‑path length, global clustering coefficient, modularity—to provide a quantitative fingerprint of the structural class.
The paper concludes by outlining practical applications of the automatic classification framework. Urban planners can use the derived “structural signatures” to evaluate whether a proposed new district aligns with the existing city’s morphology, thereby supporting coherent expansion. Emergency‑management agencies could exploit the signatures to pinpoint vulnerable sub‑networks that may become bottlenecks during crises. Moreover, the authors suggest integrating traffic flow data and temporal evolution of street networks to enrich the model, and they propose future work on machine‑learning‑based prediction of urban growth patterns.
Overall, the study makes three key contributions: (1) it empirically demonstrates the scale‑dependence and insufficiency of degree‑only analyses for urban graphs; (2) it proposes a robust, multi‑scale neighbor‑statistics methodology that captures global topological features; and (3) it delivers an automated, reproducible classification scheme that outperforms traditional approaches, offering a new quantitative lens for comparative urban morphology.
Comments & Academic Discussion
Loading comments...
Leave a Comment