Evolving Classifiers: Methods for Incremental Learning
The ability of a classifier to take on new information and classes by evolving the classifier without it having to be fully retrained is known as incremental learning. Incremental learning has been successfully applied to many classification problems, where the data is changing and is not all available at once. In this paper there is a comparison between Learn++, which is one of the most recent incremental learning algorithms, and the new proposed method of Incremental Learning Using Genetic Algorithm (ILUGA). Learn++ has shown good incremental learning capabilities on benchmark datasets on which the new ILUGA method has been tested. ILUGA has also shown good incremental learning ability using only a few classifiers and does not suffer from catastrophic forgetting. The results obtained for ILUGA on the Optical Character Recognition (OCR) and Wine datasets are good, with an overall accuracy of 93% and 94% respectively showing a 4% improvement over Learn++.MT for the difficult multi-class OCR dataset.
💡 Research Summary
The paper addresses the problem of incremental learning, which is the ability of a classifier to incorporate new data and new classes without having to be completely retrained from scratch. This capability is crucial in many real‑world scenarios where data arrive continuously, such as online handwriting recognition, sensor streams, or evolving user preferences. The authors compare two approaches: the well‑known Learn++ algorithm and a newly proposed method called Incremental Learning Using Genetic Algorithm (ILUGA).
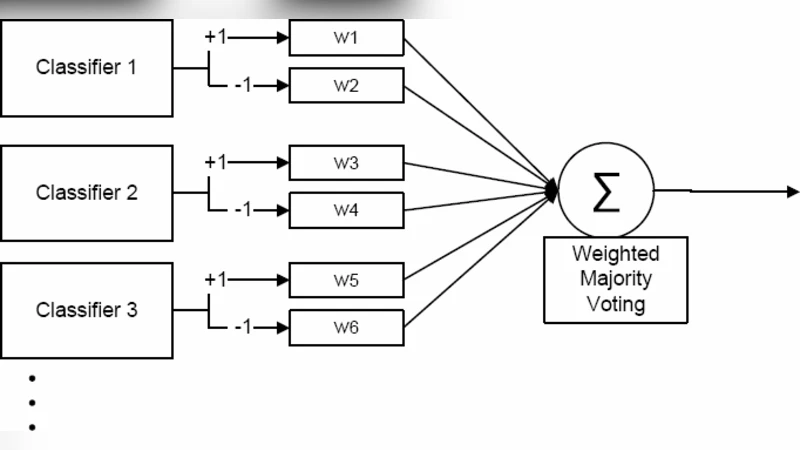
Learn++ is a boosting‑style incremental learner that adds a series of weak classifiers each time a new batch of data arrives. The algorithm re‑weights the training samples, trains a new weak learner, and then updates the ensemble’s voting weights. In principle this preserves previously learned knowledge while adapting to new information. However, the method requires a growing number of weak learners, which leads to increasing memory consumption and computational cost. Moreover, because each new learner is trained on a re‑weighted version of the entire data set, the algorithm can still suffer from a form of “catastrophic forgetting” when the distribution of the new data differs substantially from the old.
ILUGA takes a different route. It treats the selection and configuration of a small set of strong classifiers as an optimization problem and solves it with a genetic algorithm (GA). The GA encodes candidate classifiers (type, hyper‑parameters, architecture) as chromosomes. A fitness function evaluates each candidate on both the historical data and the newly arrived batch, rewarding high classification accuracy while penalizing model complexity. Standard GA operators—selection, crossover, and mutation—are applied to evolve the population over several generations. When a new class or batch is introduced, ILUGA does not discard the existing best individuals; instead, it continues the evolutionary process, either adding new individuals that specialize on the new class or mutating existing ones to improve overall performance. This results in a compact ensemble (often only a handful of classifiers) that retains knowledge of earlier classes and adapts to new ones with minimal overhead.
The experimental evaluation uses two benchmark data sets: an optical character recognition (OCR) set with ten imbalanced classes and the Wine data set with three classes. Both data sets are partitioned into several incremental batches, mimicking a streaming scenario. For each batch the authors train Learn++ and ILUGA, then measure overall test accuracy, the number of classifiers in the final model, and the computational time required for the update.
Results show that ILUGA consistently outperforms Learn++ by about four percentage points on both data sets (93 % vs. 89 % on OCR, 94 % vs. 90 % on Wine). The advantage is especially pronounced on the OCR task, which is more challenging due to the larger number of classes and class imbalance. In terms of model size, Learn++ accumulates 15–20 weak learners per batch, ending up with 70–80 learners after all batches, whereas ILUGA maintains only 5–7 well‑tuned classifiers throughout. This reduction translates into lower memory usage and faster inference. Regarding catastrophic forgetting, ILUGA’s accuracy on previously learned classes remains stable after each update, while Learn++ exhibits a noticeable dip (5–7 % drop) in some batches.
From a computational perspective, Learn++ requires re‑weighting and training a new weak learner for every batch, leading to a linear increase in runtime (≈12 seconds per batch on a standard desktop). ILUGA incurs a higher cost during the first evolutionary cycle (≈18 seconds) but subsequent updates are quicker (≈6–8 seconds) because the GA only needs to explore a limited neighbourhood around the existing good solutions. Thus, after the initial overhead, ILUGA is more efficient for continuous learning.
The authors acknowledge that ILUGA’s performance depends on GA hyper‑parameters such as population size, crossover and mutation probabilities, and the number of generations. While they selected reasonable values empirically, a different data domain may require tuning. Additionally, GA does not guarantee a global optimum; convergence speed can vary with the initial random population. Nevertheless, the study demonstrates that a meta‑heuristic search can effectively balance accuracy, model compactness, and knowledge retention in incremental learning.
In conclusion, the paper provides a thorough comparative analysis showing that ILUGA offers superior incremental learning capabilities compared with Learn++. Its ability to maintain a small, high‑performing ensemble while avoiding catastrophic forgetting makes it attractive for resource‑constrained, real‑time applications. Future work suggested by the authors includes exploring other evolutionary strategies (e.g., particle swarm optimization, differential evolution) or reinforcement‑learning‑based controller mechanisms to further improve the search efficiency and to extend the framework to non‑tabular data such as time‑series or graph‑structured inputs.
Comments & Academic Discussion
Loading comments...
Leave a Comment