Probabilistic projections of HIV prevalence using Bayesian melding
The Joint United Nations Programme on HIV/AIDS (UNAIDS) has developed the Estimation and Projection Package (EPP) for making national estimates and short-term projections of HIV prevalence based on observed prevalence trends at antenatal clinics. Assessing the uncertainty about its estimates and projections is important for informed policy decision making, and we propose the use of Bayesian melding for this purpose. Prevalence data and other information about the EPP model’s input parameters are used to derive a probabilistic HIV prevalence projection, namely a probability distribution over a set of future prevalence trajectories. We relate antenatal clinic prevalence to population prevalence and account for variability between clinics using a random effects model. Predictive intervals for clinic prevalence are derived for checking the model. We discuss predictions given by the EPP model and the results of the Bayesian melding procedure for Uganda, where prevalence peaked at around 28% in 1990; the 95% prediction interval for 2010 ranges from 2% to 7%.
💡 Research Summary
The paper addresses a critical gap in the use of the UNAIDS Estimation and Projection Package (EPP) for national HIV prevalence estimation: the lack of a formal quantification of uncertainty around the model’s point estimates and short‑term forecasts. While EPP fits a deterministic set of epidemiological parameters to observed antenatal clinic (ANC) prevalence data and then projects a single trajectory of population‑level prevalence, policymakers need to know not only the most likely trajectory but also the range of plausible outcomes. To meet this need, the authors propose applying Bayesian melding, a statistical framework that simultaneously incorporates prior information on model inputs and the likelihood of observed outputs, thereby producing a full posterior distribution over both inputs and projected prevalence curves.
Methodological steps
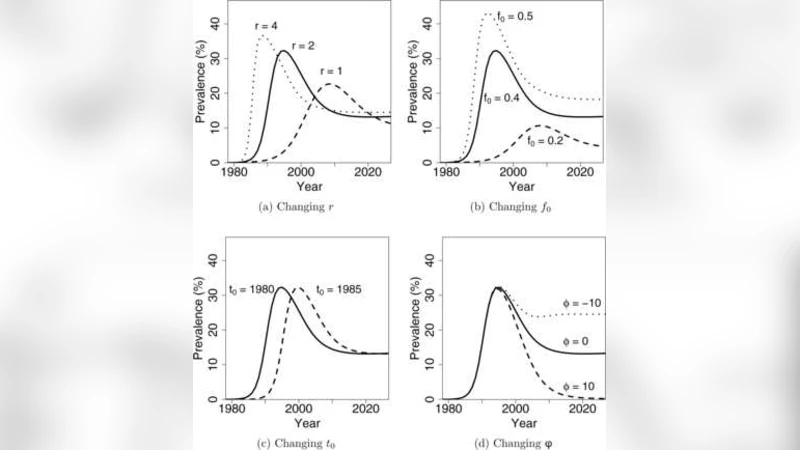
- Prior specification for EPP inputs – The key epidemiological parameters of the EPP model (e.g., transmission rate, duration of infectiousness, initial infected proportion) are assigned probability distributions based on expert elicitation, published literature, and any available country‑specific data. The authors use flexible families such as beta, normal, or uniform distributions to capture plausible ranges while allowing for uncertainty.
- Model simulation – Random draws from the prior are fed into the deterministic EPP simulator, generating a large ensemble of prevalence trajectories for each calendar year. Each draw yields a complete time series of population‑level HIV prevalence.
- Linking ANC data to population prevalence – Because ANC prevalence is not a direct measurement of the national epidemic, the authors construct a hierarchical observation model. After a log‑odds transformation, the observed clinic prevalence is modeled as the sum of the log‑odds of the true population prevalence, a clinic‑specific random effect (capturing systematic differences among clinics), and a residual error term (measurement noise). This random‑effects structure acknowledges heterogeneity across clinics and the fact that ANC data are a convenience sample rather than a random population sample.
- Likelihood evaluation – For each simulated prevalence trajectory, the hierarchical observation model yields a likelihood of the observed ANC data. This likelihood quantifies how well a particular set of input parameters reproduces the real‑world measurements.
- Bayesian melding – The prior on inputs and the likelihood from step 4 are combined using the melding algorithm, which effectively “weights” the input draws by how compatible they are with the data. The result is a posterior distribution over the input parameters and, crucially, over the entire set of future prevalence trajectories. The authors also compute predictive intervals for future ANC prevalence, providing a direct way to assess model fit.
Application to Uganda
The methodology is illustrated with data from Uganda, a country where HIV prevalence peaked at roughly 28 % in 1990 before declining. Using the Bayesian melding approach, the authors obtain a 95 % predictive interval for the national prevalence in 2010 that spans 2 % to 7 %. This interval is substantially wider than the single point estimate that would be reported by the standard EPP output, highlighting the importance of accounting for parameter and observation uncertainty. Moreover, the posterior distributions of the key epidemiological parameters are relatively diffuse, indicating that the available ANC data alone cannot tightly constrain the underlying dynamics.
Model validation
To verify that the posterior predictive distribution is sensible, the authors overlay the 95 % predictive intervals on the observed ANC prevalence series. The majority of clinic observations fall within these intervals, suggesting that the hierarchical observation model and the melding procedure produce realistic uncertainty bounds.
Implications for policy
By delivering a full probability distribution rather than a single forecast, the approach enables decision‑makers to conduct risk‑based planning. For instance, if the upper bound of the 2010 interval (≈ 7 %) were realized, the health system would need to allocate considerably more resources to antiretroviral therapy, prevention of mother‑to‑child transmission, and community outreach than if the prevalence were near the lower bound (≈ 2 %). The predictive intervals also facilitate scenario analysis, allowing stakeholders to evaluate the impact of interventions under both optimistic and pessimistic epidemic trajectories.
Limitations and future work
The authors acknowledge several constraints. First, the prior distributions rely heavily on expert judgment; misspecified priors could bias the posterior. Second, Bayesian melding requires extensive Monte‑Carlo simulation, which can be computationally demanding for large‑scale, multi‑country applications. Future research could explore more efficient sampling techniques (e.g., variational inference, adaptive MCMC) or surrogate modeling to reduce computational load. Third, ANC data are not a perfect proxy for the general population; integrating additional data sources such as population‑based surveys or routine testing data could improve the observation model and reduce uncertainty.
Conclusion
The paper demonstrates that Bayesian melding provides a principled, transparent way to quantify uncertainty in HIV prevalence projections derived from the EPP model. By coupling prior knowledge of epidemiological parameters with a hierarchical model of ANC observations, the method yields posterior predictive intervals that are both statistically coherent and directly interpretable for public‑health planning. The Uganda case study illustrates how the approach can reveal a wide range of plausible future outcomes, thereby informing more robust, evidence‑based policy decisions. The framework is readily extensible to other countries and could become a standard component of UNAIDS’s estimation toolkit, ensuring that future prevalence estimates are accompanied by rigorous measures of uncertainty.
Comments & Academic Discussion
Loading comments...
Leave a Comment