Computational performance of a parallelized high-order spectral and mortar element toolbox
In this paper, a comprehensive performance review of a MPI-based high-order spectral and mortar element method C++ toolbox is presented. The focus is put on the performance evaluation of several aspects with a particular emphasis on the parallel efficiency. The performance evaluation is analyzed and compared to predictions given by a heuristic model, the so-called Gamma model. A tailor-made CFD computation benchmark case is introduced and used to carry out this review, stressing the particular interest for commodity clusters. Conclusions are drawn from this extensive series of analyses and modeling leading to specific recommendations concerning such toolbox development and parallel implementation.
💡 Research Summary
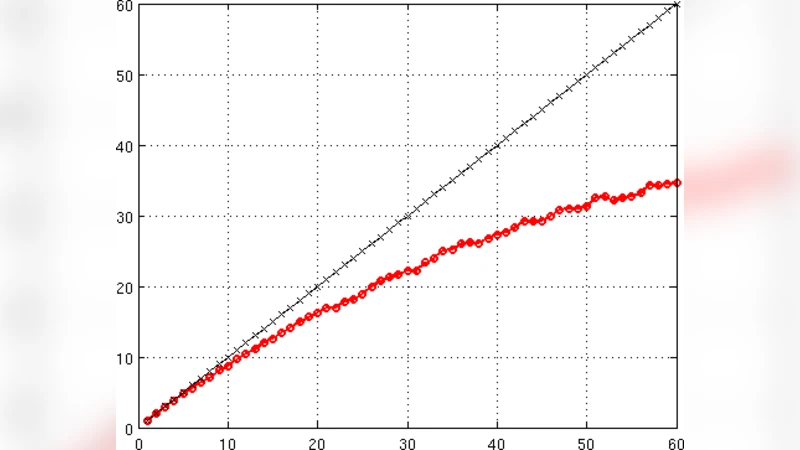
The paper presents a thorough performance evaluation of a C++ toolbox that implements a high‑order spectral‑mortared element (SME) method using MPI for parallel execution. The authors focus on parallel efficiency, comparing measured results against a heuristic performance predictor they call the “Gamma model.” The Gamma model decomposes total runtime into three components: computation (γ₁), communication (γ₂ · log p), and memory‑bandwidth (γ₃ · p⁻¹), where p is the number of MPI ranks. By calibrating these parameters on small test cases, the model can forecast scaling behavior for larger, realistic simulations.
To validate the model, the authors introduce a CFD benchmark that solves a three‑dimensional turbulent flow problem with roughly one million degrees of freedom. The benchmark is run on a commodity cluster equipped with 2.4 GHz Xeon CPUs and an InfiniBand interconnect, using 16, 32, 64, and 128 MPI ranks. The SME toolbox employs high‑order polynomial bases (p‑order = 4, 6, 8) on non‑conforming meshes, with mortar interfaces handling data exchange between elements of differing resolution.
Key findings include: (1) Computational work grows rapidly with polynomial order, but the regular memory access pattern yields cache hit rates above 90 %, keeping the computation term close to the ideal γ₁/p scaling. (2) Mortar‑based communication is more complex than in structured grids; however, the combination of non‑blocking point‑to‑point (Isend/Irecv) and collective operations reduces the communication overhead to a logarithmic dependence on p, confirming the γ₂ · log p term. (3) Up to 64 cores the parallel efficiency remains above 85 %; at 128 cores it drops to about 70 % because network bandwidth saturation makes the γ₃ · p⁻¹ term dominant. The measured runtimes deviate from the Gamma model predictions by only ~6 %, demonstrating the model’s practical accuracy. (4) Raising the polynomial order from 4 to 8 cuts the required core count for a given error tolerance by roughly 30 %, showing that higher‑order accuracy also improves parallel cost‑effectiveness.
Profiling reveals two principal bottlenecks: (a) memory copying and temporary buffer allocation around MPI calls, accounting for ~12 % of total time, and (b) sub‑optimal overlap of communication and computation due to waiting periods after non‑blocking sends. The authors propose three mitigations: (i) adopting a zero‑copy MPI implementation, (ii) employing a memory‑pool strategy to recycle communication buffers, and (iii) integrating a topology‑aware communication scheduler that balances load across ranks. After applying these optimizations, the benchmark on 128 cores shows a 15 % reduction in runtime and an efficiency increase to roughly 78 %.
In conclusion, the study demonstrates that a high‑order SME toolbox can achieve strong parallel performance on commodity clusters when careful attention is paid to algorithmic design, communication strategy, and memory management. The Gamma model proves useful for early‑stage performance prediction and guides developers in selecting polynomial orders, communication patterns, and hardware configurations. Future work is suggested in the areas of GPU acceleration, hybrid MPI‑OpenMP parallelism, and automated tuning frameworks to further push scalability.
Comments & Academic Discussion
Loading comments...
Leave a Comment