Simple Algorithmic Principles of Discovery, Subjective Beauty, Selective Attention, Curiosity & Creativity
I postulate that human or other intelligent agents function or should function as follows. They store all sensory observations as they come - the data is holy. At any time, given some agent's current coding capabilities, part of the data is compressi…
Authors: ** *Jürgen Schmidhuber* (주요 저자) – 논문에 명시된 구체적인 공동 저자는 없으며, 본 논문은 Schmidhuber의 기존 연구와 아이디어를 종합한 형태로 제시됨. **
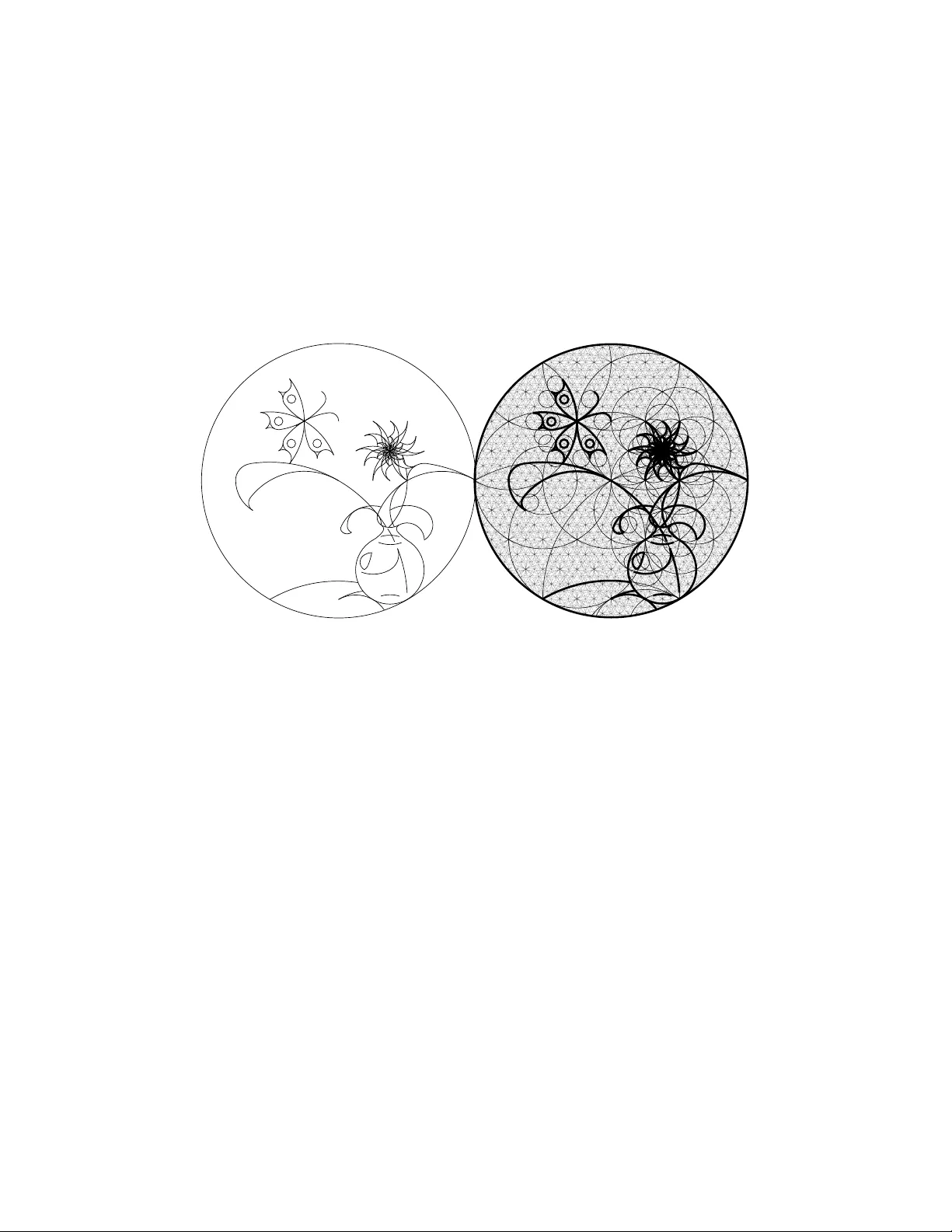
Simple Algorithmic Principles of Discov ery , Subjecti ve Beauty , Selecti ve Attention, Curiosity & Creati vity ∗ J ¨ urgen Schmidhuber TU Munich, Boltzmannstr . 3, 85748 Garching bei M ¨ unchen, Germany & IDSIA, Galleria 2, 6928 Manno (Lugano), Switzerland juergen@id sia.ch - http://w ww.idsia.c h/ ∼ juergen Abstract I po stulate that human o r o ther intelligent agents function or should fu nction as follo ws. They store all sensory observ ations as they come—the data is ‘holy . ’ At any time, gi ven some agent’ s current coding capabilities, part of the data is com- pressible by a short and hop efully fast program / description / explan ation / world model. In the agent’ s subjecti ve e yes, such d ata is more re gular and more beautiful than oth er data. It is well-known that kno wl edge of r egularity and repeatability may i mprov e the agent’ s ability t o plan actions leading to external rew ards. In absence of such rew ards, howe ver , known beauty is boring. Then inter estingness becomes the first derivative of subjectiv e beauty: as the learning agent improv es its compression algorithm, formerly apparently random data parts become sub- jectiv ely more regular and beautiful. Such progress in data compression is mea- sured and maximized by the curiosity dri ve: create action sequences that extend the observ ation history and yield pre viously unkno wn / unpredictable b ut quickly learnable algorithmic regularity . I d iscuss ho w all of the above can be naturally im- plemented o n computers, thro ugh an e xtension o f passi ve u nsupervised learning to the case of acti ve data selection: we reward a general reinforcement learner (with access to the adapti ve compressor) for actions that improve the subjectiv e com- pressibility of the growing data. An unusually large compression breakthrough deserve s the name discovery . The crea tivity of artists, dancers, musicians, pure mathematicians can be vie wed as a by-prod uct of this principle. Se veral qualita- tiv e examples support this hypo thesis. ∗ Joint In vited Lecture for Algorithmic Learning Theory (AL T 2007) and Discove ry Science (DS 2007), Sendai, Japan (preprint ). V ariant to appear in: V . Corruble, M. T akeda , and E. Suzuki (Eds. ): DS 2007, LNAI 4755, pp. 26-38, Springer -V erlag Berlin Heidelber g 2007. Abstract: M. Hutter , R.A. Servedio, and E. T akimoto (Eds.): AL T 2007, LNAI 4754, pp. 24-25, Springer-V erla g Berli n Heidelber g 2007; s ee also http:/ /www . springerli nk.com/content/y8j3453l0757m637/?p=42fb108af50a4cbf8ec06c12309884f6 &pi=2 and http: //www .springer .com/west/home/generic/search/results?SGWID=4-40109-22-173760307-0 1 1 Introd uction A hu man lifetime lasts ab out 3 × 10 9 seconds. The h uman b rain has rou ghly 10 10 neuron s, each with 10 4 synapses on average. Assuming each synapse can sto re no t more than 3 bits, the re is still eno ugh cap acity to store the lifelong sensory input stream with a rate of rou ghly 10 5 bits/s, compa rable to the d emands of a m ovie with reaso nable resolution. The stor age c apacity of a ffordable technical systems will soo n exceed this value. Hence, it is not u nrealistic to consider a mortal age nt that intera cts with an envi- ronmen t and has the means to store the entire h istory of sensory inputs, which partly depend s on its actio ns. This data an chors all it will e ver know about itself and its role in the world. In this sense, the data is ‘holy . ’ What shou ld the ag ent do w ith the data? How shou ld it learn f rom it? Which actions should it execute to influenc e future data? Some of the sen sory inputs reflect external rew ards. At any given time, the agent’ s goal is to maximize the remainin g reward or reinfo rcement to be received b efore it dies. In realistic settings external rewards are rar e thoug h. In a bsence of such r ew ards throug h teacher s etc., what shou ld be the agent’ s motiv ation? Answer: It should spend some time on unsupervised learning , figuring out how the world works, hop ing th is knowledge wil l later be useful to gain external re wards. T radition al u nsuperv ised learning is about finding regularities, by clustering the data, or encod ing it through a factorial code [2, 14] with statistically independ ent co m- ponen ts, or predictin g par ts of it from other parts. All of this may be viewed as special cases o f da ta comp ression. For examp le, wher e ther e are cluster s, a data p oint can be efficiently encod ed b y its cluster center plu s relatively few bits for th e deviation fro m the center . Where ther e is d ata red undancy , a non-r edunda nt factorial co de [1 4] will be mor e compact than the r aw data. Where there is p redictability , compression can b e achieved by a ssigning sh ort codes to ev ents that are predicta ble with high probability [3]. Generally spea king we may say that a major goal of traditiona l unsup ervised learn- ing is to imp rove the co mpression of the o bserved data, by d iscovering a program that computes and thus explain s the h istory (a nd hopefully does so qu ickly) b ut is clearly shorter than the shortest previously known program of this kind. According to o ur co mplexity-based theory of beauty [15, 17, 25], the agen t’ s cur- rently achieved compression performance corresponds to subjectively perceived beauty : among sev eral sub-p atterns classified as ‘com parable’ by a given ob server , the su bjec- ti vely m ost beautiful is th e o ne with th e simp lest (sh ortest) description, giv en the ob - server’ s pa rticular m ethod fo r encoding a nd memorizing it. For example, mathemati- cians find beauty in a simple proof with a s hor t description in the form al langu age they are using . Others like geom etrically simple, aesthetically pleasing, low-complexity drawings of v arious objects [15, 17]. T radition al unsuperv ised learning is not enough thou gh—it just analy zes and en - codes the d ata but d oes not cho ose it. W e have to extend it along the dime nsion of activ e a ction selection, since ou r u nsupervised learn er mu st a lso choo se the action s that influen ce the ob served data, just like a scientist choo ses h is e xperime nts, a baby its toys, an a rtist his colors, a dancer his moves, or a ny attentive system its next sensory input. 2 Which data shou ld the agen t select by executing appro priate ac tions? Which a re the interesting sensory inputs that deserve to be tar gets of its cur iosity? I postu late [25] that in the absence of external re wards o r punishment the answer is: Those th at yield pr ogress in data comp ression. What do es this mea n? New data obser ved by the learn- ing agent may initially look rather rand om and inco mpressible and har d to explain. A good lear ner, howe ver , will impr ove its co mpression algo rithm over tim e, u sing som e application- depend ent learnin g alg orithm, making parts of the d ata history subjectively more com pressible, mor e explaina ble, mor e regular a nd more ‘ beautiful. ’ A beautiful thing is intere sting only as long as it is new , that is , as long as t he algorithmic regularity that makes it simple has not yet been fully assimilated by the adap tiv e observer who is still learn ing to compress the data better . So th e ag ent’ s goal shou ld be: create action sequences that extend the observation history and yield previously unknown / unpre- dictable but q uickly learnable algorithm ic regularity or comp ressibility . T o rephr ase this principle in an informal way: maximize the first derivative of subjecti ve beauty . An unusually large co mpression br eakthrou gh deserves th e name discovery . How can we motiv ate a reinfo rcement learning agent to make discoveries? Clearly , we can- not simply reward it fo r executing a ctions that just yield a c ompressible but bo ring history . For example , a vision-based a gent that always stays in the dark will experi- ence an extremely com pressible and unin teresting h istory of un changin g sensory in- puts. Neither can we reward it for executing actions that y ield hig hly in formative but uncomp ressible data. For example, our agent sitting in fron t of a screen f ull of wh ite noise will experience highly un predictable and fundame ntally uncom pressible and un- interesting data conve ying a lot o f informatio n in the tradition al sense of Boltzmann and Sh annon [32]. I nstead, the agen t sho uld rec eiv e reward for creating / observ ing data that allows for impr ovements of the data’ s subjective comp ressibility . The append ix will describ e form al details of how to implem ent this pr inciple o n computer s. T he next section will provid e examples of subjective beauty tailored to human ob servers, and illustrate the learnin g process leading f rom less to mo re subjec- ti ve beauty . Then I will argu e that the creativity o f artists, dancers, musicians, pure mathematician s as well as unsupervised attention in gene ral is just a by-pro duct of our principle, using qualitative examples to s upp ort this hypothesis. 2 V isual Examples of Subjectiv e Beauty and its ‘Firs t Deriv ative’ Inter es tingness Figure 1 dep icts the drawing o f a female face con sidered ‘ beautiful’ by some hum an observers. I t also sho ws that the essential features of this face follo w a very simple ge- ometrical pattern [17] to be spe cified by very fe w bits of info rmation. That is, the da ta stream gener ated by observ ing the image ( say , thro ugh a sequen ce of eye saccades) is mo re com pressible than it would b e in the ab sence of such regularities. A lthough few peo ple are able to immediately see how the drawing was ma de without studying its gr id-based expla nation (r ight-han d side o f Figu re 1 ), mo st do notice that the facial features somehow fit together and exhibit some sort of r egularity . According to our postulate, the observer’ s reward is generated by the conscious or subconscious discov- 3 ery of this compressibility . The face remain s interesting until its observation does not reveal any additional previously unknown regularities. Then it beco mes boring even in the eyes of those who think it is beautiful—b eauty and interesting ness a re two different things. Figure 1: Left: Drawing of a female face based on a p r eviously p ublished construc- tion plan [17 ] (1998) . Some human observers r eport they feel this face is ‘beautiful. ’ Although the drawing has lots of no isy details (textur e etc) without an obviou s short description, position s and shapes of the ba sic facial features ar e comp actly encoda ble thr ou gh a very simple geometrical scheme. Hence th e image contain s a high ly com- pr essible alg orithmic re gula rity or p attern de scribable by few bits o f informatio n. An observer can per ceive it thr ou gh a sequence of a ttentive eye movemen ts o r saccades, and con sciously or su bconsciou sly d iscover the comp r e ssibility of the incomin g data str ea m. Right: Explanatio n of how the essential facial featur e s wer e constructed [17]. F irst the sides of a square wer e partitioned into 2 4 equal intervals. Certain interval bound aries wer e conn ected to obtain thr ee r otated , superimposed grids based on lines with slop es ± 1 or ± 1 / 2 3 or ± 2 3 / 1 . Higher-r esolu tion details of the grids wer e ob- tained by iteratively selectin g two pre viously generated, neig hbou ring, parallel lines and inserting a n ew one equid istant to bo th. F inally th e grids wer e vertically com- pr essed by a factor of 1 − 2 − 4 . The r esultin g lines and their inter sections define essen- tial bound aries and shap es o f eyebr o ws, eyes, lid s had es, mouth, no se, and facial frame in a simple way that is obv ious fr om the construction plan. Althou gh th is plan is simple in hindsight, it was har d to find : hun dr eds of my pr evious attempts at discovering such pr ecise matches between simple geometries and pretty faces failed. Figure 2 provides ano ther e xamp le: a b utterfly and a vase with a flower . The image to the lef t can be specified by very few bits o f infor mation; it can be constru cted th rough a very simple procedure or algorithm based on fractal circle patterns [15]. People who understan d this algor ithm tend to appreciate the dr awing more than th ose wh o do n ot. They realize how simple it is. Th is is not an imm ediate, all-or-nothing , binar y process 4 though . Since th e typ ical human visual system ha s a lot of experien ce with circles, most people quickly notice th at th e c urves so mehow fit tog ether in a regular way . But few are able to imm ediately state the p recise geom etric principles u nderlyin g the drawing. This pattern, howev er, is learnable from the right-hand side of Figure 2. The conscious or subconscious discovery pro cess leadin g fro m a longer to a shorter description of the data, o r from less to m ore compre ssion, o r from less to more subjectively perceived beauty , yields rew ard depen ding on the first derivati ve of subjecti ve beauty . Figure 2: Left: I mage of a b utterfly and a vase with a flo wer , r eprinted fr om Leon ardo [15, 25]. Right: Explan ation of how the image was constructed thr ough a very simple algorithm e xplo iting fractal cir cles [1 5]. The frame is a circle; its leftmost point is th e center of an other circle o f th e same size. Wher ever two circles of equa l size touch or intersect ar e centers of two mor e circles with equal and h alf size, respectively . Each line of the drawing is a segment o f some cir cle, its e ndpoin ts a r e wher e cir cles touch or intersect. There are few big circles and many sma ll on es. In general, the smaller a cir cle, the more bits are needed to specify it. The drawing to th e left is simple (com- pr essible) as it is based on few , rather lar ge cir cles. Many huma n observers r e port that they derive a certain amoun t of pleasur e fr o m discovering this simplicity . The o b- server’ s learning p r ocess cau ses a reduction of the subjective complexity of the da ta, yielding a temporarily hig h de rivative of subjective beau ty . ( Again I needed a long time to discover a satisfactory way of using fr actal cir cles to create a reasonable dr awing.) 5 3 Compr essibility-Based Rewards of Art and Music The examples above in dicate that work s o f art and music may have importan t pu r- poses beyond their social aspects [ 1] despite of tho se who classify art as superfluo us [10]. Good o bserver-dependent art deepens the ob server’ s insights abou t this world or possible worlds, u n veiling previously unknown re gular ities in com pressible data, co n- necting pr eviously discon nected pattern s in an initially surprising way that makes the combinatio n of these p atterns subjectively more com pressible, and e ventually becomes known and less in teresting. I postulate that the active creation and attentive perception of all kinds o f artwork a re just by-pro ducts of my curiosity principle yielding r ew ard for compressor improvements. Let us elab orate on this idea in m ore detail, f ollowing th e discussion in [25]. Artifi- cial or human observers must percei ve art sequentially , and typically also acti vely , e.g., throug h a sequ ence of atten tion-shifting eye saccades or camer a movements scan ning a sculpture, or intern al shifts of attention that filter and emphasize sounds made by a pianist, while surpressing ba ckgrou nd noise. Undoubtedly many derive pleasure an d rew ards from pe rceiving works of art, such as ce rtain pa intings, or songs. But differ- ent subje cti ve ob servers with different sen sory appar ati and compressor im provement algorithm s will prefer different in put s eque nces. Hence any o bjectiv e theor y of what is good art mu st take the subjecti ve observer as a parameter, to answer qu estions such as: Which ac tion seq uences shou ld he select to max imize h is p leasure? According to ou r principle h e shou ld select one th at max imizes the quickly learnable co mpressibility that is new , relati ve to his curr ent knowledge and his (usually limited) way of incorporating or learning ne w data. For e xample, which song s hou ld some hu man observer select next? Not the one he just heard ten times in a row . It beca me too p redictable in the pro cess. But also not the new weird one with the c ompletely unfamiliar rhy thm and ton ality . It seems too irregular and contain too much arbitrariness and subjective noise. He should try a song that is un familiar enough to contain somewhat unexpected harmonies or m elodies or beats etc., but familiar enou gh to allow for q uickly r ecognizin g the pre sence of a n ew learnable regularity or comp ressibility in the sou nd stream. Sure, th is song will get boring over time, but not yet. The observer depen dence is illustrated by the fact that Sch ¨ onberg’ s twelve ton e music is less popular than certain pop music tunes, presu mably becau se its algorithmic structure is less o bvious to m any huma n observers as it is b ased on more comp licated harmon ies. For example, fr equency r atios of successive no tes in twelve tone music often cannot be expressed as fraction s of very small in tegers. Those with a prior ed- ucation abo ut the basic c oncepts and objectives and constraints of twelve to ne mu sic, howe ver , tend to apprec iate Sch ¨ onberg more than tho se without such an education. All of th is perfectly fits our principle: The current compr essor of a giv en subjective observer tries to comp ress his history of acoustic and other inpu ts wher e possible. The action selector tries to find history -influencin g actio ns that impr ove the compressor ’ s perfor mance on the history so far . The in teresting musical an d other sub sequences are those with previously unk nown yet learn able ty pes of regularities, be cause they lead to compressor improvements. The borin g patter ns are those that s eem arbitra ry or random , or who se structure seems too hard to understand. 6 Similar statements not o nly hold for other dy namic art includ ing film an d dance (taking into acc ount the compressibility of controller actio ns), b u t also for painting and sculpture, wh ich cau se dyn amic pattern seq uences due to attention -shifting actions [31] of the observer . Just as observers get in trinsic r ew ards fro m sequ entially fo cusing attentio n o n ar t- work that exhibits new , pr eviously un known r egularities, th e ‘crea ti ve’ artists g et r e- ward for mak ing it. For example, I fou nd it extremely r ew arding to discover (afte r hundr eds o f frustrating failed attemp ts) the simple ge ometric regularities that per mit- ted the construction of the drawings in Figures 1 and 2. The distinction between artists and observers is not clear thoug h. Artists can be ob servers and vice versa. Both artists and observers execute ac tion seq uences. The in trinsic motiv ations of both are f ully compatible with our simp le principle. Some artists, however , crave external rew ard from o ther ob servers, in fo rm of p raise, mo ney , or both , in ad dition to the intern al re- ward th at comes from cre ating a new work of art. Our principle, howe ver , co nceptually separates these two types of re ward. From our perspective, scientists are very mu ch like artists. Th ey activ ely select experiments in search for simple laws comp ressing the observation history . For exam- ple, d ifferent apples tend to fall off their trees in similar ways. The discovery of a law underly ing the acceleration of all falling apples helps to gr eatly compress the recorded data. The framework in th e app endix is suffi ciently formal to allow for implem entation of our p rinciple on comp uters. The resu lting artificial ob servers will vary in terms of the computation al power of their history com pressors an d learning algorithms. This will influence what is good art / science to them, and what they find interesting. A A ppendix This appendix is a compactified, compressibility-o riented variant of parts of [25]. The world can be explain ed to a d egree b y com pressing it. Th e comp ressed ver - sion of the d ata can be viewed as its explanation . Discoveries correspond to large data compression improvements (f ound by the given, application- depend ent compressor im- provement algorithm). How to build an adaptive agent th at n ot on ly tries to achieve externally g iv en rewards but also to discover, in an unsup ervised and experimen t-based fashion, exp lainable and compressible data? (The explan ations gained thr ough explo- rativ e behavior may e ventu ally help to solve teacher-giv en tasks.) Let us f ormally consider a learn ing ag ent wh ose single life con sists of discrete cycles or time steps t = 1 , 2 , . . . , T . Its complete lifetime T may o r may no t b e known in advance. I n what follows, the v alue of any time-varying v ariable Q at time t ( 1 ≤ t ≤ T ) will be den oted by Q ( t ) , the o rdered seq uence o f values Q (1 ) , . . . , Q ( t ) by Q ( ≤ t ) , and the (p ossibly empty) sequen ce Q (1) , . . . , Q ( t − 1) by Q ( < t ) . At any giv en t the agen t receives a r eal-valued input x ( t ) from the environment and executes a real- valued action y ( t ) which may af fect fu ture inp uts. At times t < T its go al is to 7 maximize future success or utility u ( t ) = E µ " T X τ = t +1 r ( τ ) h ( ≤ t ) # , (1) where r ( t ) is an additio nal real-valued r ew ard input at time t , h ( t ) the ordered triple [ x ( t ) , y ( t ) , r ( t )] (h ence h ( ≤ t ) is the known history up to t ), and E µ ( · | · ) deno tes the conditional expectatio n o perator with respect to some p ossibly u nknown distribu- tion µ from a set M of possible distributions. Here M r eflects whatever is kn own about the possibly pro babilistic reactions of the environmen t. For examp le, M may contain all c omputab le distributions [33, 3 4, 9, 4]. There is ju st one life, no need for predefined repeatable trials, no restriction to Markovian interfaces between sensors and en viron ment, and the utility fu nction imp licitly takes into accoun t the expected remain- ing lifespan E µ ( T | h ( ≤ t )) and thus the possibility to extend it through approp riate actions [23, 26, 24]. Recent work has led to the first learning m achines that ar e universal and optimal in various very gen eral senses [4, 23, 26, 27, 28, 29]. Such machines can in pr inciple find out b y themselves whether cur iosity and world mod el construction are useful or useless in a given environment, and learn to behav e according ly . The present app endix, howe ver , will assum e a priori that compression / explanation of the history is goo d and sh ould be d one; here we shall not worry ab out th e possibility th at ‘cur iosity may kill th e cat. ’ T ow ard s this en d, in the spirit of our previous work [12, 11, 3 5, 16, 18], we split the rew ard signal r ( t ) in to two scalar real-valued comp onents: r ( t ) = g ( r ext ( t ) , r int ( t )) , where g maps pairs of real values to real values, e.g., g ( a, b ) = a + b . Here r ext ( t ) denotes traditional external rew ard provided by the en viron ment, such as n egati ve reward in respon se to bumping against a wall, or positiv e rew ard in response to reach ing some teache r-gi ven go al state. But I am especially interested in r int ( t ) , the interna l or intrinsic or curiosity reward, which is provided whene ver the data co mpressor / intern al world mo del of the agen t impr oves in some sen se. Ou r initial focus will be on the case r ext ( t ) = 0 f or all v alid t . The b asic p rinciple is e ssentially the one we published before in various variants [11, 12, 35, 16, 18, 22, 25]: Principle 1 Generate curiosity re war d fo r the co ntr oller in r espon se to impr ovements of the history compres sor . So we c onceptua lly separ ate the go al (explainin g / com pressing the history) from the means o f achieving the goal. Once the g oal is form ally sp ecified in terms of an algo- rithm for com puting curiosity rewards, let the controller’ s reinforcemen t le arning (RL) mechanism figure ou t how to tra nslate such rewards into action sequen ces th at allow the given com pressor imp rovement algorithm to find and exploit p reviously unkn own types of compre ssibility . A.1 Pr edictors vs Compressors Most of our previous work on artificial curiosity was predic tion-orien ted, e. g., [11, 1 2, 35, 16, 18, 22, 25]. Prediction and compression are closely related though. A pred ictor 8 that correctly predicts many x ( τ ) , giv en history h ( < τ ) , fo r 1 ≤ τ ≤ t , can be used to encode h ( ≤ t ) compactly: Given the predicto r , only th e wrongly predicted x ( τ ) plus informa tion abo ut the corre sponding time steps τ are necessary to reconstru ct history h ( ≤ t ) , e .g., [13]. Similar ly , a p redictor that lear ns a pr obability distribution o f the possible next events, giv en previous ev ents, can be used to efficiently enco de ob ser- vations with high (r espectively lo w) predicted pr obability b y few ( respectively many) bits [3, 30], thu s ac hieving a co mpressed history representation. Generally speaking , we may vie w the predicto r as the essential part o f a program p that re-computes h ( ≤ t ) . If th is pro gram is shor t in com parison to the ra d d ata h ( ≤ t ) , th en h ( ≤ t ) is regular or non-r andom [ 33, 7, 9, 19], presumably reflecting ess ential environmental laws. Then p may also be highly useful for predicting future, yet unseen x ( τ ) fo r τ > t . A.2 Compr essor Perf o rmance Measur es At any time t ( 1 ≤ t < T ), g iv en some co mpressor pr ogram p able to compr ess history h ( ≤ t ) , let C ( p, h ( ≤ t )) denote p ’ s comp ression performa nce on h ( ≤ t ) . An approp riate performance measur e w ould be C l ( p, h ( ≤ t )) = l ( p ) , (2) where l ( p ) de notes the length o f p , measured in number of bits: the shorter p , th e more algorithim ic r egularity and compressibility and predic tability and lawfulness in the observations so far . The ultimate limit for C l ( p, h ( ≤ t )) would be K ∗ ( h ( ≤ t )) , a variant of the Kolmogorov co mplexity of h ( ≤ t ) , namely , the length o f the shortest progr am (for the g iv en h ardware) that co mputes an o utput starting with h ( ≤ t ) [ 33, 7, 9, 19]. C l ( p, h ( ≤ t )) does not take into ac count th e time τ ( p, h ( ≤ t )) spent by p on com- puting h ( ≤ t ) . An alternative perform ance measure insp ired by co ncepts of optimal universal search [8, 21] is C lτ ( p, h ( ≤ t )) = l ( p ) + log τ ( p, h ( ≤ t )) . (3) Here compression by one bit is worth as much as runtime reduction by a factor of 1 2 . A.3 Compr essor Improv ement Measure s The p revious Section A.2 on ly discussed measure s of com pressor per forman ce, but not of perf ormance impr ovemen t, which is the essential issue in our curiosity- oriented context. T o r epeat the po int mad e above: The imp ortant thing a r e th e impr ovements of the comp r e ssor , not its co mpr ession performance per se. Our cur iosity rew ard in response to the comp ressor’ s progress (due to some application-dep endent co mpressor improvement algor ithm) between t imes t and t + 1 should be r int ( t + 1) = f [ C ( p ( t + 1) , h ( ≤ t + 1)) , C ( p ( t ) , h ( ≤ t + 1))] , (4) where f map s pairs of real v alues to real v alues. V a rious alternati ve prog ress measures are possible; most obvious is f ( a, b ) = a − b . Note th at both th e old and the n ew compressor have to be tested on the same d ata, namely , the complete history so far . 9 A.4 Asynchr onous Framework f or Creating Curiosity Reward Let p ( t ) den ote the agent’ s curren t compressor prog ram at time t , s ( t ) its cur rent con- troller, and do: Controller: At any time t ( 1 ≤ t < T ) do: 1. Let s ( t ) use (parts of) histor y h ( ≤ t ) to select and execute y ( t + 1 ) . 2. Observe x ( t + 1) . 3. Check if there is non-zero cur iosity re ward r int ( t + 1) provid ed by the separate, asynchro nously run ning compressor improvemen t algor ithm (see below). If not, set r int ( t + 1) = 0 . 4. Let the contr oller’ s reinfo rcement learn ing (RL) algorith m use h ( ≤ t + 1) in - cluding r int ( t + 1) ( and possibly also the l atest av ailable comp ressed version of the observed d ata—see b elow) to obtain a new con troller s ( t + 1) , in line with objective (1). Compressor: Set p new equal to the initial d ata com pressor . Startin g at time 1, repeat forever until interrupte d by death T : 1. Set p old = p new ; get curr ent time step t and set h old = h ( ≤ t ) . 2. Evaluate p old on h old , to obtain C ( p old , h old ) (Sec tion A.2 ). This m ay take many time steps. 3. Let some (ap plication-d ependen t) comp ressor improvement alg orithm (such as a learning algo rithm fo r an adaptive neural network p redictor) use h old to ob- tain a hop efully better compressor p new (such as a neural net with the same size but impr oved prediction capab ility an d th erefore im proved compression perfo r- mance). Althoug h this may take many time steps, p new may not be optimal, due to limitations of the learning algor ithm, e.g., local maxim a. 4. Evaluate p new on h old , to obtain C ( p new , h old ) . This may take many time steps. 5. Get curren t time step τ and ge nerate curiosity re ward r int ( τ ) = f [ C ( p old , h old ) , C ( p new , h old )] , (5) e.g., f ( a, b ) = a − b ; see Section A.3. Obviously this asynchr onuo us scheme may cause long tempora l delay s be tween co n- troller actions and co rrespon ding curiosity rewards. This may impo se a hea vy burden on the co ntroller’ s RL algorithm whose task is to assign cr edit to past actions (to in- form the co ntroller abou t beginnings of com pressor e valuation processes etc., we may augmen t its input b y unique rep resentations of such events). Nevertheless, th ere are RL algorithms for this purpose which are theoretically optimal in v ar ious senses, to be discussed next. 10 A.5 Optimal Curiosity & Cr eativity & Focus of Attention Our chosen c ompressor class typically will have certain c omputatio nal limitations. In the absence of any external rewards, we may define op timal pur e curiosity b ehavior relativ e to these limitations: At time t this behavior would select the actio n th at maxi- mizes u ( t ) = E µ " T X τ = t +1 r int ( τ ) h ( ≤ t ) # . (6) Since the true, world-governin g probab ility d istribution µ is un known, the resulting task of the con troller’ s RL algorithm may be a f ormidab le one. As the system is revis- iting previously uncompr essible parts of the environment, some o f those will tend to become m ore comp ressible, that is, th e cor respondin g curiosity rewards will d ecrease over time. A go od RL algor ithm must so mehow detect and th en p r edict this decre ase, and a ct acc ording ly . T radition al RL algo rithms [ 6], howe ver , do not provide any th e- oretical guar antee of op timality for such situation s. (This is n ot to say th ough th at sub-optim al RL methods may not lead to success in certain applicatio ns; experimental studies might lead to interesting insights.) Let us first make the na tural a ssumption th at the com pressor is n ot sup er-complex such a s Kolmogorov’ s, that is, its o utput and r int ( t ) are computab le for all t . Is there a best possible RL algo rithm that comes as close as any other to maximizin g objecti ve (6)? Indeed , there is. Its drawback, howe ver , is that it is n ot comp utable in finite time. Nev ertheless, it serves as a reference point for defining what is achie vable at best. A.6 Optimal But Incomputable Action Selector There is an optimal way of selecting action s whic h makes u se o f Solomono ff ’ s theo- retically optimal universal pr edictors and the ir Bayesian learning algorithm s [33, 34, 9, 4, 5]. The latter on ly assume that the r eactions of the environment are sampled from an unkn own p robab ility distribution µ co ntained in a set M of all enu merable distributions—compare text after equation (1). M ore pr ecisely , given an ob servation sequence q ( ≤ t ) , we only assume there exists a c omputer pro gram that can compute the pro bability of the n ext possible q ( t + 1) , given q ( ≤ t ) . In general we do no t know this program, hence we predict using a mixture distribution ξ ( q ( t + 1 ) | q ( ≤ t )) = X i w i µ i ( q ( t + 1) | q ( ≤ t )) , (7) a we ighted sum of all distributions µ i ∈ M , i = 1 , 2 , . . . , where the sum of the con- stant weig hts satisfies P i w i ≤ 1 . This is ind eed the be st on e can p ossibly d o, in a very general sense [3 4, 4]. The drawback of the scheme is its incomputa bility , sin ce M co ntains infin itely many distributions. W e may increa se the theoretical power of the scheme by augm enting M by certain no n-enu merable but limit-comp utable distri- butions [1 9], or restrict it s uch that it becomes co mputab le, e.g. , by assuming the world is comp uted by som e un known b ut determ inistic compu ter program sampled from the Speed Prior [20] which a ssigns low pr obability to e n viron ments that are hard to com- pute by any method. 11 Once we have such an optimal p redictor, we can exten d it by form ally including the effects o f executed action s to define an optim al action selector maximizing futu re expected rew ard. At any time t , Hu tter’ s theor etically optimal (y et un computab le) R L algorithm A I X I [4] u ses an extended version o f Solomon off ’ s p rediction scheme to select those action sequences that promise maxima l futu re reward up to som e ho rizon T , given the current data h ( ≤ t ) . Th at is, in cycle t + 1 , A I X I selects as its next action the first actio n of an action sequence maxim izing ξ -pr edicted rew ard up to the giv en horizon , appropr iately generalizing eq . (7). A I X I uses ob servations optimally [4]: the Bayes-optimal p olicy p ξ based o n th e mixtu re ξ is self-optimizin g in th e sense that its a verage utility value co n verges asymptotica lly fo r all µ ∈ M to the optimal value achieved by the Bayes-op timal policy p µ which knows µ in advance. The n ecessary and sufficient co ndition is tha t M adm its self-optimizing policies. The po licy p ξ is also Pareto-optimal in the sense that ther e is no o ther p olicy yielding hig her or equal value in all environments ν ∈ M and a strictly higher value in at least one [4]. A.7 Computable Selector of Pro vably Optimal Actions, Given C ur - r ent System A I X I above ne eds unlim ited computatio n time. Its computable variant A I X I ( t,l) [4] h as asymptotically op timal runtime but may suffer f rom a huge co nstant slowdown. T o take the consum ed co mputation time into acc ount in a gene ral, optimal way , we may use the recent G ¨ odel machines [23, 26, 24] instead. T hey represent the first class o f mathematically rig orous, fully self-ref erential, self-improving, genera l, optimally effi- cient pro blem solvers. They are also ap plicable to the p roblem embodied b y objective (6). The initial software S of such a G ¨ odel machine contain s an initial pro blem solver , e.g., some typically sub-o ptimal m ethod [6 ]. It also co ntains an asy mptotically optimal initial pro of searc her based on an o nline variant o f Levin’ s Un iversal Sear ch [8], which is used to ru n and test pr o of techniques . Proof techniqu es are p rogram s written in a universal langu age imple mented on the G ¨ odel machine within S . They are in principle able to compute pro ofs conce rning the system’ s own futu re p erform ance, based on a n axiomatic system A encod ed in S . A describes the f ormal utility fun ction, in o ur case eq. (6), the ha rdware prop erties, axiom s of ar ithmetic and p robability theo ry and data manipulatio n etc, and S itself, which is possible without introdu cing circular ity [26]. Inspired by Kurt G ¨ odel’ s c elebrated self-refere ntial formu las (1931) , the G ¨ odel ma- chine rewrites any part of its own cod e (including the proof searcher) through a self- generated executable pro gram as soon as its Univers al Sea r ch variant has found a pro of that th e rewrite is useful acc ording to o bjective (6). Accor ding to the Glob al Optimal- ity Theorem [2 3, 2 6, 2 4], su ch a self- rewrite is globally optimal—no local maxima possible!—since th e self-r eferential code first ha d to p rove that it is n ot usef ul to con- tinue the search for alternative self-rewrites. If there is no provably usefu l o ptimal way of rewriting S at all, then hum ans will not find o ne either . But if there is o ne, then S itself can fin d and explo it it. Un - like the pr evious non -self-refer ential meth ods based on hard wired proof searcher s [4], G ¨ odel machines not only bo ast an optimal or der of comp lexity but can optim ally re- 12 duce (thr ough self-ch anges) any slowdowns hidden by the O () -notation , pr ovided the utility of such speed-up s i s provable. A.8 Consequences of Optimal Action Selecton Now let us apply any optima l RL algorithm to cu riosity r ew ards as defin ed above. The expected consequen ces are: at time t the con troller will do the b est to select an action y ( t ) that s tarts an ac tion sequence e xpected to create observations yield ing m ax- imal expected compre ssion pr ogress up to the expec ted death T , takin g in to accu nt the limitations o f b oth the co mpressor and the co mpressor improvement algorithm. In particular, igno ring issues of c omputatio n time, it will focus in the best possible way on thing s that are c urrently still uncom pressible but will soon bec ome compressible throug h additio nal lear ning. It will g et bored by things th at already are c ompressible. It will also get bor ed by thing s that are cu rrently un compre ssible but will appar ently remain so, given the e xper ience so f ar, or where the costs of making them compr essible exceed those of making other things compressible, etc. Refer ences [1] M. Balter . Seek ing the ke y to music. S cience , 306:11 20–11 22, 20 04. [2] H. B. Barlow , T . P . Kaushal, and G. J. Mitchison . Finding minim um en tropy codes. Neural Computation , 1(3):412–4 23, 19 89. [3] D. A. Huffman. A method for construction of minimum- redund ancy co des. Pr o- ceedings IRE , 40:1098– 1101 , 19 52. [4] M. Hutter . Universal Artificial Intelligence: Seq uential Decisions based on Al- gorithmic Pr obab ility . Springer , Berlin, 2004 . (On J. Sch midhub er’ s SNF g rant 20-61 847). [5] M. Hutter . On universal prediction and Bayesian confirmation. Theor etical Com- puter Science , 2007. [6] L. P . Kaelbling, M. L. Littman, and A. W . Mo ore. Reinfor cement learning : a survey . Journal of AI r esearc h , 4:23 7–28 5, 19 96. [7] A. N. K olmog orov . Three ap proach es to the quan titati ve definition of info rmation. Pr ob lems of Information T ransmission , 1:1–11, 1965. [8] L. A. Levin. Universal seque ntial search pro blems. P r oblems of Informatio n T ransmission , 9(3):265 –266 , 1973. [9] M. Li and P . M. B. V it ´ anyi. An In tr od uction to K olmogor ov Comple xity and its Application s (2nd edition) . Springe r , 1997. [10] S. Pinker . H ow the mind works . 1997. 13 [11] J. Schmid huber . Adaptive cur iosity and adaptive c onfidence. T echnical Re- port FKI-149 -91, Institut f ¨ ur Info rmatik, T echnische Universit ¨ a t M ¨ unchen , April 1991. See also [12]. [12] J. Sch midhub er . Curio us mo del-building control systems. In Pr oceedin gs of the Internation al J oint Conference on Neural Networks, Sin gapore , volume 2, p ages 1458– 1463 . IEEE press, 1991 . [13] J. Schmid huber . Learning com plex, extended sequences using the p rinciple of history compression. Neural Computation , 4(2):234–2 42, 19 92. [14] J. Schmid huber . Learnin g factorial codes by predictability minimization. Neural Computation , 4(6 ):863– 879, 1 992. [15] J. Schm idhub er . Lo w-com plexity art. Leona r do, Journal of the Internation al Society for the Arts, Sciences, and T echno logy , 30(2):97– 103, 19 97. [16] J. Schm idhuber . What’ s interestin g? T echnical Report IDSIA-3 5-97 , ID- SIA, 1997. ftp://ftp.idsia.ch/pu b/juergen/interest.ps.gz; extend ed ab stract in Proc. Snowbird’98, Utah, 1998 ; see also [18]. [17] J. Schm idhube r . Facial b eauty and fractal geo metry . T echn ical Re- port TR IDSIA-28-9 8, IDSIA, 199 8. Published in the Cogpr int Archive: http://cogp rints.soton.ac .uk. [18] J. Schmid huber . Explor ing the predictable . In A. Gh osh and S. Tsuitsui, e ditors, Advance s in Evolu tionary Computing , pages 579–612. Springer, 20 02. [19] J. Schmid huber . Hierarchies of gen eralized K o lmogor ov complexities and nonen umerable un i versal measure s co mputab le in the lim it. Internatio nal J ourn al of F ou ndatio ns of Computer Science , 13(4 ):587– 612, 2 002. [20] J. Sch midhub er . The Speed Prior : a n ew simplicity measure yield ing near-optimal computab le p redictions. In J. Ki vin en and R. H . Slo an, ed itors, Pr o ceedings of the 15th Annu al Confer ence on Comp utationa l Learning Theory (COLT 2002) , Lec- ture Notes in Artificial I ntelligence, pages 21 6–228 . Springer, Sydn ey , Australia, 2002. [21] J. Schmidhu ber . Op timal o rdered pro blem solver . Machine Learning , 54:21 1– 254, 2004. [22] J. S chm idhuber . Overv iew o f artificial curiosity an d activ e exploratio n, with links to publications since 1990, 2004. http ://www .idsia.ch/˜ju ergen/interest.html. [23] J. Schm idhube r . Completely self-ref erential optimal reinfo rcement lear ners. In W . Duch, J. Kacp rzyk, E. Oja, and S. Zadro zny , editors, Artificial Neural Net- works: Bio logical I nspirations - ICANN 2005, LNCS 3697 , pages 223–2 33. Springer-V erlag Berlin Heidelberg, 2005. Plenary talk. 14 [24] J. Schmidhu ber . G ¨ odel machines: T owards a technical justification of conscious- ness. In D. Kudenko, D . Ka zakov , and E. Alonso, editors, Adaptive Agen ts a nd Multi-Agent Systems III (LNCS 3394) , pages 1–23. Springer V erlag, 2005. [25] J. Schmidhu ber . Developmental robotics, o ptimal artificial curiosity , creativity , music, and the fine arts. Conn ection Science , 18(2):1 73–18 7, 200 6. [26] J. Schmid huber . G ¨ odel machines: fully self-r eferential optimal universal problem solvers. In B. Go ertzel and C. Pennachin, editors, Artificial Gen- eral Intelligence , page s 199– 226. Sp ringer V erlag, 2006 . V ar iant av ailable as arXiv:cs.LO/030904 8. [27] J. Schmidhu ber . The ne w AI: General & sound & rele vant f or physics. In B. Go- ertzel an d C. Pennachin, edito rs, Artificial Gen eral Intelligence , p ages 17 5–19 8. Springer, 2006. Also available as TR IDSIA-0 4-03, arXi v:cs.AI/0 30201 2. [28] J. Schmidhu ber . New millennium AI and the con vergence of history . In W . Duch and J. Mandziu k, editors, Challenges to Computation al Intelligence . Springer, in press, 2006. Also available as arXi v :cs.AI/0606 081. [29] J. Schmidh uber . 2006: Celebrating 75 years of AI - history and outlook : th e next 25 years. I n Pr oceedin gs of the “50th Anniversary Su mmit of Artificial In- telligence” at M onte V erita, Ascona, Switzerland . Springer V erlag, 2007. V ariant av a ilable as arXi v:070 8.431 1. [30] J. Sch midhub er and S. Heil. Sequ ential neu ral text compression. IEEE T ransac- tions on Neural Netw orks , 7 (1):142 –146 , 1996. [31] J. Schmidhu ber and R. Huber . Learn ing to generate ar tificial fovea trajectorie s for target detection. In ternational J ourna l of Neural Systems , 2(1 & 2):135 –141 , 1991. [32] C. E. Shanno n. A mathematical theory of com munication (parts I and II). Bell System T echnical J ournal , XXVII:379 –423 , 194 8. [33] R. J. So lomono ff. A formal theor y of inductive inferen ce. Part I. Information and Contr o l , 7:1–22, 1964. [34] R. J. Solom onoff. Comp lexity-based ind uction systems. IEEE T ransaction s on Information Theory , IT -24( 5):422 –432, 19 78. [35] J. Stor ck, S. Hochreiter, and J. Schmidhub er . Reinforcement dr iv en inf ormation acquisition in n on-deter ministic environments. In Pr o ceedings of the Interna - tional Conference on Artificial Neural Networks, P a ris , volume 2 , pag es 159 –164. EC2 & Cie, 1995. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment