Indo-European languages tree by Levenshtein distance
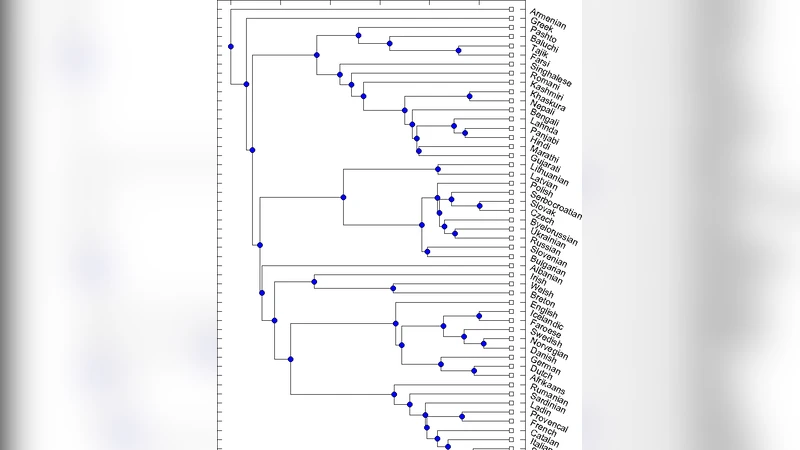
The evolution of languages closely resembles the evolution of haploid organisms. This similarity has been recently exploited \cite{GA,GJ} to construct language trees. The key point is the definition of a distance among all pairs of languages which is the analogous of a genetic distance. Many methods have been proposed to define these distances, one of this, used by glottochronology, compute distance from the percentage of shared ``cognates’’. Cognates are words inferred to have a common historical origin, and subjective judgment plays a relevant role in the identification process. Here we push closer the analogy with evolutionary biology and we introduce a genetic distance among language pairs by considering a renormalized Levenshtein distance among words with same meaning and averaging on all the words contained in a Swadesh list \cite{Sw}. The subjectivity of process is consistently reduced and the reproducibility is highly facilitated. We test our method against the Indo-European group considering fifty different languages and the two hundred words of the Swadesh list for any of them. We find out a tree which closely resembles the one published in \cite{GA} with some significant differences.
💡 Research Summary
The paper proposes a novel, fully quantitative method for measuring linguistic distances that draws a direct analogy to genetic distances used in evolutionary biology. Instead of relying on the traditionally subjective identification of cognates, the authors compute a normalized Levenshtein distance for each pair of words that share the same meaning across languages. The Levenshtein distance, which counts the minimum number of insertions, deletions, and substitutions required to transform one string into another, is divided by the length of the longer word, yielding a value between 0 and 1 that is independent of word length. By averaging these normalized distances over the entire 200‑item Swadesh list for each language pair, the authors obtain a single, reproducible distance metric that reflects overall lexical similarity while minimizing the influence of any single word.
The dataset consists of 50 Indo‑European languages, each represented by the same 200 Swadesh items. For every pair of languages the authors calculate 200 normalized Levenshtein distances and then compute their arithmetic mean, producing a 50 × 50 distance matrix. This matrix is fed into the UPGMA (Unweighted Pair Group Method with Arithmetic Mean) hierarchical clustering algorithm to reconstruct a language phylogeny. The resulting tree reproduces the major branches identified in earlier glottochronological studies (e.g., the division into Germanic, Slavic, Romance, Indo‑Iranian, etc.) and confirms the overall topology reported by Gray and Atkinson (2003). However, several finer‑scale relationships differ: Albanian, for example, occupies a more intermediate position relative to Latin than previously suggested, and some Indo‑Iranian languages show unexpected proximities. These discrepancies illustrate how a purely orthographic distance can reveal alternative hypotheses about historical contact, borrowing, or parallel phonological change that are not captured by cognate‑based methods.
A key contribution of the work is the dramatic reduction of subjectivity. Traditional cognate identification requires expert judgment about historical derivation, which can vary between scholars and is difficult to automate. By contrast, the Levenshtein‑based approach is algorithmic, fully reproducible, and scalable to large language families. The normalization step also corrects for bias introduced by short words, which would otherwise dominate raw edit‑distance calculations. Consequently, the method is well suited for high‑throughput comparative linguistics, where thousands of language pairs can be processed without manual annotation.
Nevertheless, the authors acknowledge important limitations. Levenshtein distance captures only surface‑level orthographic similarity and ignores semantic shift, borrowing, and phonological processes that may leave the spelling unchanged. Moreover, the Swadesh list, while widely used, represents a limited lexical core and may not reflect deeper structural changes in a language. Future extensions could incorporate meaning‑based similarity measures (e.g., semantic vectors or weighted edit distances) or combine orthographic distances with phonological and morphological features. Integrating larger, more diverse lexical databases would also improve the resolution of the resulting phylogenies.
In summary, the study demonstrates that a normalized Levenshtein distance applied to a standardized Swadesh list provides a robust, objective metric for linguistic comparison. The resulting Indo‑European language tree aligns closely with established phylogenies while offering new insights into specific sub‑group relationships. This approach paves the way for automated, reproducible language‑family analyses and invites further methodological refinements that blend orthographic, phonological, and semantic information for a more comprehensive view of language evolution.
Comments & Academic Discussion
Loading comments...
Leave a Comment