A Practical Ontology for the Large-Scale Modeling of Scholarly Artifacts and their Usage
The large-scale analysis of scholarly artifact usage is constrained primarily by current practices in usage data archiving, privacy issues concerned with the dissemination of usage data, and the lack of a practical ontology for modeling the usage dom…
Authors: ** 제공된 텍스트에는 저자 정보가 명시되어 있지 않음. (원문 PDF 혹은 학술 데이터베이스에서 확인 필요) **
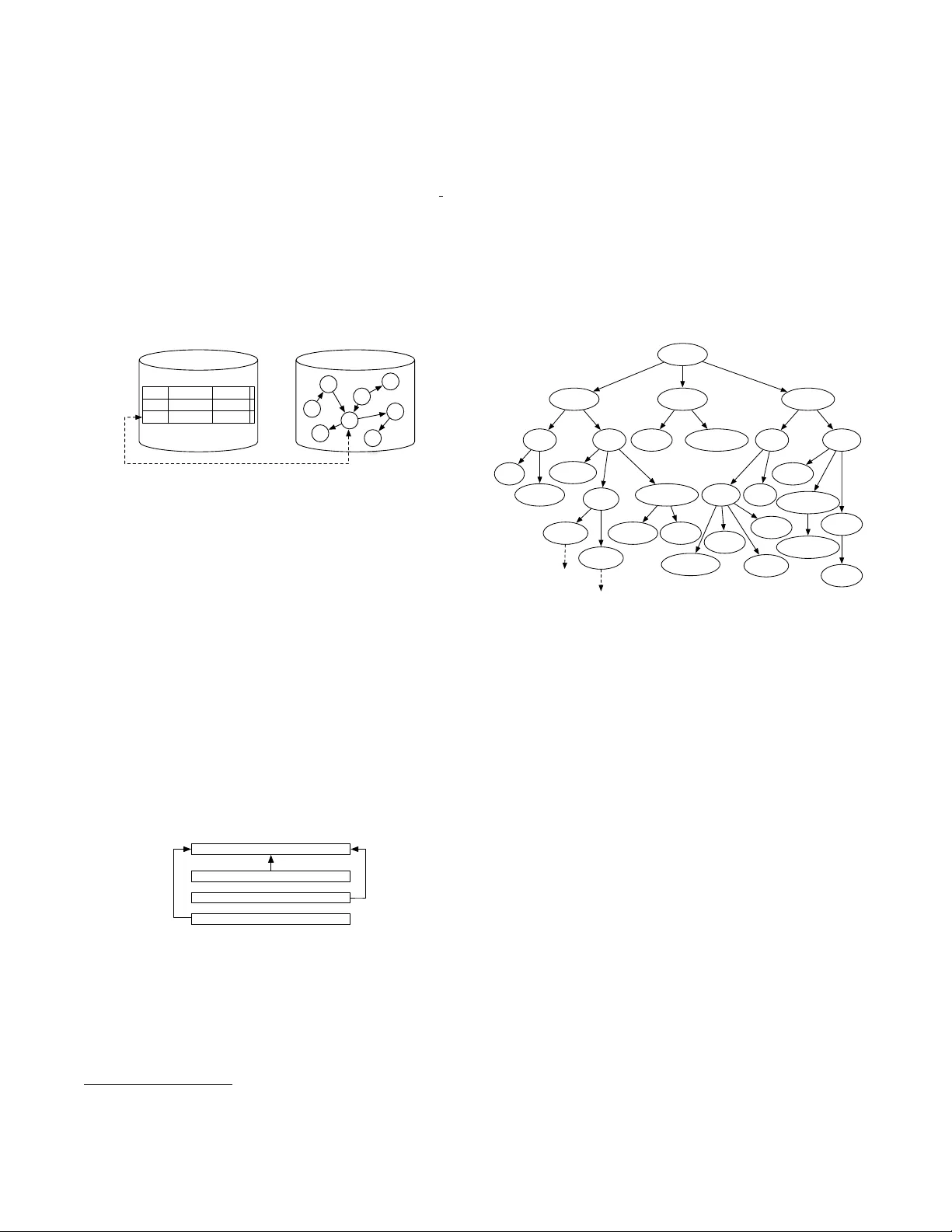
A Practical Ontology f or the Lar g e-Scale Modeling of Scholarl y Ar tifacts and their Usage Marko A. Rodriguez Digital Library Research & Prototyping T eam Los Alamos National Laboratory Los Alamos, NM 87545 marko@lanl.gov Johan Bollen Digital Library Research & Prototyping T eam Los Alamos National Laboratory Los Alamos, NM 87545 jbollen@lanl.gov Herber t V an de Sompel Digital Library Research & Prototyping T eam Los Alamos National Laboratory Los Alamos, NM 87545 herber tv@lanl.gov ABSTRA CT The large-scale analysis of sc holarly artifact usage is con- strained primarily b y curren t practices in usage data arc hiv- ing, priv acy issues concerned with the dissemination of usage data, and the lack of a practical ontology for mo deling the usage domain. As a remedy to the third constrain t, this article presen ts a scholarly ontology that was engineered to represen t those classes for which large-scale bibliographic and usage data exists, supp orts usage research, and whose instan tiation is scalable to the order of 50 million articles along with their asso ciated artifacts (e.g. authors and jour- nals) and an accompan ying 1 billion usage even ts. The real w orld instan tiation of the presen ted abstract ontology is a seman tic net work model of the scholarly communit y which lends the sc holarly pro cess to statistical analysis and com- putational supp ort. W e present the ontology , discuss its instan tiation, and pro vide some example inference rules for calculating v arious sc holarly artifact metrics. Categories and Subject Descriptors I.2.4 [ Knowledge Representation F ormalisms and Meth- o ds ]: Semantic Net w orks; H.3.7 [ Digital Libraries ]: Stan- dards— ontolo gies General T erms On tologies, Sc holarly Comm unication K eywords Resource Description F ramework and Schema, W eb On tol- ogy Language, Semantic Netw orks 1. INTR ODUCTION New publications are added to the scholarly record at an accelerating pace. This p oint is realized by observing the This paper is authored by an employee(s) of the United States Government and is in the public domain. JCDL ’07, June 17–22, 2007, V ancouver , British Columbia, Canada. A CM 978-1-59593-644-8/07/0006. ev olution of the amount of publications indexed in Thom- son Scien tific’s citation database o v er the last fifteen years: 875,310 in 1990; 1,067,292 in 1995; 1,164,015 in 2000, and 1,511,067 in 2005. Ho wev er, the exten t of the scholarly record reaches far b eyond what is indexed b y Thompson Scien tific. While Thompson Scientific fo cuses primarily on qualit y-driven journals (roughly 8,700 in 2005), they do not index more no vel sc holarly artifacts such as preprints de- p osited in institutional or discipline-orien ted rep ositories, datasets, softw are, and simulations that are increasingly b e- ing considered scholarly communication units in their own righ t. While the size (and growth) of the sc holarly record is impressiv e, the extent of its use is even more staggering. F or instance, in Nov em b er 2006, Elsevier’s Science Direct, whic h pro vides access to articles from approximately 2,000 journals, celebrated its 1 billionth full-text download since coun ting started in April of 1999 1 . And, again, the extent of sc holarly usage clearly reaches far b eyond Elsevier’s rep os- itory . F urthermore, usage ev ents include not only full-text do wnloads, but also ev en ts suc h as requesting services from linking servers, downloading bibliographic citations, email- ing abstracts, etc. T o a large exten t, the effect of usage b eha vior on the schol- arly pro cess is a horizon that is only b eginning to b e under- sto od and, if prop erly studied, will offer clues to the ev o- lutionary trends of science [1, 2, 3], quantitativ e mo dels of the v alue of scholarly artifacts [4, 5], and services to sup- p ort sc holars [6]. The Andrew W. Mellon funded MESUR 2 pro ject at the Research Library of the Los Alamos National Lab oratory aims at developing metrics for assessing schol- arly comm unication artifacts (e.g. articles, journals, confer- ence pro ceedings, etc.) and agen ts (e.g. authors, institu- tions, publishers, rep ositories, etc.) on the basis of scholarly usage. In order to do this, the MESUR pro ject mak es use of a representativ e collection of bibliographic, citation and usage data. This data is collected from a wide v ariet y of sources including academic publishers, secondary publish- ers, institutional linking servers, etc. Exp ectations are that the collected data will even tually encompass tens of millions of bibliographic records, hundreds of millions of citations, 1 Elsevier’s 1 billion do wnloads article a v ailable at: h ttp://www.info.sciencedirect.com/news/archiv e/2006/ news billionth.asp 2 MEtrics from Scholarly Usage of Resources av ailable at: h ttp://www.mesur.org/ and billions of usage even ts. Mining such a v ast data set in an efficient, p erforming, and flexible manner presents sig- nifican t challenges regarding data representation and data access. This article presents, the OWL ontology [7] used b y MESUR to represen t bibliographic, citation and usage data in an integrated manner. The prop osed MESUR on- tology is practical, as opposed to all encompassing, in that it represents those artifacts and prop erties that, as previ- ously shown in [6], are realistically av ailable from mo dern sc holarly information systems. This includes bibliographic data such as author, title, identifier, publication date and us- age data suc h as the IP address of the accessing agent, the date and time of access, type of usage, etc. Finally , another no vel contribution of this work is the hybrid storage and access architecture in which relational database and triple store technology are com bined. This is achiev ed by storing core data and relationships in the triple store and auxiliary data in a relational database. This design choice is driven b y the need to keep the size of the triple store to a lev el that can realistically b e handled by current technologies. The com bination of the data architecture and scholarly ontology presen ted in this article provide the foundation for the large- scale mo deling and analysis of scholarly artifacts and their usage. 2. SEMANTIC NETWORK ONT OLOGIES A semantic netw ork (sometimes called a multi-relational net work or m ulti-graph) is comp osed of a set of nodes (repre- sen ting heterogeneous artifacts) connected to one another by a set of qualified, or labeled, edges [8]. In a graph theoretic sense, a semantic net work is a directed lab eled graph. Be- cause an edge is lab eled, tw o no des can b e connected to one another by an infinite num ber of edges. How ev er, in most cases, the p ossible interconnections b etw een node types is constrained to a predetermined set. This predetermined set is made explicit in the semantic netw ork’s asso ciated on tol- ogy . An ontology is generally defined as a set of abstract classes, their relationship to one another, and a collection of inference rules for deriving implicit relationships [9]. An on- tology makes no explicit reference to the actual instances of the defined abstract classes; this is the role of the semantic net work. An ontology is related to the dev eloper’s API in ob ject ori- en ted programming languages suc h as C++ and Jav a (min us the explicit represen tation of class metho ds/functions). F or example, the set of relationships of an ontological class are kno wn as the class’ prop erties and, in the ob ject oriented lexicon, can b e understo o d as class fields. Also, a taxon- om y is usually expressed in a seman tic netw ork ontology . A taxonom y of sub- and sup er-classes support the inheritance of class prop erties. F or instance, if all mammals are warm blo oded, then all h umans are warm blo o ded because all h u- mans are mammals. In an inheritance hierarc hy , the warm blo oded prop erty of mammals is inherited by all sub-classes of mammal (e.g. h uman). Figure 1 diagrams the relationship b etw een an ontology and its semantic netw ork instantiation. The circles repre- sen ts ob jects that are instances of the dash-dot p ointed to abstract classes (the squares). The three low er squares are sub classes of a more general top-level class (denoted b y the dashed edges). The horizon tal edges in the on tology denote p ermissible prop erty types in the instantiation and thus, corresp onding horizon tal lab eled edges in the semantic net- w ork ma y exist. Figure 1 do es not exp ose the range of con- ceptual n uances that can b e expressed by mo dern ontology languages and thus, only pro vides a rudimen tary representa- tion of the relationship b etw een an ontology and its semantic net work instantiation. ontology network a a b b b Figure 1: The relationship b etw een an ontology and its seman tic netw ork instantiation 2.1 Semantic Network T echnology The most p opular seman tic netw ork representational frame- w ork is the Resource Description F ramew ork and Schema, or RDF(S) [10]. RDF(S) represents all no des and edges b y Universal Resource Identifiers (URI) [11]. The URI ap- proac h supp orts the use of namespacing such that the URI http://www.science.org#Article has a differen t mean- ing, or connotation, than what may b e understo od by the URI http://www.newspaper.net#Article . The W eb Ontology Language (OWL) is an extension of RDF(S) that supp orts a richer vocabulary (e.g. promotes man y set theoretical concepts) [7]. Prot´ eg ´ e 3 is p erhaps the most popular application for designing OWL on tologies [12]. While OWL is primarily a machine readable language, an O WL ontology can b e diagrammed using the Unified Mo d- eling Language’s (UML) class diagrams (i.e. en tit y relation- ship diagrams). Mo dern semantic net w ork data stores represent the rela- tionship b etw een tw o no des by a triple . F or instance, the triple h URI a , http://xmlns.com/foaf/0.1/#knows , URI b i states that the resource identified by URI a kno ws the re- http://xmlns.com/foaf/0.1/#knows URI a URI b Figure 2: A diagrammed triple source iden tified b y URI b , where URI a and URI b are nodes and http://xmlns.com/foaf/0.1/#knows is a directed lab eled edge (see Figure 2). The meaning of knows is fully defined by the URI http://xmlns.com/foaf/0.1/ . The union of instan tiated FO AF triples is a F OAF seman tic net- w ork. Current platforms for storing and querying suc h se- man tic netw orks are called triple stor es . Many op en source and proprietary triple stores currently exist. V arious query- ing languages exist as well [13]. The role of the query lan- guage is to provide the interface to access the data con tained in the triple store. This is analogous to the relationships 3 Prot ´ eg´ e a v ailable at: http://protege.stanford.edu/ b et ween SQL and relational databases. P erhaps the most p opular triple store query language is SP ARQL [14]. An example SP ARQL query is SELECT ?x WHERE ( ?x foaf:knows vub:cgershen ). In the ab o ve query , the ?x v ariable is b ound to any no de that is the domain of a triple with an associated predicate of http://xmlns.com/foaf/0.1/#knows and a range of http://homepages.vub.ac.be/#cgershen . Thus, the ab o ve query returns all p eople who know vub:cgershen (i.e. Carlos Gershenson). The ontology plays a significant role in many asp ects of a semantic netw ork. Figure 3 demonstrates the role of the on tology in determining whic h real w orld data is harvested, ho w that data is represented inside of the triple store (se- man tic netw ork), and finally , what queries and inferences are possible to execute. Triple Store Ontology Query constrains constrains Real World Data insert retrieve constrains Figure 3: The many roles of an ontology 3. SCHOLARL Y ONT OLOGIES In general, an ontology’s classes, their relationships, and inferences are determined according to what is b eing mod- eled, for what problems that model is trying to solve, and ho w that mo del’s classes can b e instantiated according to real world data. Thus, there were three primary require- men ts to the developmen t of the MESUR ontology: 1. realistically a v ailable real w orld data 2. ability to study usage b ehavior 3. scalability of the triple store instan tiation. Without real-world data, an ontology serves only as a con- ceptual to ol for understanding a particular domain and, in suc h cases, ontologies of this nature may b e v ery detailed in what they represent. Ho w ever, for on tologies that are designed to b e instantiated b y real world data, the ontol- ogy is ultimately constrained by data av ailability . Thus, the MESUR on tology is constrained to bibliographic and usage data since these are the primary sources of scholarly data. In the scholarly communit y , while articles, journals, confer- ence pro ceedings, and the like are we ll do cumented and rep- resen ted in formats that lend themselves to analysis, other information, suc h as usage data, tends to be less explicit due to the inheren t priv acy issues surrounding individual usage b eha vior. Therefore, a primary ob jectiv e of the MESUR pro ject is the acquisition of large-scale usage data sets from pro viders w orld-wide. The purp ose of the MESUR pro ject is to study usage b e- ha vior in the sc holarly pro cess and therefore, usage modeling is a necessary comp onent of the MESUR ontology . Given b oth usage and bibliographic data, it will be p ossible to gen- erate and v alidate metrics for understanding the ‘v alue’ of all t yp es of sc holarly artifacts. Currently , the sc holarly com- m unity has one primary means of understanding the v alue of a journal and thus its authors: the ISI Impact F actor [15]. With a seman tic net w ork data structure that includes not only article (and thus, journal) citation, but also au- thorship, usage, and institutional relationships, new metrics that not only rank journals, but also conferences, authors, and institutions will be created and v alidated. Finally , the proposed on tology was engineered to han- dle an extremely large semantic netw ork instantiation (on the order of 50 million articles with a corresp onding 1 bil- lion usage ev ents). The MESUR ontology was engineered to make a distinction b etw een required base-relationships and those, that if needed, can b e inferred from the base- relations. F uthermore, due to the fact that the MESUR on tology was dev elop ed to support the large-scale analysis of usage, many of the metadata prop erties suc h as article title or author name are not explicitly represented in the on tology and thus, as will b e demonstrated, suc h data can b e accessed outside the triple store by reference to a rela- tional database. 4. RELA TED W ORK Other efforts hav e pro duced and exploited scholarly on- tologies, but they do not cov er the needs of the MESUR pro ject for tw o primary reasons. First, they generally lack the integration of publication, citation and usage data, which MESUR requires in order to represen t and analyze these cru- cial stages of the public scholarly communication pro cess. Second, scalabilit y app ears to not hav e b een a ma jor con- cern when designing the ontologies and thus, instantiating them at the order of what MESUR will b e representing is unfeasible. Sometimes, the ontology is too elaborate, adding complexit y that rarely pays off for the simple reason that it is hard to realistically come by data to p opulate defined prop erties (e.g. detailed author or affiliation information). Other times, the ontology requires the storage of informa- tion that cannot realistically b e represented for v ast data collections using current triple store tec hnologies. Sev eral scholarly ontologies are av ailable in the DAML On tology Library 4 . While they fo cus on bibliographic con- structs, they do not model usage ev en ts. The same is true of the Seman tic Comm unity W eb Portal on tology [16], whic h, in addition maintains many detailed classes whose instanti- ation is unrealistic given what is recorded by mo dern sc hol- arly information systems. The Sc holOnto ontology was developed as part of an ef- fort aimed at enabling researchers to describ e and debate, via a seman tic netw ork, the contributions of a do cument, and its relationship to the literature [17]. While this on- tology supp orts the concept of a scholarly do cument and a sc holarly agen t, it focuses on formally summarizing and in- teractiv ely debating claims made in do cuments, not on ex- pressing the actual use of documents. Moreov er, support for bibliographic data is minimal whereas supp ort for discourse constructs, not required for MESUR, is v ery detailed. The ABC ontology [18] was primarily engineered as a com- 4 D AML On tology Library a v ailable at: h ttp://www.daml.org/ontologies/ mon conceptual mo del for the interoperability of a v ariet y of metadata on tologies from different domains. Although the ABC ontology is able to represent bibliographic and us- age concepts by means of constructs such as artifact (e.g. article), agent (e.g. author), and action (e.g. use), it is de- signed at a level of generality that do es not directly supp ort the gran ularit y required by the MESUR pro ject. An in teresting ontology-based approach w as dev eloped by the Ingenta MetaStore pro ject [19]. Unfortunately , again, the Ingenta ontology does not supp ort expressing usage of sc holarly do cuments, which is a primary concern in MESUR. Nev ertheless, the approach is inspiring b ecause Ingenta faces significan t c hallenges regarding scalability of the ontology- based representation, storage and access of their bibliographic metadata collection, which cov ers appro ximately 17 million journal articles. How ever, the scale of the MESUR data set is sev eral orders of magnitude larger, calling for optimiza- tions wherever p ossible. F or example, given the MESUR pro ject’s fo cus on usage, storing bibliographic properties (author names, abstract, titles, etc.) in the triple store, as done b y Ingen ta, is not essen tial. As a result, in order to im- pro ve triple store query efficiency , MESUR stores suc h data in a relational database, an d the MESUR ontology do es not explicitly represen t these literals. The principles esp oused by the On tologyX 5 on tology are inspiring. On tologyX uses c ontext classes as the “glue” for relating other classes, an approach that was adopted for the MESUR on tology . F or instance, the MESUR on tology do es not hav e a direct relationship b etw een an article and its publishing journal. Instead, there exists a publishing con- text that serves as an N-ary operator uniting a journal, the article, its publication date, its authors, and auxiliary infor- mation such as the source of the bibliographic data. The con text construct is intuitiv e and allows for future exten- sions to the ontology . On tologyX also help ed to determine the primary abstract classes for the MESUR on tology . Un- fortunately , OntologyX is a proprietary ontology for which v ery limited public information is a v ailable, making direct adoption unfeasible for MESUR. As a matter of fact, all in- spiration was deriv ed from a single Po werP oin t presentation from the 2005 FBRB W orkshop [20]. Finally , in the realm of usage data represen tation, no on tology-based efforts were found. Nev ertheless, the fol- lo wing existing schema-driv en approac hes w ere explored and serv ed as inspiration: the Op enURL ContextOb ject approach to facilitate OAI-PMH-based harvesting of scholarly usage ev ents [6], the XML Log standard to represent digital library logs [21], and the COUNTER sc hema to express journal level usage statistics [22]. 5. LEVERA GING RELA TION AL D A T ABASE TECHNOLOGY The MESUR pro ject makes use of a triple store to rep- resen t and access its collected data. While the triple store is still a maturing tec hnology , it provides man y adv an tages o ver the relational database mo del. F or one, the netw ork- based representation supp orts the use of netw ork analysis algorithms. F or the purp oses of the MESUR pro ject, a net work-based approach to data analysis will play a ma jor role in quan tifying the v alue of the sc holarly artifacts con- tained within it. Other b enefits that are found with triple 5 On tologyX a v ailable at: http://www.on tologyx.com/ store technologies that are not easily repro ducible within the relational database framework include ease of schema extension and ontological inferencing. A nov el contribution of the presen ted ontology is its so- lution to the problem of scalability found in mo dern triple store technologies [23]. While semantic net works pro vide a flexible medium for representing and searching knowledge, curren t triple store applications do not supp ort the amoun t of data that can b e represented at the upper limit of what is p ossible with mo dern relational database tec hnologies. Therefore, it w as necessary to b e selective of what infor- mation is actually mo deled b y the MESUR ontology . F or the MESUR pro ject, muc h of the data asso ciated with eac h sc holarly artifact is main tained outside the triple store in a relational database. The typical bibliographic record contains, for example, an article’s identifiers (e.g. DOI, SICI, etc.), authors, title, journal/conference/b ook, volume, issue, num ber, and page n umbers. Typical usage information con tains, for example, the users identifier (e.g. IP address), the time of the usage ev ent, and a session identifier. An example of the v arious bibliographic and usage prop erties are outlined in the T a- ble 1 and T able 2, resp ectiv ely . Note that the connection b et ween the bibliographic record and the usage ev ent o c- curs through the do c id (b olded prop erties). The doc id is a internally generated identifier created during the MESUR pro ject’s ingestion process. property v alue title The Con vergence of Digital Libraries ... author(s) Rodriguez, Bollen, V an de Somp el collection Journal of Information Science publisher Sage Publications date 2006 start page 149 end page 159 volume 32 issue 2 doi 10.1177/0165551506062327 doc id b5e1ab73-26b5-41f0-a83f-b47b4d737 T able 1: Example bibliographic prop erties property v alue even t id 45563ac2-c7d4-4669-ab9c-ac5129535ee5 time 2006-09-27 00:00:03 agent 4AD2FD457EB59CE08AAAF6EA2A63F session C3044206 affiliation California State Universit y , Los Angeles doc id b5e1ab73-26b5-41f0-a83f-b47b4d737 T able 2: Example usage prop erites The t w o tables demonstrate how bibliographic and usage data can b e easily represented in a relational database. F rom the relational database represen tation, a RDF N-T riple 6 data file can b e generated. One such solution for this relational database to triple store mapping is the D2R mapp er [24]. Ho wev er, note that not all data in the relational database is exp orted to this intermediate format. Instead, only those prop erties that promote triple store scalability and usage researc h were included. Th us, article titles, journal issues 6 N-T riple a v ailable at: h ttp://www.w3.org/2001/sw/RDFCore/n triples/ and v olumes, names of authors, to name a few, are not ex- plicitly represented within the triple store and thus, are not mo deled by the ontology . If a particular artifact prop ert y that is not in the ontology is required for a computation, the computing algorithm references the relational database holding the complete represen tation the acquired data. F or example, bi-directional resolution of the artifact with do c id 2 is depicted in Figure 4 where the resolving identifier is sp ecific to the artifact (for the sake of diagram readability , assume that 2 is b5e1ab73-26b5-41f0-a83f-b47b4d737 from T able 1 and 2). This mo del is counter to what is seen in other scholarly ontologies such as the Ingenta ontology [19]. This design c hoice was a ma jor factor that prompted the engineering of a new ontology for bibliographic and usage mo deling. 1 8 3 4 5 6 7 2 doc_id doi title 1 doi:10/jm.. "A Me.." 2 doi:10.1.. "The C.." T riple Store Relational Database Figure 4: The relationship b etw een the relational database and the triple store 6. THE MESUR ONT OLOGY The MESUR ontology is currently at version 2007-01 at http://www.mesur.org/schemas/2007-01/mesur (ab- breviated mesur ). F ull HTML do cumentation of the ontol- ogy can b e found at the namespace URI. The follo wing sec- tions will describe how bibliographic and usage data is mod- eled to meet the requirements of understanding large-scale usage behavior, while at the same time promoting scalabil- it y . 6.1 The Primary Classes The most general class in O WL is owl:Thing . The MESUR ontology provides three subclasses of owl:Thing . These MESUR classes are mesur:Agent , mesur:Document , and mesur:Context 7 . This is represented in Figure 5 where an edge denotes a rdfs:subClassOf relationship. Document Context Agent owl:Thing Figure 5: The primary cla sses of the MESUR ontol- ogy The Context classes serv e as the “glue” by which Agent s and Document s interact. A Context is analogous to rdf:Bag in that it is an N-ary operator unifying the literals and ob jects p ointed to by its resp ective prop erties. All rela- tionships b etw een Agent s and Document s o ccurs through 7 F or the remainder of this article, all classes that are not explicitly namespaced are from the mesur namespace. a particular Context . How ev er, as will b e demonstrated, direct relationships can be inferred. All inferred prop erties are denoted by the “(i)” notation in the follo wing UML class diagrams. All inferred prop erties are sup erfluous relation- ships since there is no loss of information by excluding their instan tiation (the information is con tained in other relation- ships). The algorithms for inferring them will b e discussed in their resp ective Context subsection. Curren tly , all the MESUR classes are specifications or generalizations of other classes. No holonym y/meron ym y (comp osite) class definitions are used at this stage of the on- tology’s developmen t. Figure 6 presents the complete taxon- om y of the MESUR on tology . This diagram primarily serves as a reference. Each class will b e discussed in the following sections. owl:Thing Context Document Agent State Event Unit Group Human Organization Affiliation Metric Weighted Relationship Uses Publishes Nominal Metric Numeric Metric Coauthor Citation Article Book Journal Article Book Article Preprint Article Conference Article Journal Edited Book Proceedings Proceedings Edition Journal Edition Figure 6: MESUR taxonomy 6.2 The Agent Classes The Agent taxonomy is diagrammed in Figure 7. An Agent can either b e a Human or an Organization . A Human is an actual individual whether that individual can b e uniquely iden tified (e.g. an do cument author) or not (e.g. a do cument user). The authored prop erty is an in- ferred relationship and denotes that an Agent authored a particular Document and the published prop erty denotes that an Agent has published a Document . The authored and published prop erty can b e inferred by information within the Publishes context discussed later. Similarly , the used prop ert y denotes that an Agent has used a par- ticular Document . The used prop erty can b e inferred from the Uses context. An Organization is a class that is used for b oth bib- liographic and usage pro v enance purp oses. Given that bib- liographic and usage data, at the large-scale, must b e har- v ested from multiple institutions, it is necessary to make a distinction b et ween the v arious data providers. In man y cases, an Organization can be b oth a bibliographic (e.g. a publisher) and a usage (e.g. a repository) pro vider. F urther- more, an Organization can also be an author’s academic institution (e.g. a univ ersity). Finally , all Agent s can hav e any num b er of affiliations. F or an Organization , this is a recursive definition whic h allo ws a n Organization to hav e many affiliate Organization s while at the same time allo wing for the Human leaf no des of an Organization to be represen ted b y the same construct. The rules gov erning the inference of the hasAffiliation and hasAffiliate prop erties are discussed in the section describing the Affiliation con text. Human hasAffiliate: Agent [0..*] (i) Organization hasAffiliation: Organization [0..*] (i) authored: Document [0..*] (i) used: Document [0..*] (i) published: Group [0..*] (i) Agent Figure 7: Classes of Agent and their prop erties 6.3 The Document Classes A Document is an abstract concept of a particular sc hol- arly product suc h as those depicted in Figure 8. authoredBy: Agent [0..*] (i) usedBy: Agent [0..*] (i) publishedBy: Agent [0..1] (i) Document containedIn: Group [0..1] (i) Article Book contains: Article [0..*] (i) Group Journal Proceedings partOf: Journal [1] hasIssue: xsd:int [0..1] hasV olume: xsd:int [0..1] JournalEdition JournalArticle ConferenceArticle BookArticle PreprintArticle partOf: Proceedings [1] hasIssue: xsd:int [0..1] ProceedingsEdition Unit contains: BookArticle [0..*] (i) EditedBook Figure 8: Classes of Do cument and their prop erties In general, Document ob jects are those artifacts that are written, used, and published b y Agent s. Thus, a Document can b e a sp ecific article, a b o ok, or some grouping such as a Journal , conference Proceedings , or an EditedBook . There are t w o Document subclasses to denote whether the Document is a collection ( Group ) or an individually writ- ten w ork ( Unit ). A Journal and Proceedings is an ab- stract concept of a collection of volumes/issues. An edi- tion to a pro ceedings or journal is asso ciated with its ab- stract Group by the partOf property . The authoredBy , containedIn , publishedBy , and contains prop erties can b e inferred from the Publishes context. Also, the usedBy property can be inferred from the Uses context. 6.4 The Context Classes As previously stated, all prop erties from the Agent and Document classes that are marked b y the “(i)” notation are inferred properties. These prop erties can b e automatically generated b y inference algorithms and th us, are not required for insertion into the triple store. What this means is that inheren t in the triple store is the data necessary to infer suc h relationships. Dep ending on the time (e.g. query com- plexit y) and space (e.g. disk space allo cation) constraints, the inclusion of these inferred prop erties is determined. At an y time, these prop erties can b e inserted or remov ed from the triple store. The v arious inferred properties are de- termined from their resp ective Context ob jects. There- fore, the MESUR owl:ObjectProperty taxonomy pro- vides tw o types of ob ject prop erties: ContextProperty and InferredProperty (see Figure 9). rdf:Property owl:ObjectProperty owl:DatatypeProperty ContextProperty InferredProperty Figure 9: The abstract MESUR prop erty classes A Context class is an N-ary operator muc h lik e an rdf:Bag . Curren t triple store technology expresses tertiary relation- ships. That means that only three resources are related b y a semantic netw ork edge (i.e. a sub ject URI, predicate URI, and ob ject URI). How ever, many real-w orld relation- ships are the pro duct of multiple interacting ob jects. It is the role of the v arious Context classes to pro vide relation- ships for more than three URIs. The Context classes are represen ted in Figure 10. Publishes hasGroup: Group [0..1] hasUnit: Unit [0..1] hasAuthor: Agent [1..*] hasPublisher: Agent [0..1] hasUser: Agent [1] hasAccess: xsd:string [0..1] hasSession: xsd:string [0..1] hasDocument: Document [1] Uses hasTime: xsd:datetime [1] hasProvider: Agent [0..1] Event hasSink: Agent or Document [1] hasSource: Agent or Document [1] hasWeight: xsd:float [0..1] WeightedRelationship hasSpec: xsd:string [0..1] hasObject: Agent or Document [1] Metric hasNominalV alue: xsd:string [1] NominalMetric hasNumericV alue: xsd:float [1] NumericMetric . . . . . . Citation Coauthor (i) Context hasStartTime: xsd:datetime [0..1] hasEndTime: xsd:datetime [0..1] State hasAffiliator: Organization [1] hasAffiliatee: Agent [1] Affiliation Figure 10: Classes of Context and their prop erties The Context class has tw o sub classes: Event and State . An Event is some measurement done by some provider at a particular p oint in time. F or example, the Publishes and Uses ev en ts are recorded b y publisher and rep ositories at some p oint in time. As a side note, the hasProvider prop ert y of the Event class is an efficient mo del for the represen tation of prov enance constructs. Instead of reifying ev ery statemen t with pro v enance data (e.g. triple x was sup- plied by provider y [19]), a single triple is pro vided for each Event (e.g. even t x was supplied b y pro vider y ). On the other side of the Context taxonomy are the State con texts. A State is some measurement that can, in some cases, o ccur ov er a span of time and are used to represen t complex relationships b et ween artifacts or as a wa y of at- tac hing high-level properties (i.e. metadata) to an artifact. The next sections will provide a detailed description of each Context class along with SP AQRL queries for inferring all the aforemen tioned InferredProperty prop erties. 6.4.1 The Publishes Context A Publishes even t states, in words, that a particular bibliographic data pro vider has ackno wledged that a set of authors hav e authored a unit that was published in a group by some publisher at a particular p oint in time. A Publishes ob ject relates a single bibliographic data pro vider, Agent authors, a Unit , an Agent publisher, a Group , and a publication ISO-8601 date time literal 8 . Figure 11 rep- resen ts a Publishes con text and the inferable prop erties (dashed edges) of the v arious asso ciated artifacts. All in- ferred prop erties hav e a resp ective inv erse relationship. Note that both PreprintArticle and Book publishing are rep- resen ted with OWL restrictions (i.e. they are not published in a Group ). The details of these restrictions can b e found in the actual on tology definition. Publishes Group Agent 2006-1 1-30T17:06:00-07:00 Agent hasGroup hasUnit hasAuthor hasPublisher hasTime Unit rdf:type rdf:type rdf:type rdf:type rdf:type 1..* 1 0..1 0..1 0..1 authoredBy 1..* authored 0..* containedIn 0..1 contains 0..* published publishedBy 0..* 0..1 hasProvider Agent rdf:type 0..1 Figure 11: Example Publishes Context The dashed edges in Figure 11 denote prop erties that are a rdfs:subClassOf the InferredProperty . F or in- stance, the abstract triple h Author , authors , Document i is inferred given the results of the following SP ARQL query , where for the sake of brevity , the PREFIX declarations are remo ved and the INSERT statement represents the insert of its triple argument into the triple store 9 . S E L E C T ? a ? b W H E R E 8 ISO-8601 a v ailable at: http://www.w3.org/TR/NOTE- datetime/ 9 Please note that all the presented SP AR QL queries are not optimized for speed, but instead, are optimized for readabil- it y . ( ? x r d f : t y p e m e s u r : P u b l i s h e s ) ( ? x m e s u r : h a s U n i t ? a ) ( ? x m e s u r : h a s A u t h o r ? b ) IN SE R T < ? a m e s u r : a u t h o r e d B y ? b > IN SE R T < ? b m e s u r : a u t h o r e d ? a > . T o infer the Group prop erty contains and Unit prop- ert y containedIn , the following SP ARQL query and INSERT statemen ts suffice. S E L E C T ? a ? b W H E R E ( ? x r d f : t y p e m e s u r : P u b l i s h e s ) ( ? x m e s u r : h a s U n i t ? a ) ( ? x m e s u r : h a s G r o u p ? b ) IN SE R T < ? a m e s u r : c o n t a i n e d I n ? b > IN SE R T < ? b m e s u r : c o n t a i n s ? a > . Finally , the published and publishedBy properties are inferred by: S E L E C T ? a ? b W H E R E ( ? x r d f : t y p e m e s u r : P u b l i s h e s ) ( ? x m e s u r : h a s P u b l i s h e r ? a ) ( ? x m e s u r : h a s G r o u p ? b ) IN SE R T < ? a m e s u r : p u b l i s h e d ? b > IN SE R T < ? b m e s u r : p u b l i s h e d B y ? a > . 6.4.2 The Uses Context The Uses context denotes a single usage ev en t where an Agent uses a Document at a particular p oint in time. The Uses context is diagrammed in Figure 12. Lik e the Publishes context, the Uses context is an N-ary con- struct. Dep ending on the usage provider, a session iden tifier and access t ype is recorded. A session identifier denotes the user’s login session. An access type denotes, for example, whether the used Document had its abstract viewed or w as fully do wnloaded. Uses Full Download Agent 2006-1 1-30T17:06:00-07:00 Agent hasProvider hasDocument hasUser hasAccess hasTime Document rdf:type rdf:type rdf:type rdf:type 1 1 1 0..1 0..1 4AD2FD457E hasSession 0..1 used usedBy 0..* 0..* Figure 12: Example Uses Context The following SP ARQL query and INSERT statemen ts represen t the inference of the usedBy and used inv erse prop erties of an Article do cument and Agent , respec- tiv ely . Also, note the last tw o INSERT statemen ts. These statemen ts demonstrate ho w Group usage information can also be inferred. S E L E C T ? a ? b ? c W H E R E ( ? x r d f : t y p e m e s u r : U s e s ) ( ? x m e s u r : h a s D o c u m e n t ? a ) ( ? a r d f : t y p e m e s u r : A r t i c l e ) ( ? x m e s u r : h a s U s e r ? b ) ( ? y r d f : t y p e m e s u r : P u b l i s h e s ) ( ? y m e s u r : h a s U n i t ? a ) ( ? y m e s u r : h a s G r o u p ? c ) IN SE R T < ? a m e s u r : u s e d B y ? b > IN SE R T < ? b m e s u r : u s e d ? a > IN SE R T < ? c m e s u r : u s e d B y ? b > IN SE R T < ? b m e s u r : u s e d ? c > . 6.4.3 The W eighted Relationship Context In many instances, one artifact is related to another by a particular seman tic. How ev er, in some instance, one arti- fact is related to another by a seman tic lab el and a floating p oin t weigh t v alue. F urthermore, that weigh ted relation- ship may hav e b een recorded ov er some p erio d of time. The WeightedRelationship state con text is used to represen t suc h relationships. The Citation state context denotes a weigh ted citation and is a rdfs:subClassOf the WeightedRelationship . F or Unit to Unit citation, the weigh t v alue is 1 . 0 (or no w eight prop erty to reduce the triple store fo otprint) and there are no start and end time p oints. How ev er, for Group to Group citations, the weigh t of the Citation represen ts ho w many times a particular Group cites another ov er some p eriod of time. Hence, it is necessary to denote the start and end p oints of b oth the source and the sink no des. Figure 13 diagrams a Citation context. F urthermore, the sink and source types can b e either an Agent or a Document , th us, Organization to Organization citations can b e represen ted. Citation 1 Agent or Document hasSource hasSink hasWeight Agent or Document rdf:type rdf:type rdf:type 1 0..1 1 hasSourceStartTime 2004-1 1-30T17:06:00-07:00 0..1 hasSourceEndTime 2006-1 1-30T17:06:00-07:00 0..1 hasSinkStartTime 2004-1 1-30T17:06:00-07:00 0..1 hasSinkEndTime 2006-1 1-30T17:06:00-07:00 0..1 Figure 13: Example Citation Context Giv en Unit to Unit citations, the Citation weigh t b e- t ween any tw o Group s can b e inferred. The following ex- ample SP AR QL query generates the Citation ob ject for citations from 2007 articles in the Journal of Informetrics (ISSN: 1751-1577) to 2005-2006 articles in Scientometrics (ISSN: 0138-9130). Assume that the URI of the journals are their ISSN num bers, the date time is represented as a y ear instead of the lengthy ISO-8601 representation, and the COUNT command is analogous to the SQL COUNT command (i.e. returns the n umber of elements returned b y the v ariable binding). S E L E C T ? x W H E R E ( ? x r d f : t y p e m e s u r : C i t a t i o n ) ( ? x m e s u r : h a s S o u r c e ? a ) ( ? x m e s u r : h a s S i n k ? b ) ( ? a r d f : t y p e m e s u r : A r t i c l e ) ( ? b r d f : t y p e m e s u r : A r t i c l e ) ( ? y r d f : t y p e m e s u r : P u b l i s h e s ) ( ? z r d f : t y p e m e s u r : P u b l i s h e s ) ( ? y m e s u r : h a s T i m e ? t ) A N D ( ? t > 2 0 0 4 A N D ? t < 2 0 0 7 ) ( ? z m e s u r : h a s T i m e ? u ) A N D ? u = 2 0 0 7 ( ? y m e s u r : h a s U n i t ? a ) ( ? z m e s u r : h a s U n i t ? b ) ( ? y m e s u r : h a s G r o u p ? c ) ( ? z m e s u r : h a s G r o u p ? d ) ( ? c m e s u r : p a r t O f u r n : i s s n : 1 7 5 1 − 1 5 7 7 ) ( ? d m e s u r : p a r t O f u r n : i s s n : 0 1 3 8 − 9 1 3 0 ) IN SE R T < 1 2 3 r d f : t y p e m e s u r : C i t a t i o n > IN SE R T < 1 2 3 m e s u r : h a s S o u r c e u r n : i s s n : 1 7 5 1 − 1 5 7 7 > IN SE R T < 1 2 3 m e s u r : h a s S i n k u r n : i s s n : 0 1 3 8 − 9 1 3 0 > IN SE R T < 1 2 3 m e s u r : h a s W e i g h t C O U N T( ? x ) > IN SE R T < 1 2 3 m e s u r . h a s S o u r c e S t a r t T i m e 2 0 0 7 > IN SE R T < 1 2 3 m e s u r : h a s S o u r c e E n d T i m e 2 0 0 7 > IN SE R T < 1 2 3 m e s u r . h a s S i n k S t a r t T i m e 2 0 0 5 > IN SE R T < 1 2 3 m e s u r : h a s S i n k E n d T i m e 2 0 0 6 > . Figure 14 diagrams the Coauthor weigh ted relationship con text. The weigh t v alue of this relationship denotes the n umber of times tw o authors ha v e coauthored together ov er a some p erio d of time. Coauthor 1 Agent hasSource hasSink hasWeight Agent rdf:type rdf:type rdf:type 1 0..1 1 hasStartTime 2004-1 1-30T17:06:00-07:00 0..1 hasEndTime 2006-1 1-30T17:06:00-07:00 0..1 Figure 14: Example Coauthor Context The following SP ARQL query demonstrates how to infer the weigh ted Coauthor relationship b etw een the authors Mark o ( lanl:marko ) and Herbert ( lanl:herbertv ) o ver all time. A time perio d for coauthorship counting can b e inserted in a fashion similar to the Citation example pre- vious. S E L E C T ? x W H E R E ( ? x r d f : t y p e m e s u r : P u b l i s h e s ) ( ? x m e s u r : h a s A u t h o r l a n l : m a r k o ) ( ? x m e s u r : h a s A u t h o r l a n l : h e r b e r t v ) IN SE R T < 1 2 3 r d f : t y p e m e s u r : C o a u t h o r > IN SE R T < 1 2 3 m e s u r : h a s S o u r c e l a n l : m a r k o > IN SE R T < 1 2 3 m e s u r : h a s S i n k l a n l : h e r b e r t v > IN SE R T < 1 2 3 m e s u r : h a s W e i g h t C O U N T( ? x ) > IN SE R T < 4 5 6 r d f : t y p e m e s u r : C o a u t h o r > IN SE R T < 4 5 6 m e s u r : h a s S o u r c e l a n l : h e r b e r t v > IN SE R T < 4 5 6 m e s u r : h a s S i n k l a n l : m a r k o > IN SE R T < 4 5 6 m e s u r : h a s W e i g h t C O U N T( ? x ) > . 6.4.4 The Affiliation Context An Affiliation context denotes that a particular Human is affiliated with an Organization or that an Organization is affiliated with another Organization . An Affiliation can b e represented as o ccurring ov er a particular p erio d of time. An example of an Affiliation state context is di- agrammed in Figure 15. Affiliation Agent hasAffiliator hasAffiliatee Organization rdf:type rdf:type rdf:type 1 1 hasStartTime 1998-1 1-30T17:06:00-07:00 0..1 hasEndTime 2006-1 1-30T17:06:00-07:00 0..1 Figure 15: Example Affiliation Context The hasAffiliate and hasAffiliation prop erties of the Agent classes can b e inferred by the follo wing SP ARQL query . S E L E C T ? a ? b W H E R E ( ? x r d f : t y p e m e s u r : A f f i l i a t i o n ) ( ? x m e s u r : h a s A f f i l i a t o r ? a ) ( ? x m e s u r : h a s A f f i l i a t e e ? b ) IN SE R T < ? a m e s u r : h a s A f f i l i a t e ? b > IN SE R T < ? b m e s u r : h a s A f f i l i a t i o n ? a > . 6.4.5 The Metric Context The primary ob jective of the MESUR pro ject is to study the relationship betw een usage-based v alue metrics (e.g. Us- age Impact F actor [5]) and citation-based v alue metrics (e.g. ISI Impact F actor [15] and the Y-F actor [25]). The Metric con text allows for the explicit representation of such met- rics. The Metric context has b oth the NumericMetric and NominalMetric sub classes. Figure 16 diagrams the 2007 ImpactFactor numeric metric context for a Group . Note that the Context hierarch y in Figure 10 does not rep- resen t the set of Metric s explored by the MESUR pro ject. This taxonom y will b e presen ted in a future publication. 1.78 hasNumericV alue 1 Impact Factor Group rdf:type rdf:type 1 hasObject hasStartTime 2007-01-01T00:00:00-00:00 0..1 hasEndTime 2007-12-30T00:00:00-00:00 0..1 hasSpec ISI provided 0..1 Figure 16: Example Impact F actor Context The example SP ARQL query and respective INSERT state- men ts demonstrate how to calculate the 2007 Impact F actor for the Pro ceedings of the Joint Conference on Digital Li- braries (JCDL ISSN: 1082-9873). The 2007 Impact F actor for the JCDL is defined as the num b er of citations from any Unit published in 2007 to articles in the JCDL pro ceedings published in either 2005 or 2006 normalized by the total n umber of articles published by JCDL in 2005 and 2006 [15]. S E L E C T ? x W H E R E ( ? x r d f : t y p e m e s u r : P u b l i s h e s ) ( ? x m e s u r : h a s U n i t ? a ) ( ? x m e s u r : h a s G r o u p ? b ) ( ? b m e s u r : p a r t O f u r n : i s s n : 1 0 8 2 − 9 8 7 3 ) ( ? x m e s u r : h a s T i m e ? t ) A N D ( ? t > 2 0 0 4 A N D ? t < 2 0 0 7 ) ( ? y r d f : t y p e m e s u r : C i t a t i o n ) ( ? y m e s u r : h a s S o u r c e ? c ) ( ? y m e s u r : h a s S i n k ? a ) ( ? z r d f : t y p e m e s u r : P u b l i s h e s ) ( ? z m e s u r : h a s U n i t ? c ) ( ? z m e s u r : h a s T i m e ? u ) A N D ? u = 2 0 0 7 S E L E C T ? y W H E R E ( ? y r d f : t y p e m e s u r : P u b l i s h e s ) ( ? y m e s u r : h a s G r o u p ? a ) ( ? a m e s u r : p a r t O f u r n : i s s n : 1 0 8 2 − 9 8 7 3 ) ( ? y m e s u r : h a s T i m e ? t ) A N D ( ? t > 2 0 0 4 A N D ? t < 2 0 0 7 ) IN SE R T < 1 2 3 r d f : t y p e m e s u r : I m p a c t F a c t o r > IN SE R T < 1 2 3 m e s u r : h a s O b j e c t u r n : i s s n : 1 0 8 2 − 9 8 7 3 > IN SE R T < 1 2 3 m e s u r : h a s S t a r t T i m e 2 0 0 7 > IN SE R T < 1 2 3 m e s u r : h a s E n d T i m e 2 0 0 7 > IN SE R T < 1 2 3 m e s u r : h a s N u m b e r i c V a l u e (C O U N T( ? x ) / C O U N T( ? y ) ) > . The 2007 Usage Impact F actor for the JCDL Pro ceedings can b e calculated by using the following SP AR QL queries and INSERT commands. The 2007 Usage Impact F actor for the JCDL is defined as the num ber of usage even ts in 2007 that p ertain to articles published in the JCDL pro ceedings in either 2005 or 2006 normalized b y the total num ber of articles published by the JCDL in 2005 and 2006 [5]. S E L E C T ? x W H E R E ( ? x r d f : t y p e m e s u r : U s e s ) ( ? x m e s u r : h a s D o c u m e n t ? a ) ( ? x m e s u r : h a s T i m e ? t ) A N D ? t = 2 0 0 7 ( ? y r d f : t y p e m e s u r : P u b l i s h e s ) ( ? y m e s u r : h a s U n i t ? a ) ( ? y m e s u r : h a s G r o u p ? c ) ( ? c m e s u r : p a r t O f u r n : i s s n : 1 0 8 2 − 9 8 7 3 ) ( ? y m e s u r : h a s T i m e ? u ) A N D ( ? u > 2 0 0 4 A N D ? u < 2 0 0 7 ) S E L E C T ? y W H E R E ( ? y r d f : t y p e m e s u r : P u b l i s h e s ) ( ? y m e s u r : h a s G r o u p ? a ) ( ? a m e s u r : p a r t O f u r n : i s s n : 1 0 8 2 − 9 8 7 3 ) ( ? y m e s u r : h a s T i m e ? t ) A N D ( ? t > 2 0 0 4 O R ? t < 2 0 0 7 ) IN SE R T < 1 2 3 r d f : t y p e m e s u r : U s a g e I m p a c t F a c t o r > IN SE R T < 1 2 3 m e s u r : h a s O b j e c t u r n : i s s n : 1 0 8 2 − 9 8 7 3 > IN SE R T < 1 2 3 m e s u r : h a s N u m e r i c V a l u e (C O U N T( ? x ) / C O U N T( ? y ) ) > . As demonstrated, the presented metrics can b e easily cal- culated using simple SP ARQL queries. How ev er, more com- plex metrics, such as those that are recursive in definition, can be computed using other semantic net w ork algorithms. F or example, the eigenv ector-based Y-F actor [25] can b e computed in semantic netw orks using the grammar-based random walk er framework presented in [26]. The ob jec- tiv e of the MESUR pro ject is to understand the space of suc h metrics and their application to v aluing artifacts in the sc holarly communit y . F uture work in this area will rep ort the finding that are derived from such algorithms. 7. CONCLUSION This article presented the MESUR ontology which has b een engineered to provide an in tegrated mo del of biblio- graphic, citation, and usage asp ects of the scholarly com- m unity . The ontology focuses only on that information for whic h large-scale real world data exists, supp orts usage re- searc h, and whose instantiation is scalable to an estimated 50 million articles and 1 billion usage even ts. A no vel ap- proac h to data representation was defined that lev erages b oth relational database and triple store technology . The MESUR pro ject was started in Octob er of 2006 and thus, is still in its early stages of developmen t. While a trim on- tology has b een presented, the effects of this ontology on load and query times is still inconclusive. F uture work will presen t benchmark results of the MESUR triple store. 8. A CKNO WLEDGMENTS This research is supp orted by a grant from the Andrew W. Mellon F oundation. 9. REFERENCES [1] M. J. Kurtz, G. Eic hhorn, A. Accomazzi, C. S. Gran t, M. Demleitner, and S. S. Murray , “The bibliometric prop erties of article readership information,” Journal of the Americ an Society for Information Scienc e and T e chnolo gy , vol. 56, no. 2, pp. 111–128, 2005. [2] T. Brody , S. Harnad, and L. Carr, “Earlier w eb usage statistics as predictors of later citation impact.” Journal of the Americ an So ciety for Information Scienc e and T e chnolo gy , vol. 57, no. 8, pp. 1060 – 1072, 2006. [3] J. Bollen and H. V an de Somp el, “Mapping the structure of science through usage,” Scientometrics , v ol. 69, no. 2, 2006. [4] J. Bollen, H. V an de Somp el, J. Smith, and R. Luce, “T ow ard alternative metrics of journal impact: a comparison of download and citation data,” Information Pr o c essing and Management , v ol. 41, no. 6, pp. 1419–1440, 2005. [Online]. Av ailable: h ttp://www.arxiv.org/p df/cs.DL/0503007 [5] J. Bollen and H. V an de Somp el, “Usage impact factor: the effects of sample characteristics on usage-based impact metrics,” Los Alamos National Lab oratory , T ec h. Rep., 2006. [Online]. Av ailable: h [6] ——, “An arc hitecture for the aggregation and analysis of scholarly usage data,” in Joint Confer enc e on Digital Libr aries (JCDL06) , Chapel Hill, NC, June 2006, pp. 298–307. [7] D. L. McGuinness and F. v an Harmelen, “OWL web on tology language ov erview,” F ebruary 2004. [Online]. Av ailable: http://www.w3.org/TR/o wl- features/ [8] J. F. So w a, Ed., Principles of Semantic Networks: Explor ations in the R epr esentation of Know ledge . San Mateo, CA: Morgan Kaufmann, 1991. [9] H. P . Alesso and C. F. Smith, Developing Semantic Web Servic es . W ellesey , MA: A.K. P eters L TD, 2005. [10] F. Manola and E. Miller, “RDF primer: W3C recommendation,” F ebruary 2004. [Online]. Av ailable: h ttp://www.w3.org/TR/rdf- primer/ [11] T. Berners-Lee, , R. Fielding, D. Soft ware, L. Masin ter, and A. Systems, “Uniform Resource Iden tifier (URI): Generic Syntax,” January 2005. [12] N. F. No y , W. Grosso, and M. A. Musen, “The kno wledge model of Protege-2000: Combining in terop erability and flexibilit y ,” in International Confer enc e on Know le dge Engine ering and Know le dge Management , Juan-les-Pins, F rance, 2000. [13] A. Magk anaraki, G. Karv ounarakis, T. T. Anh, V. Christophides, and D. Plexousakis, “Ontology storage and querying,” ´ Ecole Nationale Sup´ erieure des T ´ el´ ecommunications, T ech. Rep., April 2002. [Online]. Av ailable: http://139.91.183.30: 9090/RDF/publications/tr308.p df [14] E. Prud’hommeaux and A. Seaborne, “SP AR QL query language for RDF,” W orld Wide W eb Consortium, T ech. Rep., Octob er 2004. [Online]. Av ailable: http://www.w3.org/TR/2004/ WD- rdf- sparql- query- 20041012/ [15] E. Garfield, “Journal impact factor: a brief review,” Canadian Me dic al Asso ciation Journal , vol. 161, pp. 979–980, 1999. [16] S. Staab, J. Angele, S. Deck er, M. Erdmann, A. Hotho, A. Maedc he, H. P . Sc hnurr, R. Studer, and Y. Sure, “Semantic communit y w eb p ortals,” in 9th International World Wide Web Conferenc e , Amsterdam, Netherlands, May 2000. [Online]. Av ailable: http://www9.org/w9cdrom/134/134.h tml [17] S. B. Sh um, E. Motta, and J. Domingue, “Scholon to: an on tology-based digital library serv er for research do cumen ts and discourse,” International Journal on Digital Libr aries , v ol. 3, no. 3, pp. 237–248, 2000. [Online]. Av ailable: citeseer.ist.psu.edu/sh um00scholon to.h tml [18] C. Lagoze and J. Hun ter, “The ABC on tology and mo del,” Journal of Digital Information , vol. 2, no. 2, 2001. [19] K. P ortwin and P . P arv atik ar, “Building and managing a massive triple store: An experience rep ort,” in XT ech: Building Web 2.0 , Amsterdam, Netherlands, 2006. [20] G. Rust, “On tologyx,” in F unctional R e quir ements for Biblio gr aphic R e c or ds Workshop Pr o c e e dings , Dublin, Ohio, Ma y 2005. [21] M. A. Goncalv es, M. Luo, R. Shen, M. F. Ali, and E. A. F ox, “An XML log standard and to ol for digital library logging analysis,” in ECDL 2002: LNCS 2458 , M. Agosti and C. Thanos, Eds. Berlin: Springer-V erlag, Septem ber 2002, pp. 129–143. [22] P . T. Shepherd, “Pro ject COUNTER - Setting in ternational standards for online usage statistics,” Journal of Information Pr o c essing and Management , v ol. 47, no. 4, pp. 245 – 257, 2004. [23] R. Lee, “Scalabilit y rep ort on triple store applications,” Massac h usetts Institute of T ec hnology , T ech. Rep., 2004. [24] C. Bizer, “D2R - a database to RDF mapping language,” in The Twelth International World Wide Web Confer enc e (WWW03) , Budap est, Hungary , Ma y 2003. [25] J. Bollen, M. A. Rodriguez, and H. V an de Somp el, “Journal status,” Scientometrics , v ol. 69, no. 3, Decem b er 2006. [26] M. A. Rodriguez, “Grammar-based random w alkers in seman tic net works,” Los Alamos National Laboratory , T ech. Rep. LA-UR-06-7791, 2007. [Online]. Av ailable: h ttp://www.so e.ucsc.edu/ ∼ okram/pap ers/ random- grammar.p df
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment