On the Statistical Modeling and Analysis of Repairable Systems
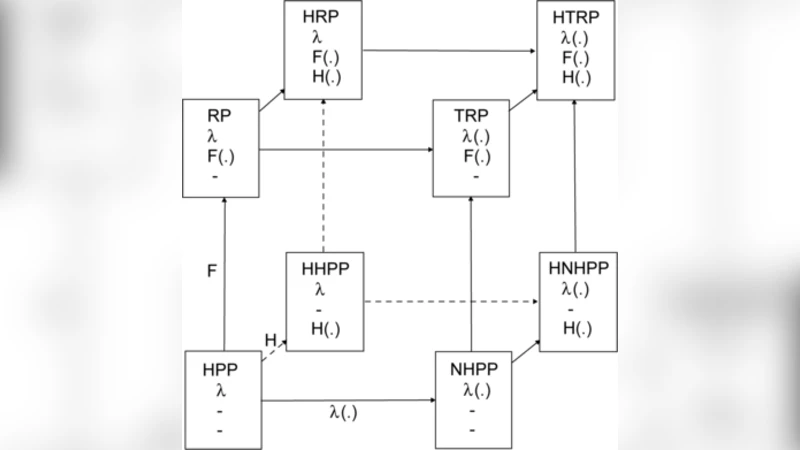
We review basic modeling approaches for failure and maintenance data from repairable systems. In particular we consider imperfect repair models, defined in terms of virtual age processes, and the trend-renewal process which extends the nonhomogeneous Poisson process and the renewal process. In the case where several systems of the same kind are observed, we show how observed covariates and unobserved heterogeneity can be included in the models. We also consider various approaches to trend testing. Modern reliability data bases usually contain information on the type of failure, the type of maintenance and so forth in addition to the failure times themselves. Basing our work on recent literature we present a framework where the observed events are modeled as marked point processes, with marks labeling the types of events. Throughout the paper the emphasis is more on modeling than on statistical inference.
💡 Research Summary
The paper provides a comprehensive review of statistical modeling techniques for failure and maintenance data arising from repairable systems, emphasizing model formulation rather than inference procedures. It begins by critiquing the traditional reliance on either renewal processes (RP) or non‑homogeneous Poisson processes (NHPP) to describe failure times, noting that these frameworks assume either perfect renewal or a deterministic trend, which rarely matches real‑world repair actions. To address this gap, the authors introduce imperfect‑repair models based on the concept of a virtual age (VA). In a VA model, each repair updates the system’s effective age to a value between zero (as‑good‑as‑new) and the current chronological age (minimal repair). This continuous adjustment allows the hazard function to reflect wear‑out or rejuvenation dynamics, and the resulting inter‑failure time distribution can be derived analytically from the underlying baseline hazard.
Building on the VA framework, the paper presents the Trend‑Renewal Process (TRP), a unifying model that multiplies a baseline hazard λ₀(t) by a time‑dependent trend function g(t). By choosing g(t) to be linear, exponential, polynomial, or any flexible parametric form, TRP simultaneously captures the stochastic renewal structure and systematic trends (e.g., increasing failure rate due to aging or decreasing rate after preventive maintenance). The authors show that NHPP and RP appear as special cases when g(t) is constant or when the renewal component collapses, respectively.
When multiple identical units are observed, the authors discuss how to incorporate observed covariates (temperature, load, operating regime) and unobserved heterogeneity (frailty). They propose mixed‑effects formulations where covariates enter the intensity function through a log‑linear link, while frailty terms are modeled as random effects, typically assumed gamma‑distributed. This hierarchical structure enables borrowing strength across units, improves parameter stability, and yields interpretable unit‑specific reliability measures.
The paper also surveys several trend‑testing methodologies. Classical approaches include Poisson regression likelihood ratio tests and cumulative sum (CUSUM) charts. More sophisticated techniques involve Markov‑type tests that assess changes in the underlying intensity process. A key contribution is the adoption of marked point processes: each event is labeled with a “mark” indicating failure type, maintenance type, or other categorical information. By modeling both the event times and the mark distribution, one can test for trends within specific failure modes, evaluate interactions between maintenance actions and failure rates, and exploit the rich metadata now available in modern reliability databases.
Although the focus remains on model specification, the authors briefly outline estimation strategies, recommending maximum likelihood or Bayesian methods implemented in existing software (e.g., R packages “repa”, “survival”, “frailtypack”). They acknowledge that inference can be computationally intensive, especially when frailty and mark processes are combined, and suggest that future work should develop efficient algorithms and diagnostic tools.
In conclusion, the paper delivers a unified, flexible modeling framework for repairable systems that integrates virtual‑age based imperfect repair, trend‑renewal dynamics, covariate and frailty effects, and marked point process representations. By prioritizing model structure, the authors equip reliability engineers and statisticians with a versatile toolkit capable of handling the complex, heterogeneous data typical of contemporary maintenance environments, while also laying the groundwork for more advanced inferential and predictive developments.
Comments & Academic Discussion
Loading comments...
Leave a Comment