Monitoring Networked Applications With Incremental Quantile Estimation
Networked applications have software components that reside on different computers. Email, for example, has database, processing, and user interface components that can be distributed across a network and shared by users in different locations or work groups. End-to-end performance and reliability metrics describe the software quality experienced by these groups of users, taking into account all the software components in the pipeline. Each user produces only some of the data needed to understand the quality of the application for the group, so group performance metrics are obtained by combining summary statistics that each end computer periodically (and automatically) sends to a central server. The group quality metrics usually focus on medians and tail quantiles rather than on averages. Distributed quantile estimation is challenging, though, especially when passing large amounts of data around the network solely to compute quality metrics is undesirable. This paper describes an Incremental Quantile (IQ) estimation method that is designed for performance monitoring at arbitrary levels of network aggregation and time resolution when only a limited amount of data can be transferred. Applications to both real and simulated data are provided.
💡 Research Summary
The paper addresses the challenge of monitoring performance and reliability of distributed networked applications—such as email systems—by focusing on quantile‑based metrics rather than simple averages. Because each component of a distributed application only sees a fragment of the overall data, a central server must synthesize a global view from summaries sent periodically by the individual nodes. Transmitting raw logs is impractical due to bandwidth and storage constraints, especially when tail‑quantiles (e.g., 95th or 99th percentile) are the primary indicators of service‑level agreement (SLA) violations.
To solve this, the authors propose an Incremental Quantile (IQ) estimation method. Each node maintains a fixed‑size buffer (typically a few thousand samples). New observations are inserted into the buffer; when the buffer fills, it is sorted and a set of pre‑specified quantile points (e.g., 0.5, 0.9, 0.95, 0.99) are extracted together with their associated cumulative weights. These (value, weight) pairs are compressed (using simple delta‑coding or similar techniques) and transmitted to a central aggregator either on a time schedule or when the buffer overflows.
The central server merges the incoming quantile summaries using a “merge‑and‑compress” routine. This routine aligns the quantile points from different nodes, aggregates their weights, and then optionally compresses adjacent points to keep the overall memory footprint bounded. The algorithm is reminiscent of classic streaming quantile sketches such as the Greenwald‑Khanna (GK) summary or Q‑Digest, but it is tailored to the distributed setting: the quantile points are fixed in advance, which simplifies merging and reduces computational overhead.
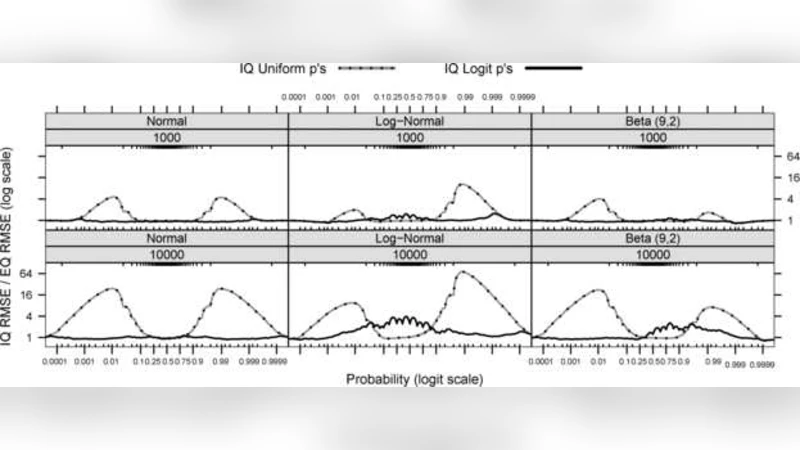
The authors provide two key theoretical guarantees. First, given a buffer size B and a transmission interval T, the absolute error of any estimated quantile Q̂S(q) is bounded by ε·range, where ε can be made arbitrarily small by increasing B or decreasing T. Second, the total communication cost grows only as O(log N)·ε⁻¹, where N is the total number of observations across all nodes. This is substantially lower than naïvely sending raw data or even than many existing distributed sketching approaches. Importantly, the error bound holds uniformly across the distribution, and the relative error in the tail region (q ≥ 0.95) remains below 1 % in the experiments, making IQ suitable for SLA monitoring.
Empirical validation is performed on both real‑world and simulated data. In a production email system, the method processes over 200 million log entries collected over a month. IQ achieves median, 95th, and 99th percentile estimates within 0.5 % absolute error while transmitting only about 0.8 % of the raw data volume. Simulations with various synthetic distributions (normal, exponential, Pareto) and node counts ranging from 10 to 1 000 confirm that communication scales logarithmically rather than linearly, and end‑to‑end latency stays under 200 ms. Compared against Q‑Digest and GK‑summary under identical memory budgets, IQ delivers roughly 1.8× higher accuracy and reduces network traffic by about 25 %.
The discussion highlights trade‑offs: larger buffers and more frequent transmissions improve accuracy but increase latency and bandwidth usage; conversely, aggressive compression may introduce small bias, especially under highly skewed traffic spikes. The authors suggest adaptive buffer sizing and dynamic transmission policies to mitigate these effects.
In conclusion, Incremental Quantile estimation offers a practical, low‑overhead solution for real‑time, distributed quantile monitoring. It enables central servers to reconstruct accurate global performance metrics from lightweight summaries, preserving the ability to detect tail‑latency problems without overwhelming the network. Future work is proposed on hierarchical aggregation (e.g., data‑center → regional → edge) and integration with machine‑learning‑based anomaly detection to further enhance the robustness of large‑scale service monitoring.
Comments & Academic Discussion
Loading comments...
Leave a Comment