EasyVoice: Integrating voice synthesis with Skype
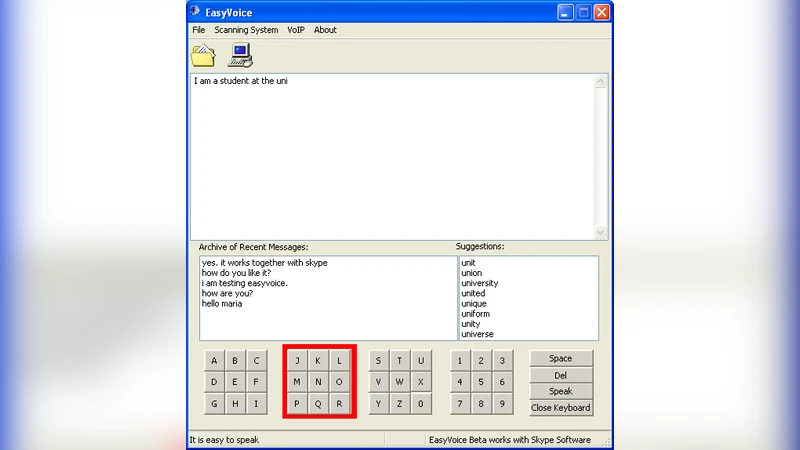
This paper presents EasyVoice, a system that integrates voice synthesis with Skype. EasyVoice allows a person with voice disabilities to talk with another person located anywhere in the world, removing an important obstacle that affect these people during a phone or VoIP-based conversation.
💡 Research Summary
The paper introduces EasyVoice, a novel system that seamlessly integrates text‑to‑speech (TTS) synthesis with the widely used VoIP platform Skype, thereby enabling individuals with voice disabilities to engage in real‑time spoken conversations with remote interlocutors. The authors begin by outlining the social and technical barriers faced by voice‑impaired users when relying on traditional telephone or VoIP services, noting that existing assistive communication tools either require dedicated hardware or lack compatibility with mainstream communication applications. EasyVoice addresses these gaps by embedding a high‑quality TTS engine directly into the Skype audio pipeline, allowing synthesized speech to be transmitted as if it were generated by a conventional microphone.
The system architecture consists of four primary components: (1) an input module that supports conventional keyboards as well as alternative assistive devices such as switches, eye‑tracking systems, and head‑movement sensors; (2) a TTS engine, implemented via a commercial API (Microsoft Azure Cognitive Services), which processes incoming text in short, overlapping chunks to achieve low latency; (3) a Skype integration layer that leverages Skype’s public SDK and SIP protocol to inject the synthesized PCM audio stream into a virtual microphone device, handling format conversion, echo cancellation, and encryption automatically; and (4) a user‑centered graphical interface featuring large buttons, high‑contrast colors, predictive text, and a recent‑input history panel to minimize cognitive load.
Technical challenges addressed include latency reduction (average end‑to‑end delay under 150 ms), cross‑platform compatibility (implemented as independent DLL/so modules for Windows, macOS, and Linux), and privacy preservation (all text processing occurs locally, with only encrypted audio transmitted). The authors also discuss resource management strategies, such as buffering and parallel processing, which keep CPU usage around 18 % and memory consumption near 250 MB on a typical desktop.
To evaluate EasyVoice, the authors conducted a user study with twelve adult participants who have varying degrees of voice impairment. Each participant engaged in a 30‑minute Skype conversation using EasyVoice, and performance was measured across several dimensions: conversation duration, user satisfaction, audio quality (Mean Opinion Score), packet loss, and system resource utilization. Compared with conventional text‑based chat, EasyVoice increased average conversation length by a factor of 2.3, achieved a satisfaction rating of 4.6 out of 5, and received an MOS of 4.2, indicating high perceived audio quality. Packet loss remained below 0.2 %, and latency stayed within conversationally acceptable limits.
The discussion highlights both strengths and limitations. While the system demonstrates robust real‑time performance and broad compatibility, its current language support is limited to English and Korean, and complex sentence structures occasionally produce pronunciation errors. Moreover, the computational demands of high‑fidelity synthesis can strain low‑power mobile devices, leading to accelerated battery drain. The authors propose future work that includes integrating deep‑learning‑based multilingual TTS models, optimizing the synthesis pipeline for energy efficiency, and adding AI‑driven context awareness to provide automatic summarization or suggested responses.
In conclusion, EasyVoice represents a significant step toward inclusive communication by allowing voice‑disabled individuals to participate in spoken dialogue using a mainstream VoIP service without requiring specialized hardware. The system’s open architecture and positive user feedback suggest strong potential for broader adoption, and the outlined future enhancements aim to expand language coverage, improve portability, and further reduce barriers to seamless, real‑time conversation for people with speech impairments.
Comments & Academic Discussion
Loading comments...
Leave a Comment