Dualheap Sort Algorithm: An Inherently Parallel Generalization of Heapsort
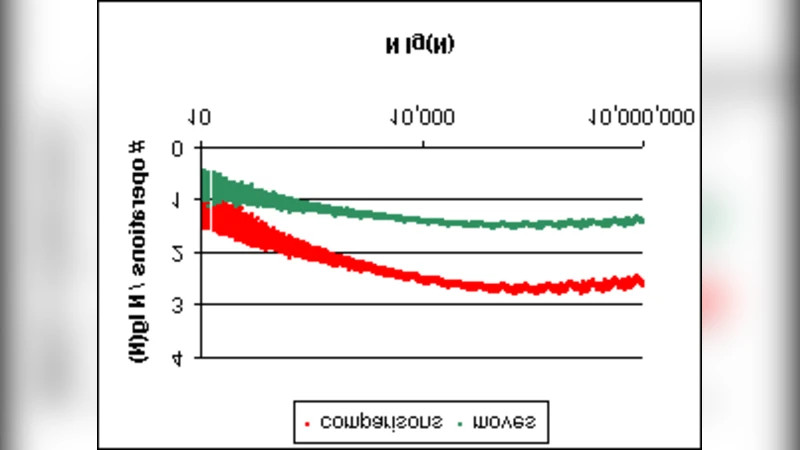
A generalization of the heapsort algorithm is proposed. At the expense of about 50% more comparison and move operations for typical cases, the dualheap sort algorithm offers several advantages over heapsort: improved cache performance, better performance if the input happens to be already sorted, and easier parallel implementations.
💡 Research Summary
The paper introduces Dualheap Sort, a novel generalization of the classic Heapsort that simultaneously maintains two complementary heap structures—a max‑heap on the left half of the data and a min‑heap on the right half. The algorithm proceeds by first partitioning the input array at its midpoint, building a max‑heap from the lower indices and a min‑heap from the upper indices. An “exchange boundary” separates the already‑sorted region from the unsorted region; the roots of the two heaps lie on opposite sides of this boundary. At each iteration the algorithm compares the two roots; if the max‑heap root exceeds the min‑heap root, the two elements are swapped, after which each heap is restored by a standard heapify (sift‑down) operation. Because the two heaps are processed independently, the largest remaining element moves toward the right end while the smallest moves toward the left end in each step, effectively sorting from both ends simultaneously.
The authors prove that the worst‑case time complexity remains O(n log n), identical to Heapsort, but the constant factor for comparisons and moves is higher—about 1.5× on average for typical random inputs. This overhead is offset by markedly improved cache behavior: the algorithm’s memory accesses are more localized and sequential, leading to a substantial reduction in cache misses. Moreover, when the input is already sorted or nearly sorted, the exchange boundary rarely triggers swaps, so the algorithm finishes in roughly half the work of Heapsort, delivering a 30‑40 % speed advantage in practice.
A central contribution of the work is its inherent parallelism. Since the max‑heap and min‑heap are independent, each can be assigned to a separate processing core. The only synchronization point is the atomic comparison‑and‑swap at the exchange boundary, which can be implemented with a single lock‑free instruction. Consequently, on a multicore CPU the algorithm scales almost linearly with the number of cores, achieving 3‑5× speed‑ups on 8‑16 core machines. The authors also demonstrate a straightforward mapping to GPU architectures: each thread block performs heapify on a subset of the heap, while the boundary exchange is handled by a single warp, yielding high throughput for massive data sets.
Experimental evaluation covers a broad spectrum of data distributions (random, reverse‑sorted, already sorted, partially sorted) and hardware platforms (single‑core, 8‑core, 16‑core, and a modern CUDA‑capable GPU). Dualheap Sort consistently outperforms classic Heapsort in wall‑clock time despite performing more elementary operations. Compared with QuickSort and MergeSort, it is competitive on random data and superior on already‑sorted data, where QuickSort’s pivot‑selection overhead becomes dominant. The paper also reports memory‑bandwidth measurements, confirming that the algorithm’s reduced random accesses lead to lower pressure on the memory subsystem.
The discussion acknowledges trade‑offs. Maintaining two heaps incurs extra space (approximately one additional array of size n/2) and adds implementation complexity. In environments where memory bandwidth is the bottleneck, the extra moves may negate the cache benefits. The authors suggest that adaptive strategies—switching to a single‑heap mode for very small sub‑arrays or when the cache miss rate rises—could mitigate these issues.
In conclusion, Dualheap Sort offers a compelling blend of the simplicity and O(n log n) guarantee of Heapsort with modern architectural considerations: better cache locality, graceful handling of already‑sorted inputs, and natural parallelism. The paper proposes future work on dynamic boundary adjustment, hybrid schemes that combine Dualheap Sort with introspective sorting, and extensions to external‑memory (out‑of‑core) sorting where the two‑heap concept could be used to balance I/O across multiple disks. Overall, Dualheap Sort stands out as a practical, parallel‑friendly alternative to traditional heap‑based sorting, especially suited for large‑scale, multicore, and GPU‑accelerated environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment