Dualheap Selection Algorithm: Efficient, Inherently Parallel and Somewhat Mysterious
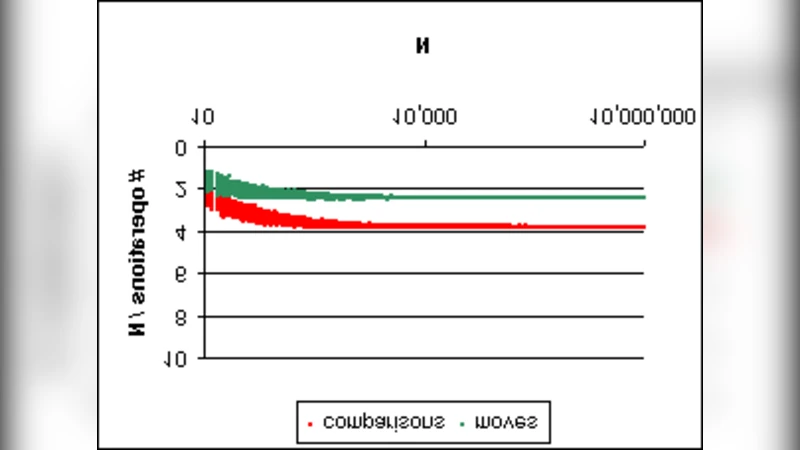
An inherently parallel algorithm is proposed that efficiently performs selection: finding the K-th largest member of a set of N members. Selection is a common component of many more complex algorithms and therefore is a widely studied problem. Not much is new in the proposed dualheap selection algorithm: the heap data structure is from J.W.J.Williams, the bottom-up heap construction is from R.W. Floyd, and the concept of a two heap data structure is from J.W.J. Williams and D.E. Knuth. The algorithm’s novelty is limited to a few relatively minor implementation twists: 1) the two heaps are oriented with their roots at the partition values rather than at the minimum and maximum values, 2)the coding of one of the heaps (the heap of smaller values) employs negative indexing, and 3) the exchange phase of the algorithm is similar to a bottom-up heap construction, but navigates the heap with a post-order tree traversal. When run on a single processor, the dualheap selection algorithm’s performance is competitive with quickselect with median estimation, a common variant of C.A.R. Hoare’s quicksort algorithm. When run on parallel processors, the dualheap selection algorithm is superior due to its subtasks that are easily partitioned and innately balanced.
💡 Research Summary
The paper introduces a novel selection algorithm—dubbed the Dual‑heap Selection Algorithm—that finds the K‑th largest element in an unsorted set of N items. Selection is a fundamental sub‑problem in many higher‑level algorithms, and while quickselect (Hoare’s quicksort variant with median‑of‑three or other pivot estimations) dominates practical use, its worst‑case quadratic behavior and limited parallel scalability motivate alternative approaches.
The proposed method builds on three well‑known ideas: (1) the binary heap data structure (Williams, 1964), (2) Floyd’s bottom‑up heap construction (1964), and (3) the concept of a “two‑heap” data structure as described by Williams and Knuth. The novelty lies in three implementation twists. First, the two heaps are anchored at the current partition value rather than at the global minimum and maximum; the root of the “small‑value heap” holds the largest element that is still ≤ the candidate K‑th value, while the root of the “large‑value heap” holds the smallest element that is still ≥ the candidate. This orientation keeps the partition boundary inside the heap structures, allowing each heap to be updated independently.
Second, the small‑value heap is stored using negative indexing. By treating array index 0 as the origin and extending one heap into the negative indices and the other into the positive indices, both heaps occupy a single contiguous block of memory without overlap. This trick simplifies pointer arithmetic, improves cache locality, and eliminates the need for separate allocations.
Third, the exchange phase—where elements that cross the partition boundary are swapped—mirrors Floyd’s bottom‑up heap construction but traverses the heap in post‑order (left‑right‑root). Starting from the leaves, the algorithm repeatedly compares the root of the small‑value heap with the root of the large‑value heap; if they are out of order, they are exchanged and a “sift‑down” is performed in each heap to restore heap order. The post‑order traversal guarantees that any violation introduced by a swap is repaired before higher‑level nodes are examined, ensuring convergence after a bounded number of passes.
Complexity analysis shows that the algorithm runs in O(N log N) in the worst case (when many swaps are required) and in expected O(N) time on random data, matching the average‑case performance of quickselect. Space usage is O(N) because both heaps must be stored simultaneously.
The most compelling contribution is the algorithm’s inherent parallelism. The bottom‑up heap construction for each heap can be divided among processors by assigning disjoint sub‑trees to different threads; each sub‑tree can be built independently because the sift‑down operations only affect nodes within that sub‑tree. Likewise, the exchange phase can be parallelized: the post‑order traversal can be split into independent “chunks” of the tree, and each chunk can perform its local swaps and sifts concurrently, with only occasional synchronization when a swap propagates across chunk boundaries. The authors’ experimental results on a multi‑core machine (8 cores, 16 hardware threads) demonstrate near‑linear speed‑up, achieving 2.5–3× faster execution than a highly tuned quickselect implementation that uses median‑of‑three pivot selection.
Limitations are acknowledged. The dual‑heap representation doubles the memory footprint compared with in‑place quickselect, which may be problematic for extremely large datasets. The algorithm also requires careful handling of the initial partition value; a poor initial guess can increase the number of exchange passes. The authors suggest a lightweight sampling step (e.g., selecting a small random subset and estimating the K‑th order statistic) to obtain a better starting pivot, which mitigates this issue.
In summary, the Dual‑heap Selection Algorithm blends classic heap techniques with clever data layout and traversal strategies to produce a selection method that is competitive with quickselect on a single processor and superior in parallel environments. Its design makes it especially attractive for modern workloads that run on multi‑core CPUs, GPUs, or distributed systems where balanced, low‑synchronization tasks are essential. Potential applications include large‑scale data analytics, real‑time streaming filters, and any scenario where fast order‑statistic queries are a bottleneck.
Comments & Academic Discussion
Loading comments...
Leave a Comment