Automatically Restructuring Practice Guidelines using the GEM DTD
This paper describes a system capable of semi-automatically filling an XML template from free texts in the clinical domain (practice guidelines). The XML template includes semantic information not explicitly encoded in the text (pairs of conditions a…
Authors: Am, a Bouffier (LIPN), Thierry Poibeau (LIPN)
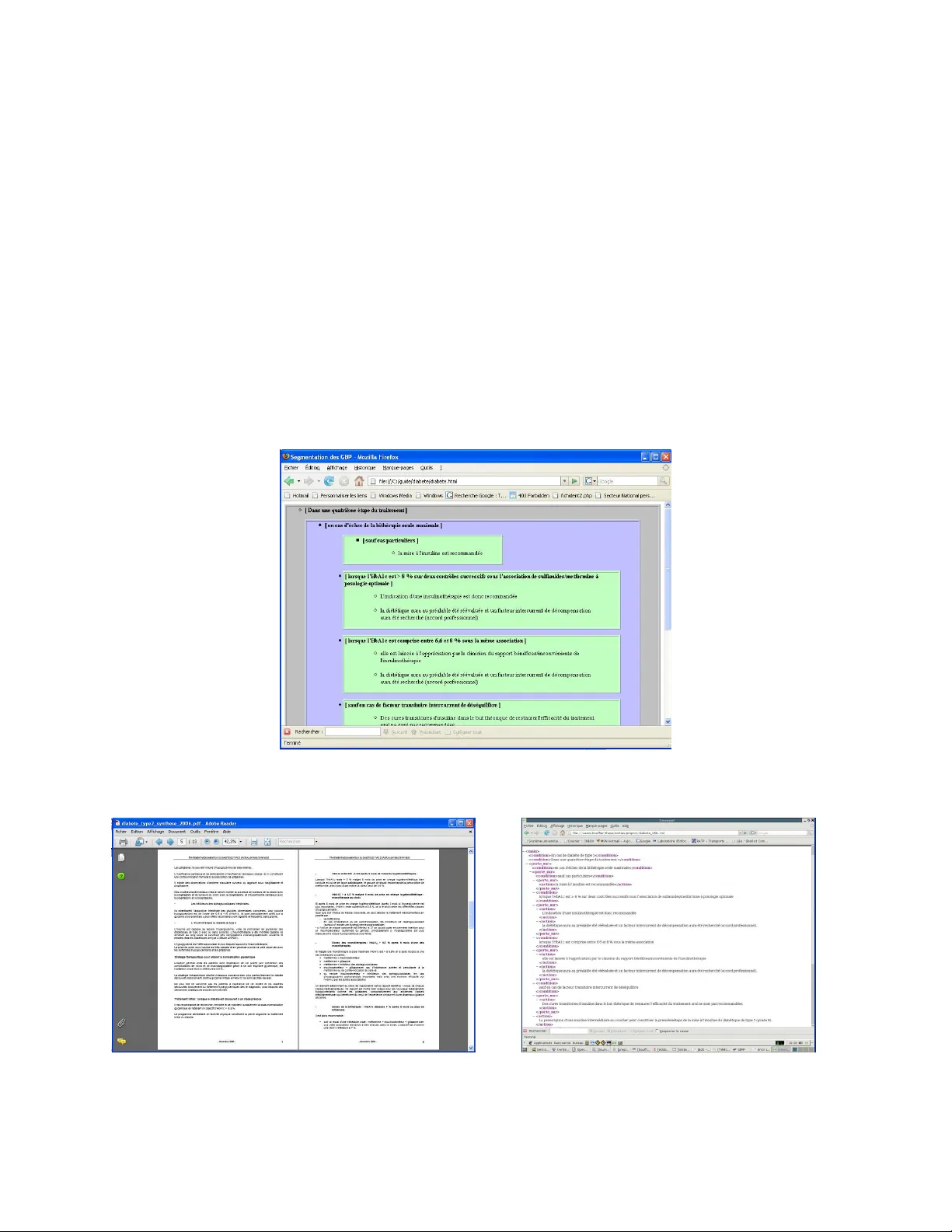
Automatically Restructuring Practice Guidelines using the GEM DTD Amanda Bouffier Thierry Poibeau Laboratoire d’Informatique de Paris-Nord Université Paris 13 and CNRS UMR 7030 99, av. J.-B. Clément – F-93430 Villetaneuse firstname .lastnam e@lipn.un iv-paris 13.fr Abstract This paper desc ribes a sys tem capable of semi-autom atically filling an XML template from free texts i n the clinical domain (prac- tice guidelines). The XML template includes semantic information not explicitly encoded in the text (pairs of conditions and ac- tions/recomm endations). Therefore, there is a need to compute the exa ct scope of condi- tions over text s equences expressing the re- quired actions. We present a system devel- oped for t his task. We show t hat it yields good performance when applied t o the analysis of French p ractice g uidelines. 1 Introduction During the past years, clinical practices have con- siderably evolv ed towards s tandardization and ef- fectiveness. A major improvement is the develop- ment of practice guidelines (Brownso n et al. , 2003). However, even if widely distributed to hos pitals, doctors and ot her medica l staff, cl inical practice guidelines are not routinel y fully exploited 1 . There is now a general tendency to transfer these guide- lines to electronic de vices (v ia an a ppropriate XML format). This transfer is justified by the assumption that electronic documents are easie r to browse than paper documents. However, m igrating a collection of texts to XML requires a lot of re-engineering. More precisely , it means ana lyzing the full set of textual documents so that they can fit with strict templates, as required either by XML schemas or DTD (document type definition). Unfortunately, most of the time, the 1 See (Kolata, 2004). This newspaper article is a good example of the huge social impact of this research area. semantic bl ocks of inform ation required by the XML m odel are not e xplicitly marked in the origi- nal text. These blocks of information correspond to discourse structures . This problem has t hus ren ewed the i nterest for the recognition and m anagem ent of discourse struc- tures, especial ly for tech nical dom ains. In thi s study, we show how technical documents belong- ing to a certain domain (nam ely, clinical pract ice guidelines) can be semi-automatically s tructured using NLP t echniques. Practice guidelines describe best practices wi th the aim of g uiding decisions and criteria in specific areas of he althcare, as defined by an authoritative examination of current evidence (evidence- based medicine , see Wikipedia or Brownson et al. , 20 03). The Guideline Elements Model (GEM) i s an XML-based guideline document model that can store and organize the heterogeneous information contained in practice guidelines (Schiffman, 2000). It is intended to facilita te translation o f natural lan- guage guideline documents into a form at that can be processed by computers. The main element of GEM, knowledge component, contains the most useful i nform ation, especially sequences of condi- tions and recomm endations. O ur aim is thus t o format t hese documents which have been written manually without any precise model, according to the GEM DTD (se e annex A). The organization of the paper is as follows: f irst, we present t he task and som e previous approaches (section 2). We then describe the diffe rent process- ing steps (section 3) and the implem entation (s ec- tion 4). We finish with the presentation of som e results (section 5), befo re the conclus ion (section 6). 2 Document Restructuring: the Case of Practice Guidelines As we have previously seen, practice guidelines are not routinely fully exploi ted. One reason is that they are not easily acc essible to doctors during consultation. Moreover, it can be difficult f or the doctor to find relevant pieces of information from these guides, even if they are not very long. To overcome these problems, national health agencies try to pr omote the electro nic distribut ion of these guidelines (so that a doctor could check recom- mendations directly from his com puter). 2.1 Previous Work Several attem pts have already been made t o im- prove the use of practice guidelines: for example knowledge- based diagnost ic aids can be de rived from them ( e.g . Sé roussi et al ., 2001). GEM is an interm ediate document model, be- tween pure text (paper practice guidelines ) and knowledge- based models like GL IF (Peleg et al. , 2000) or EON (Tu and Musen, 2001). GEM is thus an elegant solution, ind ependent from any theory or formalisms, but com pliant with othe r framework s. GEM Cutter ( http://gem.med.yale.edu/ ) i s a tool aimed at aiding experts to fill the GEM DTD from texts. However, this software is only a n inter- face allowing the end-user to p erform the task through a time- consuming cut-and-paste process. The ov erall process d escribed in Shiffman et al. (2004) is also largely m anual, even if it is an at- tempt to autom ate and r egularize the translation process. The main problem in the automation of the translation process is to identify t hat a list of rec- omm endations expressed over several sentences i s under the scope of a specific c ondition (cond itions may refer to a specific pathology, a specific kind of patients, tem poral restrictions, etc.). How ever, pre- vious approaches have been based on t he analysis of isolat ed sent ences. T hey do not com pute the ex- act scope of conditional sequences (Georg and Jaulent, 2005): t his part of the work still has to be done by hand. Our automatic a pproach relies on work done in the field of discourse processing . As we have seen in the introduction, the most important sequen ces of text to be tagged c orrespond to discourse struc- tures (conditio ns, actions …). Although most re- searchers agree that a better understanding of text structure and text coherence could help extract knowledge, descriptiv e framew orks like the one developed by Halliday and Hasan 2 are poorly for- malized and difficu lt to apply in practice. Some recent wo rks have pr oposed more opera- tional descriptions of discourse structures (Péry- Woodley, 1998). Several a uthors ( Halliday and Matthiessen, 2004; Charolles, 2005) have investi- gated t he use o f no n-lexical cues for discour se processing ( e.g temporal adverbials like “ in 1999” ). These adverbials introduce situation frames in a narrative discourse, that is to say a ‘period’ in the text which is dependen t from the adverbial. We show in this study that condition sequences play the same role in practice g uidelines: their scope m ay run over several depende nt clauses (more precisely, over a set of several r ecomm enda- tions). Our plan is to autom atically rec ognize these using surface cues a nd processing rules. 2.2 Our Approach Our aim is to semi-autom atically fill a GEM tem- plate from exis ting guidelines: the algorithm is fully automatic but the result needs to be valida ted by experts to yield adequate accuracy. Our system tries to compute the exact scope of conditional se- quences. In t his paper we apply i t to the analysis of several French prac tice guidelines. The main ai m of the approach is to go f rom a textual document to a GE M based docum ent, as shown on Figure 1 (see also annex A). We focus on conditions (including temporal r estrictions ) a nd recomm endations since these elements are of paramount importance for the task. They ar e espe- cially difficult to deal with since they r equire to accurately com pute the scope of cond itions. The example on fi gure 1 is complex since it con- tains several levels of overlapping condi tions. We observe a f irst opposition ( Chez le sujet non immu- nodéprimé / chez le sujet immunodéprimé… Con- cerning the non-immuno-d epressed patient / Con- cerning the immuno-depressed patient… ) but a sec- ond c ondition interferes i n the scope of this first level ( En c as d’aspect normal de la muqueuse ilé- ale … I f t he i leal mucus seems normal… ). The task involves recog nizing these various levels of cond i- tions in the text a nd explicitly representing them through the GEM D TD. 2 See “the text-forming component in the linguistic system” in Halliday and Hasan (1976:23). F i g u r e 1 . F r o m t h e t e x t t o G E M What is obtained in the end is a tree where t he leaves are recomm endations and the branching nodes correspond to the constraints on con ditions. 2.3 Data We ana lyzed 18 French p ractice g uidelines pub- lished by French national he alth agency ( ANAES, Agence Nati onale d’A ccréditation et d’Evaluat ion en Santé and AFSSAPS, Agence Francaise de Sé- curité Sanitaire de s Produits de San té) between 2000 and 2005. These prac tice guidelines focus on different pathologies (e.g. diabetes, high blood pressure, asthma et c.) as wel l as with clinical examination processes (e.g. digestive endoscopy ). amination processes (e.g. digestive e ndoscopy ). The data are thus homogeneous, and is about 250 pages long (150,000+ words). Most of t hese prac- tice guidelines a re publicly av ailable at: http://www.anaes.fr or http://affsaps.sante .fr . Similar docum ents have been published in English and other lang uages; t he GEM DTD is language independe nt. 3 Processing Steps Segmenting a guideline to f ill an XML tem plate is a complex process involv ing several steps. We de- scribe here in detail the most important st eps (mainly the way the scope of conditional sequences is computed), and will only give a brief overview of the pre- processing stages. 3.1 Overview A manual study of several French practice guide- lines revealed a number of trends in the data. We observed that there is a default structure in these guidelines that may hel p segm enting t he text accu- rately. T his default segmentation corresponds to a highly conventionalized writing style used i n the document (a norm ). For example, the l ocation of conditions is esp ecially im portant: if a condition occurs at t he opening of a sequence (a paragraph, a section…), its scope i s by default the entire follow- ing text sequence. I f the condition is inc luded in the sequence (inside a sentence), its default scope is restricted to the current sentence (Charolles, 2005 for similar observat ions on different text types). This default s egm entation can be revised if some linguistic cues suggest another more accurate seg- mentation ( violation of the norm ). We m ake use of Halliday’s theory of text cohesion (Hallid ay and Hasan, 1976). According to this t heory, som e “co- hesion cues” suggest extending the default segm en- tation while some ot hers suggest limiting the scope of the conditional sequ ence (see section 3.4 ). 3.2 Pre-processing (Cue Identification) The pre- processing stage concerns the analysis of relevant linguistic cues. T hese cues vary in nature : they can be based either on the m aterial structure or the content of texts. We chose to mainly focus on task-independent knowledge so that the method is portable, as far as poss ible (we took inspiration from H alliday and Matthiessen’s i ntroduction to functional gramm ar, 2004). Som e of these cues < decision.variab le> Chez le sujet non immunodép rimé en cas d'aspect macrosco pique no r- mal de la muqueus e colique des biopsies coliques nombreuses et étagées sont recommandé es (…) Les biopsies isolées son t insuffisantes(.. ) L’exploration de l’iléon termin al est égale- ment recomman dée Chez le sujet non immuno déprimé en cas d'aspect macrosco pique no r- mal de la muqueus e colique En cas d'aspect normal de la mu- queuse iléale la réalisation de biospsies n'e st pas systéma- tique Chez le sujet immunodé pri- mé il est nécessaire de réal iser des biopsie s systématiques( …) Chez le sujet non immunod éprimé , en ca s d'as- pect macroscop ique norm al de la m uqueuse co- lique , des biopsie s coliques nombreuse s et étagées sont recommandé es (…). Les biopsies is olées sont insuffisantes (…). L'exploration de l'iléon termin al est également re- commandée ( grade C). En ca s d'aspect nor mal de la muqueuse iléale (…) , la réalisation de biospsies n'est pas systémat ique (acco rd professionnel ). Chez le sujet i mmunodépri mé , il est né cessaire de réaliser des bio psies systémat iques (…) (especially connect ors and lexical cu es) can be automatically captured by machine learning meth- ods. Material struc ture cues . These features include the recognition of titles, s ection, enumerations and paragraphs. Morpho-syntactic cues. Recomm endations are not expressed in the same way as conditi ons from a morpho-sy ntactic point of view. We take the fol- lowing features in to account: − Part of speech tags . For example recommandé should be a verb and not a noun, even i f the form is ambig uous in French; − Tense and mood of the verb . Pr esent and future tenses are relevant, as well as imperative and conditional moods. Imperative and future al- ways have an injunctive value in the texts. In- junctive verbs (see lexical cues) lose their in- junctive property w hen used in a past tense. Anaphoric cues. A bas ic and local analysis of ana- phoric element s is perform ed. We espe cially fo- cused on expressions su ch as dans ce cas , dans les N cas précédents ( in this case, in the n preceding cases… ) which are very frequent in clinical docu- ments. The r ecognition of such expressions is based on a limited set of possible nouns that oc- curred in context, t ogether with specific constraints (use of dem onstrative pronouns, e tc). Conjunctive cues (discour se connectors). Condi- tions are mainly expressed through conjunctive cues. T he foll owing for ms are especially interest- ing: form s pr ototypically expressing c onditions ( si, en cas de, dans l e cas où … if, in case of …); Forms expressing the locations of some elements ( chez, en présence de... in presence of… ); Form s expressing a tem poral frame ( lorsque, au moment où, avant de… when, before …) Lexical cues. Recomm endations are mainly ex- pressed through lexical c ues. We have observed forms prototy pically expre ssing r ecomm endations ( recommander, prescrire, … recommend, pre- scribe ), obligations ( devoi r, … shall ) or options ( pouvoir, … can ). Most of these forms are highly ambiguous but can be auto matically ac quired from an ann otated corpus. Some expressions from th e medical domains c an be automatical ly extracted using a terminology extractor (we use Yatea, see section 4, “Im plementation”). 3.3 Basic Segmentation A basic segment correspo nds to a text sequence expressing ei ther a con dition or a recommendation. It is most of the time a sentence, or a proposition inside a sentence. Some of the features described in t he previous section may be highly a mbiguous. For t his reason basic s egm entation i s rare ly done according to a single f eature, but most of the t ime according to a bundle of features ac quire d from a representative corpus. For example, if a text sequence contains an injunctive verb with an infinitive form at the begin- ning of a sentence, the whole sequence is typed as action . The relevant sets of co-occurring features are autom atically der ived from a se t of annotated practice guidelines, using the chi-square test to cal- culate the dissim ilarity of distribut ions. After this step, the text i s segmented into t yped basic sequences expressing either a recommenda- tion or a condition (the rest of t he text is left untagged). 3.4 Computing Frame s and Scopes As for quant ifiers, a cond itional element m ay have a scope (a frame ) that extends over severa l basic segments. It has been show n by several authors (Halliday and Matthiessen, 2004; Charolles, 2005 ) working on different types of texts t hat condi tions detached from the sentence have most of the time a scope beyond the c urrent sentence whereas condi- tions included in a sentence (but not in the begin- ning of a sentence) have a scope which is limited to the curren t sentence. Accordingly we propose a two-step strategy : 1) the default seg mentation is done, and 2) a revision process is used to cor rect the m ain error s caused by the default s egm entation (corresponding to the no rm). Default Segmentat ion We propose a strategy which m akes use of the n o- tion of default. By default: 1. Scope of a heading goes up to the next head- ing; 2. Scope of an enum eration’s header covers all the items of the enum eration ; 3. If a conditional sequence is det ached (in the beginning of a paragraph or a sentence), its scope is the whole par agraph; 4. If the conditional seque nce is included in a sentence, its scope is equal to the current sentence. Cases 3 and 4 cover 50-80% of all the cases, de- pending on the practice guidelines used. However, this default segmentation is revised and modified when a linguistic cue is a continuation mark within the text or when the default segm entation seem s t o contradict som e cohesion cue. Revising the De fault Segmentation There are two cases which require revising t he de- fault segmentation: 1) when a cohesion mark indi - cates that the scope i s l arger than the defaul t unit; 2) when a rupture mark indicates that the scope is smaller. We only have room for two exam ples, which, we hope, giv e a broad idea o f this process. 1) Anaphoric r elations are strong cues of text coherence: they usually indicate the continuation of a frame after the end of its default bound aries. Figure 2. The last sentence int roduced by dans les deux cas is under t he scope of the conditions intro- duced by lorsque 3 . In Fi gure 2, the expr ession dans les deux cas ( in the two cases… ) is an anaphoric mark r eferring t o the two previous utterances. T he scope of the con- ditional segment i ntroduced by lorsque (that would normally be limited to the sentence it appears in) is thus extended accord ingly. 2) Other discourse cues are strong ind icators that a frame must be closed before its default boundaries. T hese cues may indicate some contras- tive, c orrective or adversativ e i nform ation ( cepen- dant, en revanche … however ). Justifications cues ( en effet, en fait … in effect ) also pertain to t his class since a justification is not part of the action element of the GEM D TD. Figure 3 is a typical example. T he linguistic cue en ef fet ( in effect ) c loses the fra me introduced by 3 In figures 2 and 3, b old and grey background are used only for sake o f clarit y; actual d ocuments are ma de of text w ithout any formatting. Figure 3. The last sentence contains a justification cue ( en effet) which li mits the scope of the condition in the preceding sentence. Chez les patients ayant initialement...(<1g /l) since this sequence should fill the explanation element of the GEM DTD and is not an action elem ent. 4 Implementation Accurate discourse processing r equires a lot of in- formation ranging from lexical cues t o complex co- occurrence of different features. We chose t o im- plement these in a classic blackboard arch itecture (Englemore and Morgan, 1988). The advantages of this architecture for our p roblem ar e easy to grasp: each linguistic phenomenon can be treated as an independent agent; i nfere nce rules can also be coded as specific a gen ts, and a facilitator controls the overall process. Basic linguistic information is co llected by a set of modules called “linguist ic experts”. Each mod- ule is specialized in a s pecific phenomenon (text structure recognition, part-of-speech tagging , ter m spotting, etc. ). The text structure and te xt format- ting elements are recog nized using Perl sc ripts. Linguistic elements are encoded in loc al gramm ars, mainly implemented as finite- state transducers (Unitex 4 ). Other linguistic featur es are o btained using public ly availa ble software pack ages, e.g. a part-of-speech tagger (Tree Tagger 5 ) and a term extractor (Yatea 6 ), etc . Eac h li nguist ex pert is en- capsulated and produces annotations that are stored in the database of facts, expressed in Prolog (we thus avoid the problem of overlapping XML tags, which are frequent a t this stage). These annotations are indexed according to the text ual clause they appear in, but linear or deri ng of the text is not cru- 4 http://www-i gm.univ-mlv .fr/~unitex / 5 http://www.i ms.uni-stut tgart.de/pr ojekte/cor plex/TreeTa gger/Decisi onTreeTagge r.html 6 http://www-l ipn.univ-pa ris13.fr/~h amon/YaTeA Chez les patients ayant initialement u ne concentr a- tion très élevée de LDL- cholestérol, et notammen t chez les patien ts à haut ri sque dont la cibl e théra- peutique est ba sse (<1g/l) , le prescripteur doit garder à l’espr it que la pre scription de s tatine à fortes doses ou en association nécess ite un e prise en c ompte au cas par cas du rapport bénéfice/risque et ne doit jamais être sys - tématique. En effet , les fortes doses de statines e t les bithérapies n ’ont pas fait l’objet à ce jour d’une é valuation suffisante dan s ces situat ions. (Prise en charge thérapeutique du patient dyslipidémique , 2005, p4) L’indication d’une insulinothéra pie est re comma n dée lorsque l’Hb A1c e st > 8%, sur deux contrôle s suc- cessifs sous l’a ssociation d e sulfami des/met formine à p osologie optimale. E lle est lais sée à l’appré ciation par le clinic ien du rapport bénéfi ces/inconvén ients de l’insulinothérap ie lorsque l’HbA1c est comprise entre 6,6% et 8% sous la mê me association. Dans les deu x cas, la diétét ique aura au pré alable été ré évaluée et un facteur intercurrent de décompensation aura é té recher- chée (accord pro fessionne l). Stratégie de pr ise en charge du patient d iabétique de type 2 à l’exclusion de la prise en charge des complications (2000) cial for f urther processing steps since t he s ystem mainly looks for co-occurrences of different cues. The resulting set of a nnotations constitutes the “working m emory” of the sy stem. Another set of experts then combine the initia l disseminated knowl edge to recogniz e basic seg- ments (section 3.3) and to com pute scopes and frames (section 3.4). T hese experts f orm the “infer- ence engine” which analyzes inform ation stored in the wo rking mem ory and adds new knowledge to the database. Even when linear order is irrelevant for the i nference pr ocess new inform ation is in- dexed with textua l clauses, t o enable the system to produce the origina l text along w ith annotation. A facilitator helps to determ ine which exper t has t he most inform ation needed to solve the prob- lem. It is the facilitator that controls, for example, the application of default rules and the revision of the defaul t seg mentation. It contro ls the chalk, me- diating among expert s competing to write on t he blackboard. Finally , an XML out put is produced for t he document, corresponding to a candidate GEM version of the document (no XML tags over- lap in the output since we produce an instance of the GEM D TD; all potential remaining conflicts must have been solved by the supervisor). T o achieve optimal accuracy t his output is v alidated and possibly m odified by dom ain experts. 5 Evaluation The study is based on a corpus of 18 practice guidelines i n French (several hundreds of frames), with the aid o f domain experts. We e valuated the approach on a subset of the corpus that has not been used for train ing. 5.1 Evaluation Criteri a In our evaluation, a sequence is considered correct if the semantics of the sequence is preserved. For example Chez l’obèse non di abétique (accord professionnel) ( I n t he case of an obese person without any diabetes (professional approval) ), recognition is correct even i f pr ofessional approval is not stricto sensu part of the condition. On the other hand, Chez l’obèse ( In the case of an obese person ) is incorrect. The same criteria are applied for recomm endations. We evaluate the scope of condition sequences by measuring whether each recom mendation is linked with the appropriate con dition sequence or not. 5.2 Manual A nnotation and Inter-annota tor Agreement The dat a is evaluat ed ag ainst practice g uidelines manually annotated by t wo annotators: a domain expert (a doctor) a nd a linguist. In order to evaluate inter-annotator agreem ent, conditions and actions are first extracted from the text. T he task of the human annotators is then to (m anually) build a tree, where each action has to be linked with a condi- tion. The output can be r epresente d as a s et of cou- ples ( condition – actions ). In the end, we calculate accuracy by comparing the outputs of the two an- notators (# of comm on couples). Inter-annotator agreement is high ( 157 nodes out of 162, i .e. above .96 agreem ent). T his degree of agreement i s encouraging. It dif fers from previous experiments, usually done using more heterogene- ous data, f or example, narrative t exts. Temporals (like “ in 1999” ) are known to open a frame but most of the tim e this frame has no clear bound ary. Practice guidelines should l ead to actions by the doctor and the scope of con ditions needs to be clear in the text. In our experiment, inter-annotator agreement is high, especially considering that we req uired an agreement between an expert and non-expert. We thus m ake the s implified assumption that the scope of conditions is expressed through linguistic c ues which do not require, most of the time, domain- specific or expert k nowledg e. Yet the very few cases where the annotations were in disagreement were clearly due to a lack of domain knowl edge by the non-expert. 5.3 Evaluation of the Automatic Recognition of Basic Sequence s The evaluation of basic segmentation gives the fol- lowing results for the condition and the recommen- dation sequences. In the table, P is precision; R is recall; P&R is t he harmoni c mean of precision and recall ( P&R = (2*P*R) / (P+R), corresponding to a F-measure with a β factor e qual to 1). Conditions: Without domain knowledge With domain knowledge P 1 1 R .83 .86 P&R .91 .92 Recommendations: Without domain knowledge With domain knowledge P 1 1 R .94 .95 P&R .97 .97 Results ar e hig h for both conditions and recom- mendations. The benefit of dom ain knowledge is not evident from overall results. Howev er, this information is useful for t he tagging of titles c orresponding to pathologies. For example, the title Hype rtension artérielle ( high arteria l blood pressure ) is equiva- lent t o a condition i ntroduced by in case of… It is thus important to recogniz e and tag it accurately, since further recomm endations are under the sc ope of this condition. This cannot be done without do- main-specific know ledge. The number of titles differs significantly from one practice guideline to another. When the num- ber is high, the impact on the performance can be strong. Also, when sev eral recom mendations are dependent on the same condi tion, the system may fail to recognize th e whole set of r ecomm endations. Finally, we observed that not all conditions and recomm endations have the same importance from a medical point of view – however, it i s difficult to quantify this in the ev aluation. 5.4 Evaluation of the Automatic Recognition of the Scope o f Conditions The scope of condi tions is r ecognized with accu- racy above .7 (we calculated this score using the same method as for inter-annotator agreement, see section 5.2). This result is encouraging, especially consider- ing the large number of param eters i nvolved in dis- course processing. In most of successful cases the scope of a condition is recogniz ed by the default rule ( default segmentation, see section 3.4). How- ever, some important cases are solved due to the detection of cohesion or boundary cue (esp ecially titles). The system fails t o r ecogniz e extended scopes (beyond the default boundary) when the cohesion marks correspond to lexical items which are related (synonyms, hyponyms or hypernym s) or t o com- plex anaphora structures (nom inal anaphora; hypo- nyms and hy pernyms c an be considered as a spe- cial case of nominal anaphora). Resolving these rarer complex cases would require “deep” domain knowledge which is diffic ult to implement using state-of- art techniques. 6 Conclusion We have presented in this paper a system capable of perform ing automatic segmentation of clinic al practice guidelines. Our aim was to automatically fill an XML DTD from textual input. The system is able to process complex discourse structures and to compute the scope of conditional segm ents span- ning several propositions or sentences. We show that inter- annotator agreement is high for this task and that the system perform s well compared to previous systems. Moreover, our system is the first one capab le of resolv ing the scope of conditions over several recomm endations. As we have seen, d iscourse processing is d iffi- cult but fundam ental for intelligent information access. We plan to apply our model to other lan- guages and other kinds of texts in the future. The task requires a t least adapting the linguistic com- ponents of our system ( mainly the pre-processing stage). More generally, the portability of discourse- based systems acro ss languag es is a challenging area for the future. References R.C. Bro wnson, E.A. B aker, T .L. Leet, K.N. Gillespie. 2003. Evidence-based public hea lth . Oxford Univer- sity Press. Oxford, UK. M. Charolles. 2 005. “Fra ming adverbials and their role in discourse cohe sion: fro m connexion to for ward labeling”. P apers of the Sy mposium on the Exploration and Mo delling of Meaning (Sem’05), Biarritz. Fr ance. R. Englemore and T . Morgan. 19 88. Bla ckboard S ys- tems . Addison-We sley, USA. G. Geo rg and M.-C. J aulent. 2 005. “An Environmen t for Document Engineerin g of Clinical Guideli nes”. P ro- ceedings o f the American Medical Info rmatics Asso- ciation . W ashington DC. USA. pp. 276–280. M.A.K. Ha llida y and R. Hasan. 1976. Coh esion in Eng- lish . Longman. Harlo w, UK. M.A.K. Hallida y and C. Matt hiessen. 20 04. Introduction to functio nal grammar (3 rd ed.). Arnold. London, UK. G. Ko lata. 200 4. “Pro gram Coaxes Hospital s to See Treatments U nder T heir No ses”. The New Yo rk Times . December 25 , 2004 . M. P eleg, A. B oxwala, O. Ogunyemi, Q. Zeng, S. T u, R. Lacson, E. Bernstam, N. Ash, P. Mork, L. Oh no- Machado, E. Shortliffe and R. Greenes. 2000. “GLIF3: The Evolutio n o f a Guideline Repr esenta- tion Fo rmat”. In Procee dings of the American Medi- cal Info rmatics Association . pp. 645–649. M-P. P éry-Woodley. 1 998. “Sign alling in written text: a corpus-based ap proach”. In M . Stede, L. W anner & E. Hovy (Eds.), Proceeding of te Coling ’98 Work- shop o n Discou rse Relations and Discourse Markers , pp. 79–85 B. Séroussi, J. Bouaud, H. Dréau., H. Falcoff., C. Riou., M. Joubert., G. Simon, A. Ve not. 2 001. “ASTI : A Guideline-based drug-ord ering system for primary care”. In Proc eedings MedI nfo . pp. 528–532 . R.N. Shiffman, B.T . Karr as, A. Agrawal, R. Chen, L. Marenco, S. Nath. 2000. “GEM: A proposal for a more comprehensi ve guidelin e document model us- ing XM L”. J ournal of th e American Medica l I nfor- matics Assoc . n°7(5 ). pp. 488–498. R.N. Shiffman, M. George, M.G. Essaihi and E. Thorn- quist. 200 4. “Bridging t he g uideline i mplementation gap: a syst ematic, document-centered approach to guideline i mplementation”. In Journa l of the A meri- can Medical In formatics Assoc . n°11(5). pp . 41 8– 426. S. Tu and M . Musen. 20 01. “Modeling data and kno wl- edge in t he EON Guideline Architecture”. In Medinfo . n°10 (1). pp. 280–2 84. Annex A. Screenshots of the system Figure A1. A practice guideline once analyz ed by the sy stem ( Trai tement méd icamenteux du diabète de type 2 , AFSSAPS- HAS, nov . 2006) Figures A2 and A3. The original t ext, an the XML G EM template ins tanciated from the text
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment