On How Developers Test Open Source Software Systems
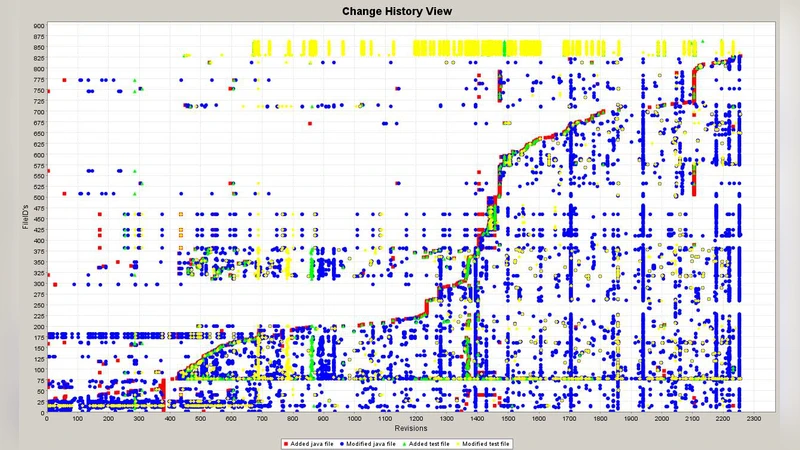
Engineering software systems is a multidisciplinary activity, whereby a number of artifacts must be created - and maintained - synchronously. In this paper we investigate whether production code and the accompanying tests co-evolve by exploring a project’s versioning system, code coverage reports and size-metrics. Three open source case studies teach us that testing activities usually start later on during the lifetime and are more “phased”, although we did not observe increasing testing activity before releases. Furthermore, we note large differences in the levels of test coverage given the proportion of test code.
💡 Research Summary
The paper investigates the co‑evolution of production code and its associated test suites in open‑source software projects by mining version‑control histories, code‑coverage reports, and size metrics. The authors selected three diverse open‑source systems—representing a web framework, a database driver, and a big‑data processing library—and extracted weekly snapshots of source‑code changes from Git repositories. Each commit was automatically classified as production or test code, allowing the authors to track the proportion of test‑code lines of code (LOC) over time. Parallel to this, they collected line, branch, and method coverage data generated by tools such as JaCoCo, producing a longitudinal view of how much of the production codebase was exercised by the existing tests.
The empirical results reveal several consistent patterns across the case studies. First, testing activity typically begins well after the initial development phase; in the earliest years, test‑code contributions are negligible, often below 5 % of total LOC. As the projects mature, the share of test code rises, but this increase is “phased”: periods of relatively intense test‑code addition last three to six months, followed by longer intervals of slower growth. Notably, the authors did not observe a systematic surge in test‑code commits immediately before major releases, suggesting that developers prioritize feature implementation over testing in release‑critical windows.
Second, the relationship between the proportion of test code and actual coverage is far from linear. One project with a modest 12 % test‑code share achieved only 45 % line coverage, while another with a higher 30 % test‑code share reached 72 % coverage. Conversely, a project with a relatively low 15 % test‑code proportion attained 68 % coverage, indicating that the quality and focus of tests (e.g., inclusion of edge‑case and exception handling) matter more than sheer quantity. Statistical analysis (Pearson correlation and linear regression) confirms a weak positive correlation, reinforcing the notion that test‑code density alone is insufficient to guarantee thorough testing.
Third, the study highlights cultural and process implications. The absence of a pre‑release testing spike aligns with a development culture that treats testing as a background activity rather than a gatekeeper for release readiness. This observation challenges the assumptions of Test‑Driven Development (TDD) and continuous testing pipelines, suggesting that teams may need to enforce stricter testing milestones or integrate coverage thresholds into their CI/CD workflows to achieve higher reliability.
The authors acknowledge limitations: the sample size of three projects restricts the generalizability of findings, and coverage metrics do not directly capture fault detection effectiveness. Future work is proposed to expand the dataset across multiple programming languages, incorporate defect‑report data, and evaluate the impact of test‑failure rates on overall software quality.
In conclusion, the paper provides a nuanced view of how test suites evolve alongside production code in real‑world open‑source ecosystems. It demonstrates that while test‑code volume tends to increase over a project’s lifespan, the timing, intensity, and effectiveness of testing are highly project‑specific. The authors recommend that open‑source communities develop tailored testing guidelines, adopt automated coverage monitoring as a mandatory gate in release pipelines, and focus on improving test design to bridge the gap between test‑code quantity and actual code exercised. By doing so, they can foster more robust, maintainable, and trustworthy software systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment