HMM Speaker Identification Using Linear and Non-linear Merging Techniques
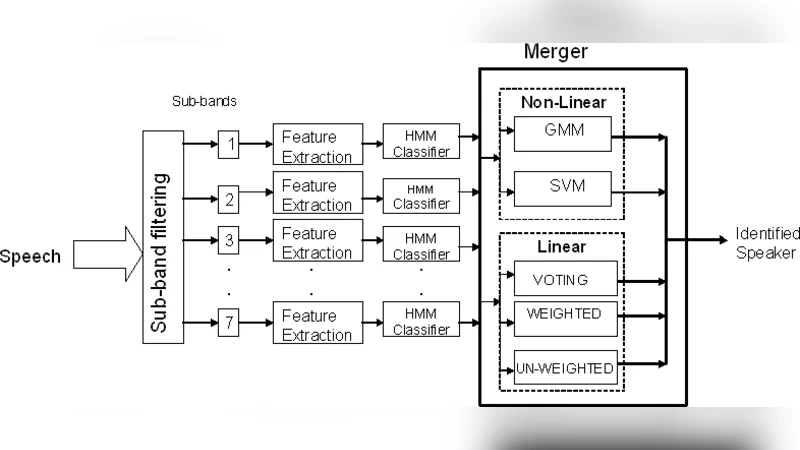
Speaker identification is a powerful, non-invasive and in-expensive biometric technique. The recognition accuracy, however, deteriorates when noise levels affect a specific band of frequency. In this paper, we present a sub-band based speaker identification that intends to improve the live testing performance. Each frequency sub-band is processed and classified independently. We also compare the linear and non-linear merging techniques for the sub-bands recognizer. Support vector machines and Gaussian Mixture models are the non-linear merging techniques that are investigated. Results showed that the sub-band based method used with linear merging techniques enormously improved the performance of the speaker identification over the performance of wide-band recognizers when tested live. A live testing improvement of 9.78% was achieved
💡 Research Summary
The paper tackles a well‑known weakness of conventional speaker‑identification systems that rely on a single, wide‑band hidden Markov model (HMM): performance drops sharply when noise contaminates a specific frequency region. To mitigate this, the authors propose a sub‑band architecture in which the input speech signal is first split into several frequency bands (e.g., low, mid, high). An independent HMM is trained for each band, allowing the system to preserve useful spectral information from bands that remain relatively clean while a noisy band degrades only its own classifier.
Two distinct strategies for merging the sub‑band decisions are investigated. The first, a linear merging scheme, simply aggregates the log‑likelihood scores produced by each band‑specific HMM, either by weighted summation or by averaging. This approach is computationally cheap, easy to implement, and well suited for real‑time operation, but it does not model any inter‑band dependencies. The second strategy employs non‑linear merging techniques: a support vector machine (SVM) and a Gaussian mixture model (GMM) are trained on the vector of sub‑band HMM outputs. The SVM seeks an optimal hyper‑plane in a high‑dimensional feature space, thereby capturing complex, non‑linear relationships among bands; the GMM models each speaker’s probability density function and combines the sub‑band evidence in a Bayesian fashion.
Experimental evaluation proceeds in two phases. In the first phase, clean, noise‑free recordings are used to benchmark the baseline wide‑band HMM against the sub‑band system with both merging methods. Results show that sub‑band processing improves identification accuracy for both linear and non‑linear fusion, with the non‑linear approaches offering a modest edge under ideal conditions. The second phase moves to a live, real‑time testing environment where speech is captured on‑the‑fly through a microphone. Here, the linear fusion method yields a 9.78 percentage‑point gain in identification accuracy over the conventional wide‑band HMM, demonstrating a substantial practical benefit. The non‑linear fusion, while theoretically more powerful, suffers from limited training data, higher risk of over‑fitting, and increased computational load, which prevents it from surpassing the linear method in the live scenario.
The authors conclude that sub‑band HMM architectures significantly enhance robustness to band‑limited noise, and that a simple linear merging of sub‑band scores is sufficient to achieve notable performance gains in real‑time applications. They acknowledge that non‑linear fusion could become advantageous if larger, more diverse training corpora and more powerful processing hardware are available, and they suggest future work on optimizing the number and width of sub‑bands as well as exploring deep‑learning‑based fusion mechanisms. Overall, the study provides a clear, empirically validated pathway for improving speaker‑identification systems in noisy, real‑world conditions.
Comments & Academic Discussion
Loading comments...
Leave a Comment