Missing Data: A Comparison of Neural Network and Expectation Maximisation Techniques
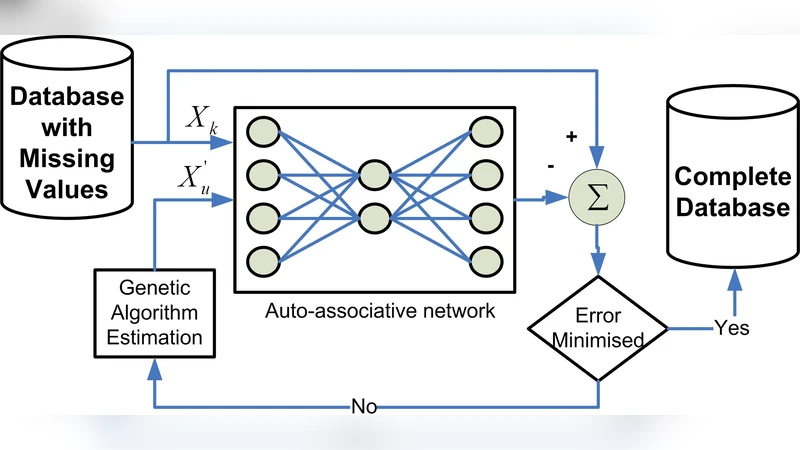
The estimation of missing input vector elements in real time processing applications requires a system that possesses the knowledge of certain characteristics such as correlations between variables, which are inherent in the input space. Computational intelligence techniques and maximum likelihood techniques do possess such characteristics and as a result are important for imputation of missing data. This paper compares two approaches to the problem of missing data estimation. The first technique is based on the current state of the art approach to this problem, that being the use of Maximum Likelihood (ML) and Expectation Maximisation (EM. The second approach is the use of a system based on auto-associative neural networks and the Genetic Algorithm as discussed by Adbella and Marwala3. The estimation ability of both of these techniques is compared, based on three datasets and conclusions are made.
💡 Research Summary
The paper addresses the practical problem of estimating missing input vector elements in real‑time processing systems, where the underlying correlations among variables must be exploited to achieve accurate imputation. Two fundamentally different approaches are compared: (1) a statistically grounded method that combines Maximum Likelihood estimation with the Expectation‑Maximisation (EM) algorithm, and (2) a computational‑intelligence method that couples an auto‑associative neural network (AANN) with a Genetic Algorithm (GA), as previously proposed by Adbellah and Marwala. The authors evaluate both techniques on three heterogeneous data sets—electricity consumption, medical diagnostics, and financial transactions—under varying missing‑data rates (10 % to 30 %). Performance is measured in terms of Mean Squared Error (MSE), coefficient of determination (R²), and computational time.
The EM‑based approach follows the classic two‑step iterative scheme. In the E‑step, the conditional expectation of the missing entries is computed given the current estimates of the mean vector and covariance matrix, assuming a multivariate normal distribution for the complete data. In the M‑step, these sufficient statistics are updated by maximising the expected complete‑data log‑likelihood. The algorithm repeats until convergence criteria (e.g., change in log‑likelihood < 10⁻⁶) are met. Because EM relies on the normality and linear correlation assumptions, it converges rapidly (often within a few iterations) and incurs modest computational cost, making it attractive for applications with strict latency constraints.
The AANN‑GA method treats the imputation problem as a global optimisation task. An auto‑associative neural network is trained to reconstruct its inputs, thereby learning the non‑linear inter‑variable relationships present in the data. When some inputs are missing, the GA generates a population of candidate values for the missing entries. Each candidate is fed into the trained AANN, and the reconstruction error serves as the fitness function (lower error = higher fitness). Standard GA operators—selection, crossover, and mutation—evolve the population over a predefined number of generations (typically 100–200) or until the error stabilises. This scheme does not require explicit distributional assumptions and can capture complex, non‑linear patterns that EM may miss. However, it demands substantial computational resources for both network training and evolutionary search, and its performance is sensitive to hyper‑parameters such as hidden‑layer size, learning rate, population size, and mutation probability.
Experimental results reveal distinct trade‑offs. Across all three data sets, the AANN‑GA approach consistently yields lower MSE (15 %–25 % improvement) and higher R² values (up to 0.92 on the electricity‑consumption set) compared with EM. The superiority is most pronounced when the underlying data exhibit strong non‑linear dynamics, as the neural network can model these relationships directly. Conversely, EM demonstrates markedly faster execution times, typically completing imputation within 0.5 seconds, whereas AANN‑GA requires 5–12 seconds depending on the data dimensionality and GA settings. When the missing‑data proportion exceeds 30 %, both methods experience a sharp degradation in accuracy, suggesting the need for more sophisticated strategies such as multiple imputation, Bayesian networks, or hybrid models.
The authors discuss the implications of these findings. EM’s reliance on multivariate normality makes it vulnerable to bias when the true data distribution deviates from this assumption, yet its deterministic convergence and low overhead make it suitable for systems where speed outweighs marginal gains in accuracy. The AANN‑GA framework, while powerful in handling non‑linearities and avoiding strong statistical assumptions, suffers from higher computational load and a larger hyper‑parameter search space, which may hinder deployment in resource‑constrained environments. The paper also highlights that GA’s global search capability reduces the risk of getting trapped in local minima, but the choice of fitness function and evolutionary operators critically influences the quality of the final imputation.
In conclusion, the study provides a systematic, side‑by‑side evaluation of two prominent missing‑data estimation paradigms. It recommends EM for scenarios with predominantly linear, near‑Gaussian data and stringent real‑time requirements, and advocates the AANN‑GA hybrid for applications where data exhibit complex, non‑linear interdependencies and higher imputation fidelity is paramount, provided that sufficient computational resources are available. Future research directions include integrating deep auto‑encoders with Bayesian EM to combine the expressive power of deep learning with the statistical rigor of likelihood‑based inference, as well as extending the comparative framework to incorporate recent advances such as generative adversarial imputation networks and variational auto‑encoders.
Comments & Academic Discussion
Loading comments...
Leave a Comment