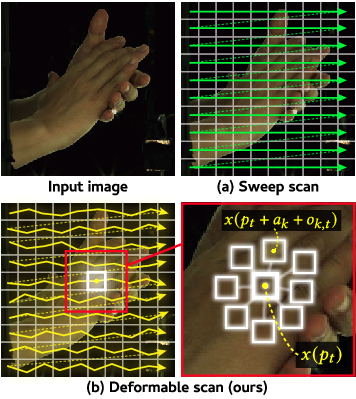
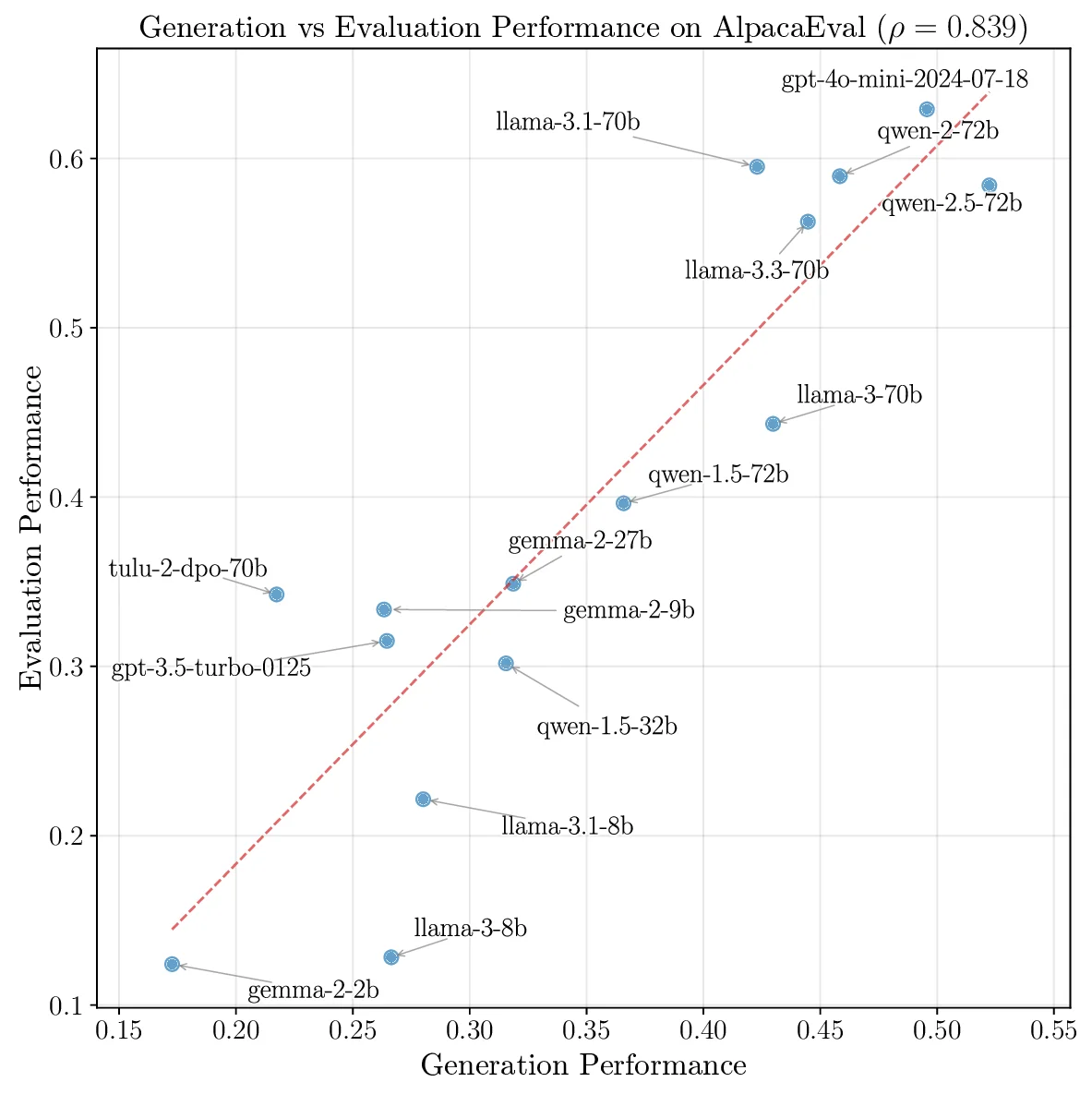
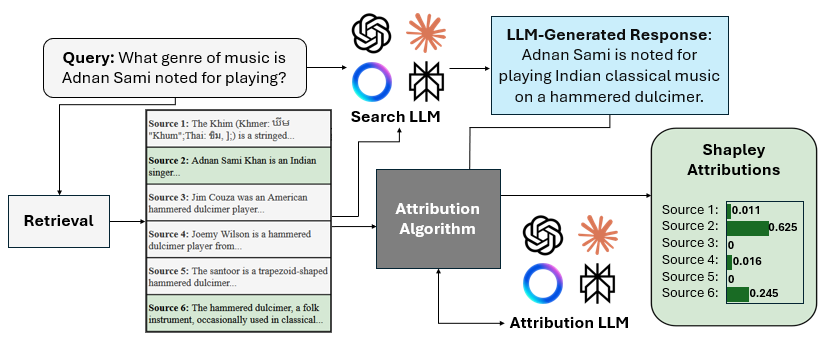
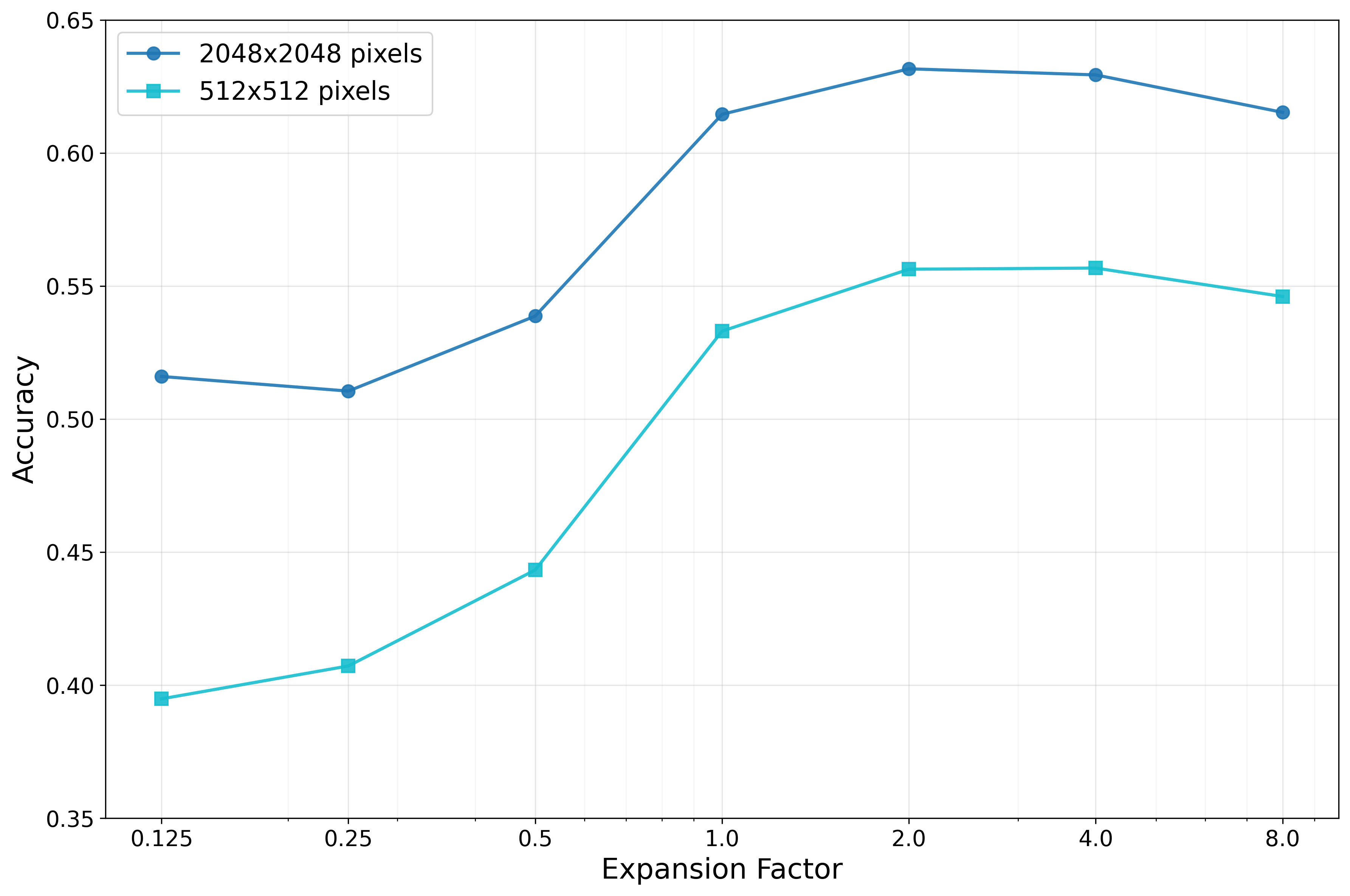
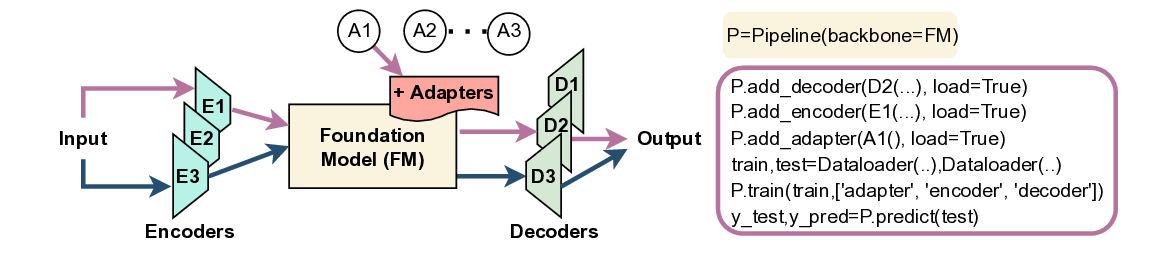
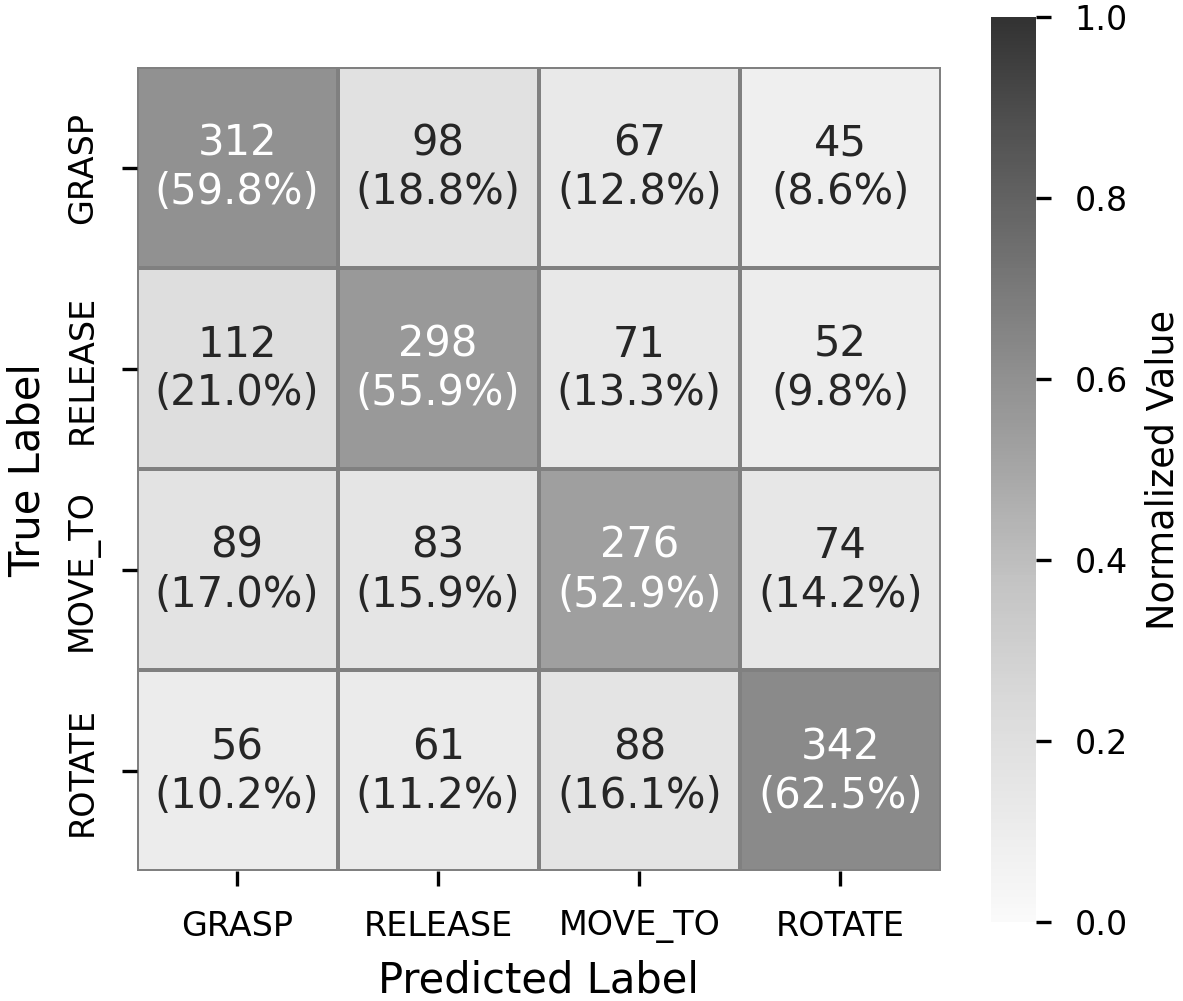
목재 단면 중심부 자동 검출 딥러닝 모델 비교 연구
Pith detection in tree cross-sections is essential for forestry and wood quality analysis but remains a manual, error-prone task. This study evaluates deep learning models-YOLOv9, U-Net, Swin Transformer, DeepLabV3, and Mask R-CNN-to automate the pro