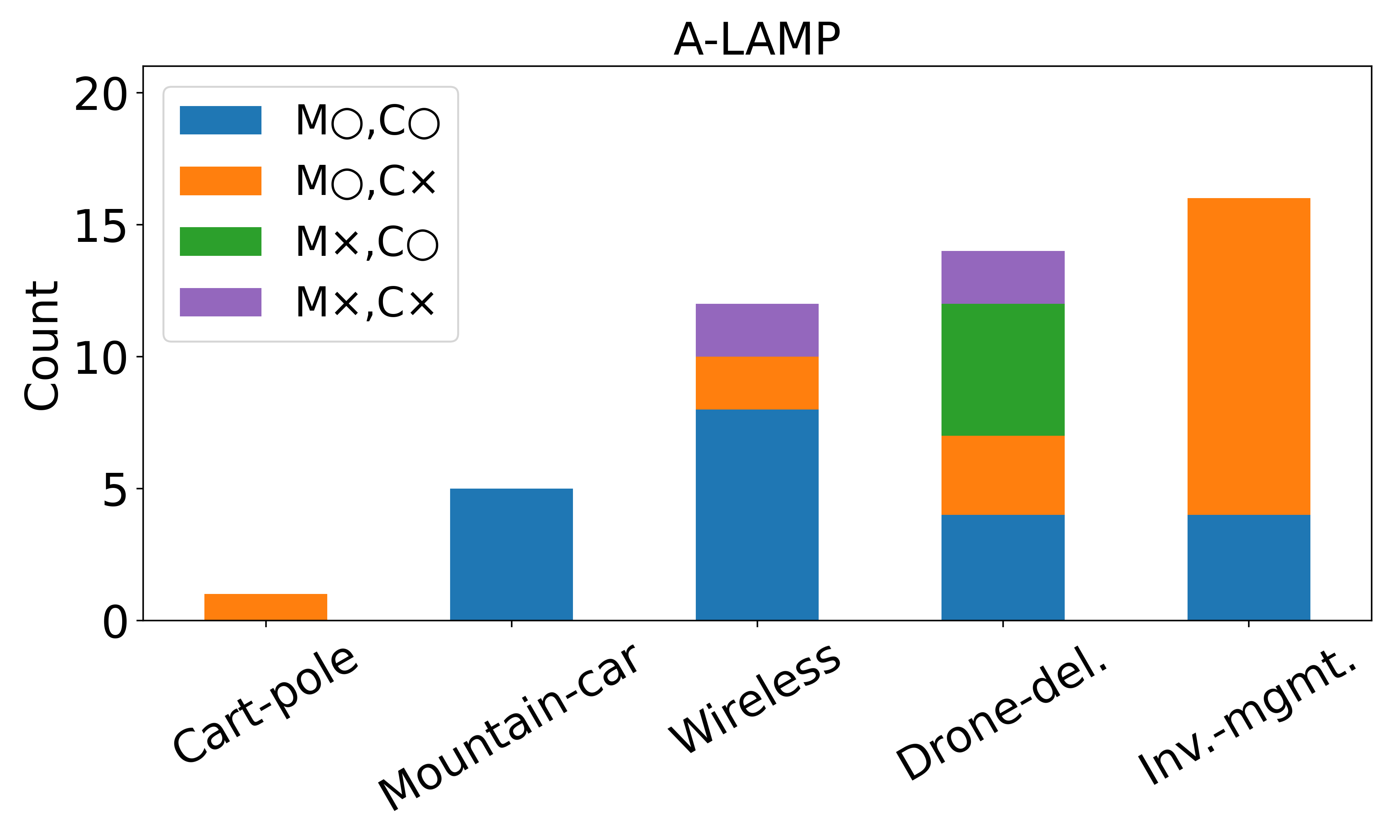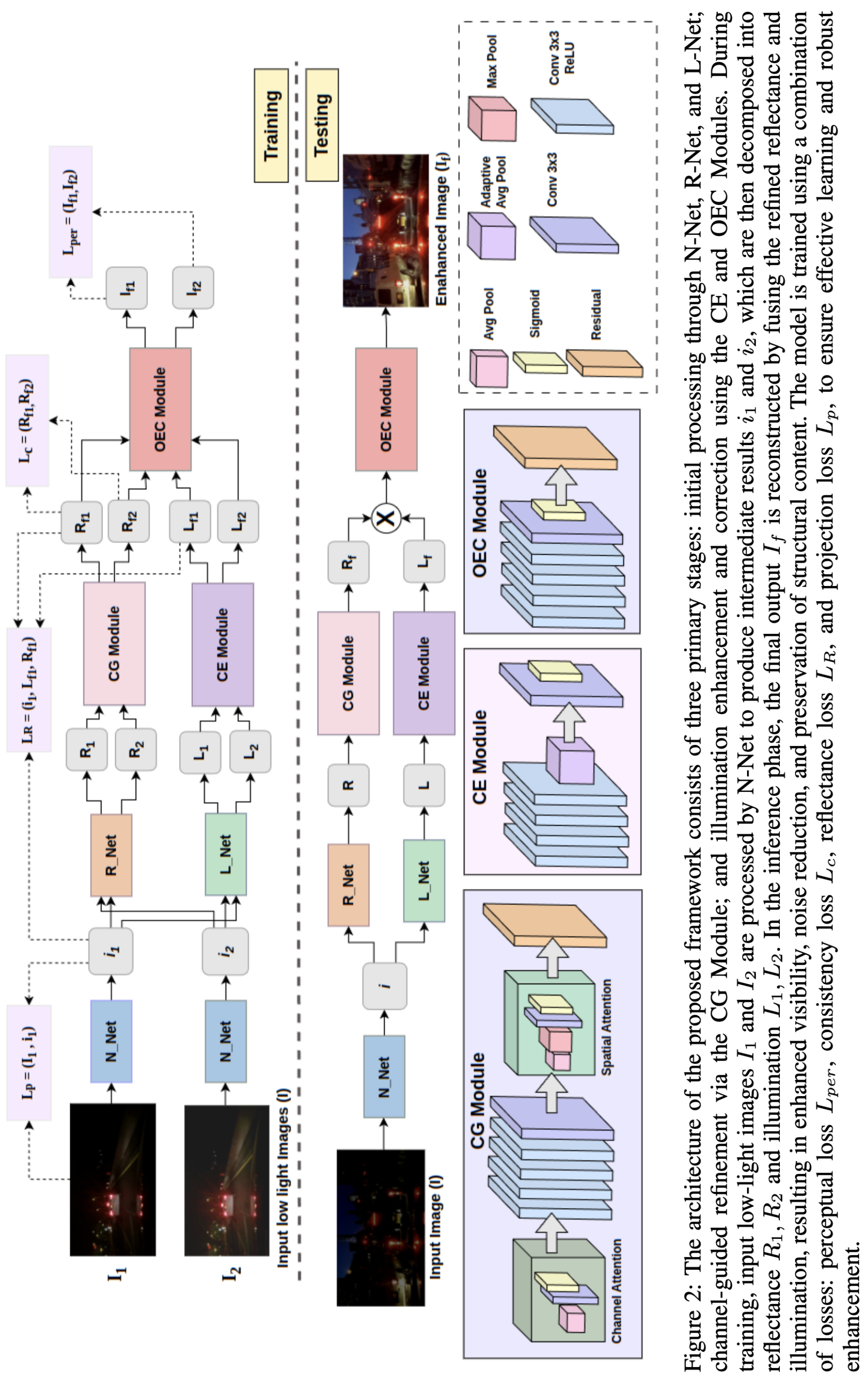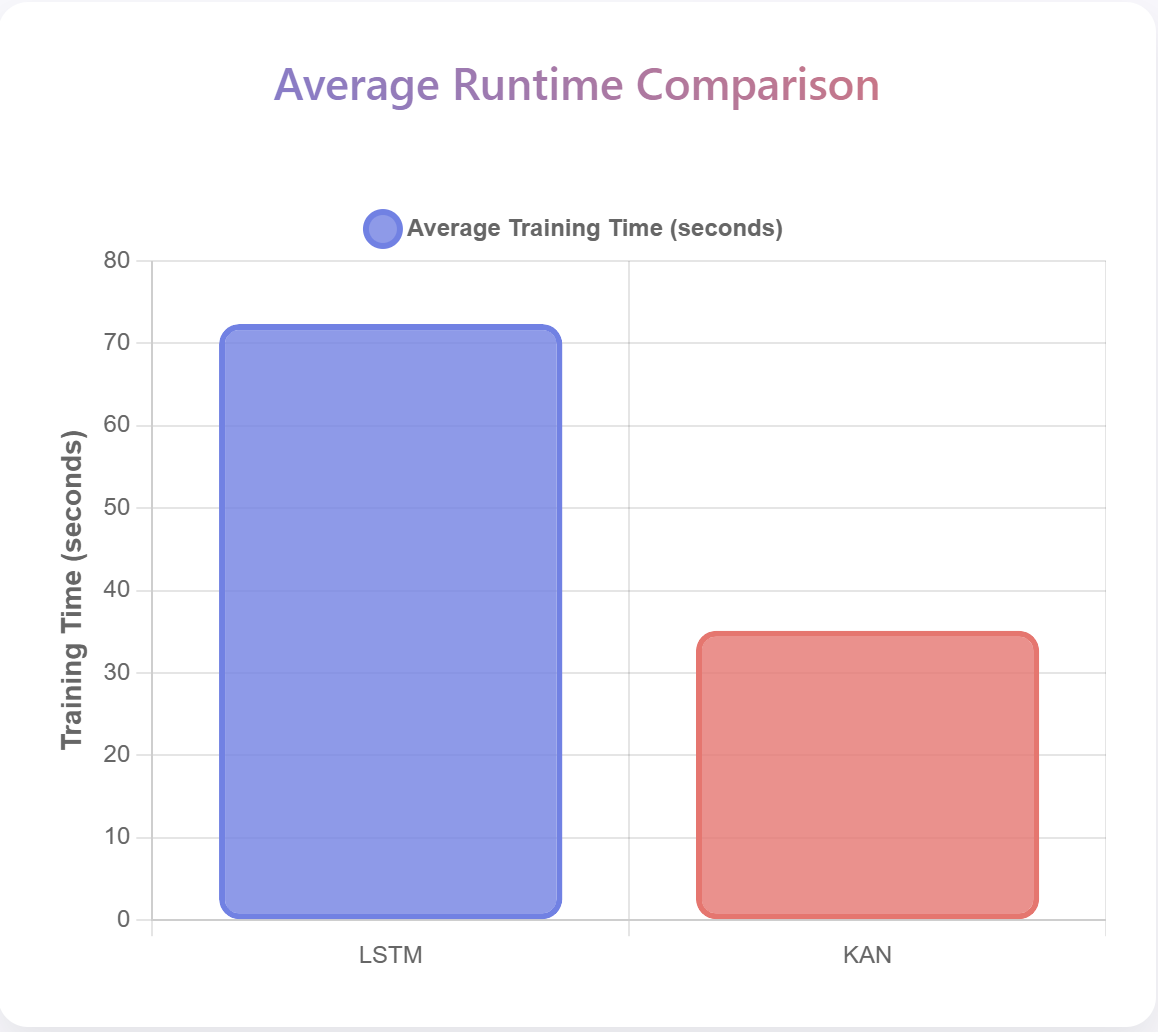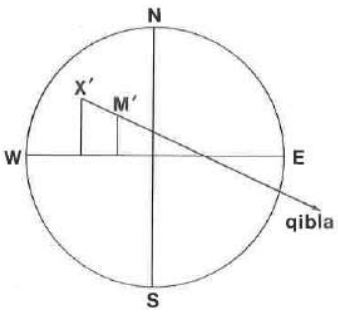
이더리움 거래 경제적 의도 파악을 위한 TxSum 데이터셋과 MATEX 멀티에이전트 시스템
Understanding the economic intent of Ethereum transactions is critical for user safety, yet current tools expose only raw on-chain data, leading to widespread 'blind signing' (approving transactions without understanding them). Through interviews with 16 Web3 users, we find that effective explanatio