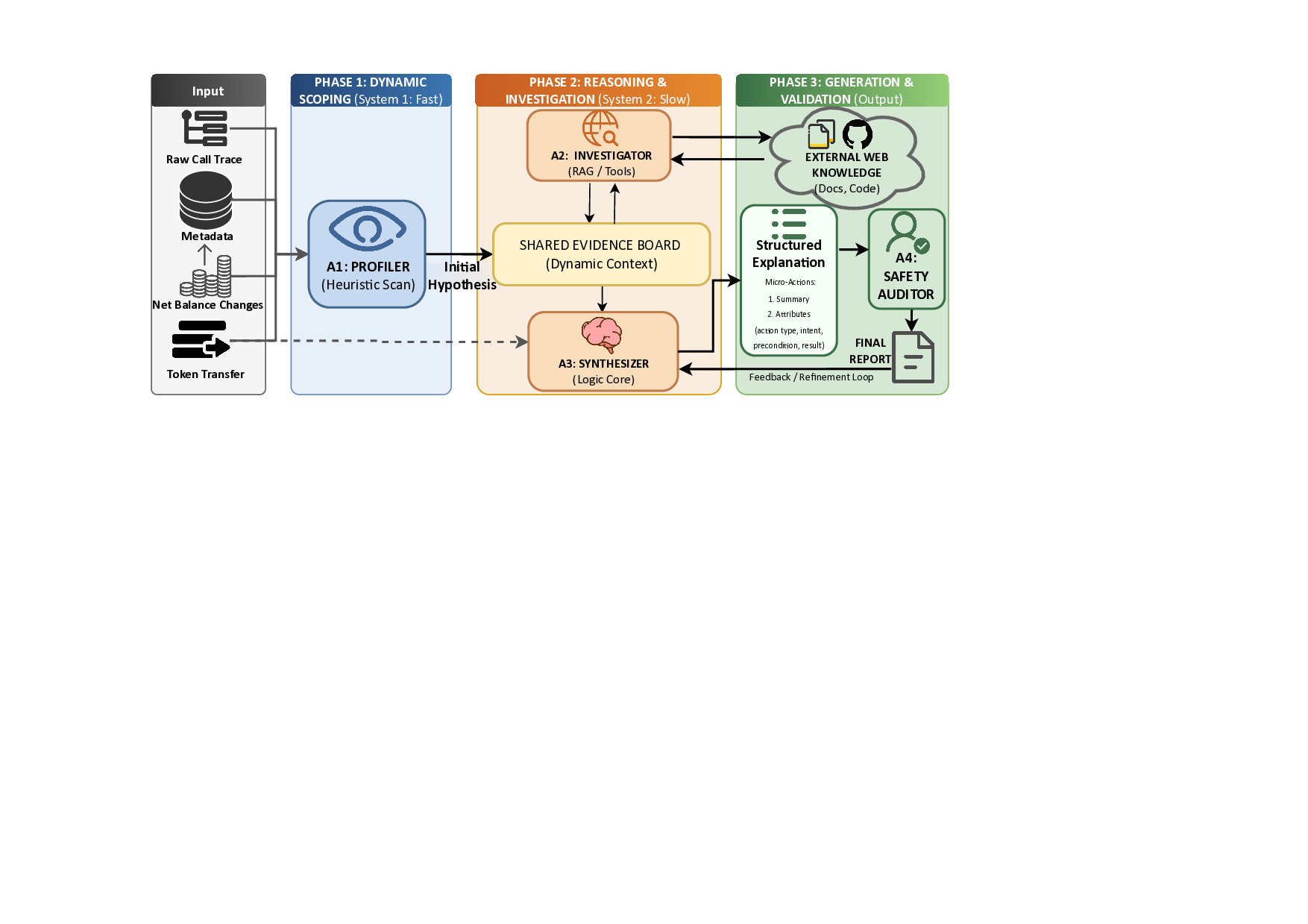
두 단계 자기지도 학습으로 구현한 고효율 음성 표현 및 압축 프레임워크
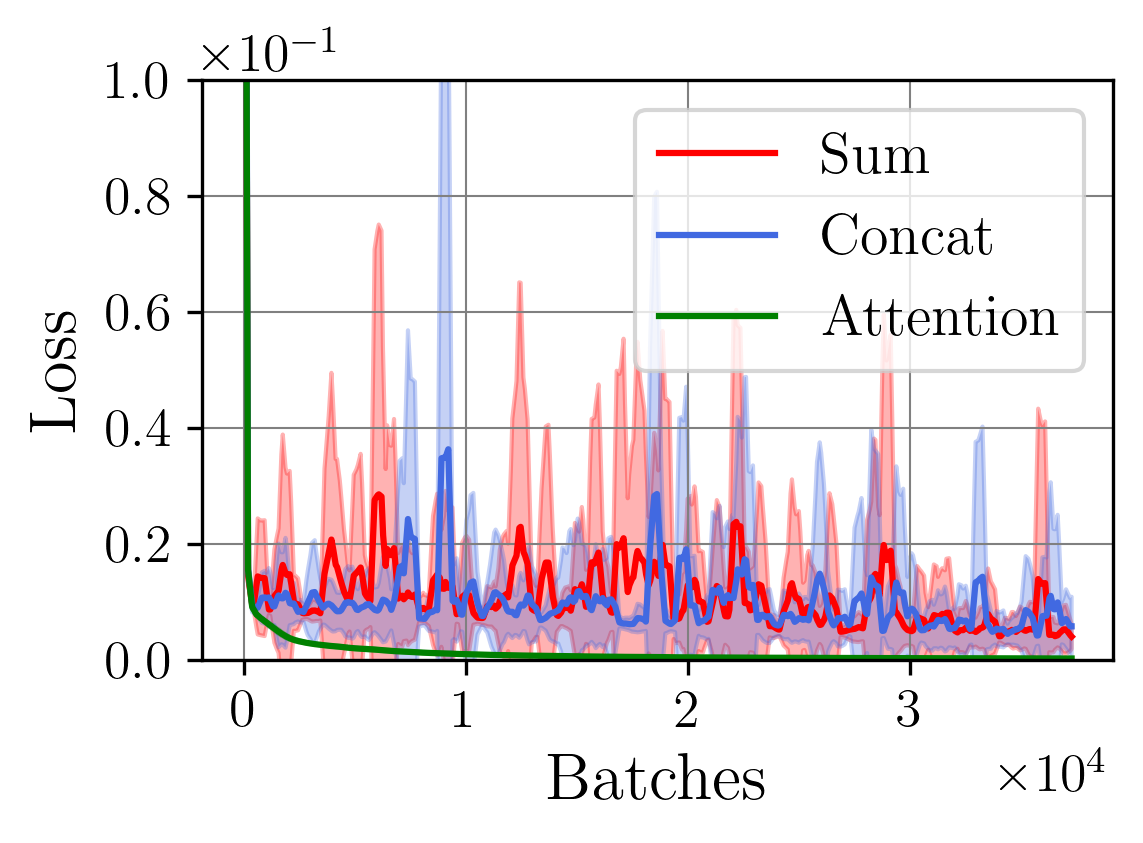
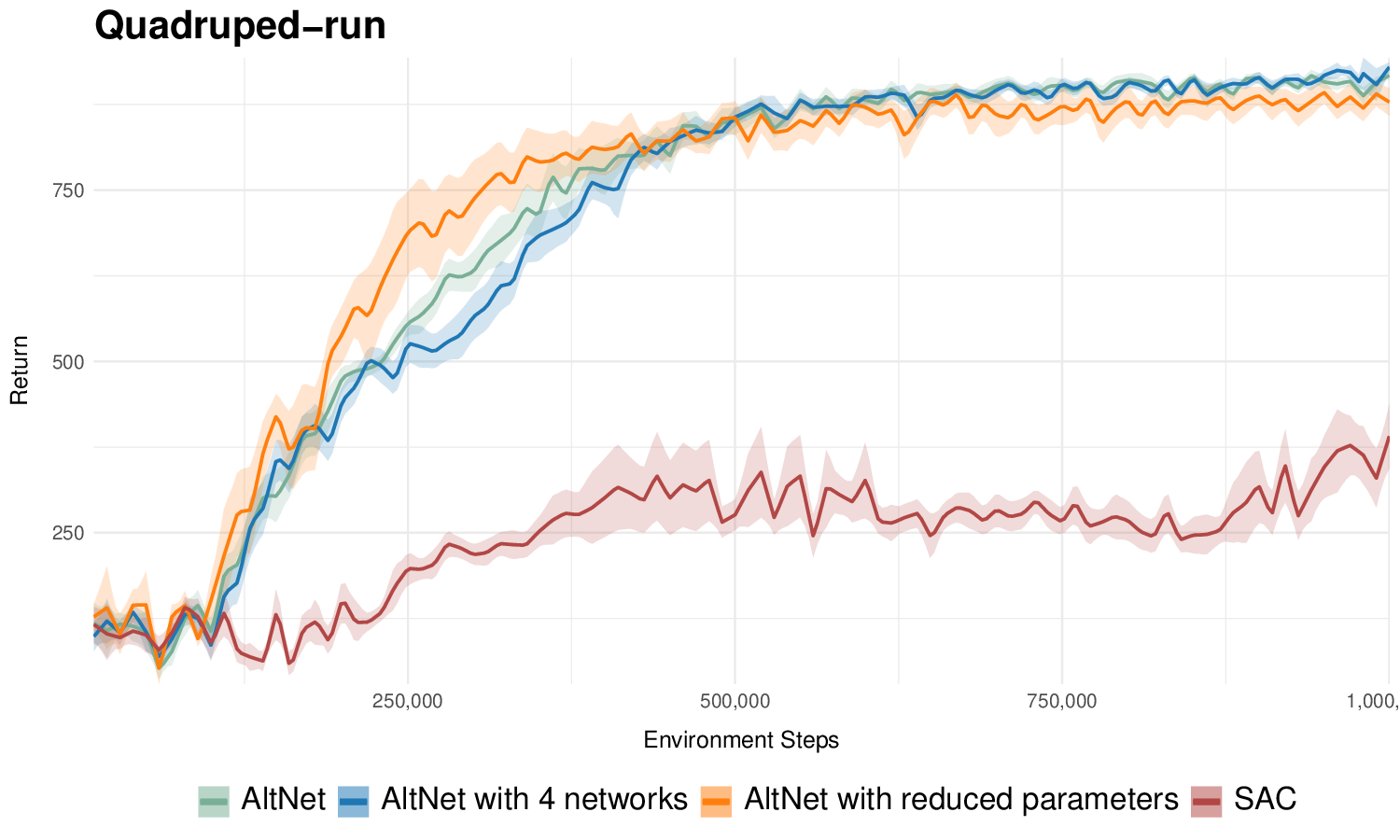
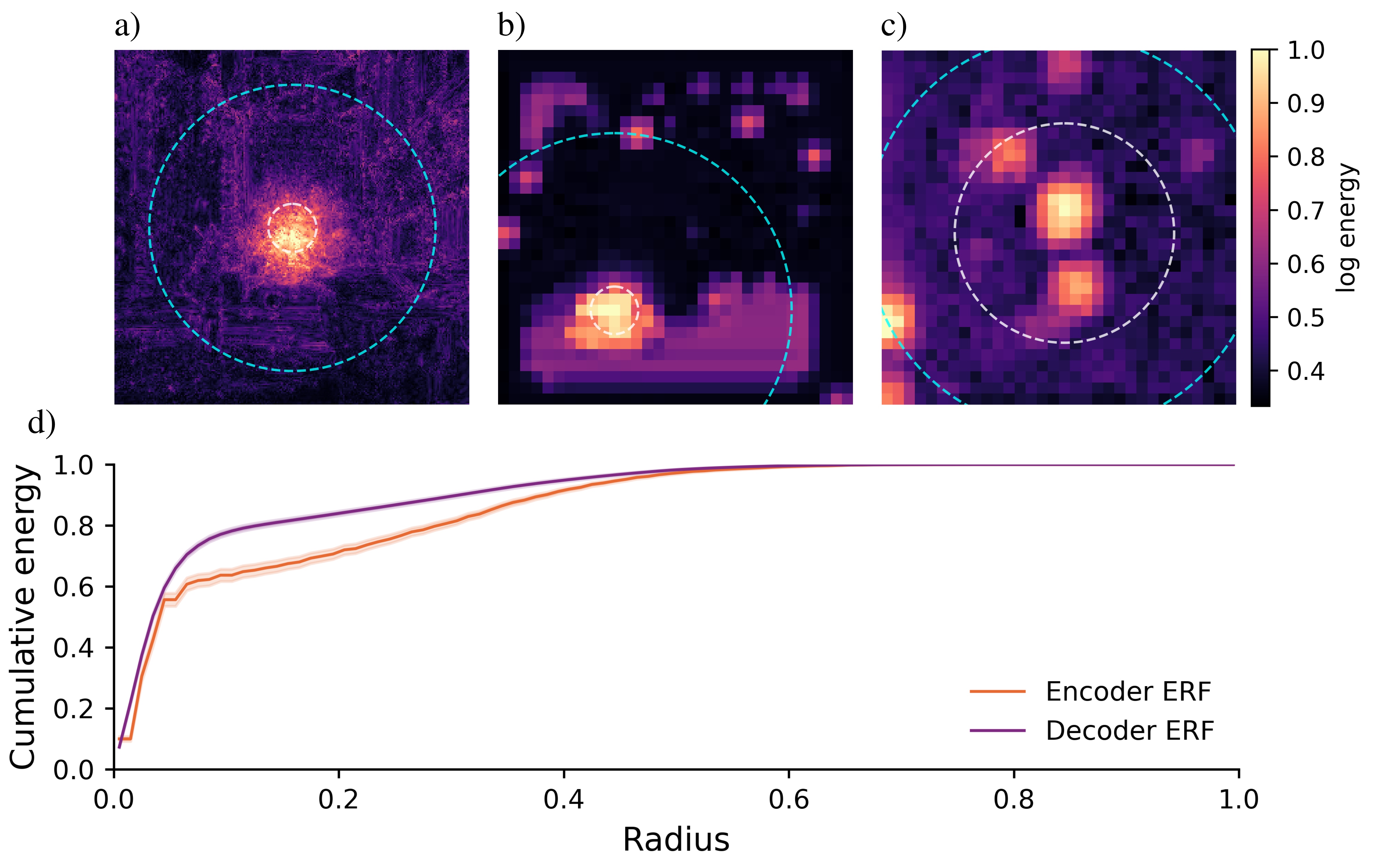
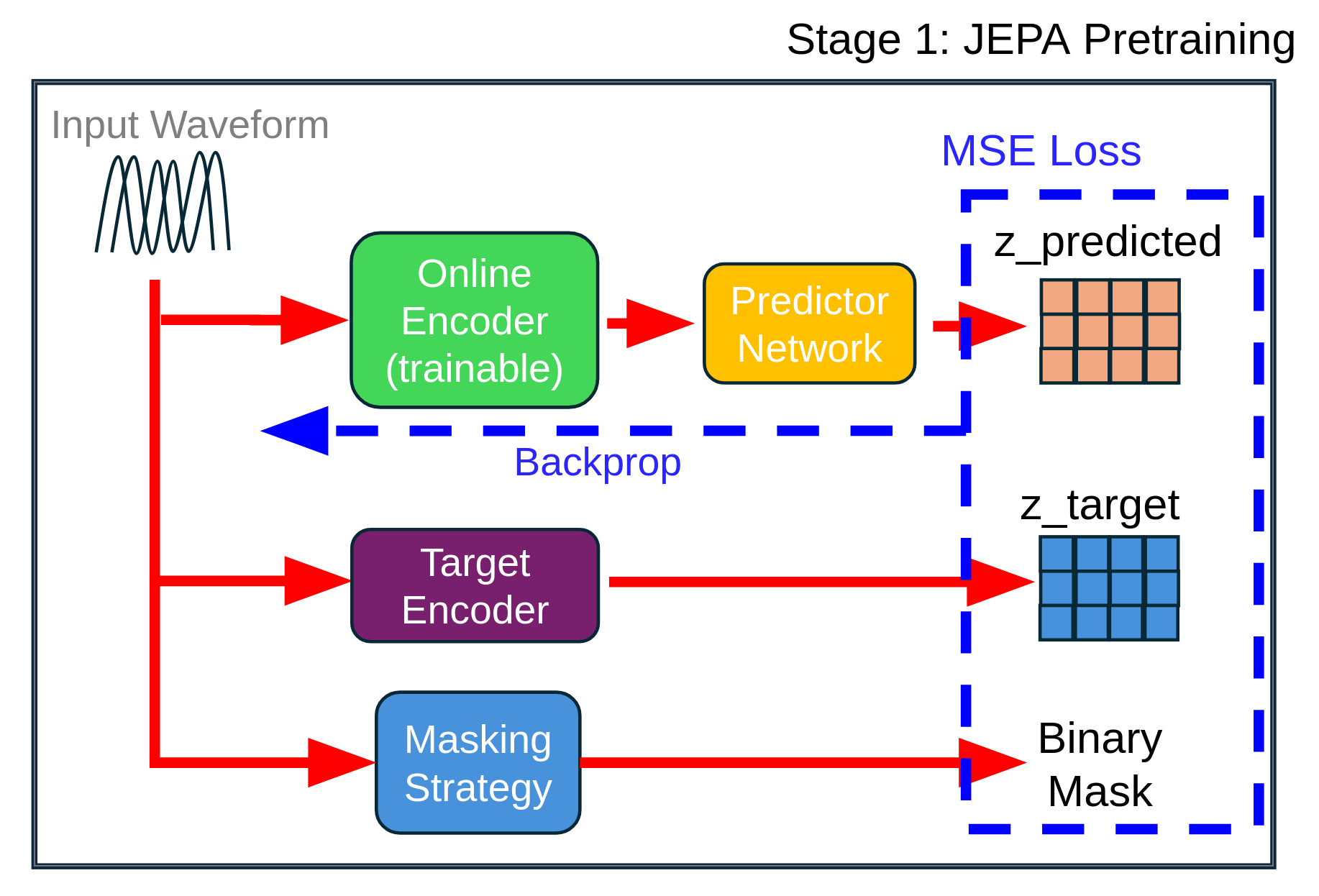
We introduce a two-stage self-supervised framework that combines the Joint-Embedding Predictive Architecture (JEPA) with a Density Adaptive Attention Mechanism (DAAM) for learning robust speech representations. Stage 1 uses JEPA with DAAM to learn semantic audio features via masked prediction in lat