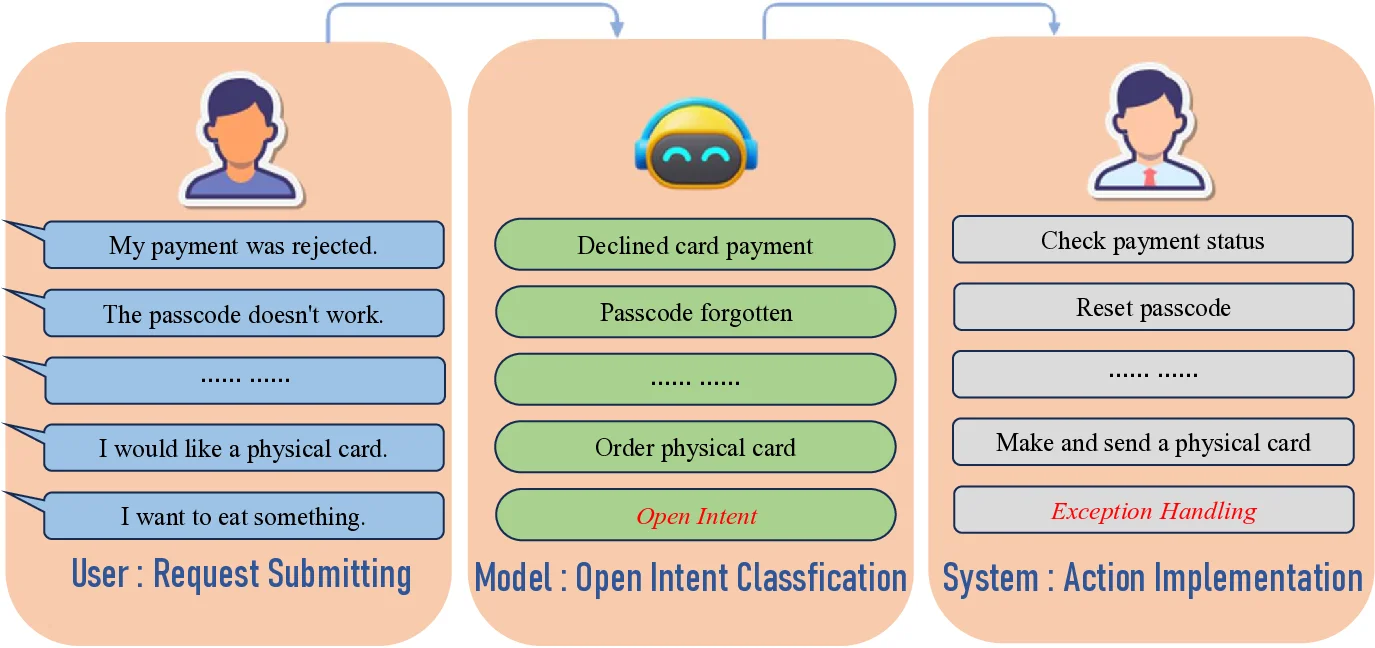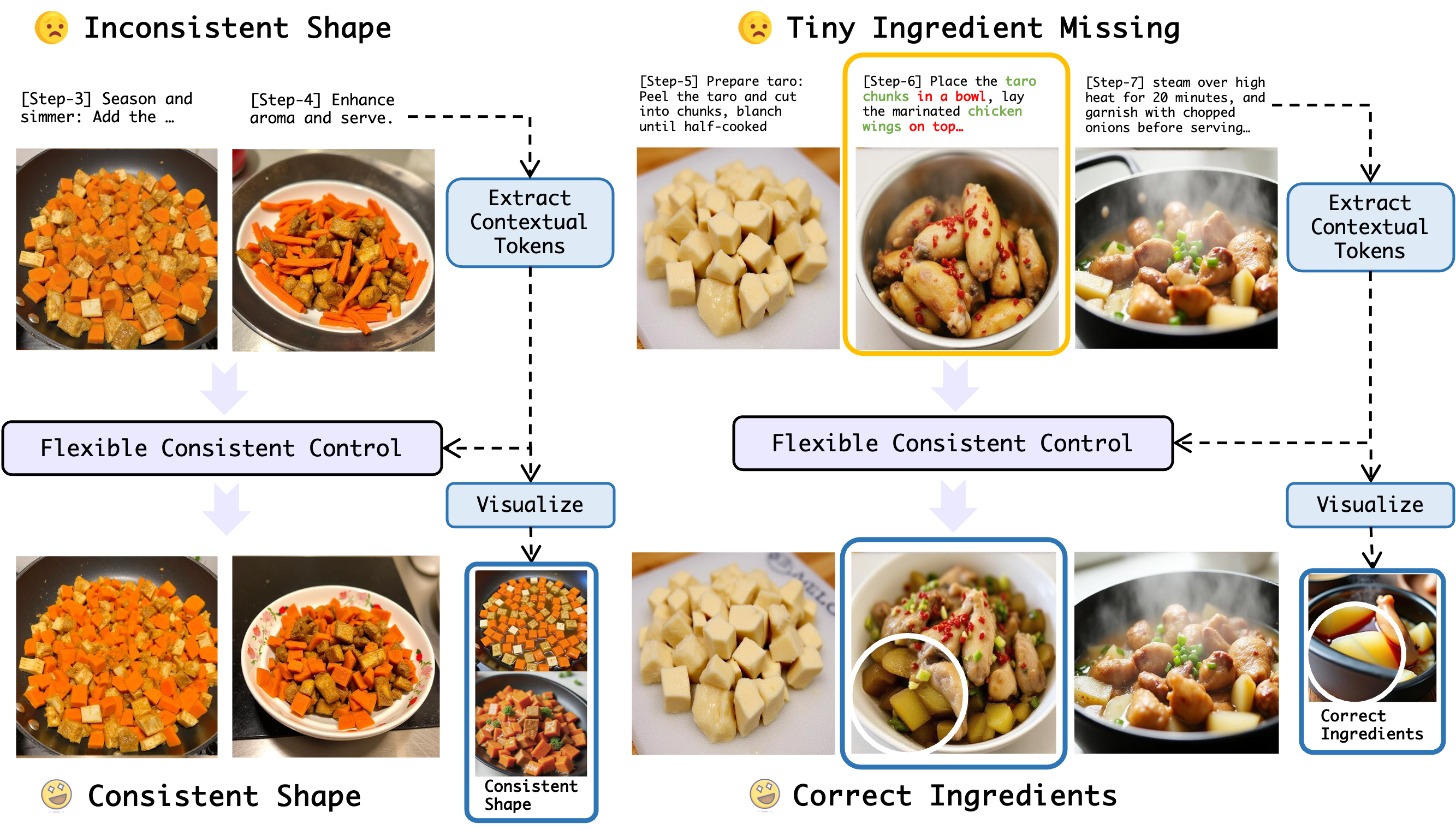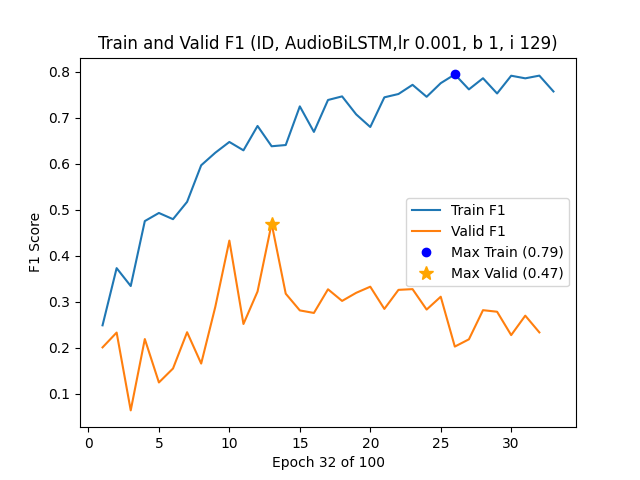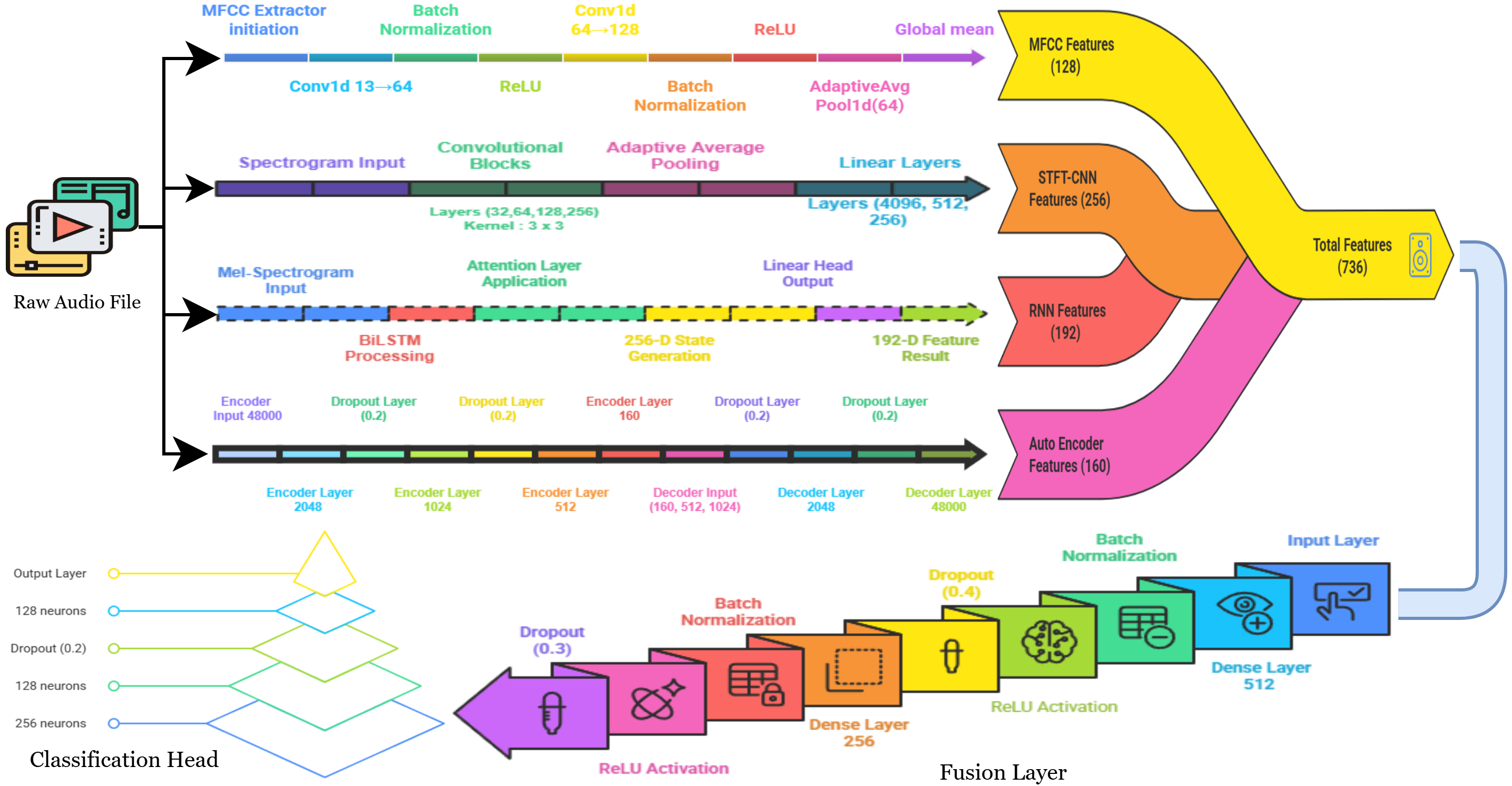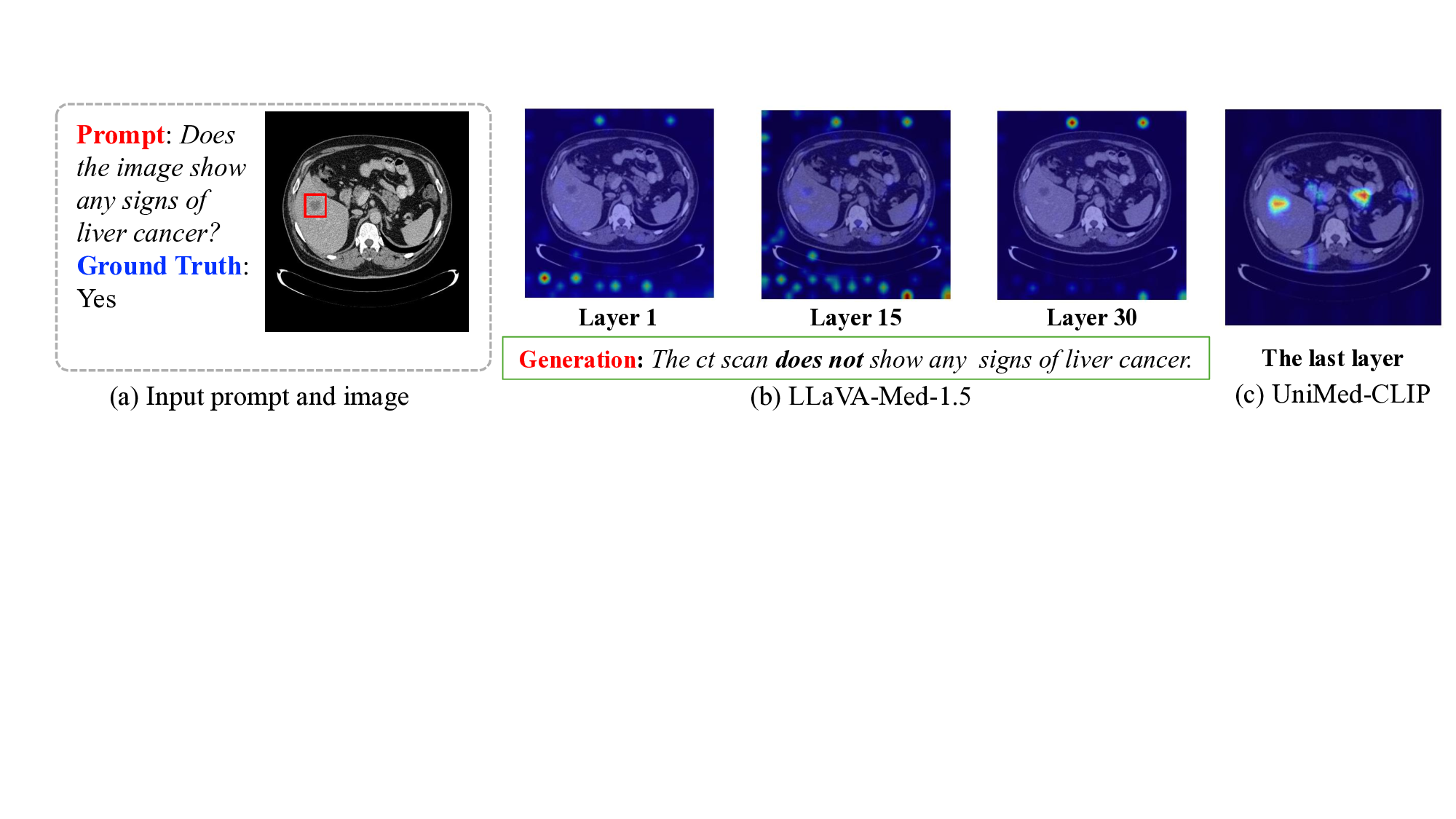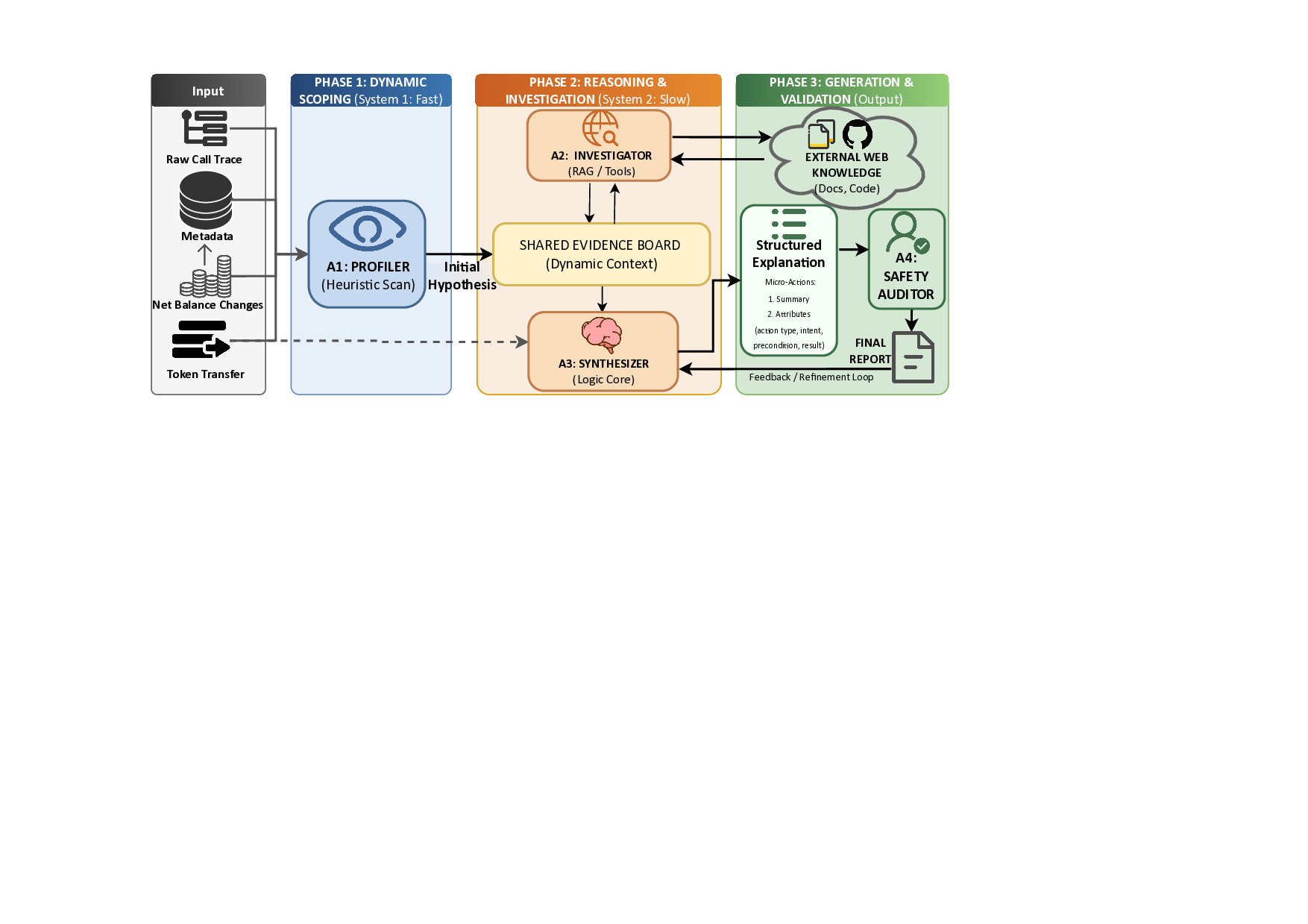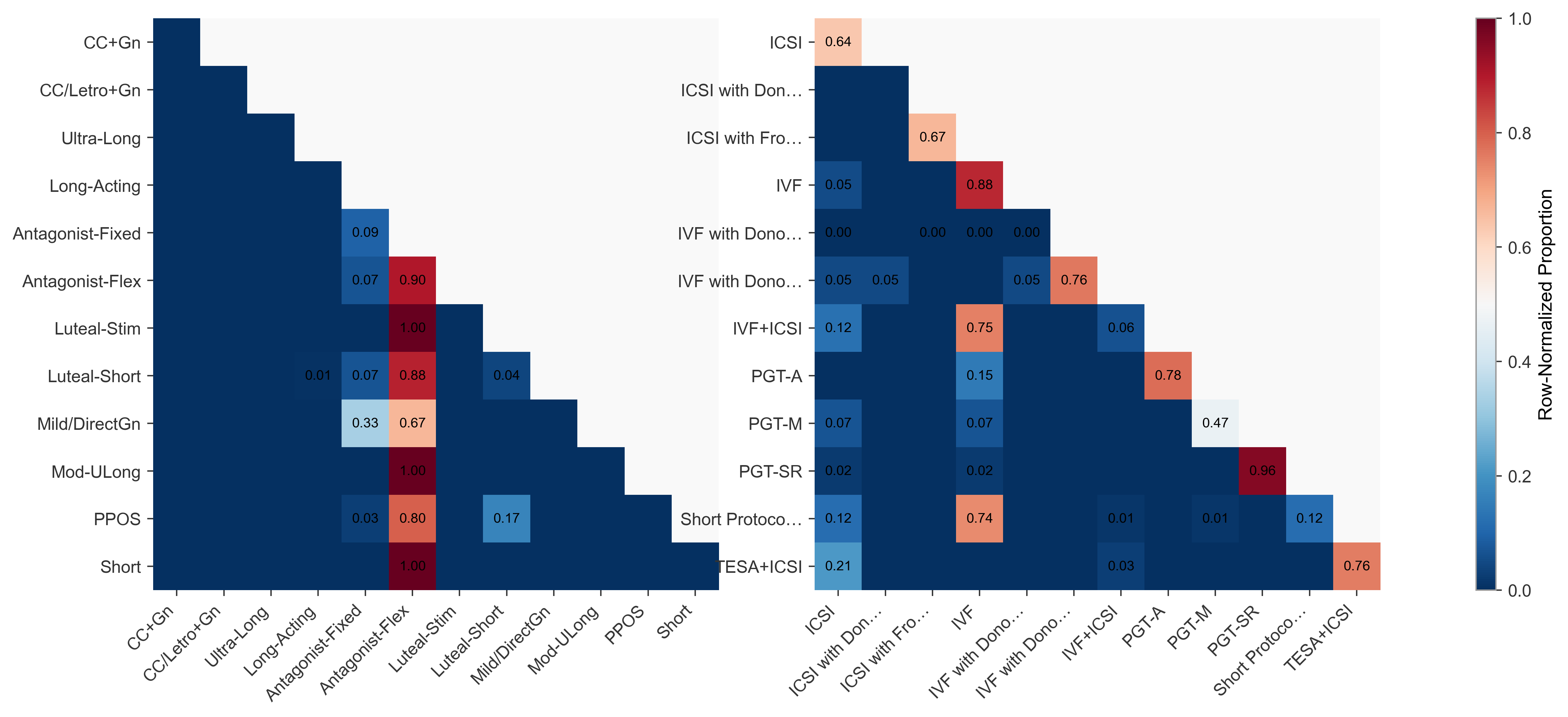
시각 인지와 추론을 위한 종합 퍼즐 벤치마크 SPHINX
We present Sphinx, a synthetic environment for visual perception and reasoning that targets core cognitive primitives. Sphinx procedurally generates puzzles using motifs, tiles, charts, icons, and geometric primitives, each paired with verifiable gro