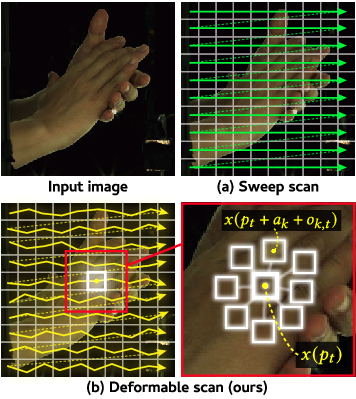
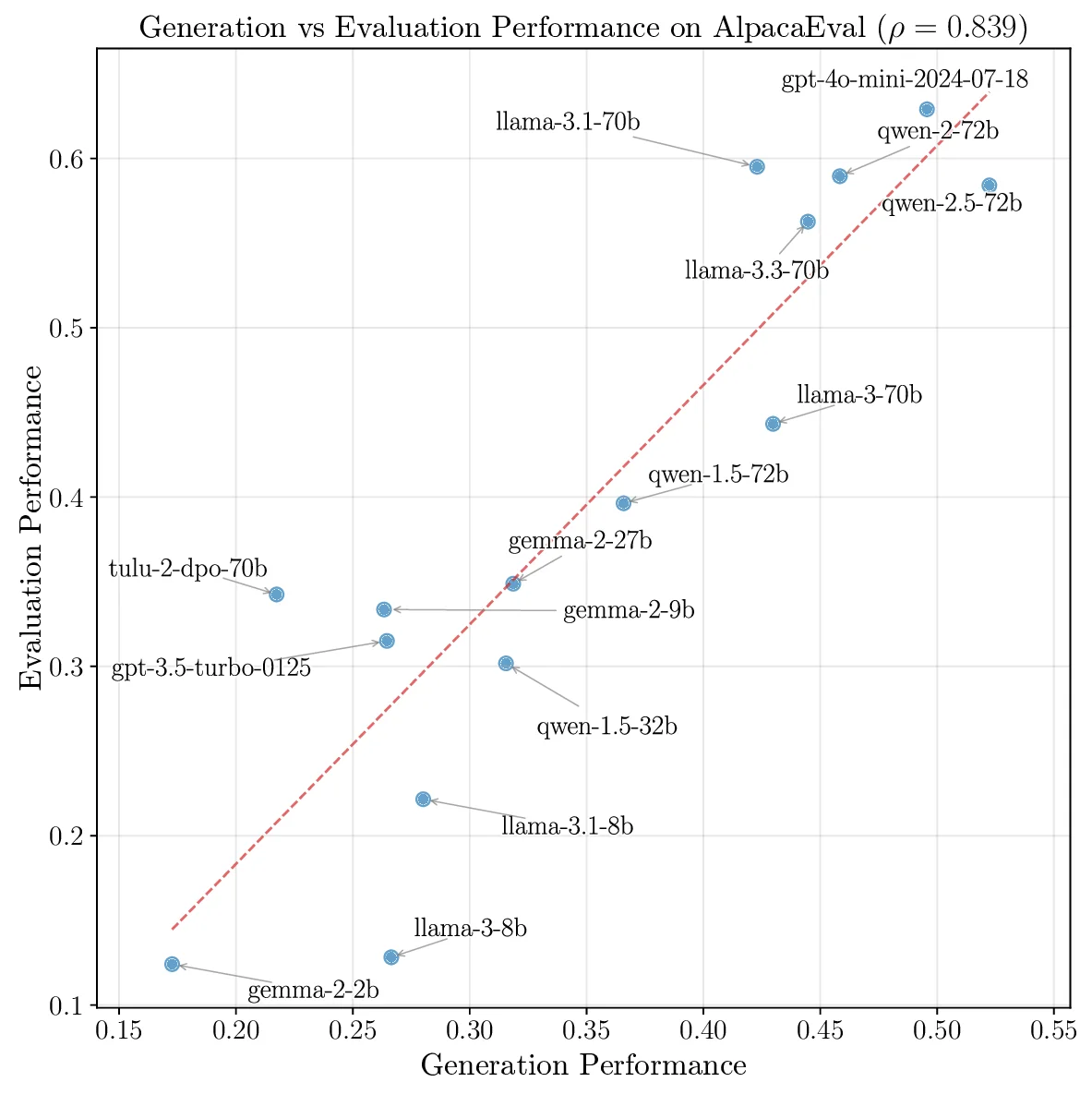
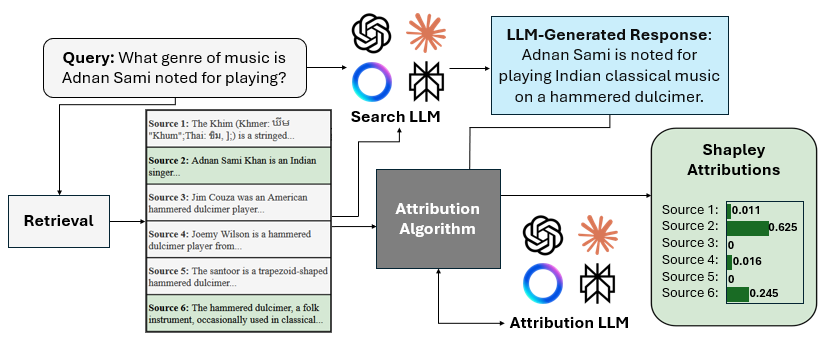
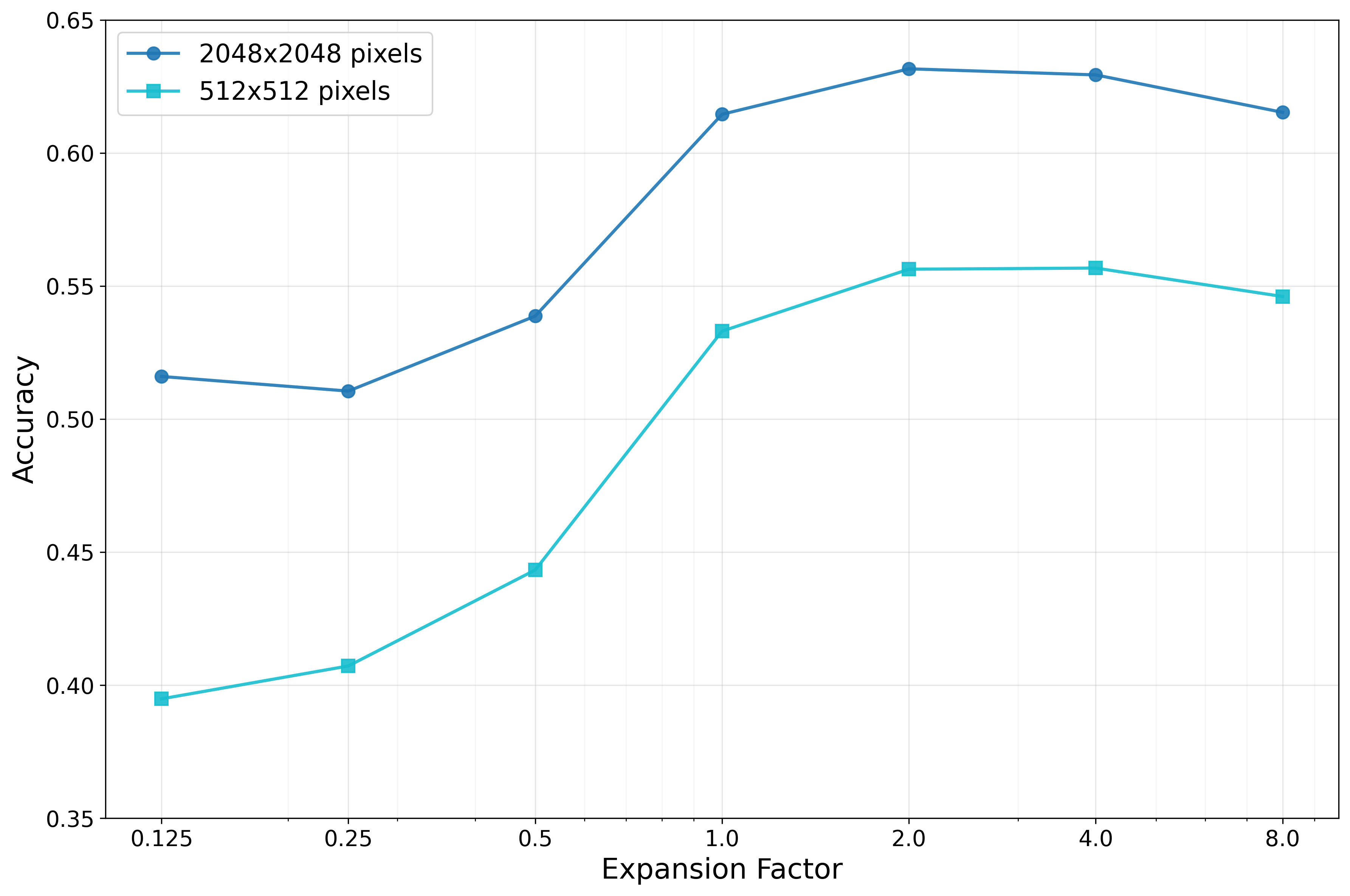
더 적은 파편화로 더 나은 결과: PartUV의 혁신
UV unwrapping flattens 3D surfaces to 2D with minimal distortion, often requiring the complex surface to be decomposed into multiple charts. Although extensively studied, existing UV unwrapping methods frequently struggle with AI-generated meshes, wh