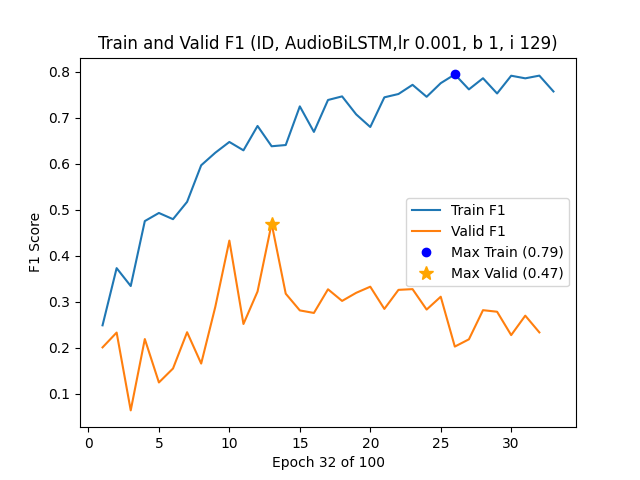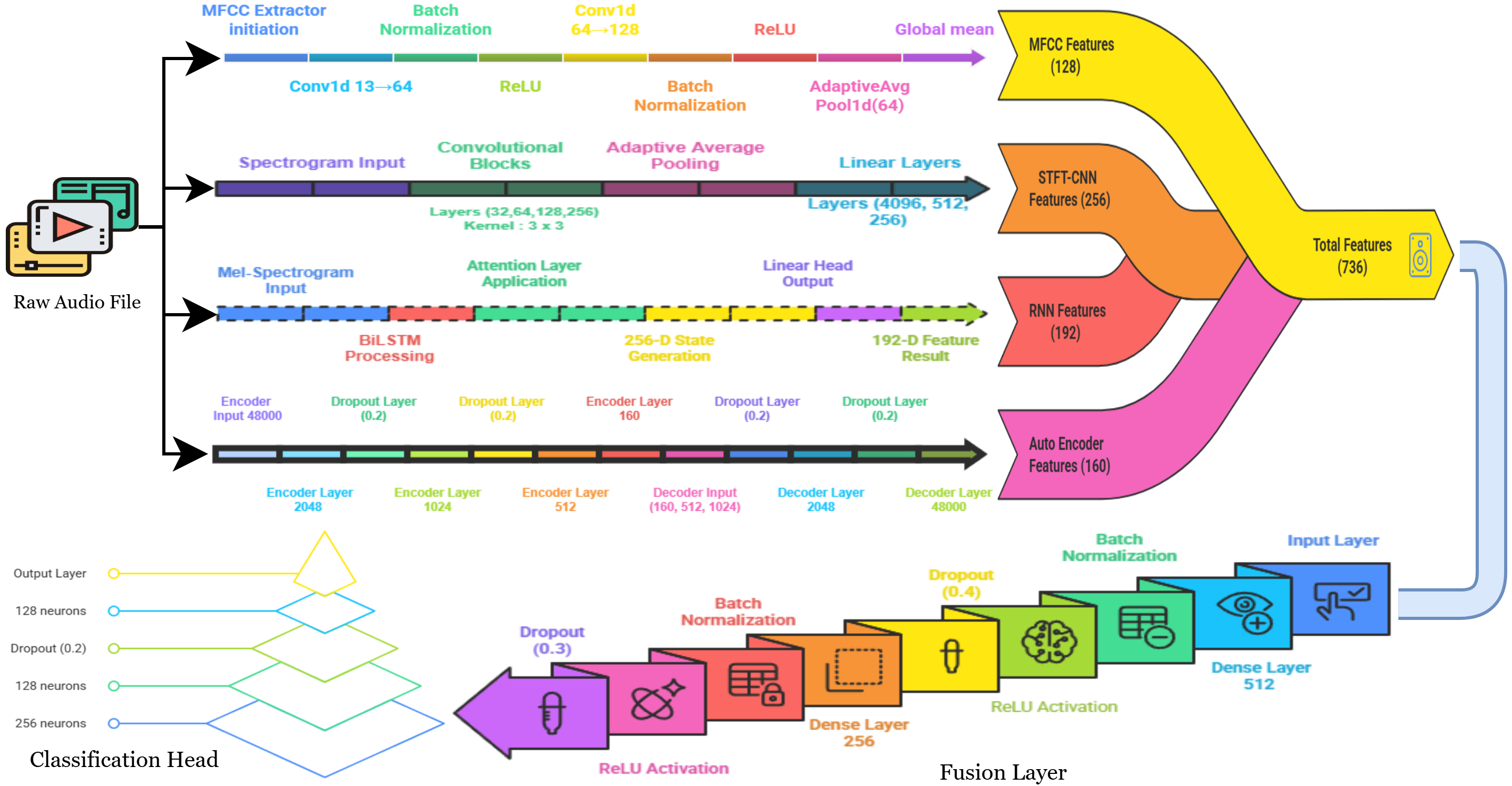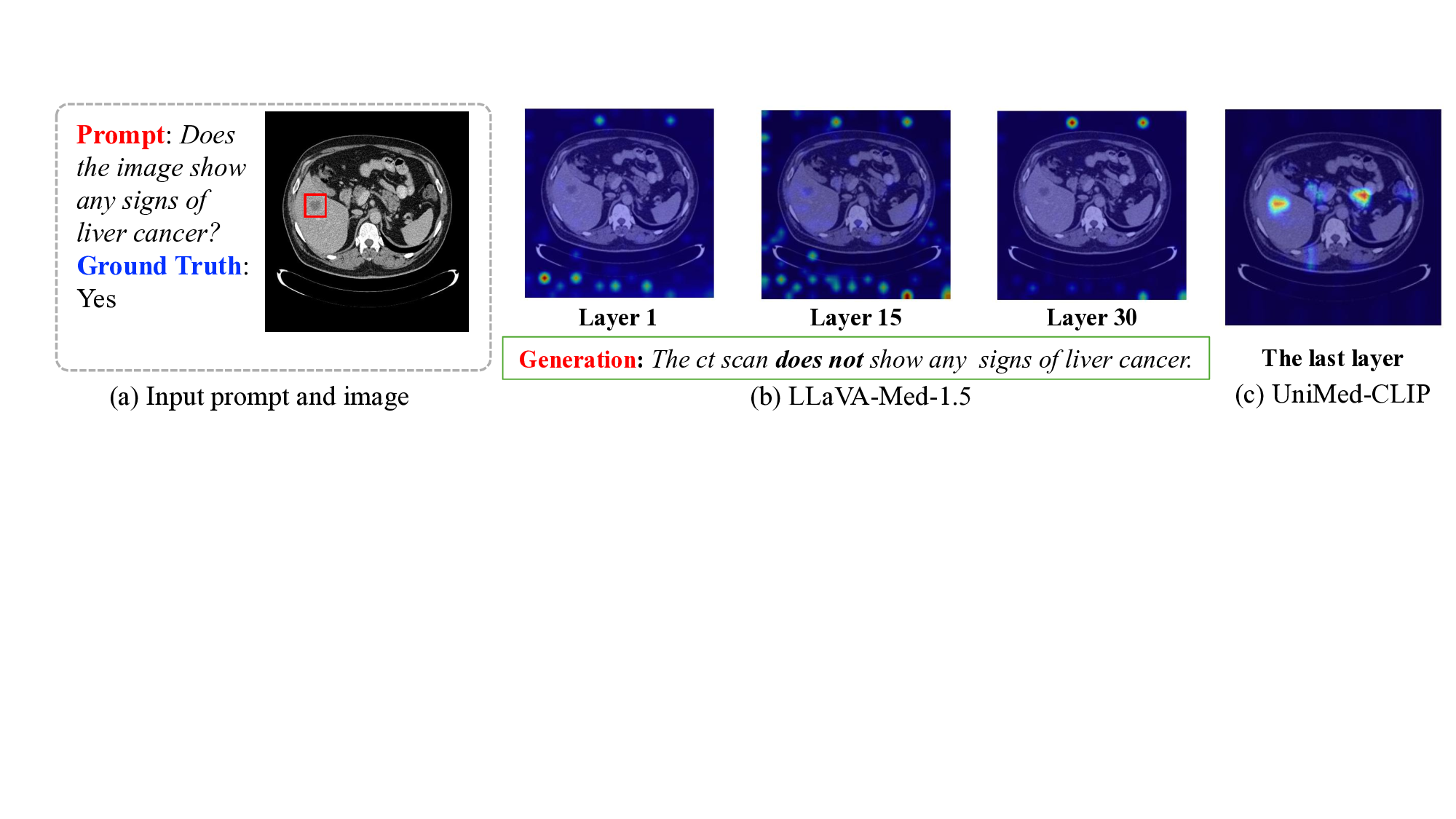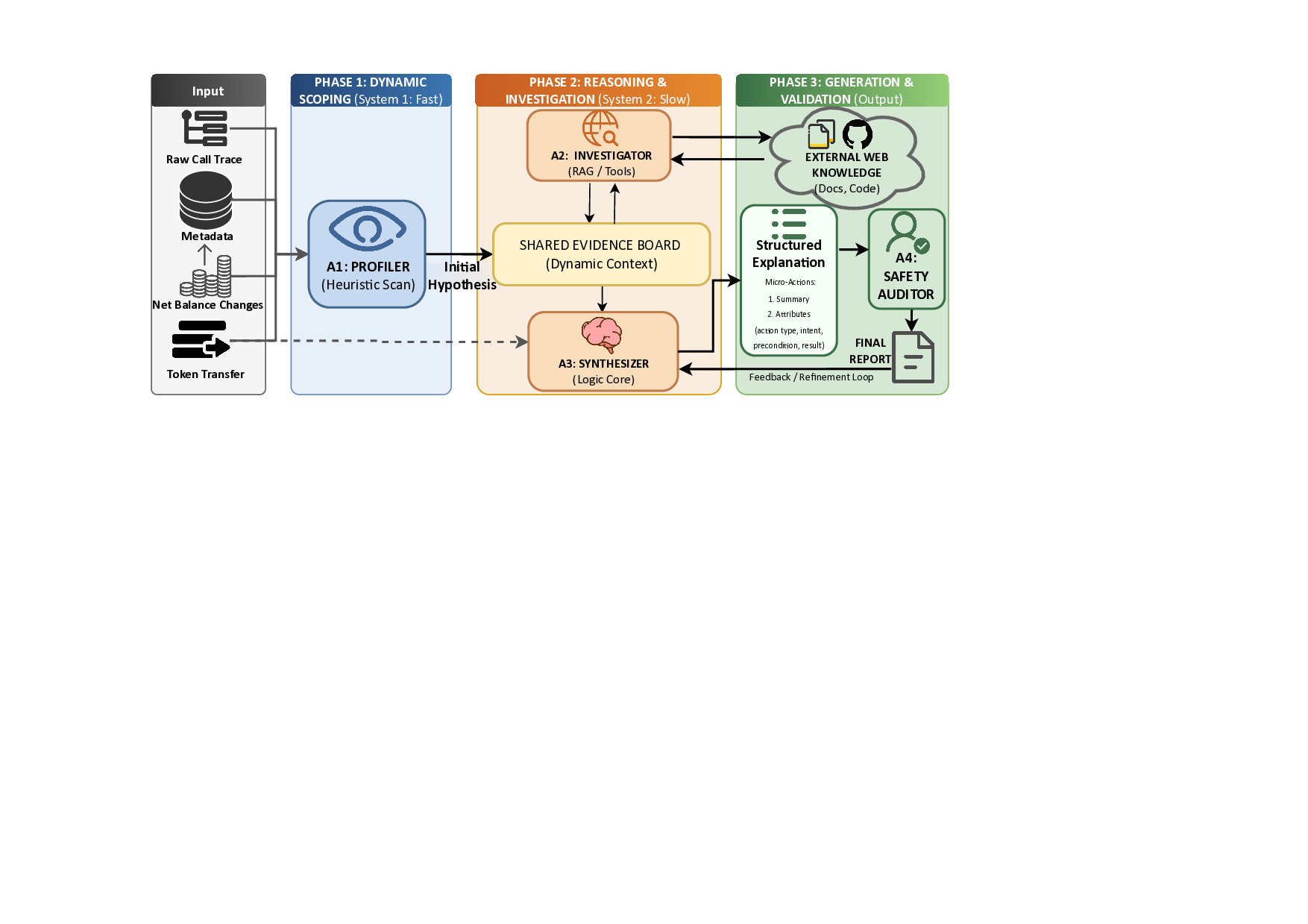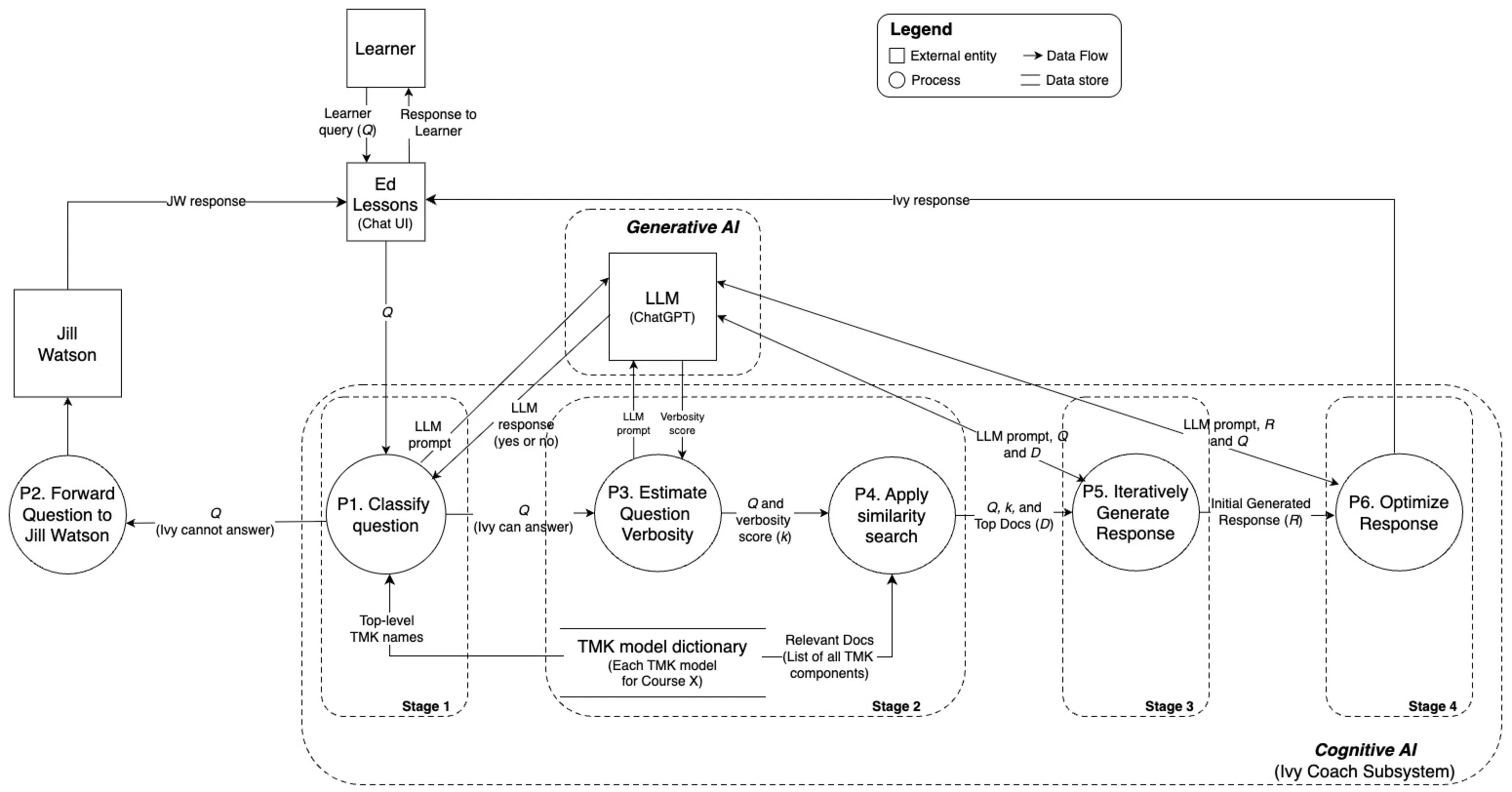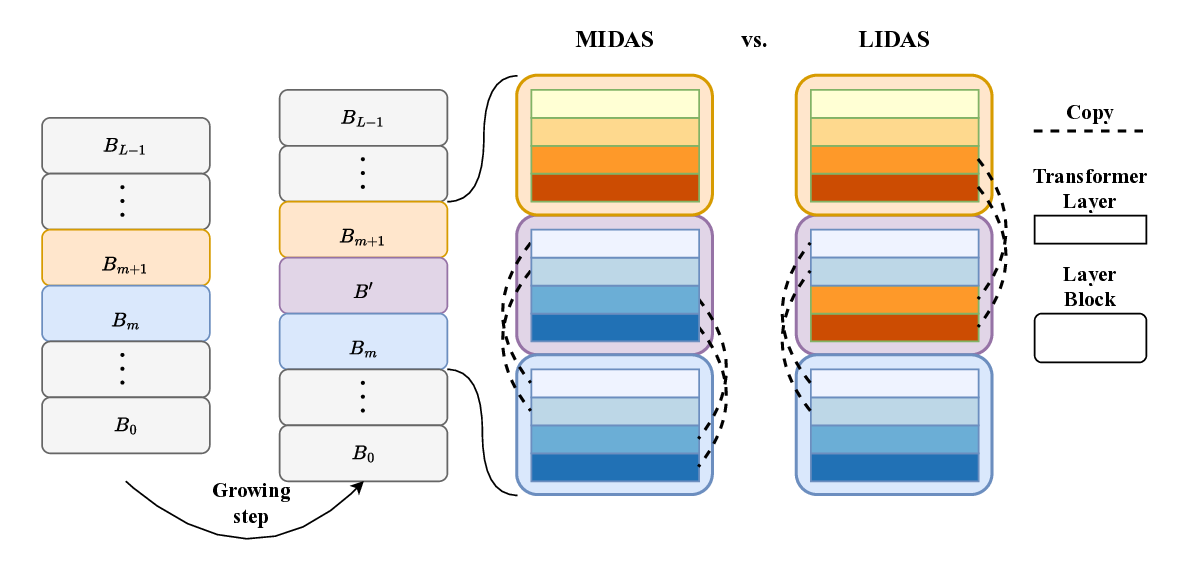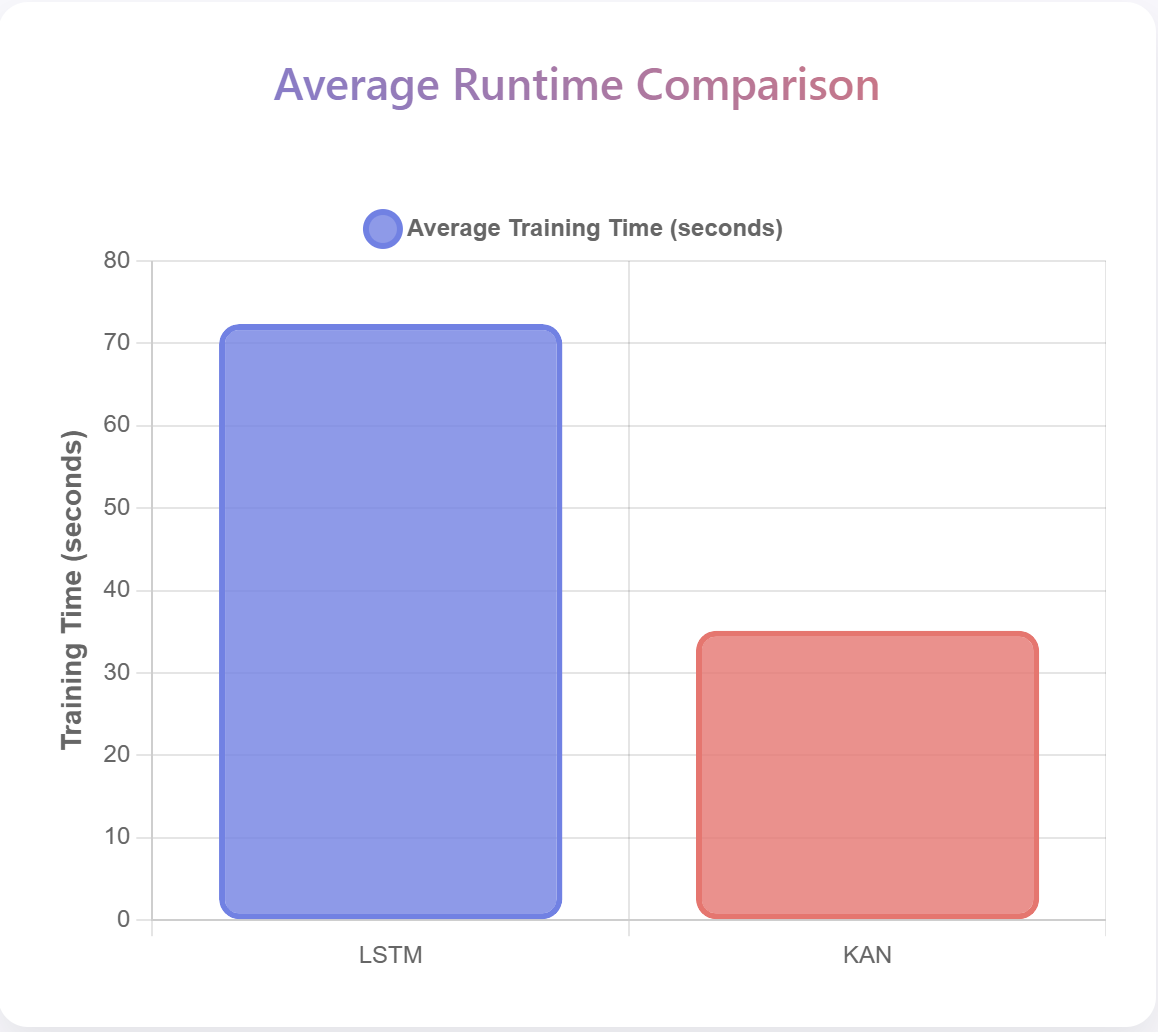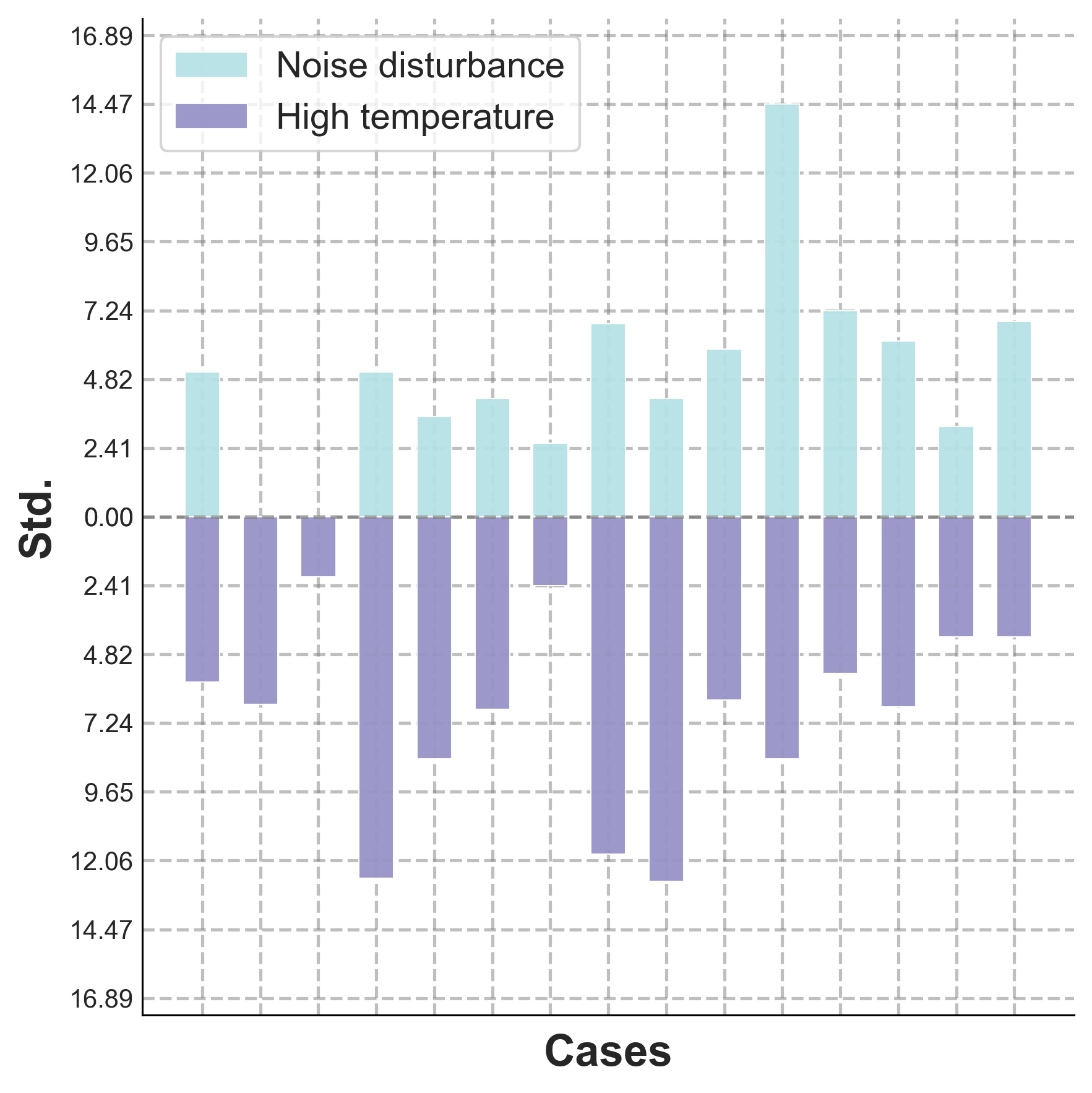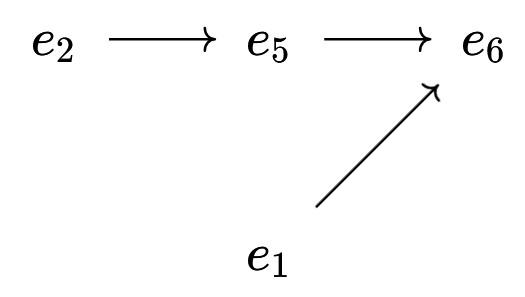
위키백과 댓글 무례성 탐지를 위한 그래프 신경망 기반 구조적 분석
Online incivility has emerged as a widespread and persistent problem in digital communities, imposing substantial social and psychological burdens on users. Although many platforms attempt to curb incivility through moderation and automated detection