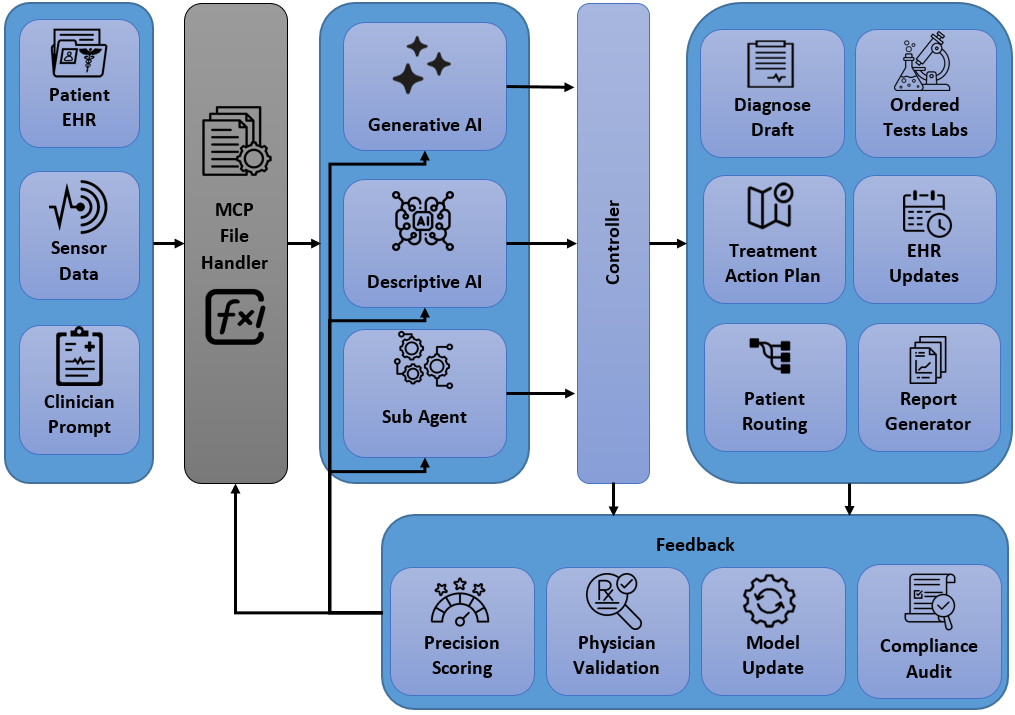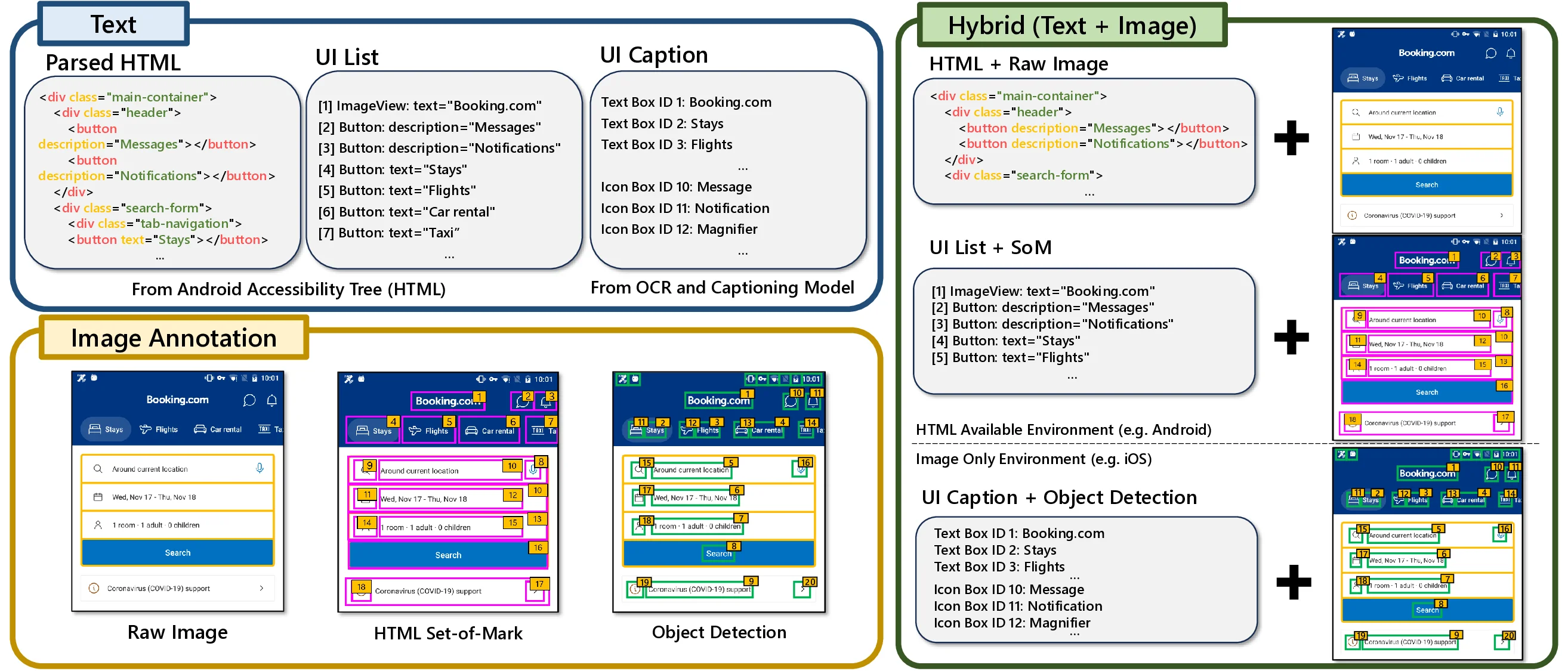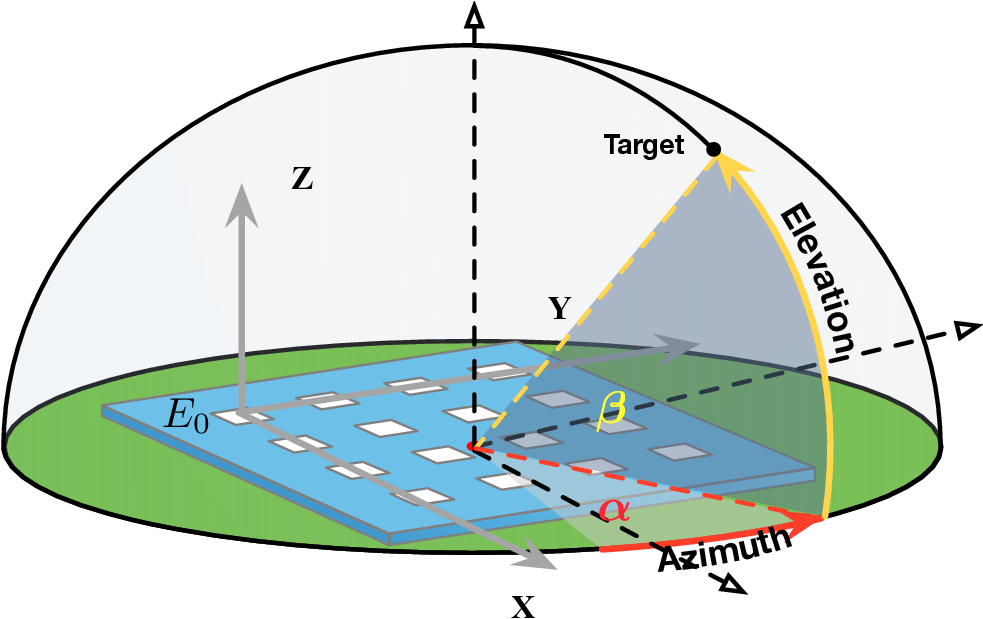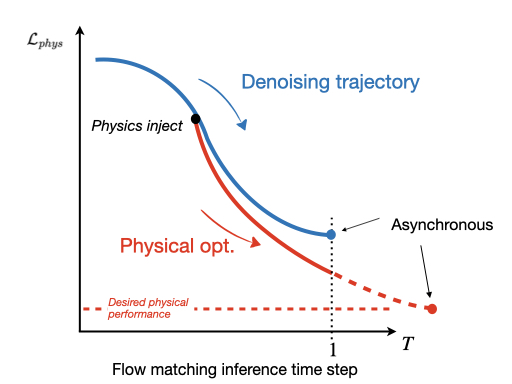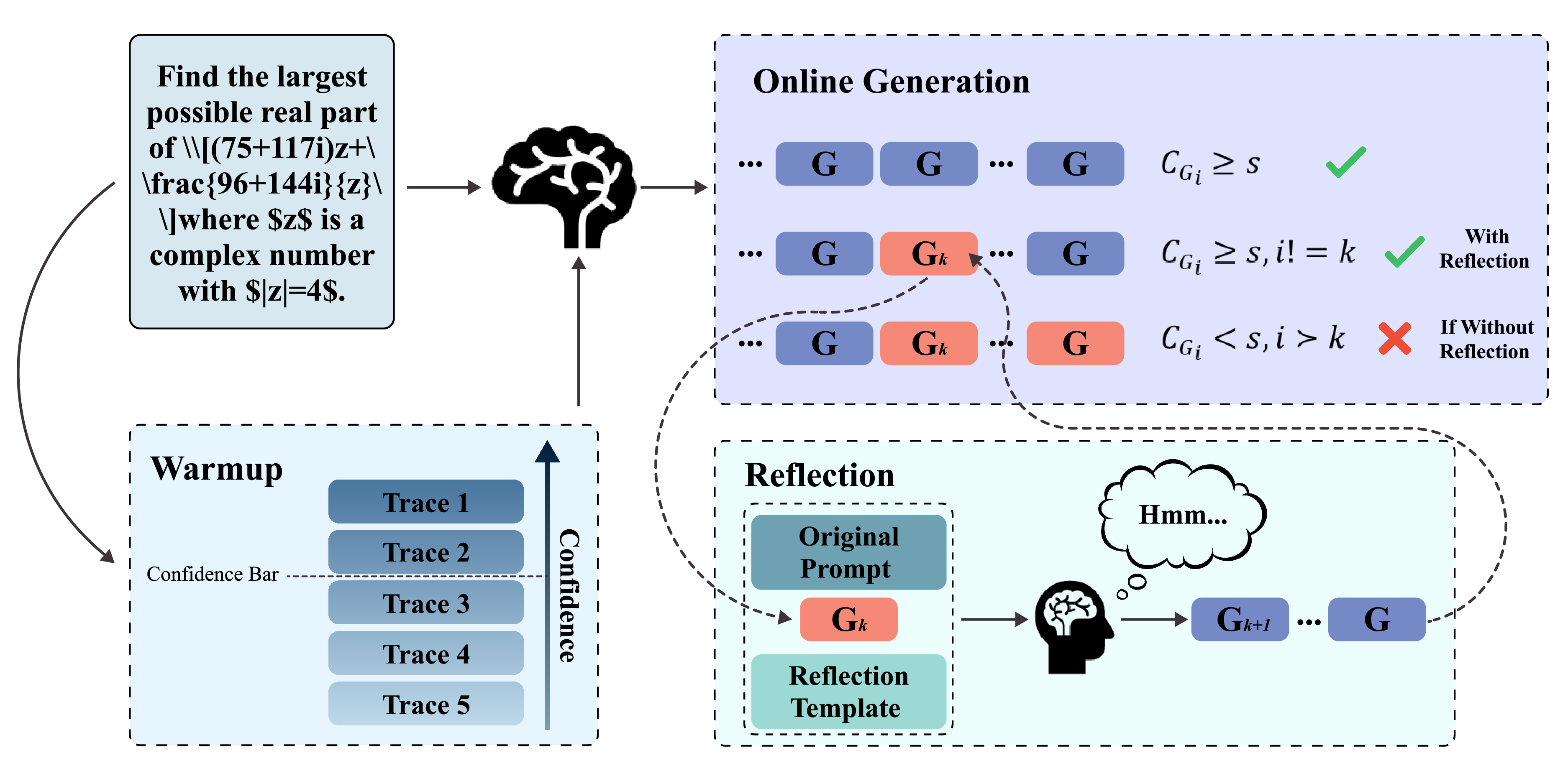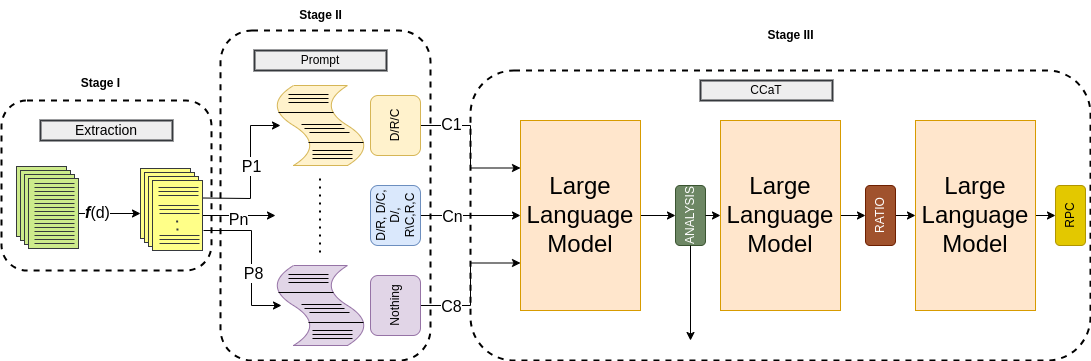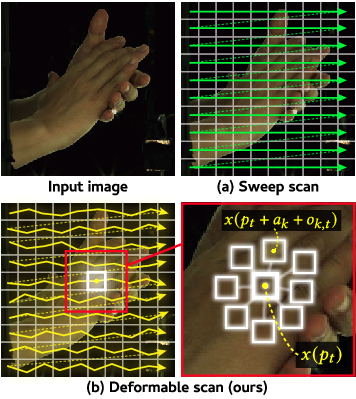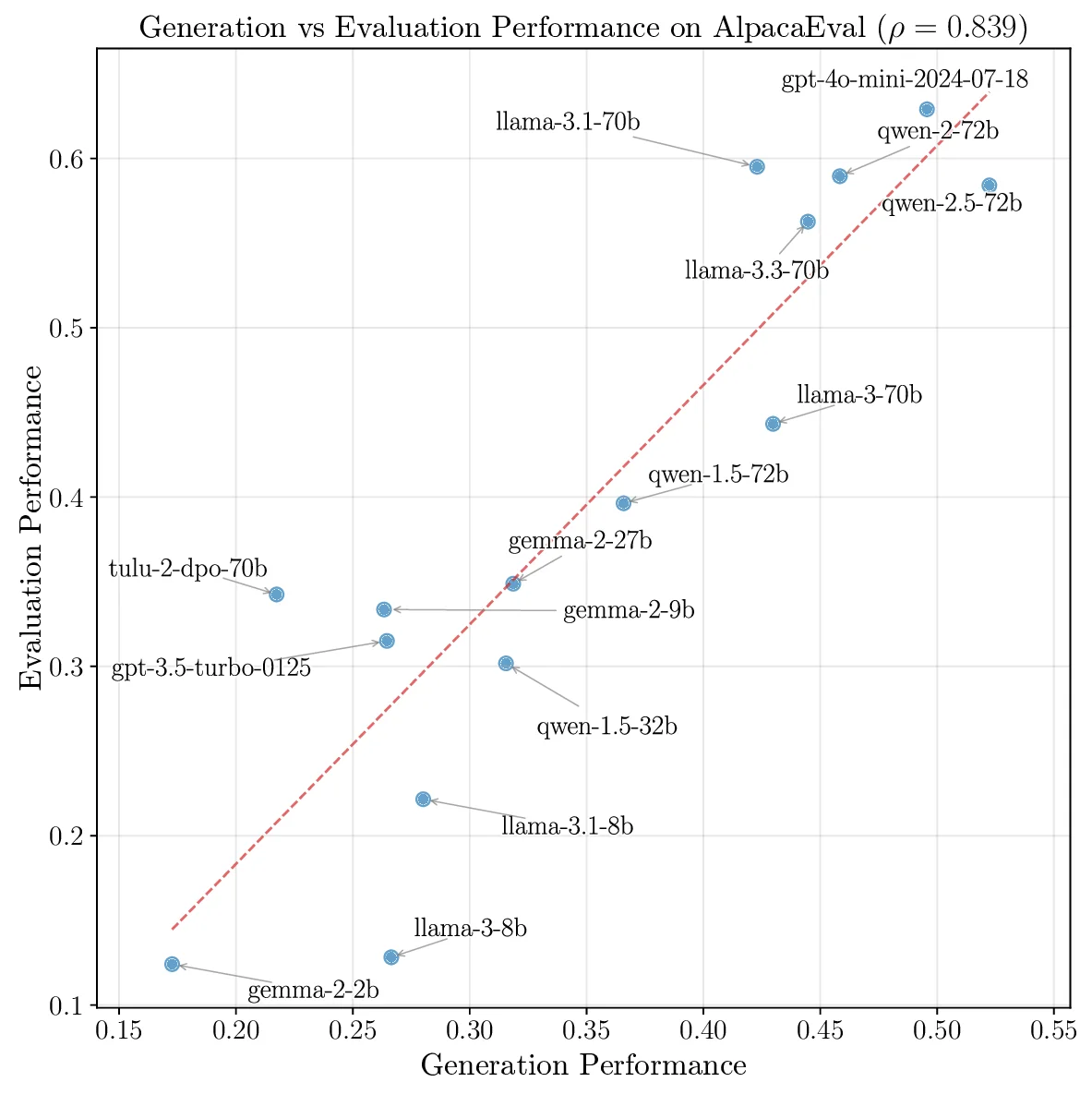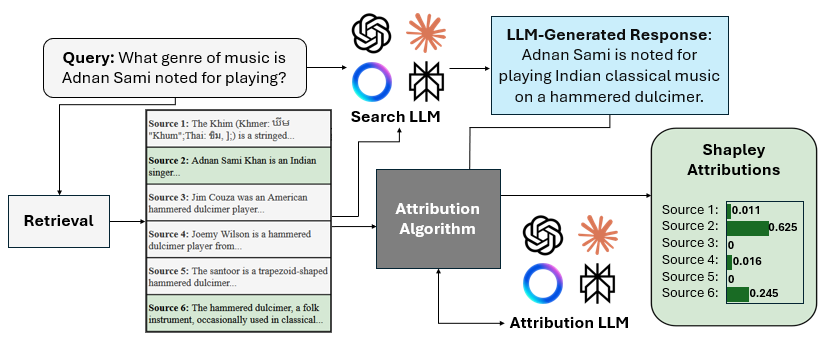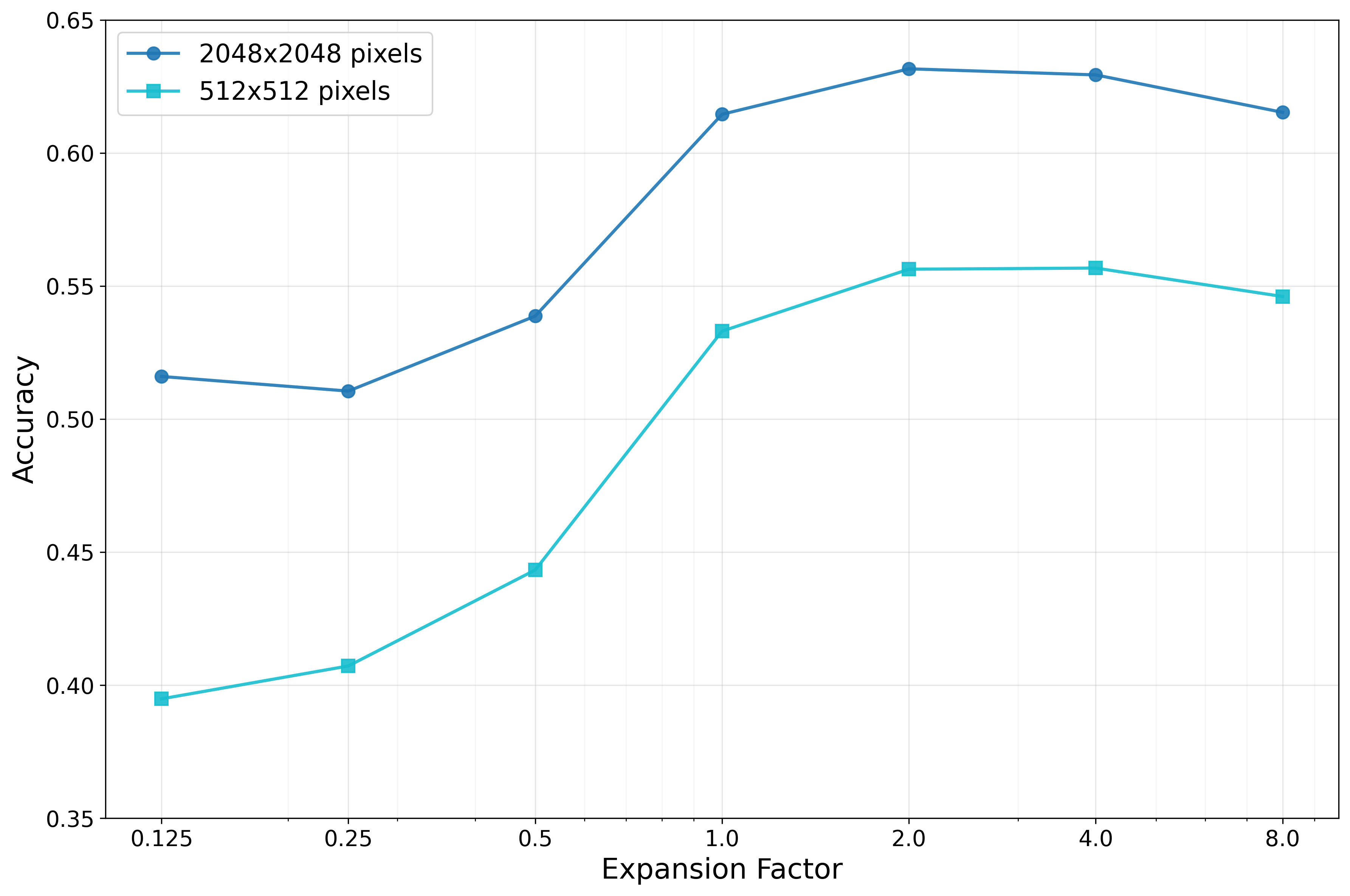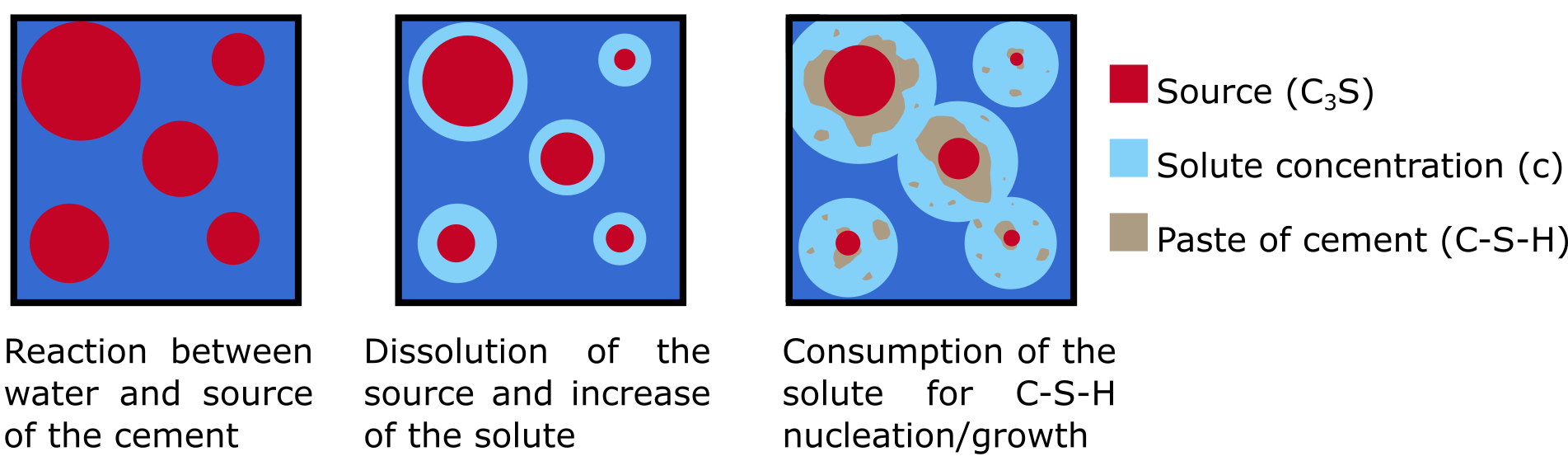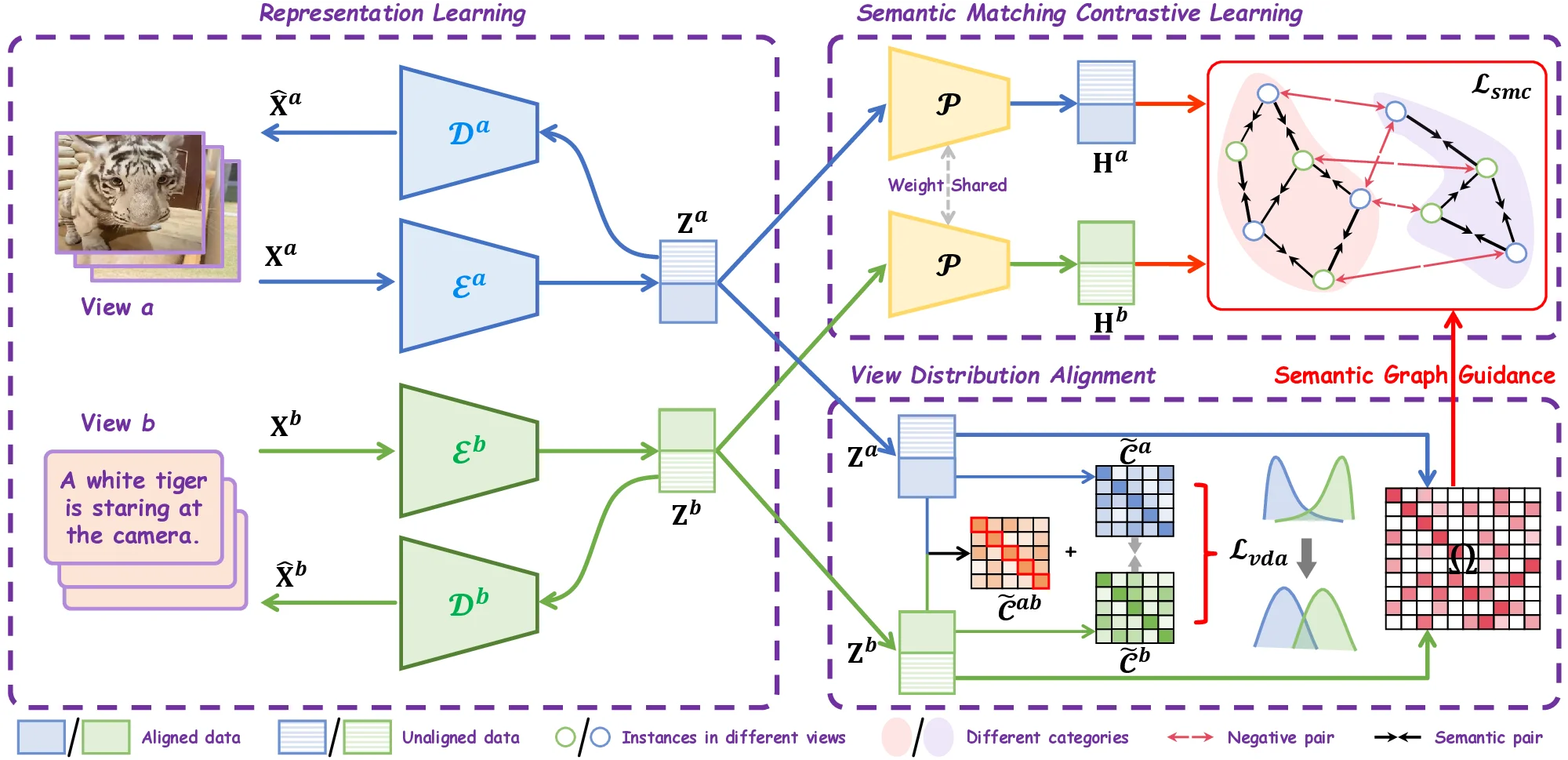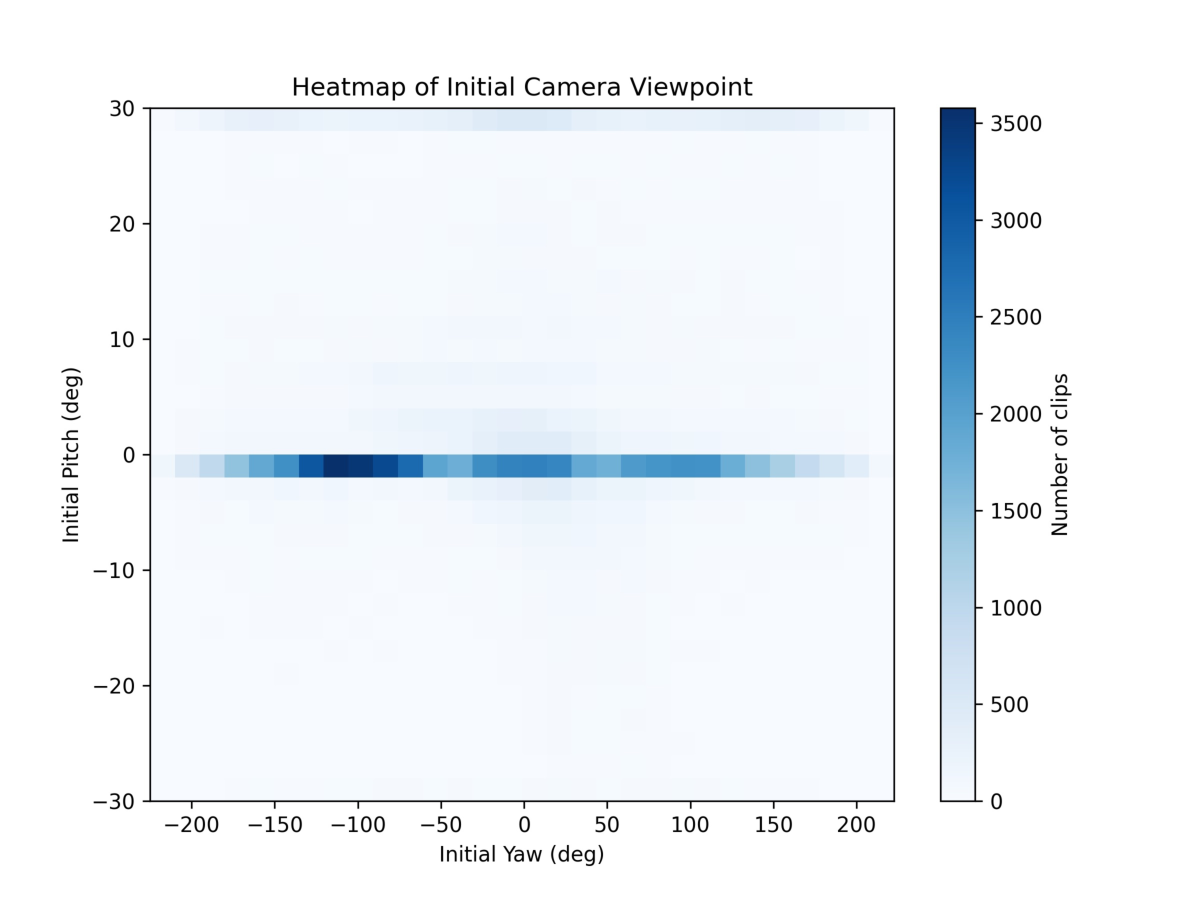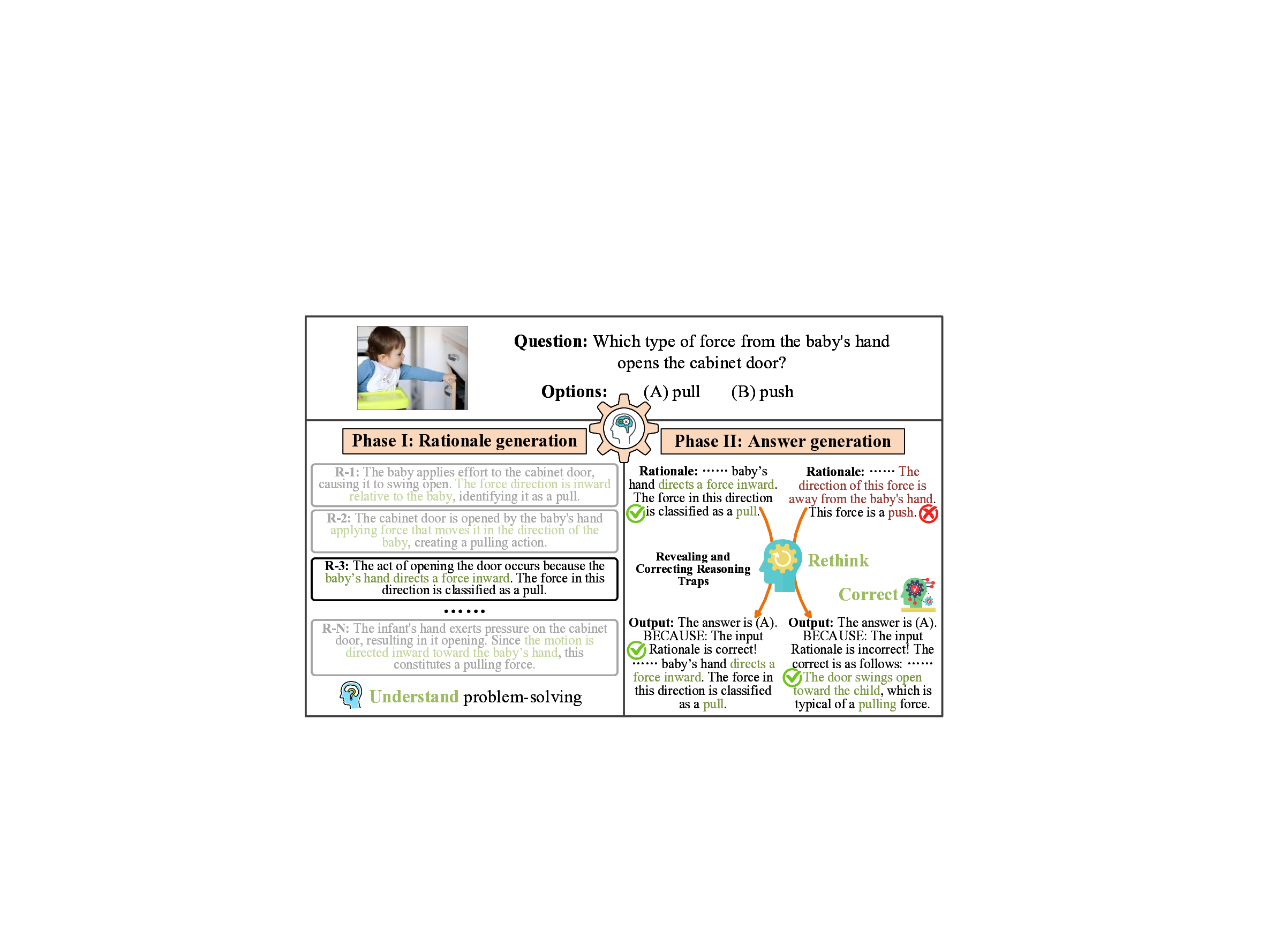
멀티이성 통합 판별 추론 프레임워크 MIND
Recently, multimodal large language models (MLLMs) have been widely applied to reasoning tasks. However, they suffer from limited multi-rationale semantic modeling, insufficient logical robustness, and are susceptible to misleading interpretations in