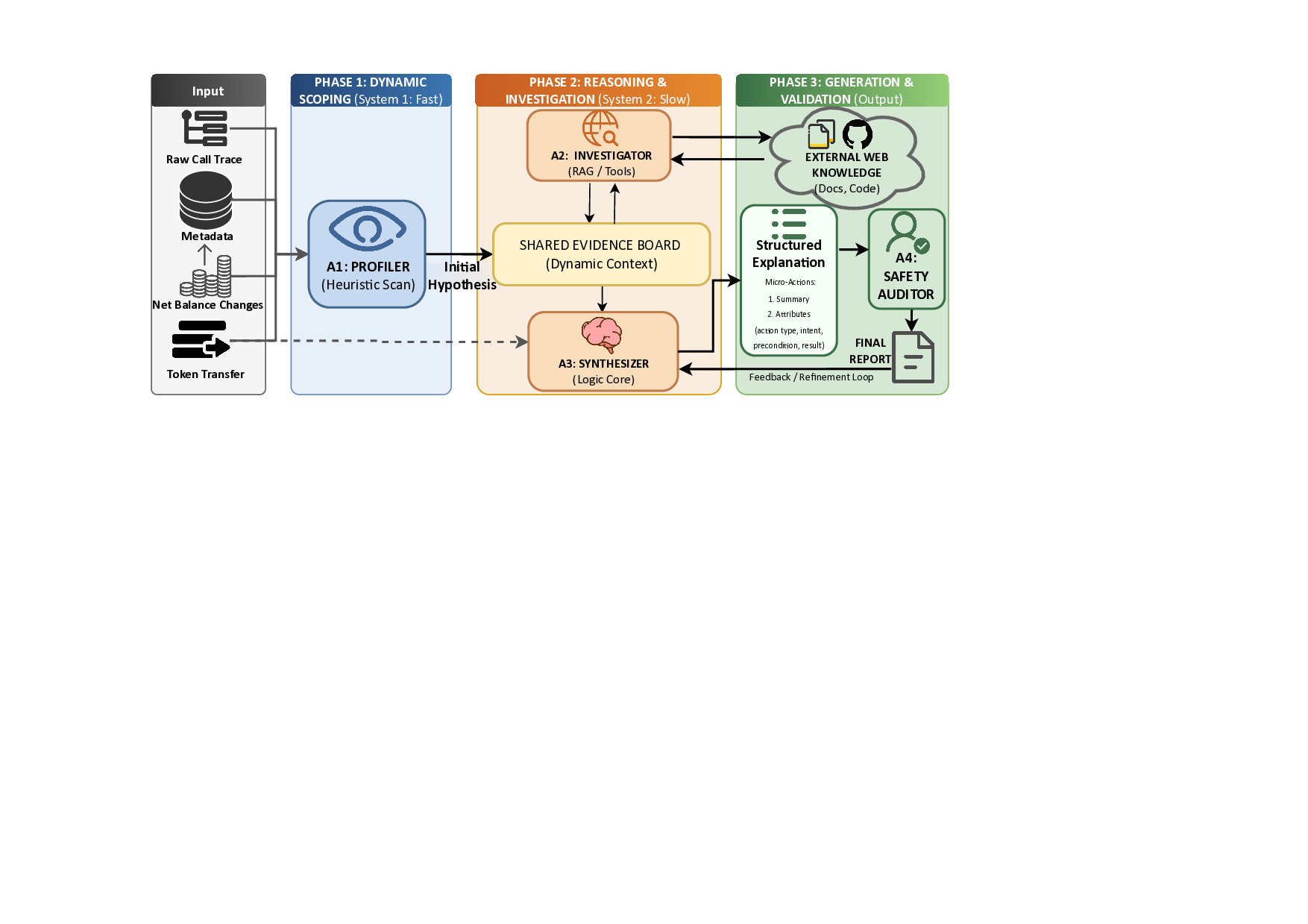
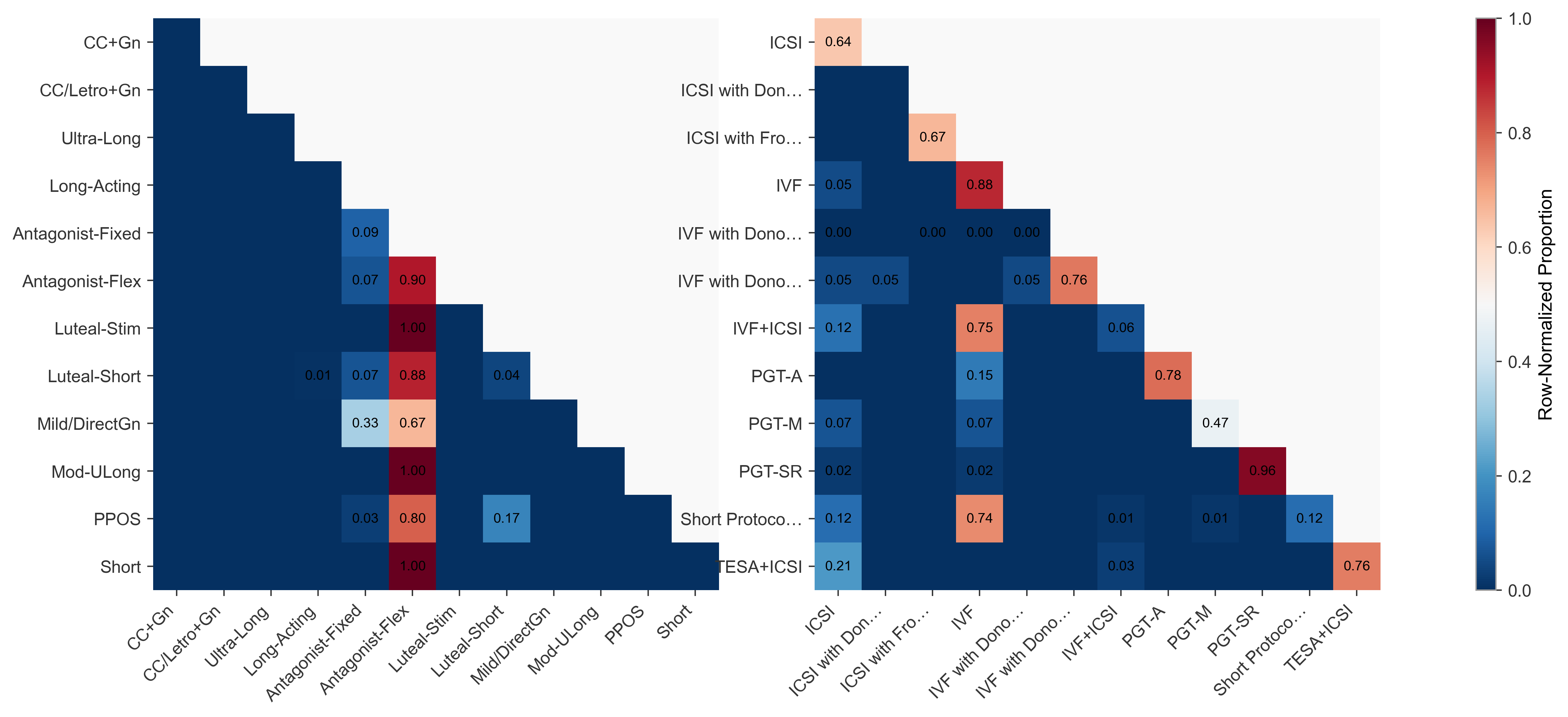
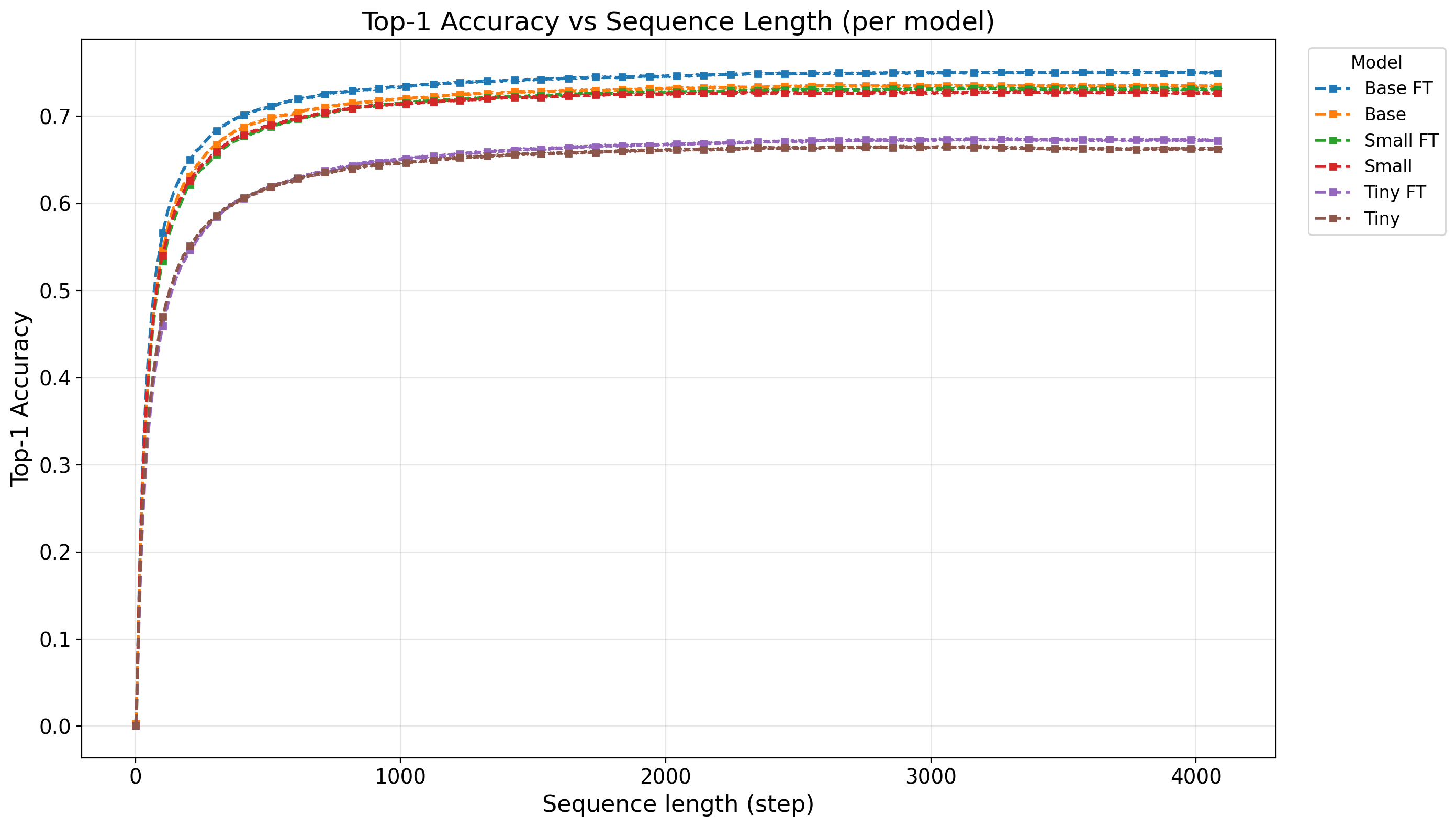
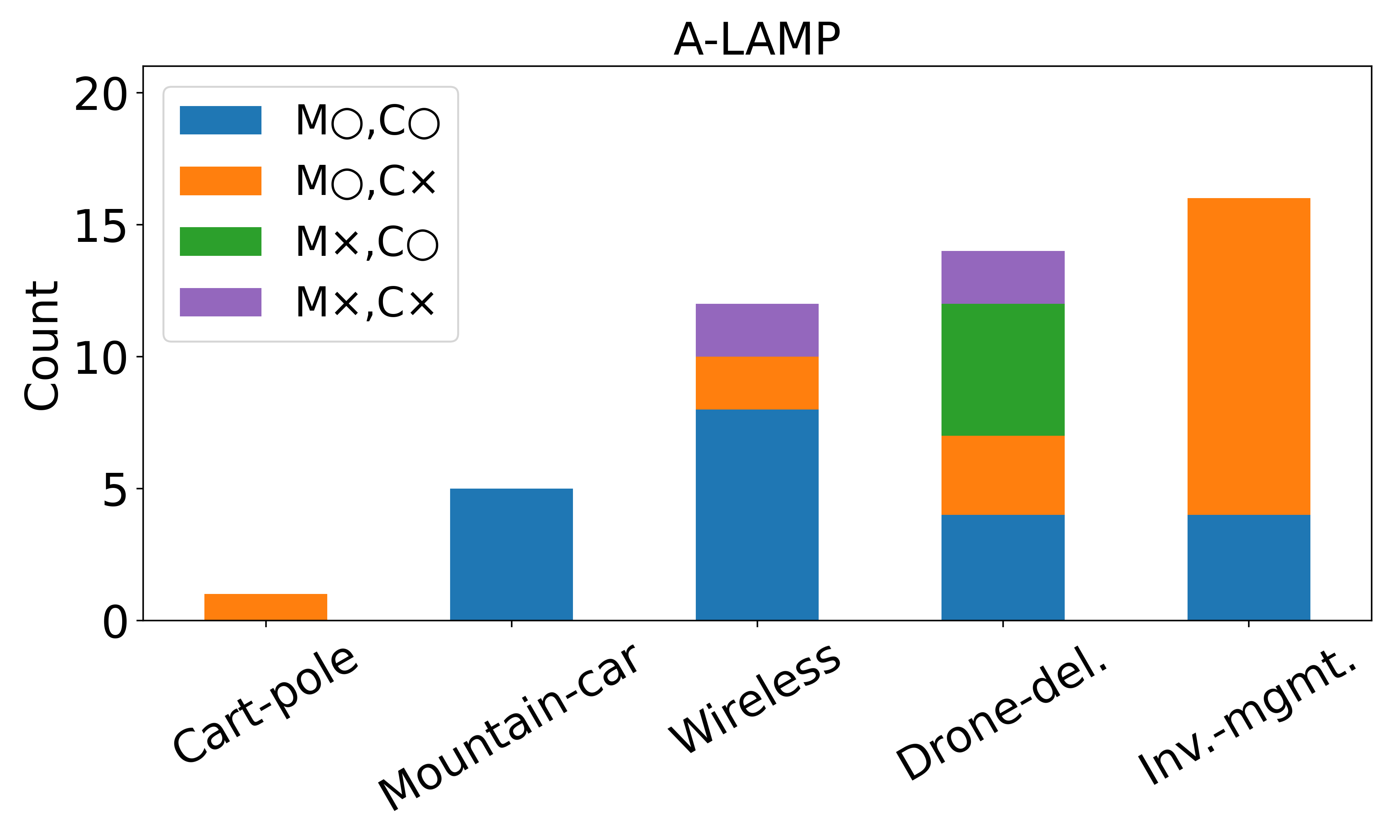
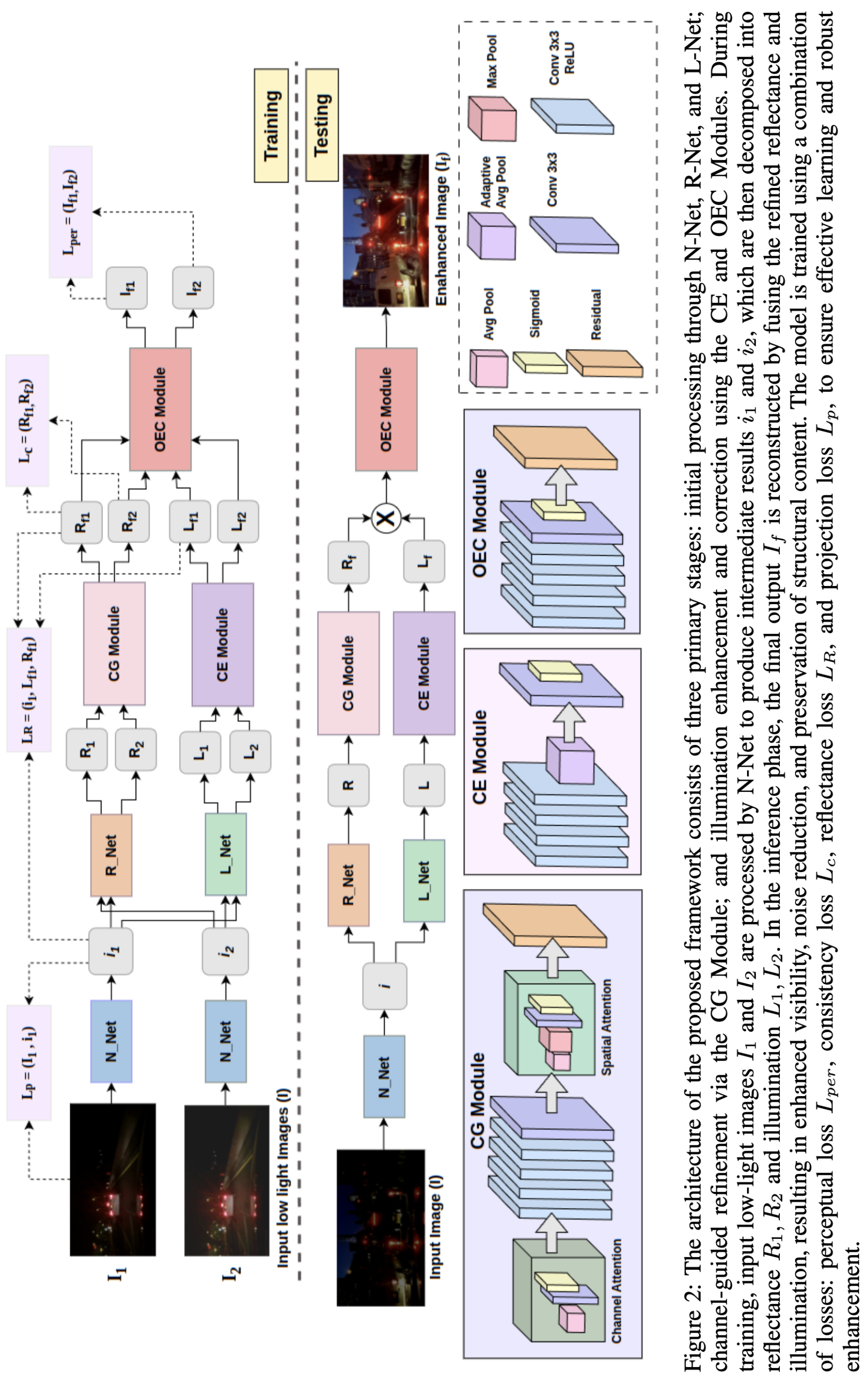
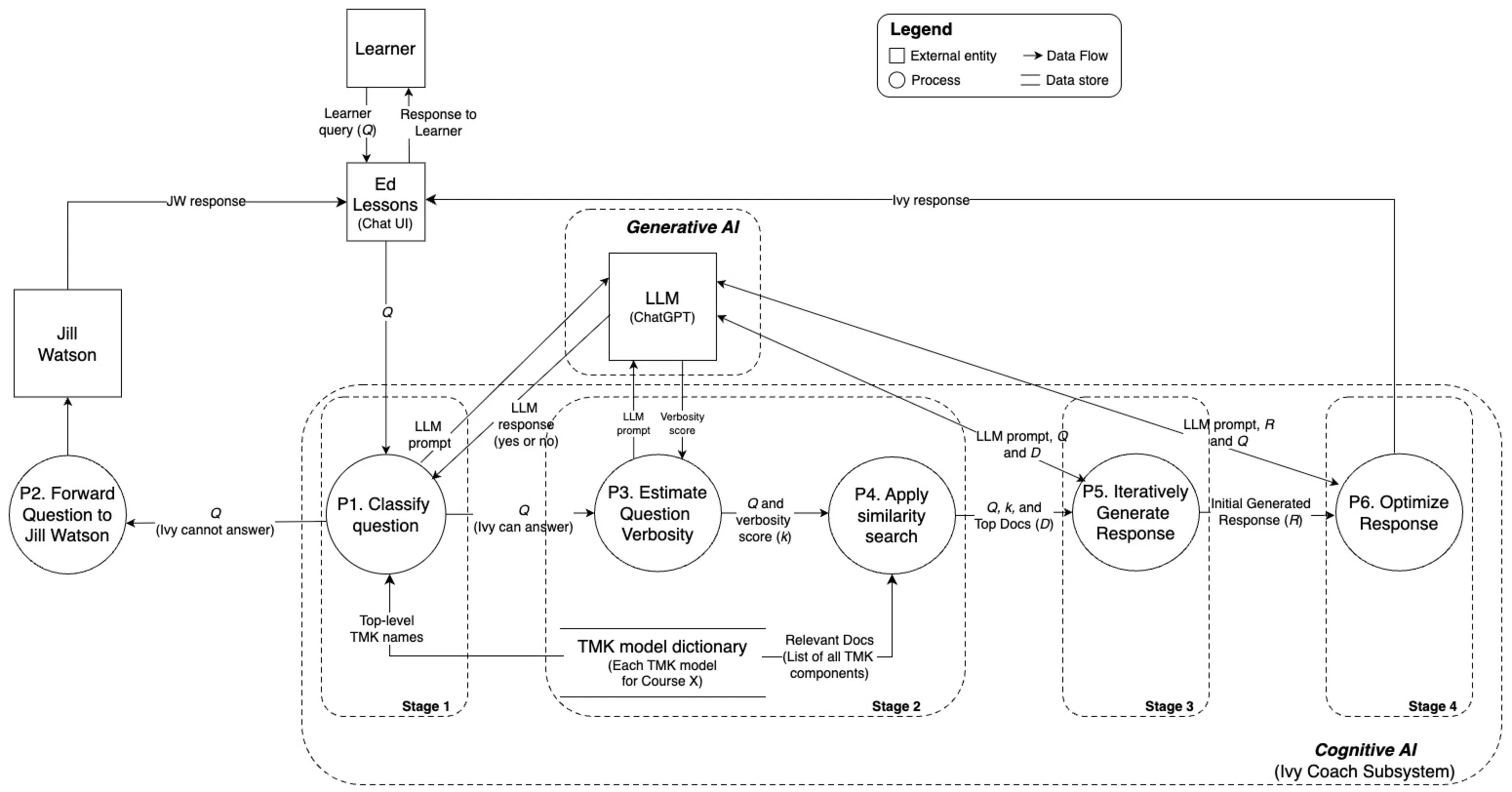
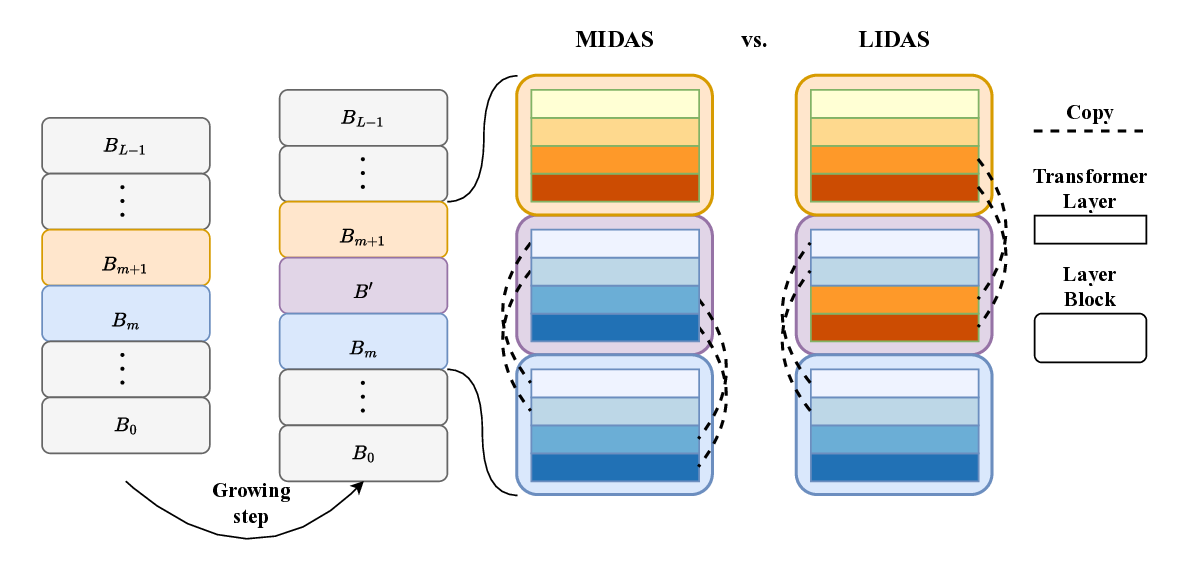
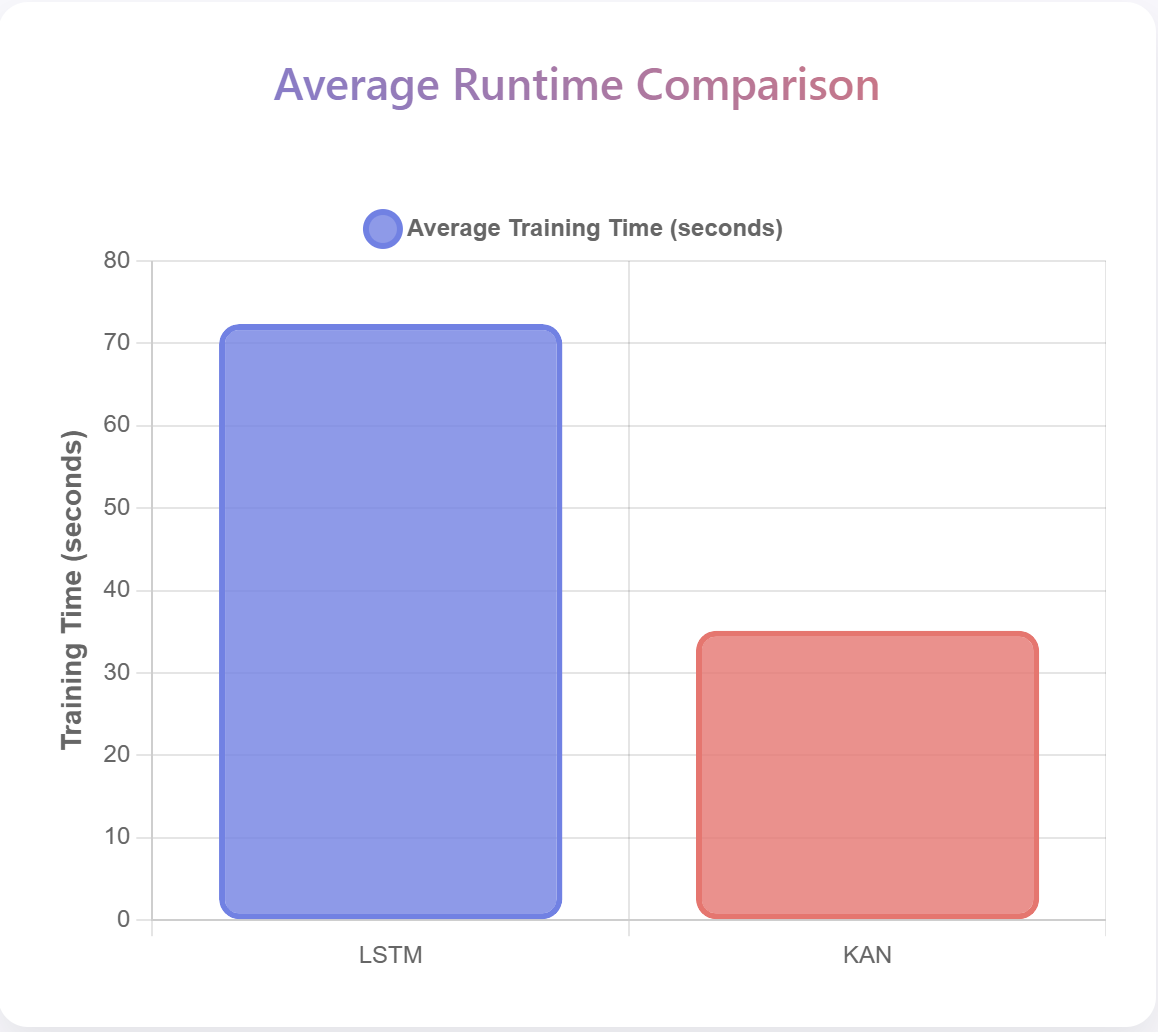
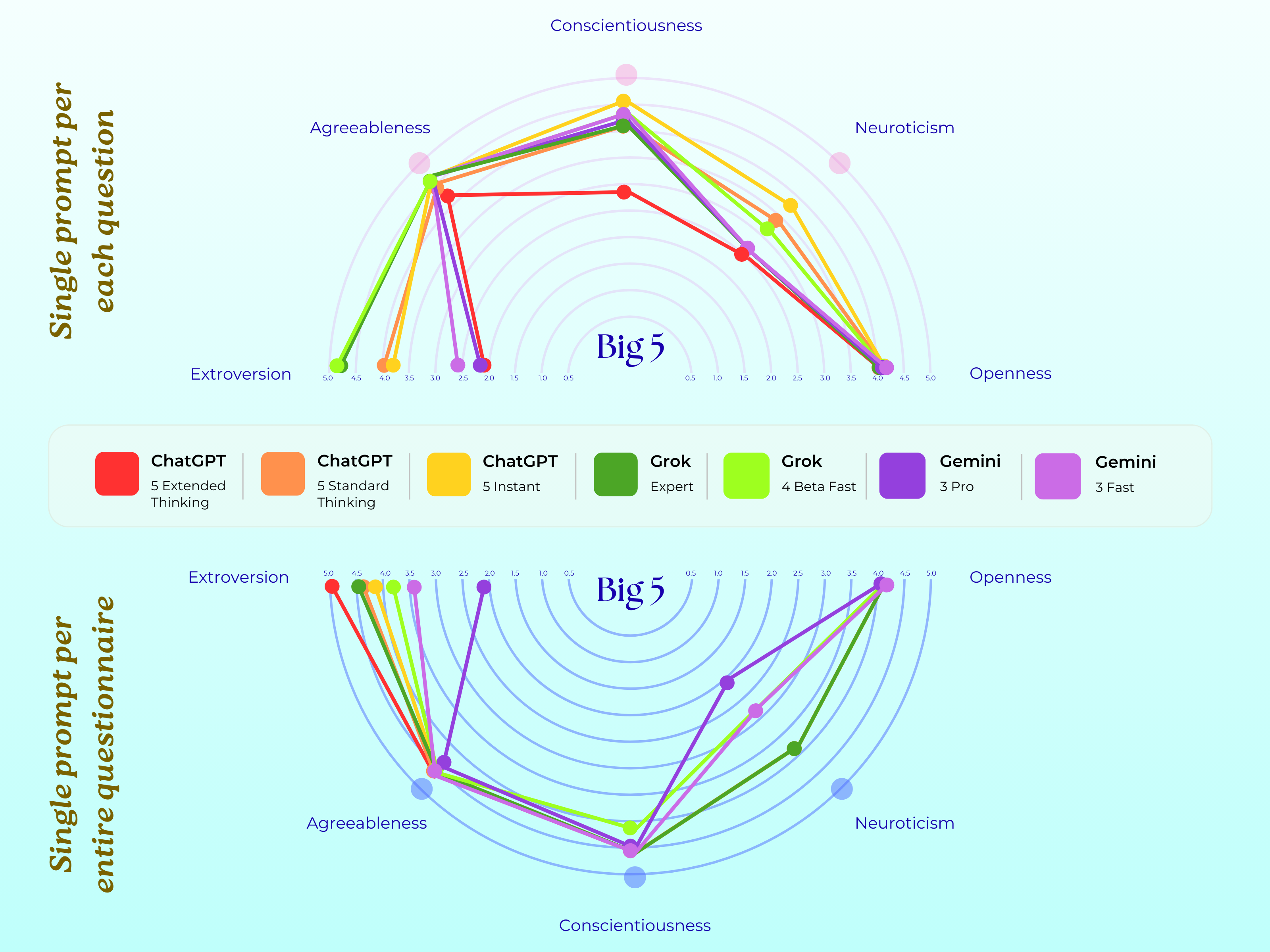
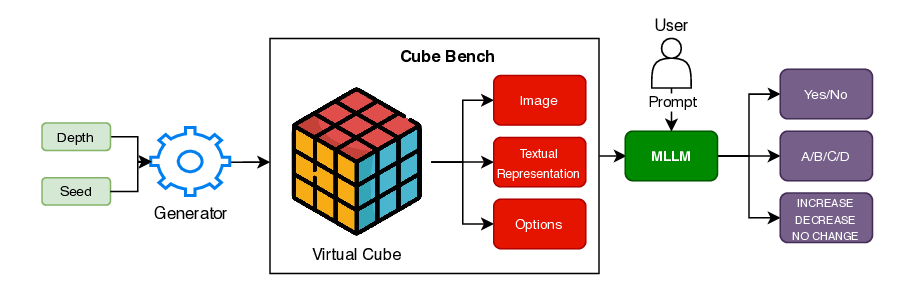
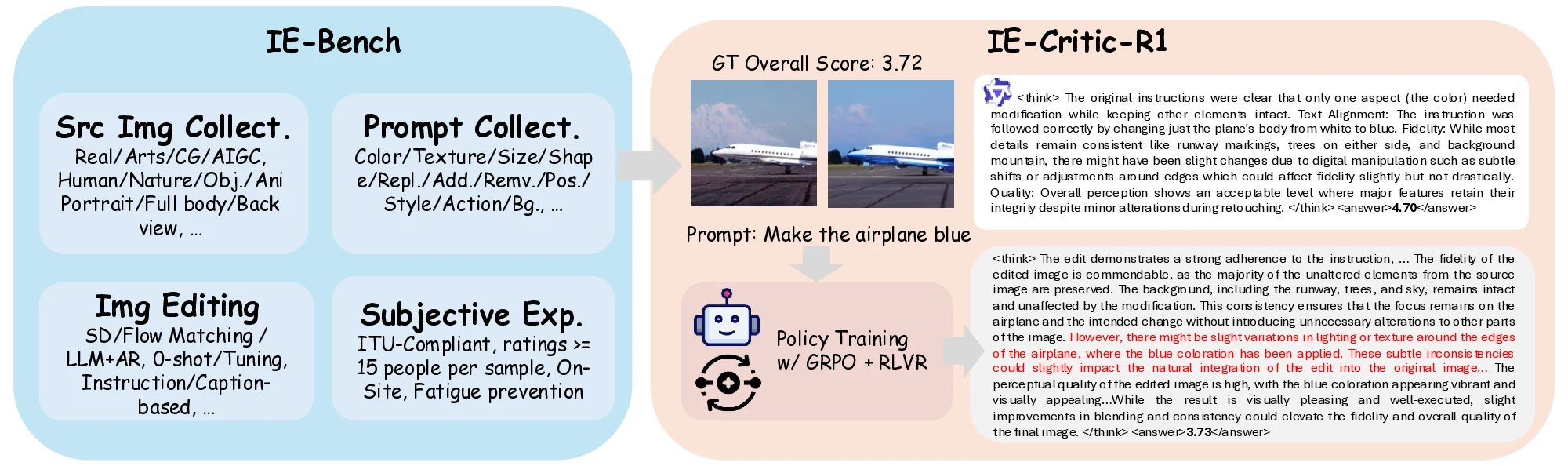
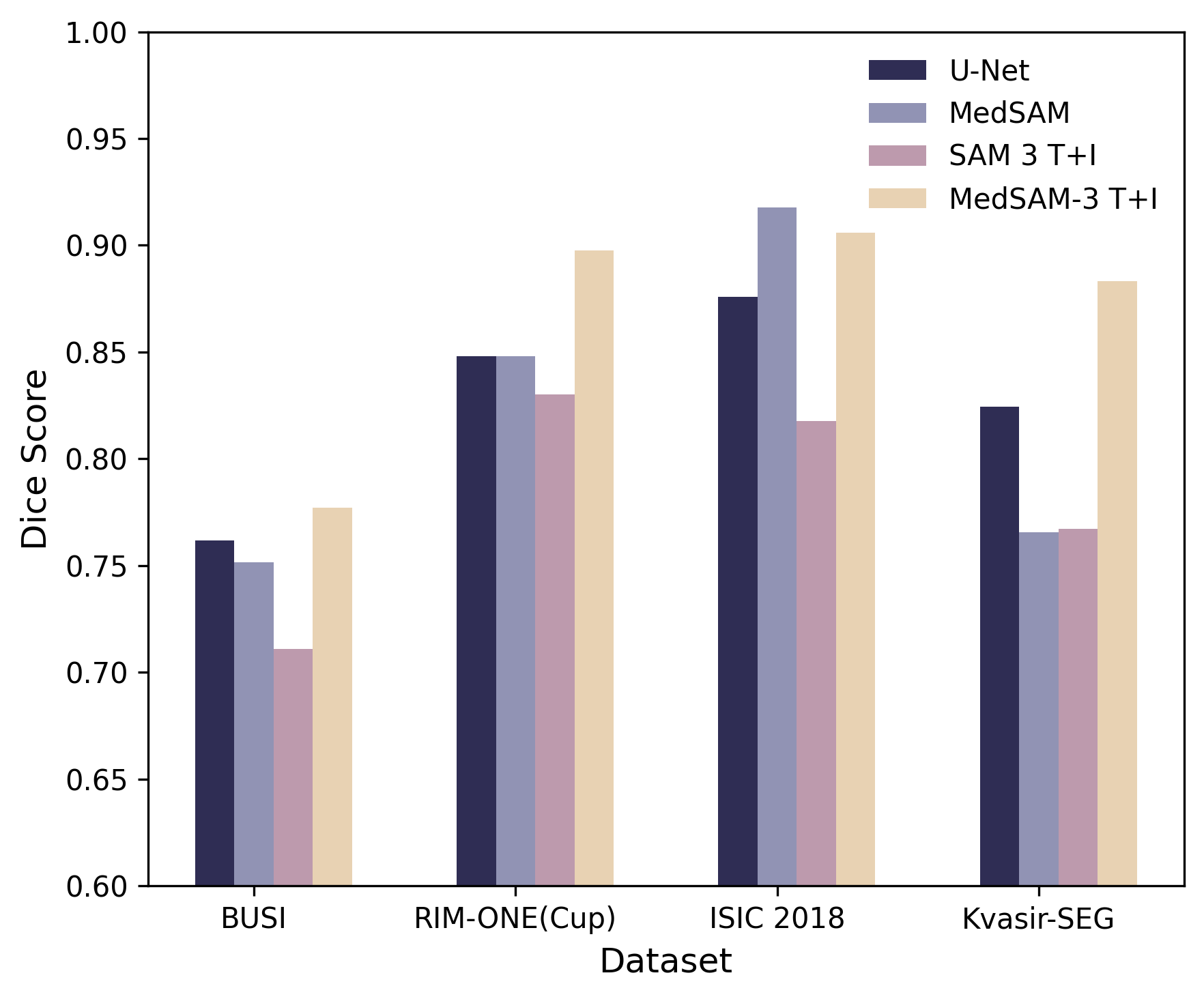
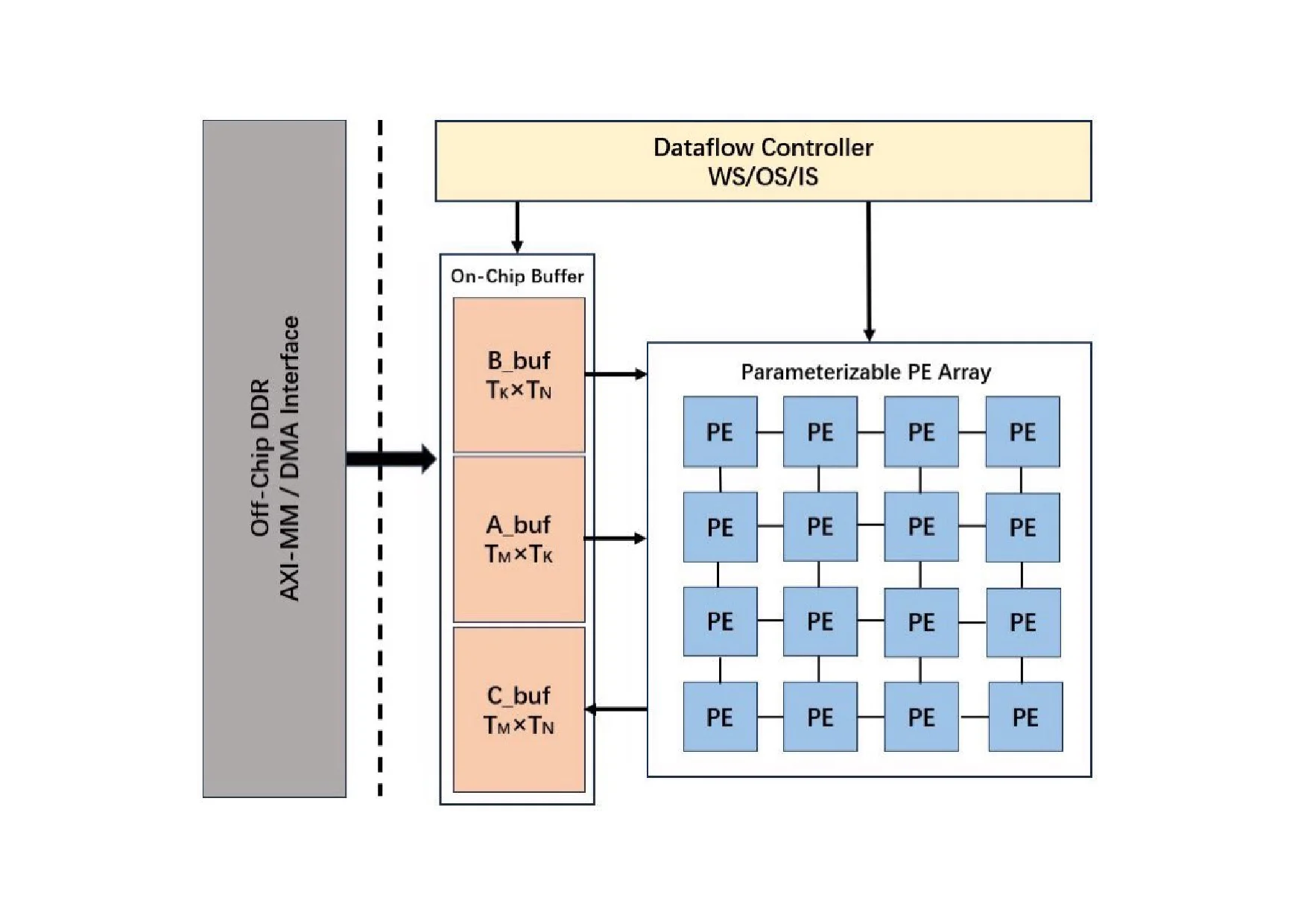
의료 현장 대형언어모델 평가를 위한 MediEval과 안전 파인튜닝
Large Language Models (LLMs) are increasingly applied to medicine, yet their adoption is limited by concerns over reliability and safety. Existing evaluations either test factual medical knowledge in isolation or assess patientlevel reasoning without